本文的主要目標是解決大數據平臺中元數據庫MySQL的異常故障。通過分析應用響應緩慢的問題,找到了集群組件HIVE和元數據庫MySQL的原因。通過日志分析、工具檢測和專家指導等一系列方法, 最終確定問題的根源是大數據集群中租戶的不規范使用所導致,并逐步解決了這個問題。本文將詳細描述故障的定位和解決思路,希望通過案例分析能為遇到類似問題的同行提供參考。
本文來自twt社區專業委員會的課題研究
一、故障背景
營銷人員在應用端進行目標客戶群建設的時候,發現有很大延遲。經過反饋、初步的查實定位,發現是后端調用大數據集群服務的時候,出現了沒有返回的情況。這個情況導致后續的住戶畫像、上傳集團、報數以及多個需要提醒目標客戶的應用延遲。甚至引起了部分專業分公司的投訴。
二、故障解決思路
1、故障定位:
HIVE 組件的問題分兩類:
1.hivemetastore
通過集群的監控頁面或者hivemetastore的日志分析查看hivemetastore的并發數量等參數的限制問題
2.hiveserver2
1)咨詢查看是不是最近有新增加的任務,通過分析看看不是有異常的SQL語句等程序;
2)通過集群的監控頁面或者hiveserver2的日志分析,查看是不是存在參數的問題;
3)審計分析hive的 元數據庫 表,是不是存在大量的分區表或者大的全表掃描的表等需要重點關注的審計表等信息
2、故障解決:
既然已經知道是hive組件導致的MySQL元數據庫的問題,建議從以下方面著手:
1.從hive組件著手
a.檢查是不是最近有新上的任務,沒有經過代碼審計或者SQL寫的不規范的任務,占用資源過多,從而導致集群響應緩慢;
b.檢查hiveserver2和hivemetastore的參數,分析其日志,看看是不是由于參數問題導致的集群組件緩慢;
2.從MySQL數據庫著手
a.檢查MySQL服務器的硬件資源情況,查看CPU、內存、IO、網卡等信息,看看是不是存在使用率過高的情況;
b.對hive的元數據庫進行盤點分析,看看是不是有長連接或者占用資源很大的SQL語句運行,從而導致數據庫緩慢;
3.從YARN組件著手
a)查看租戶隊列資源的分配是否合理;
b)檢查是否存在有大量的狀態不正常的任務。
3、案例說明:
1.如何發現MySQL的元數據庫異常故障問題
1)5月6日18點30分,運維人員發現創建目標客戶群任務延遲;經過查實,集群響應效率緩慢導致任務延遲;
2)5月6日19點到23點40分,經過分析spark日志、hiveserver日志,NameNode日志,hivemetastore日志,均未發現異常。在CM監控頁面,集群巡檢各項指標均未發現異常;
3)5月6日23點55分,運維人員發現mysql的元數據庫長連接會話較多,且Innod鎖數量持續增加未釋放;
4)5月7日0點3分,運維人員請求基保部同事協助定位原因,發現是元數據庫(MySQL)中存在大數據租戶的多個長連接,影響數據庫的性能,進而影響集群任務的提交響應效率;經過查實,長連接會話及未釋放的Innod鎖是由租戶user_yddsj(大數據租戶)的任務發起;
5)5月7日0點12分,運維人員電話通知大數據租戶廠家進行清理;并郵件通知局方協助,要求大數據租戶廠家對長連接會話進行清理;
6)5月7日 0點30分,同步邀請H公司大數據產品線專家協助處理,經過大數據產品線專家遠程分析,初步定位原因為metastore的并發數量不夠,把metastore的并發數量進行源碼級別的調整(增大并發數量),在測試環境經過多次部署、調測、驗證后,于5月7日20點30分發布到正式環境,21點30分完成了hivemetastore的服務重啟。重啟后,集群能力恢復正常。但是經過跟蹤監測,集群服務性能在23點45分左右持續下降,排除了hivemetastore的并發數量的影響,并于當晚邀請專家次日到現場進行支撐。
7)5月8日8點10分,H公司多位專家到達湖南電信現場,攜手定位故障原因,集成專家發現MySQL數據庫主機IO占用持續達到99%;
8)5月8日8點30分,通過MySQL專家定位,確認是5月7日發現的長連接會話及未釋放的Innod鎖仍未釋放,這些會話指向的目標表為user_yddsj.volte_mw,經過查詢元數據信息,此表有2萬多個分區,且租戶的執行程序存在全表掃描的情況。導致MySQL數據庫主機IO占用持續高水位;
9)5月8日11點19分,運維人員協同局方負責人,通知大數據租戶對表user_yddsj.volte_mw進行分區清理。經過局方負責人與大數據租戶確認,為盡快恢復集群的服務正常,決定先停止大數據租戶的集群服務,且停止其應用程序;
10)5月8日11點40分,大數據租戶開始清理user_yddsj.volte_mw表分區。于12點30分收到大數據租戶表分區清理完成的通知;
11)5月8日13點30分,運維人員經過一個多小時的觀察,集群的服務響應和性能都已經恢復正常。訪問元數據庫效率恢復正常。
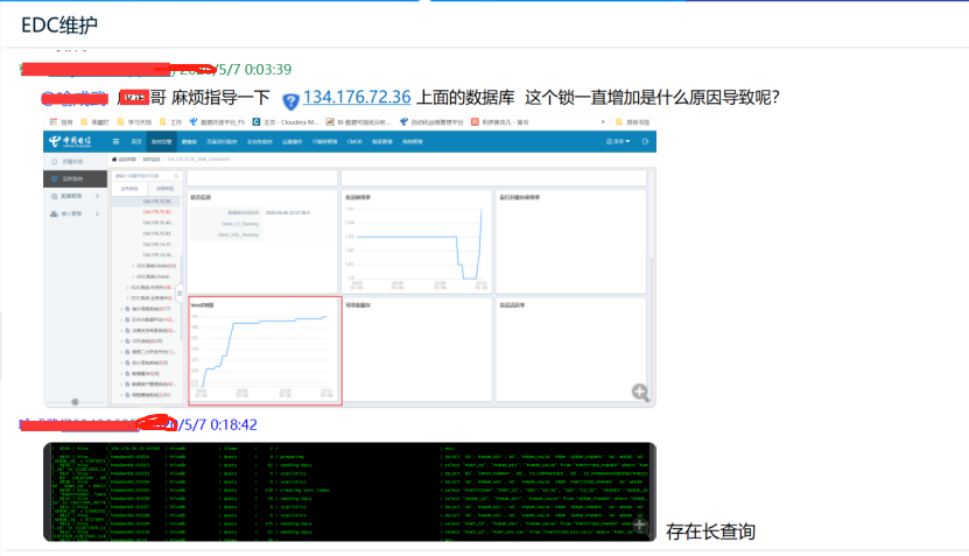
圖1:基礎保障部同事協助定位長連接問題
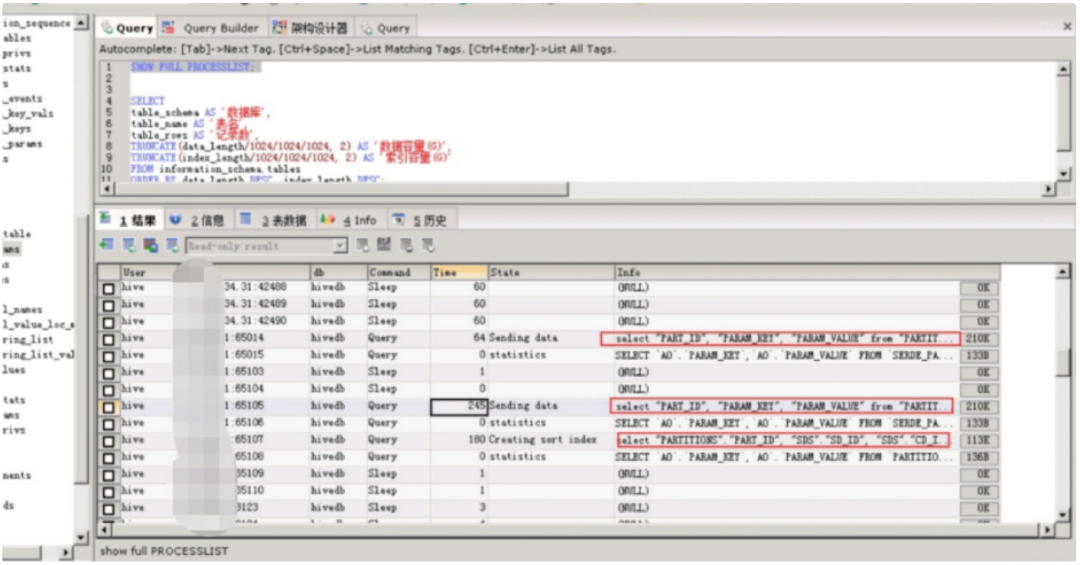
圖2-1:長連接相關語句,對應用戶為大數據開放的租戶
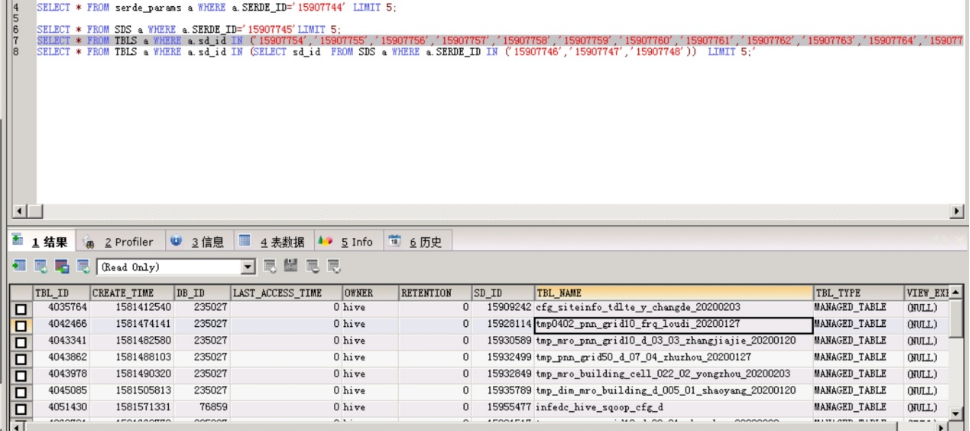
圖2-2:長連接相關語句,對應用戶為大數據開放的租戶

圖2-3:長連接相關語句,對應用戶為大數據開放的租戶
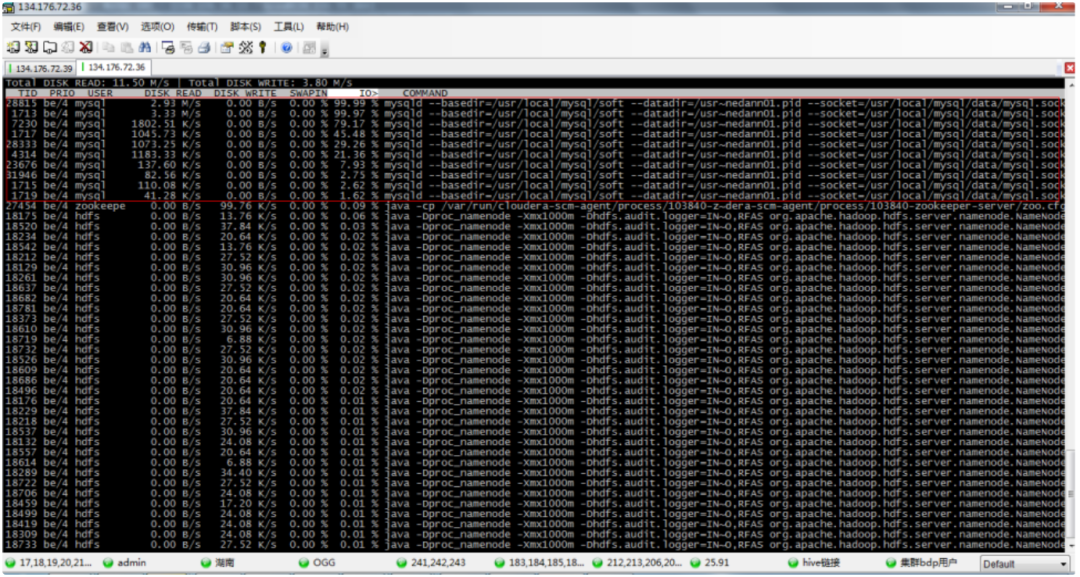
圖3:5月8日MySQL數據庫主機IO高水位
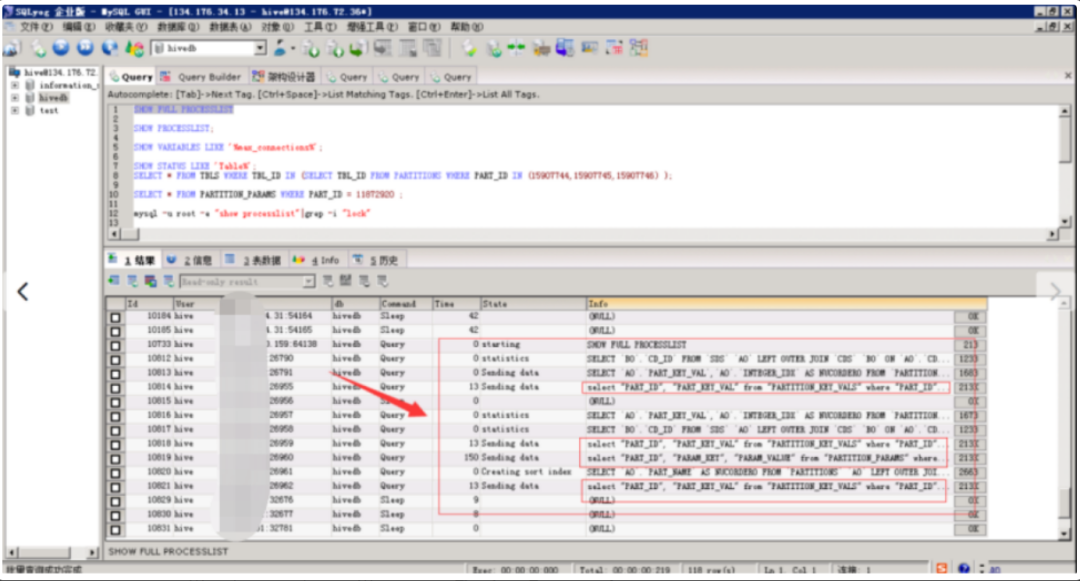
圖4-1:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區

圖4-2:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區

圖4-3:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區

圖4-4:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區

圖4-5:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區
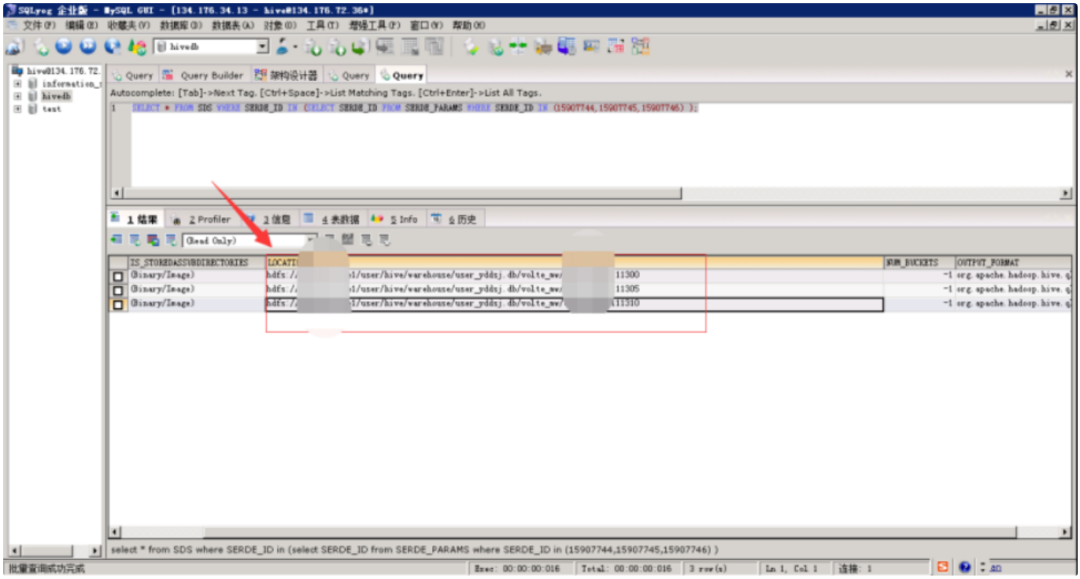
圖4-6:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區
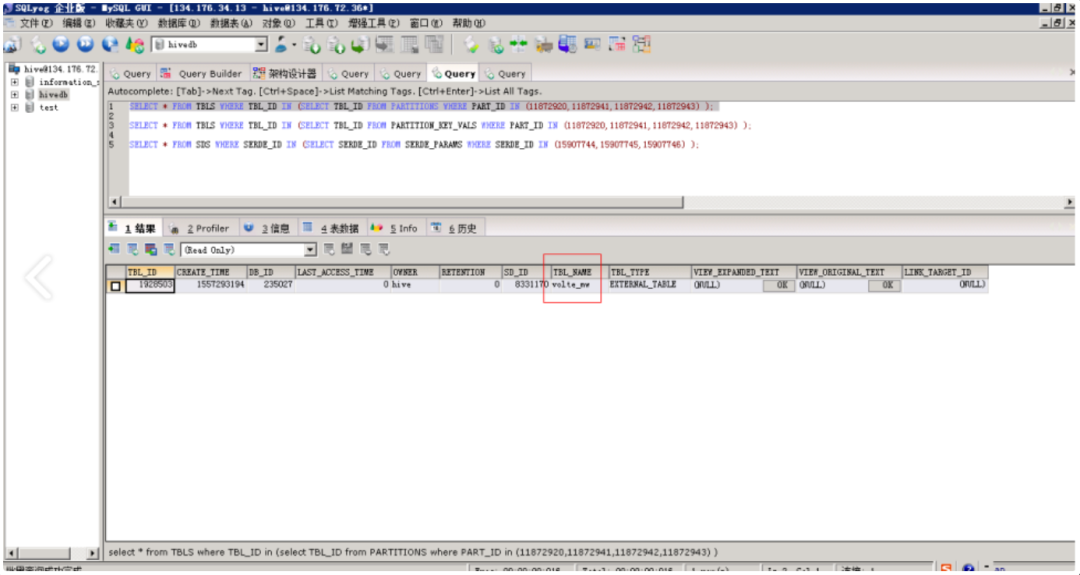
圖4-7:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區
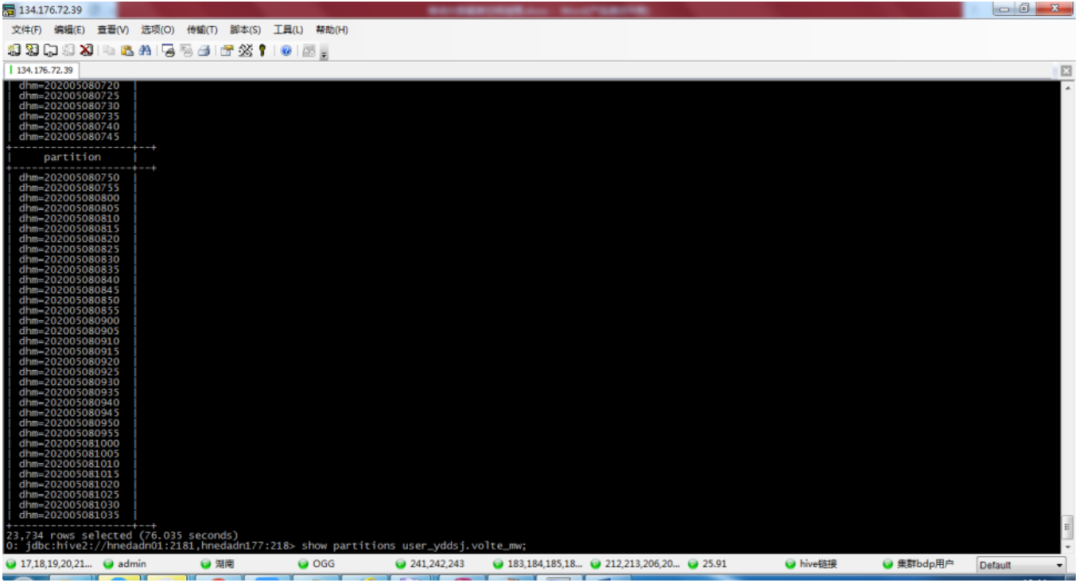
圖4-8:5月8日MySQL數據庫長連接語句,定位大數據租戶表user_yddsj.volte_mw存在2萬多個表分區
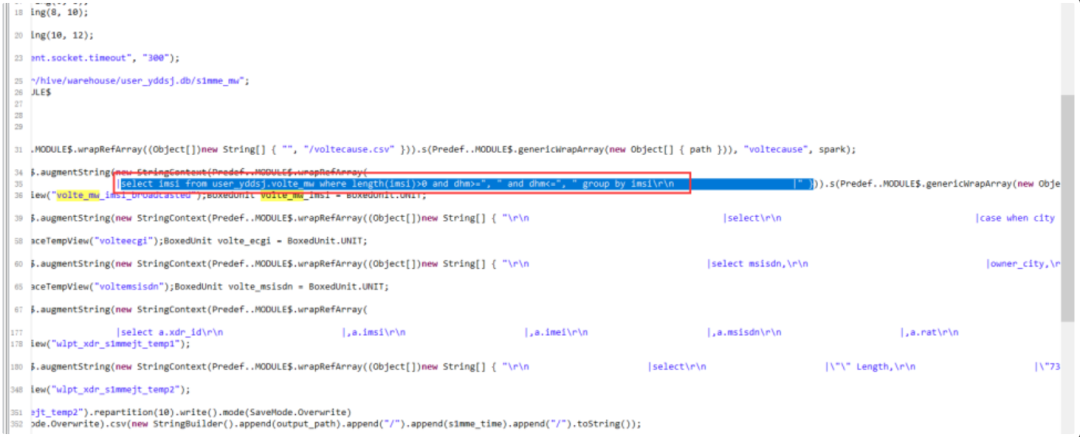
圖5:5月8日定位大數據租戶執行程序全表掃描問題
圖6:5月8日13點30分 經過一個多小時的觀察,集群的服務恢復正常。
三、故障總結
1、問題解決
臨時措施:
1)清理表分區,將元數據庫MySQL的壓力釋放;
永久措施:
1)重新評估構建表,將表設計重新建設,特別是分區的設定;
2)將表的清理規則進行設置,防止出現類似情況。
2、總結歸納
1)大數據租戶僅清理了HDFS文件,未清理HIVE表分區信息;
2)大數據租戶執行程序存在MySQL全表掃描情況;
3)大數據平臺租戶應用程序上線未納入租戶管理規范
4)大數據平臺集群表分區元數據缺少監控。
四、避免問題出現的優化
如何設計執行MySQL的元數據庫異常故障問題整改計劃 ( 限定完成時間:略 )
1)大數據租戶及時清理HIVE表分區信息,配置自動清理腳本;
2)大數據租戶對執行程序進行調整,完成volte_mw表分區改造,設計為大分區+小分區;完成執行程序的改造;
3)大數據平臺將租戶應用程序上線納入租戶管理規范;
4)大數據平臺將新增集群表分區元數據監控。
![[Unity]Lua本地時間、倒計時和正計時。](http://pic.xiahunao.cn/[Unity]Lua本地時間、倒計時和正計時。)





)
)



:視頻直播卡頓)







