目錄
1.什么是主從復制?
2.優勢
3.主從復制的原理
4.全量復制和增量復制
? ?4.1 全量復制
? ?4.2 增量復制
5.相關問題總結
? ?5.1?當主服務器不進行持久化時復制的安全性
? ?5.2 為什么主從全量復制使用RDB而不使用AOF?
? ?5.3?為什么還有無磁盤復制模式?
? ?5.4?為什么還會有從庫的從庫的設計?
? ?5.5?讀寫分離及其中的問題
1.什么是主從復制?
主從復制,是指將一臺Redis服務器的數據,復制到其他的Redis服務器。前者稱為主節點(master),后者稱為從節點(slave);數據的復制是單向的,只能由主節點到從節點。
通常情況下Master寫為主、Slave讀為主。如下圖所示:
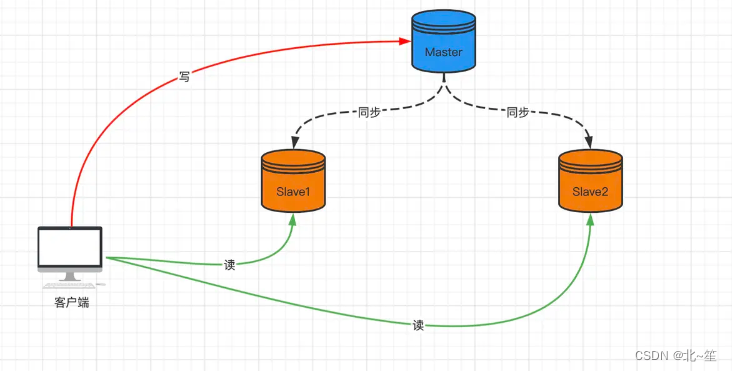
主從庫之間采用的是讀寫分離的方式。
- 讀操作:主庫、從庫都可以接收;
- 寫操作:首先到主庫執行,然后,主庫將寫操作同步給從庫。
2.優勢
主從復制的作用主要包括:
- 數據冗余:主從復制實現了數據的熱備份,是持久化之外的一種數據冗余方式。
- 故障恢復:當主節點出現問題時,可以由從節點提供服務,實現快速的故障恢復;實際上是一種服務的冗余。
- 負載均衡:在主從復制的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務(即寫Redis數據時應用連接主節點,讀Redis數據時應用連接從節點),分擔服務器負載;尤其是在寫少讀多的場景下,通過多個從節點分擔讀負載,可以大大提高Redis服務器的并發量。
- 高可用基石:除了上述作用以外,主從復制還是哨兵和集群能夠實施的基礎,因此說主從復制是Redis高可用的基礎。
3.主從復制的原理

 ?
?
主從復制過程大體可以分為3個階段:連接建立階段(即準備階段)、數據同步階段、命令傳播階段;下面分別進行介紹。?
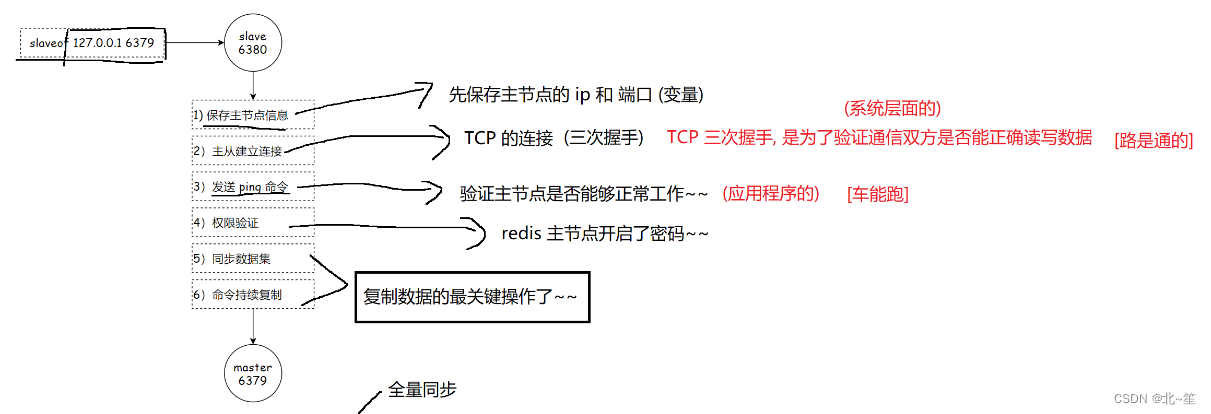
1. 連接建立階段
該階段的主要作用是在主從節點之間建立連接,為數據同步做好準備。
步驟1:保存主節點信息
從節點服務器內部維護了兩個字段,即masterhost和masterport字段,用于存儲主節點的ip和port信息。
需要注意的是,slaveof是異步命令,從節點完成主節點ip和port的保存后,向發送slaveof命令的客戶端直接返回OK,實際的復制操作在這之后才開始進行。
步驟2:建立socket連接
從節點每秒1次調用復制定時函數replicationCron(),如果發現了有主節點可以連接,便會根據主節點的ip和port,創建socket連接。如果連接成功,則:
從節點:為該socket建立一個專門處理復制工作的文件事件處理器,負責后續的復制工作,如接收RDB文件、接收命令傳播等。
主節點:接收到從節點的socket連接后(即accept之后),為該socket創建相應的客戶端狀態,并將從節點看做是連接到主節點的一個客戶端,后面的步驟會以從節點向主節點發送命令請求的形式來進行
步驟3:發送ping命令
從節點成為主節點的客戶端之后,發送ping命令進行首次請求,目的是:檢查socket連接是否可用,以及主節點當前是否能夠處理請求。
從節點發送ping命令后,可能出現3種情況:
(1)返回pong:說明socket連接正常,且主節點當前可以處理請求,復制過程繼續。
(2)超時:一定時間后從節點仍未收到主節點的回復,說明socket連接不可用,則從節點斷開socket連接,并重連。
(3)返回pong以外的結果:如果主節點返回其他結果,如正在處理超時運行的腳本,說明主節點當前無法處理命令,則從節點斷開socket連接,并重連。
步驟4:身份驗證
如果從節點中設置了masterauth選項,則從節點需要向主節點進行身份驗證;沒有設置該選項,則不需要驗證。從節點進行身份驗證是通過向主節點發送auth命令進行的,auth命令的參數即為配置文件中的masterauth的值。
如果主節點設置密碼的狀態,與從節點masterauth的狀態一致(一致是指都存在,且密碼相同,或者都不存在),則身份驗證通過,復制過程繼續;如果不一致,則從節點斷開socket連接,并重連。
步驟5:發送從節點端口信息
身份驗證之后,從節點會向主節點發送其監聽的端口號,主節點將該信息保存到該從節點對應的客戶端的slave_listening_port字段中;該端口信息除了在主節點中執行info Replication時顯示以外,沒有其他作用。
2. 數據同步階段
主從節點之間的連接建立以后,便可以開始進行數據同步,該階段可以理解為從節點數據的初始化。具體執行的方式是:從節點向主節點發送psync命令(Redis2.8以前是sync命令),開始同步。
數據同步階段是主從復制最核心的階段,根據主從節點當前狀態的不同,可以分為全量復制和部分復制,下面會專門講解這兩種復制方式以及psync命令的執行過程,這里不再詳述。
需要注意的是,在數據同步階段之前,從節點是主節點的客戶端,主節點不是從節點的客戶端;而到了這一階段及以后,主從節點互為客戶端。原因在于:在此之前,主節點只需要響應從節點的請求即可,不需要主動發請求,而在數據同步階段和后面的命令傳播階段,主節點需要主動向從節點發送請求(如推送緩沖區中的寫命令),才能完成復制。
3. 命令傳播階段
數據同步階段完成后,主從節點進入命令傳播階段;在這個階段主節點將自己執行的寫命令發送給從節點,從節點接收命令并執行,從而保證主從節點數據的一致性。
在命令傳播階段,除了發送寫命令,主從節點還維持著心跳機制:PING和REPLCONF ACK。由于心跳機制的原理涉及部分復制,因此將在介紹了部分復制的相關內容后單獨介紹該心跳機制。
4.全量復制和增量復制
注意:在2.8版本之前只有全量復制,而2.8版本后有全量和增量復制:
全量(同步)復制:比如第一次同步時增量(同步)復制:只會把主從庫網絡斷連期間主庫收到的命令,同步給從庫
 ?
?
? ?4.1 全量復制
當我們啟動多個 Redis 實例的時候,它們相互之間就可以通過 replicaof(Redis 5.0 之前使用 slaveof)命令形成主庫和從庫的關系,之后會按照三個階段完成數據的第一次同步。
 ?
?
? ?4.2 增量復制
如果主從庫在命令傳播時出現了網絡閃斷,那么,從庫就會和主庫重新進行一次全量復制,開銷非常大。從 Redis 2.8 開始,網絡斷了之后,主從庫會采用增量復制的方式繼續同步。

 ??
??
 ?
?
repl_backlog_buffer:它是為了從庫斷開之后,如何找到主從差異數據而設計的環形緩沖區,從而避免全量復制帶來的性能開銷。如果從庫斷開時間太久,repl_backlog_buffer環形緩沖區被主庫的寫命令覆蓋了,那么從庫連上主庫后只能乖乖地進行一次全量復制,所以repl_backlog_buffer配置盡量大一些,可以降低主從斷開后全量復制的概率。而在repl_backlog_buffer中找主從差異的數據后,如何發給從庫呢?這就用到了replication buffer。
replication buffer:Redis和客戶端通信也好,和從庫通信也好,Redis都需要給分配一個 內存buffer進行數據交互,客戶端是一個client,從庫也是一個client,我們每個client連上Redis后,Redis都會分配一個client buffer,所有數據交互都是通過這個buffer進行的:Redis先把數據寫到這個buffer中,然后再把buffer中的數據發到client socket中再通過網絡發送出去,這樣就完成了數據交互。所以主從在增量同步時,從庫作為一個client,也會分配一個buffer,只不過這個buffer專門用來傳播用戶的寫命令到從庫,保證主從數據一致,我們通常把它叫做replication buffer。
- 如果在網絡斷開期間,repl_backlog_size環形緩沖區寫滿之后,從庫是會丟失掉那部分被覆蓋掉的數據,還是直接進行全量復制呢?
對于這個問題來說,有兩個關鍵點:
-
一個從庫如果和主庫斷連時間過長,造成它在主庫repl_backlog_buffer的slave_repl_offset位置上的數據已經被覆蓋掉了,此時從庫和主庫間將進行全量復制。
-
每個從庫會記錄自己的slave_repl_offset,每個從庫的復制進度也不一定相同。在和主庫重連進行恢復時,從庫會通過psync命令把自己記錄的slave_repl_offset發給主庫,主庫會根據從庫各自的復制進度,來決定這個從庫可以進行增量復制,還是全量復制。
這里存在實時復制的一些知識:

5.相關問題總結
? ?5.1?當主服務器不進行持久化時復制的安全性
在進行主從復制設置時,強烈建議在主服務器上開啟持久化,當不能這么做時,比如考慮到延遲的問題,應該將實例配置為避免自動重啟。
為什么不持久化的主服務器自動重啟非常危險呢?為了更好的理解這個問題,看下面這個失敗的例子,其中主服務器和從服務器中數據庫都被刪除了。
- 我們設置節點A為主服務器,關閉持久化,節點B和C從節點A復制數據。
- 這時出現了一個崩潰,但Redis具有自動重啟系統,重啟了進程,因為關閉了持久化,節點重啟后只有一個空的數據集。
- 節點B和C從節點A進行復制,現在節點A是空的,所以節點B和C上的復制數據也會被刪除。
- 當在高可用系統中使用Redis Sentinel(哨兵),關閉了主服務器的持久化,并且允許自動重啟,這種情況是很危險的。比如主服務器可能在很短的時間就完成了重啟,以至于Sentinel都無法檢測到這次失敗,那么上面說的這種失敗的情況就發生了。
如果數據比較重要,并且在使用主從復制時關閉了主服務器持久化功能的場景中,都應該禁止實例自動重啟。
? ?5.2 為什么主從全量復制使用RDB而不使用AOF?
1、RDB文件內容是經過壓縮的二進制數據(不同數據類型數據做了針對性優化),文件很小。而AOF文件記錄的是每一次寫操作的命令,寫操作越多文件會變得很大,其中還包括很多對同一個key的多次冗余操作。在主從全量數據同步時,傳輸RDB文件可以盡量降低對主庫機器網絡帶寬的消耗,從庫在加載RDB文件時,一是文件小,讀取整個文件的速度會很快,二是因為RDB文件存儲的都是二進制數據,從庫直接按照RDB協議解析還原數據即可,速度會非常快,而AOF需要依次重放每個寫命令,這個過程會經歷冗長的處理邏輯,恢復速度相比RDB會慢得多,所以使用RDB進行主從全量復制的成本最低。
2、假設要使用AOF做全量復制,意味著必須打開AOF功能,打開AOF就要選擇文件刷盤的策略,選擇不當會嚴重影響Redis性能。而RDB只有在需要定時備份和主從全量復制數據時才會觸發生成一次快照。而在很多丟失數據不敏感的業務場景,其實是不需要開啟AOF的。
? ?5.3?為什么還有無磁盤復制模式?
Redis 默認是磁盤復制,但是如果使用比較低速的磁盤,這種操作會給主服務器帶來較大的壓力。Redis從2.8.18版本開始嘗試支持無磁盤的復制。使用這種設置時,子進程直接將RDB通過網絡發送給從服務器,不使用磁盤作為中間存儲。
無磁盤復制模式:master創建一個新進程直接dump RDB到slave的socket,不經過主進程,不經過硬盤。適用于disk較慢,并且網絡較快的時候。
使用repl-diskless-sync配置參數來啟動無磁盤復制。
使用repl-diskless-sync-delay 參數來配置傳輸開始的延遲時間;master等待一個repl-diskless-sync-delay的秒數,如果沒slave來的話,就直接傳,后來的得排隊等了; 否則就可以一起傳。
? ?5.4?為什么還會有從庫的從庫的設計?
通過分析主從庫間第一次數據同步的過程,你可以看到,一次全量復制中,對于主庫來說,需要完成兩個耗時的操作:生成 RDB 文件和傳輸 RDB 文件。
如果從庫數量很多,而且都要和主庫進行全量復制的話,就會導致主庫忙于 fork 子進程生成 RDB 文件,進行數據全量復制。fork 這個操作會阻塞主線程處理正常請求,從而導致主庫響應應用程序的請求速度變慢。此外,傳輸 RDB 文件也會占用主庫的網絡帶寬,同樣會給主庫的資源使用帶來壓力。那么,有沒有好的解決方法可以分擔主庫壓力呢?
其實是有的,這就是“主 - 從 - 從”模式。
在剛才介紹的主從庫模式中,所有的從庫都是和主庫連接,所有的全量復制也都是和主庫進行的。現在,我們可以通過“主 - 從 - 從”模式將主庫生成 RDB 和傳輸 RDB 的壓力,以級聯的方式分散到從庫上。
這樣一來,這些從庫就會知道,在進行同步時,不用再和主庫進行交互了,只要和級聯的從庫進行寫操作同步就行了,這就可以減輕主庫上的壓力,如下圖所示:
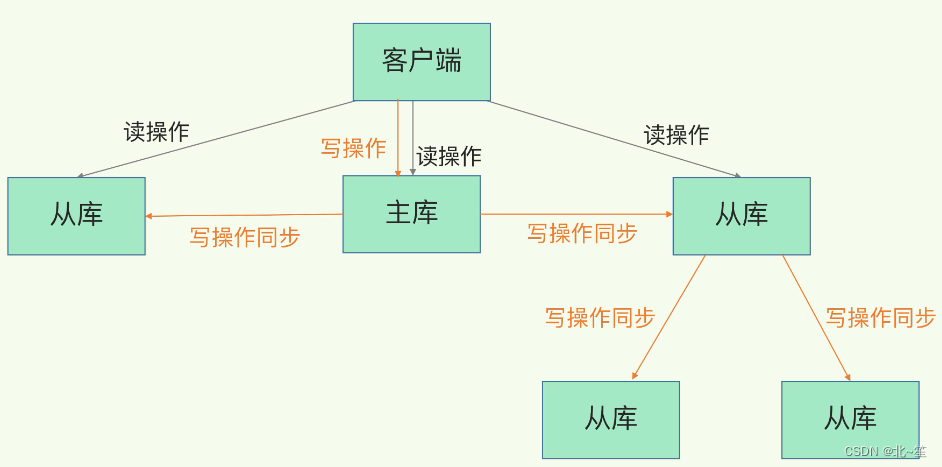
級聯的“主-從-從”模式好了,到這里,我們了解了主從庫間通過全量復制實現數據同步的過程,以及通過“主 - 從 - 從”模式分擔主庫壓力的方式。那么,一旦主從庫完成了全量復制,它們之間就會一直維護一個網絡連接,主庫會通過這個連接將后續陸續收到的命令操作再同步給從庫,這個過程也稱為基于長連接的命令傳播,可以避免頻繁建立連接的開銷。
? ?5.5?讀寫分離及其中的問題
在主從復制基礎上實現的讀寫分離,可以實現Redis的讀負載均衡:由主節點提供寫服務,由一個或多個從節點提供讀服務(多個從節點既可以提高數據冗余程度,也可以最大化讀負載能力);在讀負載較大的應用場景下,可以大大提高Redis服務器的并發量。下面介紹在使用Redis讀寫分離時,需要注意的問題。
- 延遲與不一致問題
前面已經講到,由于主從復制的命令傳播是異步的,延遲與數據的不一致不可避免。如果應用對數據不一致的接受程度程度較低,可能的優化措施包括:優化主從節點之間的網絡環境(如在同機房部署);監控主從節點延遲(通過offset)判斷,如果從節點延遲過大,通知應用不再通過該從節點讀取數據;使用集群同時擴展寫負載和讀負載等。
在命令傳播階段以外的其他情況下,從節點的數據不一致可能更加嚴重,例如連接在數據同步階段,或從節點失去與主節點的連接時等。從節點的slave-serve-stale-data參數便與此有關:它控制這種情況下從節點的表現;如果為yes(默認值),則從節點仍能夠響應客戶端的命令,如果為no,則從節點只能響應info、slaveof等少數命令。該參數的設置與應用對數據一致性的要求有關;如果對數據一致性要求很高,則應設置為no。
- 數據過期問題
在單機版Redis中,存在兩種刪除策略:
惰性刪除:服務器不會主動刪除數據,只有當客戶端查詢某個數據時,服務器判斷該數據是否過期,如果過期則刪除。定期刪除:服務器執行定時任務刪除過期數據,但是考慮到內存和CPU的折中(刪除會釋放內存,但是頻繁的刪除操作對CPU不友好),該刪除的頻率和執行時間都受到了限制。
在主從復制場景下,為了主從節點的數據一致性,從節點不會主動刪除數據,而是由主節點控制從節點中過期數據的刪除。由于主節點的惰性刪除和定期刪除策略,都不能保證主節點及時對過期數據執行刪除操作,因此,當客戶端通過Redis從節點讀取數據時,很容易讀取到已經過期的數據。
Redis 3.2中,從節點在讀取數據時,增加了對數據是否過期的判斷:如果該數據已過期,則不返回給客戶端;將Redis升級到3.2可以解決數據過期問題。
- 故障切換問題
在沒有使用哨兵的讀寫分離場景下,應用針對讀和寫分別連接不同的Redis節點;當主節點或從節點出現問題而發生更改時,需要及時修改應用程序讀寫Redis數據的連接;連接的切換可以手動進行,或者自己寫監控程序進行切換,但前者響應慢、容易出錯,后者實現復雜,成本都不算低。
- 總結
在使用讀寫分離之前,可以考慮其他方法增加Redis的讀負載能力:如盡量優化主節點(減少慢查詢、減少持久化等其他情況帶來的阻塞等)提高負載能力;使用Redis集群同時提高讀負載能力和寫負載能力等。如果使用讀寫分離,可以使用哨兵,使主從節點的故障切換盡可能自動化,并減少對應用程序的侵入。






及控制臺安裝)
模式)











)