DERT 目標檢測
- 基于卷積神經網絡的目標檢測回顧
- DETR對比Swin Transformer
- 摘要
- 檢測網絡流程
- DERT網絡架構
- 編碼器概述
- 解碼器概述
- 整體結構
- object queries的初始化
- Decoder中的Muiti-Head Self-Attention
- Decoder中的Muiti-Head Attention
- 損失函數
- 解決的問題

基于卷積神經網絡的目標檢測回顧
雙階段代表檢測算法:faster rcnn
單階段代表算法:yolo
上述單雙階段都是基于anchor
目標檢測廣泛的使用NMS(非極大值抑制算法)
DETR拋棄了上述算法思路。基于編碼器和解碼器來進行目標檢測
DETR對比Swin Transformer
之前的Swin TransformerSwin Transformer 主要用于目標檢測的編碼器部分,而不是解碼器部分。
在目標檢測中,通常會使用兩個主要組件:編碼器和解碼器。編碼器負責提取輸入圖像的特征,而解碼器則負責將這些特征轉換為目標檢測結果。Swin Transformer 主要用作編碼器,它通過多層的 Transformer 模塊來提取圖像特征。
至于解碼器部分,可以采用其他的方法來完成目標檢測任務。常見的解碼器包括使用卷積神經網絡 (CNN) 或者其他的傳統機器學習算法。具體選擇哪種解碼器取決于具體的任務和需求。
總結起來,Swin Transformer 在目標檢測中主要用作編碼器部分,而解碼器部分可以根據需求選擇其他方法來完成。
摘要

我們提出的新方法將物體檢測視為一個直接的集合預測問題。我們的方法簡化了檢測流水線,有效地消除了對許多手工設計組件的需求,如非最大抑制程序或錨點生成,這些組件明確地編碼了我們對任務的先驗知識。新框架被稱為 DEtection TRansformer 或 DETR,其主要成分是基于集合的全局損失(通過兩端匹配強制進行唯一預測)和變換器編碼器-解碼器架構。DETR 給定了一小組固定的已學對象查詢,通過推理對象之間的關系和全局圖像上下文,直接并行輸出最終的預測結果。與許多其他現代檢測器不同,新模型概念簡單,不需要專門的庫。在極具挑戰性的 COCO 物體檢測數據集上,DETR 的準確性和運行時間性能與成熟且高度優化的 Faster RCNN 基準相當。此外,DETR 可以很容易地通用于以統一的方式進行全視角分割。我們的研究表明,DETR 的性能明顯優于競爭基線。訓練代碼和預訓練模型見 https://github.com/facebookresearch/detr。
檢測網絡流程
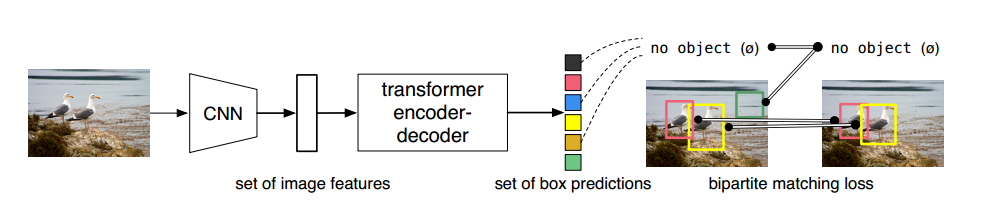
先使用CNN得到各個Patch作為輸入,在套用Transformer做編碼解碼結構
編碼和Vision Transformer一致,重點在于解碼,直接預測100個坐標框
Vision Transformer
預測的100個框當中,包括物體和非物體。

我們的 DEtection TRansformer(DETR,見圖 1)可一次性預測所有物體,并使用集合損失函數進行端到端訓練,在預測物體和地面實況物體之間進行雙向匹配。DETR 通過放棄多個手工設計的、編碼先驗知識(如空間錨點或非最大抑制)的組件來簡化檢測管道。與現有的大多數檢測方法不同,DETR 不需要任何定制層,因此可以在任何包含標準 CNN 和轉換器類的框架中輕松復制1。
大致思路就是:在編碼器部分輸入的100個向量,通過解碼器輸出,完成100個檢測框的預測
較NLP的區別是:詞語之間是有前后的對應關系的,檢測是100個向量同時輸入
DERT網絡架構
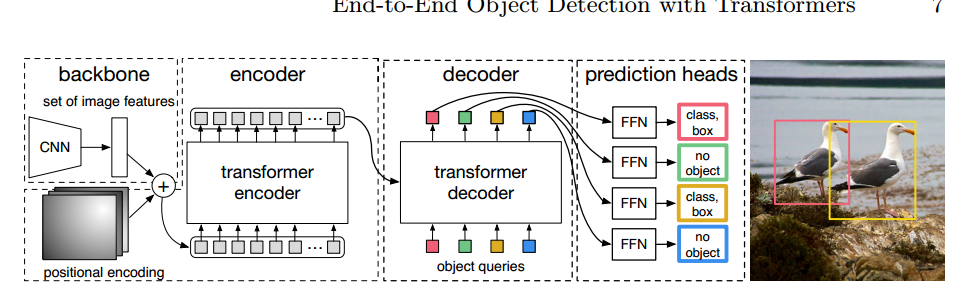

DETR 使用傳統的 CNN 骨干來學習輸入圖像的二維表示。該模型將其扁平化,并輔以位置編碼,然后將其傳遞給變換器編碼器。然后,變換解碼器將少量固定數量的已學位置嵌入(我們稱之為對象查詢)作為輸入,并額外關注編碼器的輸出。我們將解碼器的每個輸出嵌入信息傳遞給一個共享前饋網絡(FFN),該網絡可以預測檢測結果(類別和邊界框)或 "無對象 "類別。
其實
就是和VIT一模一樣的
編碼器概述


編碼器對一組參考點的自我關注。編碼器能夠分離單個實例。使用基準 DETR 模型對驗證集圖像進行預測。
得到各個目標的注意力結果,準備好特征,等解碼器來匹配
解碼器概述
解碼器階段首先初始化100個向量 (object queries)
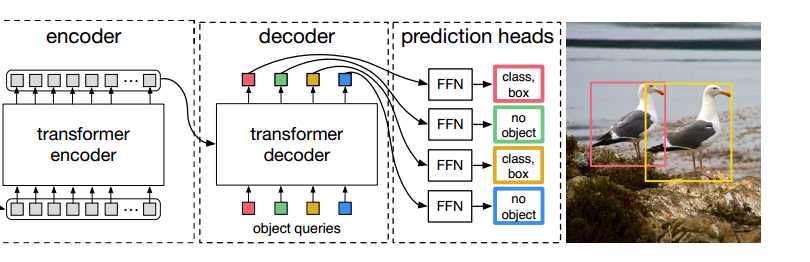
可以把encoder看成生產者,decoder看成消費者
encoder提供 k 和 v
decoder提供 q, 并使用q去查詢匹配 k 和 v
在解碼器中,所有的object queries同時去查詢匹配編碼器中每個位置的k和v
解碼器輸出的結果經過全連接層得到檢測框的位置和目標得分
object queries是核心,讓他學會從原始特征數據中找到物體的位置
整體結構
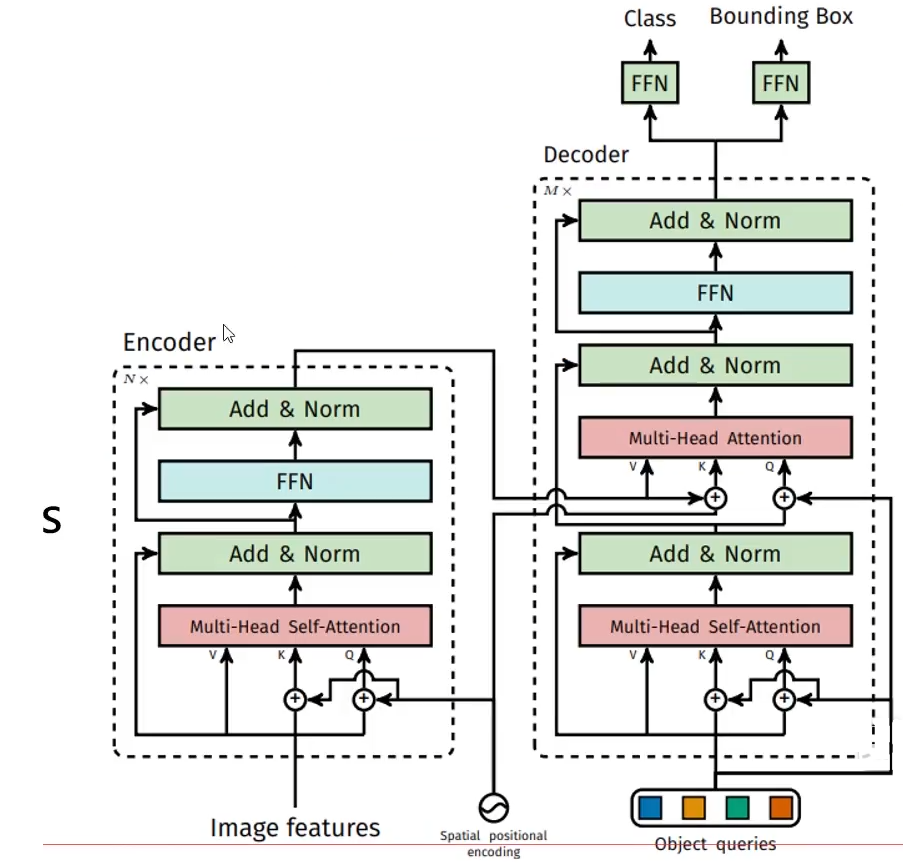
object queries的初始化
輸出層就是100個 object queries 預測
編碼器和Vision Transformer一樣(減去了cls)
解碼器首先隨機初始化100個object queries (以0+位置編碼進行的初始化的) 相當于就是用位置編碼進行的初始化
直接使用位置編碼作為初始化的目的:使得不同的object queries 關注圖像的不同區域。
通過多層讓其學習如何利用輸入特征
Decoder中的Muiti-Head Self-Attention
100個 object queries分別使用q,k,v完成自注意力機制
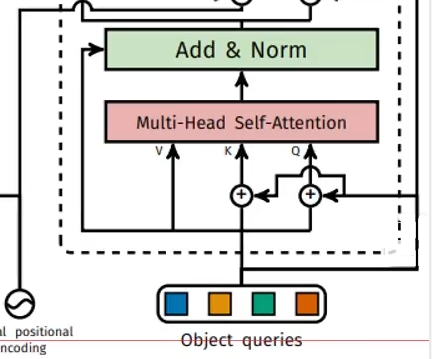
Decoder中的Muiti-Head Attention
由Encoder提供k和v,由Muiti-Head Self-Attention提供q
損失函數
匈牙利匹配
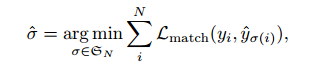

是地面實況 yi 與索引為 σ(i)的預測之間的成對匹配成本。根據之前的工作,匈牙利算法可以高效地計算出這一最優分配
匈牙利匹配:按照最小的loss進行匹配,使得選擇的預測框和真實框的loss最小,其余剩下的預測框就是背景
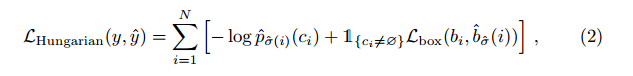

匹配成本既要考慮類別預測,也要考慮預測框和地面實況框的相似性
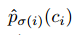 類別概率
類別概率
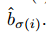 檢測框位置
檢測框位置

這種尋找匹配的過程與現代檢測器中用于將建議[37]或錨點[22]與地面實況對象相匹配的啟發式分配規則的作用相同。主要區別在于,我們需要找到一對一的匹配,以實現無重復的直接集合預測。第二步是計算損失函數,即上一步中所有匹配對的匈牙利損失。我們對損失的定義與常見物體檢測器的損失類似,即類預測的負對數似然和稍后定義的盒損失的線性組合:
解決的問題
注意力起到的作用:可以識別出遮擋區域


可視化解碼器對每個預測對象的注意力(圖像來自 COCO val set)。使用 DETR-DC5 模型進行預測。不同物體的注意力分數用不同顏色表示。解碼器通常會關注物體的四肢,如腿部和頭部。最佳彩色視圖











--類的使用)






![rust踩雷筆記(2)——一道hard帶來的思考[哈希表、字符串、滑動窗口]](http://pic.xiahunao.cn/rust踩雷筆記(2)——一道hard帶來的思考[哈希表、字符串、滑動窗口])
