文件的打開與關閉
想一想:
如果想用word編寫一份簡歷,應該有哪些流程呢?
- 打開word軟件,新建一個word文件
- 寫入個人簡歷信息
- 保存文件
- 關閉word軟件
同樣,在操作文件的整體過程與使用word編寫一份簡歷的過程是很相似的
- 打開文件,或者新建立一個文件
- 讀/寫數據
- 關閉文件
<1>打開文件
在python,使用open函數,可以打開一個已經存在的文件,或者創建一個新文件
open(文件路徑,訪問模式)
示例如下:
f = open('test.txt', 'w')說明:
文件路徑
文件的路徑分為相對路徑和絕對路徑兩種。
絕對路徑:指的是絕對位置,完整地描述了目標的所在地,所有目錄層級關系是一目了然的。
-
- 例如:
C:/Users/chris/AppData/Local/Programs/Python/Python37/python.exe,從電腦的盤符開始,表示的就是一個絕對路徑。
- 例如:
相對路徑:是從當前文件所在的文件夾開始的路徑。
-
test.txt,是在當前文件夾查找?test.txt?文件./test.txt,也是在當前文件夾里查找test.txt文件,?./?表示的是當前文件夾。../test.txt,從當前文件夾的上一級文件夾里查找?test.txt?文件。?../?表示的是上一級文件夾demo/test.txt,在當前文件夾里查找?demo這個文件夾,并在這個文件夾里查找?test.txt文件。
訪問模式:
| 訪問模式 | 說明 | |
| r | 以只讀方式打開文件。文件的指針將會放在文件的開頭。如果文件不存在, 則報錯。這是默認模式。 | |
| w | 打開一個文件只用于寫入。如果該文件已存在則將其覆蓋。 如果該文件不存在,創建新文件。 | |
| a | 打開一個文件用于追加。如果該文件已存在,文件指針將會放在文件的結尾。 也就是說,新的內容將會被寫入到已有內容之后。如果該文件不存在,創建新文件進行寫入。 | |
| r+ | 打開一個文件用于讀寫。文件指針將會放在文件的開頭。 | |
| w+ | 打開一個文件用于讀寫。如果該文件已存在則將其覆蓋。 如果該文件不存在, 創建新文件。 | |
| a+ | 打開一個文件用于讀寫。如果該文件已存在,文件指針將會放在文件的結尾。 文件打開時會是追加模式。如果該文件不存在,創建新文件用于讀寫。 | |
| rb | 以二進制格式打開一個文件用于只讀。文件指針將會放在文件的開頭。 | |
| wb | 以二進制格式打開一個文件只用于寫入。如果該文件已存在則將其覆蓋。 如果該文件不存在,創建新文件。 | |
| ab | 以二進制格式打開一個文件用于追加。如果該文件已存在, 文件指針將會放在文件的結尾。也就是說,新的內容將會被寫入到已有內容之后。如果該文件不存在,創建新文件進行寫入。 | |
| rb+ | 以二進制格式打開一個文件用于讀寫。文件指針將會放在文件的開頭。 | |
| wb+ | 以二進制格式打開一個文件用于讀寫。如果該文件已存在則將其覆蓋。 如果該文件不存在,創建新文件。 | |
| ab+ | 以二進制格式打開一個文件用于讀寫。如果該文件已存在, 文件指針將會放在文件的結尾。如果該文件不存在,創建新文件用于讀寫。 |
<2>關閉文件
close( )
示例如下:
# 新建一個文件,文件名為:test.txt
f = open('test.txt', 'w')# 關閉這個文件
f.close()文件的讀寫
<1>寫數據(write)
使用write()可以完成向文件寫入數據
demo: 新建一個文件?file_write_test.py,向其中寫入如下代碼:
f = open('test.txt', 'w')f.write('hello world, i am here!\n' * 5)f.close()運行之后會在file_write_test.py文件所在的路徑中創建一個文件test.txt,并寫入內容,運行效果顯示如下:?
注意:
- 如果文件不存在,那么創建;如果存在那么就先清空,然后寫入數據
<2>讀數據(read)
使用read(num)可以從文件中讀取數據,num表示要從文件中讀取的數據的長度(單位是字節),如果沒有傳入num,那么就表示讀取文件中所有的數據
demo: 新建一個文件file_read_test.py,向其中寫入如下代碼:
f = open('test.txt', 'r')content = f.read(5)? # 最多讀取5個數據print(content)print("-"*30)? # 分割線,用來測試content = f.read()? # 從上次讀取的位置繼續讀取剩下的所有的數據print(content)f.close()? # 關閉文件,這個可是個好習慣哦運行現象:
hello------------------------------ world, i am here!注意:
- 如果用open打開文件時,如果使用的"r",那么可以省略?
open('test.txt')
<3>讀數據(readline)
readline只用來讀取一行數據。
f = open('test.txt', 'r')content = f.readline()print("1:%s" % content)content = f.readline()print("2:%s" % content)f.close()<4>讀數據(readlines)
readlines可以按照行的方式把整個文件中的內容進行一次性讀取,并且返回的是一個列表,其中每一行為列表的一個元素。
f = open('test.txt', 'r')content = f.readlines()print(type(content))for temp in content:
??? print(temp)f.close()指針定位
tell() 方法用來顯示當前指針的位置
f = open('test.txt')print(f.read(10))? # read 指定讀取的字節數print(f.tell())??? # tell()方法顯示當前文件指針所在的文字f.close()seek(offset,whence) 方法用來重新設定指針的位置。
-
- offset:表示偏移量
- whence:只能傳入012中的一個數字。
- 0表示從文件頭開始
- 1表示從當前位置開始
- 2 表示從文件的末尾開始
f = open('test.txt','rb')? # 需要指定打開模式為rb,只讀二進制模式print(f.read(3))print(f.tell())f.seek(2,0)?? # 從文件的開頭開始,跳過兩個字節print(f.read())f.seek(1,1) # 從當前位置開始,跳過一個字節print(f.read())f.seek(-4,2) # 從文件末尾開始,往前跳過四個字節print(f.read())f.close()CSV文件
CSV文件:Comma-Separated Values,中文叫逗號分隔值或者字符分割值,其文件以純文本的形式存儲表格數據。可以把它理解為一個表格,只不過這個表格是以純文本的形式顯示的,單元格與單元格之間,默認使用逗號進行分隔;每行數據之間,使用換行進行分隔。
name,age,scorezhangsan,18,98lisi,20,99wangwu,17,90jerry,19,95Python中的csv模塊,提供了相應的函數,可以讓我們很方便的讀寫csv文件。
CSV文件的寫入
import csv
# 以寫入方式打開一個csv文件
file = open('test.csv','w')
# 調用writer方法,傳入csv文件對象,得到的結果是一個CSVWriter對象
writer = csv.writer(file)
# 調用CSVWriter對象的writerow方法,一行行的寫入數據
writer.writerow(['name', 'age', 'score'])
# 還可以調用writerows方法,一次性寫入多行數據
writer.writerows([['zhangsan', '18', '98'],['lisi', '20', '99'], ['wangwu', '17', '90'], ['jerry', '19', '95']])
file.close()
CSV文件的讀取
import csv
# 以讀取方式打開一個csv文件
file = open('test.csv', 'r')
# 調用csv模塊的reader方法,得到的結果是一個可迭代對象
reader = csv.reader(file)
# 對結果進行遍歷,獲取到結果里的每一行數據
for row in reader:
??? print(row)
file.close()
內存中寫入數據
除了將數據寫入到一個文件以外,我們還可以使用代碼,將數據暫時寫入到內存里,可以理解為數據緩沖區。Python中提供了StringIO和BytesIO這兩個類將字符串數據和二進制數據寫入到內存里。
StringIO
StringIO可以將字符串寫入到內存中,像操作文件一下操作字符串。
from io import StringIO
# 創建一個StringIO對象
f = StringIO()
# 可以像操作文件一下,將字符串寫入到內存中
f.write('hello\r\n')
f.write('good')
# 使用文件的 readline和readlines方法,無法讀取到數據
# print(f.readline())
# print(f.readlines())
# 需要調用getvalue()方法才能獲取到寫入到內存中的數據
print(f.getvalue())
f.close()
BytesIO
如果想要以二進制的形式寫入數據,可以使用BytesIO類,它的用法和StringIO相似,只不過在調用write方法寫入時,需要傳入二進制數據。
from io import BytesIO
f = BytesIO()
f.write('你好\r\n'.encode('utf-8'))
f.write('中國'.encode('utf-8'))
print(f.getvalue())
f.close()
應用:制作文件的備份
輸入文件的名字,然后程序自動完成對文件進行備份
參考代碼
# 提示輸入文件
file_name = input("請輸入要拷貝的文件名字:")
# 以讀的方式打開文件
old_file = open(file_name, 'rb')
# 分割文件名和后綴名
file_names =file_name.rsplit('.', maxsplit=1)
# 組織新的文件名字
new_file_name = file_names[0] + '.bak.'+file_names[1]
# 創建新文件
newFile = open(new_file_name, 'wb')
# 把舊文件中的數據,一行一行的進行復制到新文件中
for lineContent in old_file.readlines():
??? newFile.write(lineContent)
# 關閉文件
old_file.close()
newFile.close()
序列化和反序列化
通過文件操作,我們可以將字符串寫入到一個本地文件。但是,如果是一個對象(例如列表、字典、元組等),就無法直接寫入到一個文件里,需要對這個對象進行序列化,然后才能寫入到文件里。
設計一套協議,按照某種規則,把內存中的數據轉換為字節序列,保存到文件,這就是序列化,反之,從文件的字節序列恢復到內存中,就是反序列化。
Python中提供了JSON和pickle兩個模塊用來實現數據的序列化和反序列化。
JSON模塊
JSON(JavaScriptObjectNotation, JS對象簡譜)是一種輕量級的數據交換格式,它基于 ECMAScript 的一個子集,采用完全獨立于編程語言的文本格式來存儲和表示數據。JSON的本質是字符串!
使用JSON實現序列化
JSON提供了dump和dumps方法,將一個對象進行序列化。
dumps方法的作用是把對象轉換成為字符串,它本身不具備將數據寫入到文件的功能。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# file.write(names)? 出錯,不能直接將列表寫入到文件里
# 可以調用 json的dumps方法,傳入一個對象參數
result = json.dumps(names)
# dumps 方法得到的結果是一個字符串
print(type(result))? # <class 'str'>
# 可以將字符串寫入到文件里
file.write(result)
file.close()
dump方法可以在將對象轉換成為字符串的同時,指定一個文件對象,把轉換后的字符串寫入到這個文件里
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# dump方法可以接收一個文件參數,在將對象轉換成為字符串的同時寫入到文件里
json.dump(names, file)
file.close()
注意:如果是一個空對象,調用dumps方法轉換成為一個JSON對象,得到的結果是null(JS里的空對象)
json.dumps(None)? # null使用JSON實現反序列化
使用loads和load方法,可以將一個JSON字符串反序列化成為一個Python對象。
loads方法需要一個字符串參數,用來將一個字符串加載成為Python對象。
import json
# 調用loads方法,傳入一個字符串,可以將這個字符串加載成為Python對象
result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]')print(type(result))? # <class 'list'>load方法可以傳入一個文件對象,用來將一個文件對象里的數據加載成為Python對象。
import json
# 以可讀方式打開一個文件
file = open('names.txt', 'r')# 調用load方法,將文件里的內容加載成為一個Python對象
result = json.load(file)print(result)file.close()pickle模塊
和json模塊類似,pickle模塊也有dump和dumps方法可以對數據進行序列化,同時也有load和loads方法進行反序列化。區別在于,json模塊是將對象轉換成為字符串,而pickle模塊是將對象轉換成為二進制。
pickle模塊里方法的使用和json里方法的使用大致相同,需要注意的是,pickle是將對象轉換成為二進制,所以,如果想要把內容寫入到文件里,這個文件必須要以二進制的形式打開。
區別(了解)
思考: json和pickle兩個模塊都可以將對象進行序列化和反序列化,那它們有哪些區別,在使用場景上又該如何選擇?
json模塊:
將對象轉換成為字符串,不管是在哪種操作系統,哪種編程語言里,字符串都是可識別的。
json就是用來在不同平臺間傳遞數據的。
并不是所有的對象都可以直接轉換成為一個字符串,下標列出了Python對象與json字符串的對應關系。
| Python | JSON |
| dict | object |
| list,tuple | array |
| str | string |
| int,float | number |
| True | true |
| False | false |
| None | null |
如果是一個自定義對象,默認無法裝換成為json字符串,需要手動指定JSONEncoder.
如果是將一個json串重新轉換成為對象,這個對象里的方法就無法使用了。
import jsonclass MyEncode(json.JSONEncoder):
??? def default(self, o):??????? # return {"name":o.name,"age":o.age}??????? return o.__dict__class Person(object):
??? def __init__(self, name, age):??????? self.name = name??????? self.age = age????? def eat(self):????????? print(self.name+'正在吃東西')p1 = Person('zhangsan', 18)# 自定義對象想要轉換成為json字符串,需要給這個自定義對象指定JSONEncoder
result = json.dumps(p1, cls=MyEncode)print(result)? # {"name": "zhangsan", "age": 18}# 調用loads方法將對象加載成為一個對象以后,得到的結果是一個字典
p = json.loads(result)print(type(p))pickle模塊:
-
- pickle序列化是將對象按照一定的規則轉換成為二進制保存,它不能跨平臺傳遞數據。
- pickle的序列化會將對象的所有數據都保存。
異常的概念
程序在運行過程中,由于我們的編碼不規范,或者其他原因一些客觀原因,導致我們的程序無法繼續運行,此時,程序就會出現異常。如果我們不對異常進行處理,程序可能會由于異常直接中斷掉。為了保證程序的健壯性,我們在程序設計里提出了異常處理這個概念。
讀取文件異常
在讀取一個文件時,如果這個文件不存在,則會報出FileNotFoundError錯誤。
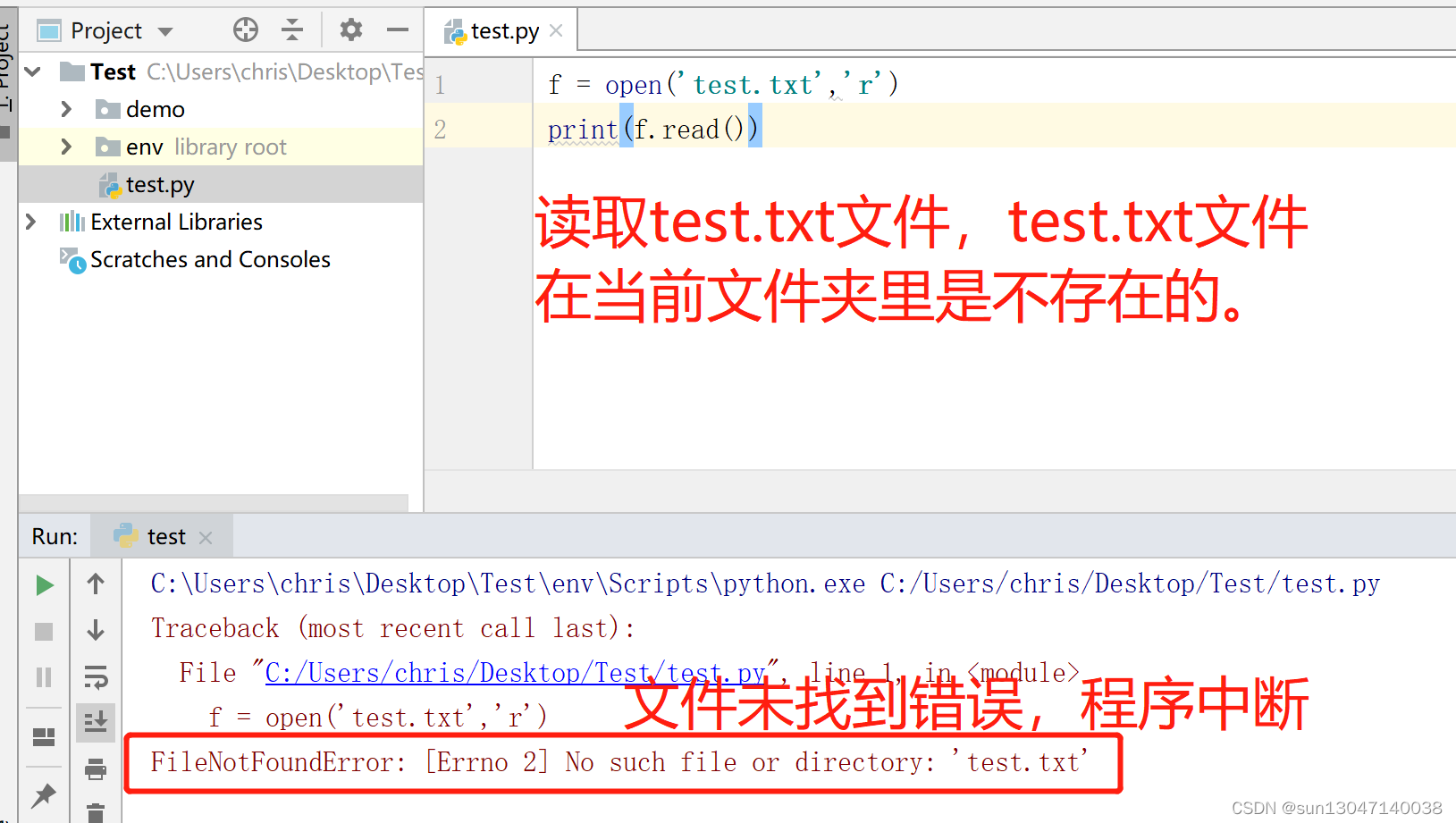
程序在運行過程中會經常遇到類似的異常,如果我們不進行處理,此時程序就會中斷并退出。為了提高程序的健壯性,我們可以使用異常處理機制來解決程序運行過程中可能出現的問題。
try...except語句
try...except語句可以對代碼運行過程中可能出現的異常進行處理。 語法結構:
try:
??? 可能會出現異常的代碼塊except 異常的類型:??? 出現異常以后的處理語句示例:
try:
??? f = open('test.txt', 'r')??? print(f.read())except FileNotFoundError:??? print('文件沒有找到,請檢查文件名稱是否正確')try...else語句
咱們應該對else并不陌生,在if中,它的作用是當條件不滿足時執行的實行;同樣在try...except...中也是如此,即如果沒有捕獲到異常,那么就執行else中的事情
try: num = 100 print(num) except NameError as errorMsg: print('產生錯誤了:%s'%errorMsg) else: print('沒有捕獲到異常,真高興') 運行結果如下:?
try..finally語句
try...finally...語句用來表達這樣的情況:
在程序中,如果一個段代碼必須要執行,即無論異常是否產生都要執行,那么此時就需要使用finally。 比如文件關閉,釋放鎖,把數據庫連接返還給連接池等。
try:
??? f = open('test.txt')??? try:??????? while True:??????????? content = f.readline()??????????? if len(content) == 0:??????????????? break??????????? print(content)??? except:??????? #如果在讀取文件的過程中,產生了異常,那么就會捕獲到??????? #比如 按下了 ctrl+c??????? pass??? finally:??????? f.close()??????? print('關閉文件')except:??? print("沒有這個文件")說明:
我們可以觀察到KeyboardInterrupt異常被觸發,程序退出。但是在程序退出之前,finally從句仍然被執行,把文件關閉。
with關鍵字的使用
對于系統資源如文件、數據庫連接、socket 而言,應用程序打開這些資源并執行完業務邏輯之后,必須做的一件事就是要關閉(斷開)該資源。
比如 Python 程序打開一個文件,往文件中寫內容,寫完之后,就要關閉該文件,否則會出現什么情況呢?極端情況下會出現 "Too many open files" 的錯誤,因為系統允許你打開的最大文件數量是有限的。
同樣,對于數據庫,如果連接數過多而沒有及時關閉的話,就可能會出現 "Can not connect to MySQL server Too many connections",因為數據庫連接是一種非常昂貴的資源,不可能無限制的被創建。
來看看如何正確關閉一個文件。
- 普通版:
def m1():
??? f = open("output.txt", "w")??? f.write("python之禪")??? f.close()這樣寫有一個潛在的問題,如果在調用 write 的過程中,出現了異常進而導致后續代碼無法繼續執行,close 方法無法被正常調用,因此資源就會一直被該程序占用者釋放。那么該如何改進代碼呢?
- 進階版:
def m2():
??? f = open("output.txt", "w")??? try:??????? f.write("python之禪")??? except IOError:??????? print("oops error")??? finally:??????? f.close()改良版本的程序是對可能發生異常的代碼處進行 try 捕獲,使用 try/finally 語句,該語句表示如果在 try 代碼塊中程序出現了異常,后續代碼就不再執行,而直接跳轉到 except 代碼塊。而無論如何,finally 塊的代碼最終都會被執行。因此,只要把 close 放在 finally 代碼中,文件就一定會關閉。
- 高級版:
def m3():
??? with open("output.txt", "r") as f:??????? f.write("Python之禪")一種更加簡潔、優雅的方式就是用 with 關鍵字。open 方法的返回值賦值給變量 f,當離開 with 代碼塊的時候,系統會自動調用 f.close() 方法, with 的作用和使用 try/finally 語句是一樣的。
上下文管理器
with語句實質上是一個上下文管理器,with語句后的對象都會有__enter__()和__exit__()方法。在進入到上下文時,會自動調用__enter__()方法,程序正常執行完成,或者出現異常中斷的時候,都會調用__exit__()方法。
class MyContext(object):
??? def __init__(self, name, age):??????? self.name = name??????? self.age = age??? def __enter__(self):??????? print('調用了enter方法')??????? return self??? def test(self):??????? 1 / 0??????? print(self.name + '調用了test方法')??? def __exit__(self, exc_type, exc_val, exc_tb):??????? print('調用了exit方法')??????? print(exc_type, exc_val, exc_tb)with MyContext('zhangsan', 18) as context:
??? context.test()自定義異常
你可以用raise語句來引發一個異常。異常/錯誤對象必須有一個名字,且它們應是Error或Exception類的子類
下面是一個引發異常的例子:
class ShortInputException(Exception):
??? '''自定義的異常類'''??? def __init__(self, length, atleast):??????? #super().__init__()??????? self.length = length??????? self.atleast = atleast??? def __str__(self):??????? return '輸入的長度是 %d,長度至少應是 %d'% (self.length, self.atleast))def main():
??? try:??????? s = input('請輸入 --> ')??????? if len(s) < 3:??????????? # raise 引發一個自定義的異常??????????? raise ShortInputException(len(s), 3)??? except ShortInputException as result:? # x這個變量被綁定到了錯誤的實例??????? print('ShortInputException:' % result)??? else:??????? print('沒有異常發生.')main()運行結果如下:
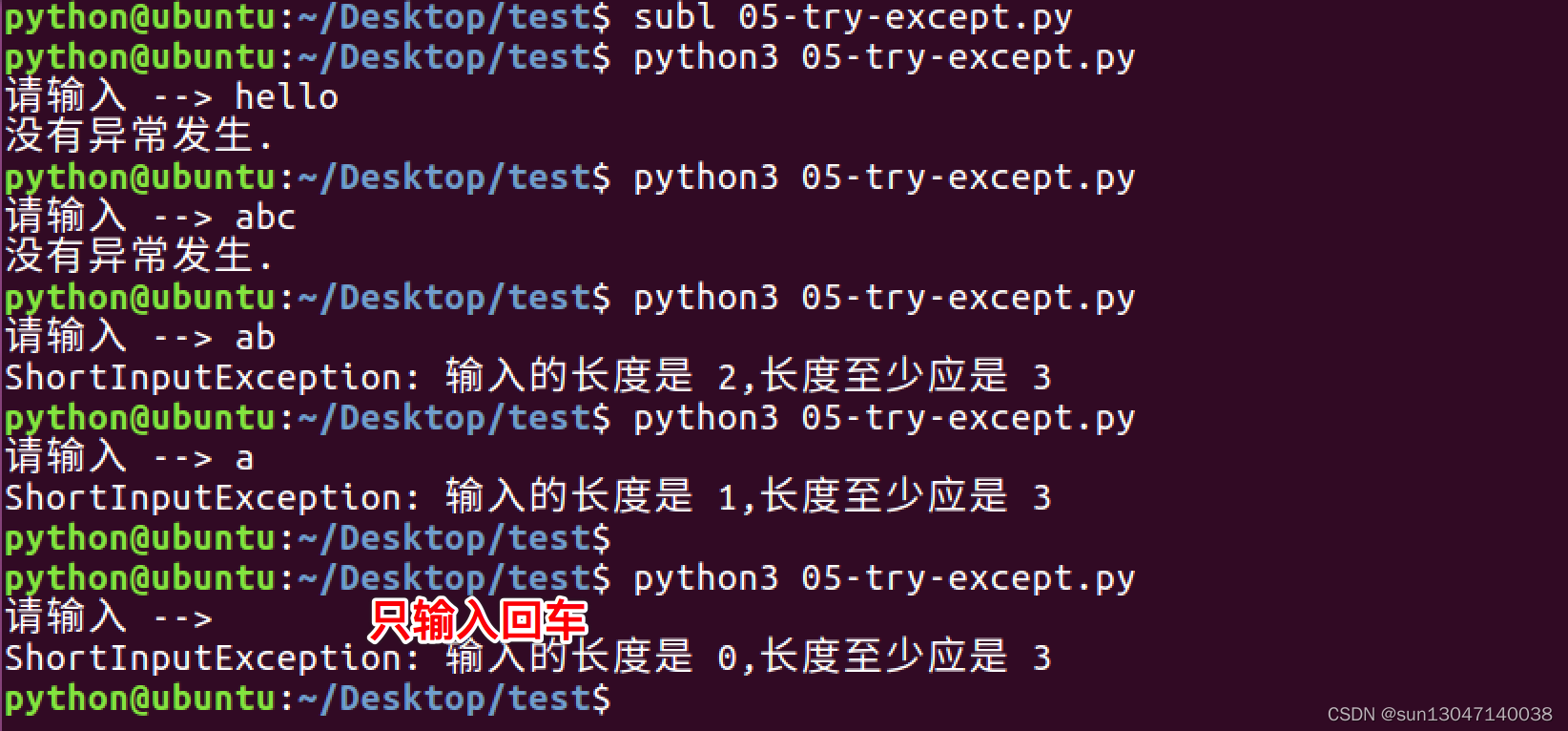
--某課網登錄)
【Redis】)










)
![[C++] string類的介紹與構造的模擬實現,進來看吧,里面有空調](http://pic.xiahunao.cn/[C++] string類的介紹與構造的模擬實現,進來看吧,里面有空調)





