為什么80%的碼農都做不了架構師?>>> ??
今天客戶系統升級,通過DMVs性能分析查了一下,升級后發現一個語句執行時間比較長,執行語句要好幾秒鐘,調出語句如下:
select?distinct?field003?from?ufi2j0n11179717502375?where?
field003?not?in?('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b',
'40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3')?and???requestid?in(select?requestid?from?ufi8s6u81179717475734?where?field001?in?(select?requestid?from? uft3a6h61176948132312?where?field066?is?not??null?and??field197?between?convert(datetime,?'2008-08-16')?and?convert(datetime,'2008-09-15'))?)
?? 后來看了一下,這幾表的數據
--?表 dbo.uft3a6h61176948132312?:?988行
-- 表:dbo.ufi2j0n11179717502375??:713行
-- 表:?dbo.ufi8s6u81179717475734?:??273行
? ?發現這三張表都沒有超過1千行數據,建立索引意義不大,為何如此慢,看看執行計劃:
??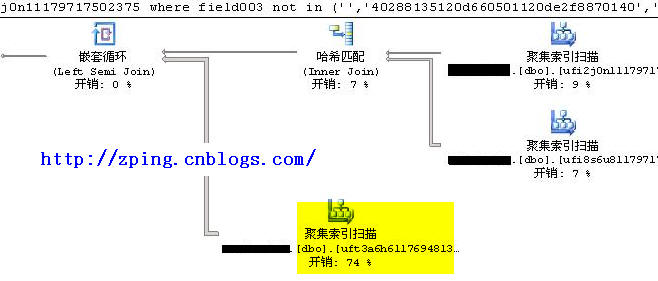
? 分析:發現是表dbo.uft3a6h61176948132312?訪問開銷最大,但表中數據不到一千行。執行看看結果:
(5?行受影響)
表?'uft3a6h61176948132312'。掃描計數?1,邏輯讀取?27161?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'Worktable'。掃描計數?0,邏輯讀取?0?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'ufi8s6u81179717475734'。掃描計數?1,邏輯讀取?37?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'ufi2j0n11179717502375'。掃描計數?1,邏輯讀取?46?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
??? 這里發現表uft3a6h61176948132312的訪問有近3萬次IO。?一開始以為是in的緣故,將in換成exists結果也是一樣,這時考慮用inner join來重新寫sql語句,語句如下:
select?distinct?a.field003?from?ufi2j0n11179717502375??a
inner?join?ufi8s6u81179717475734?b?on?a.requestid=b.requestid
inner?join??uft3a6h61176948132312?c?on?b.field001=c.requestid
where?a.field003?not?in?('','40288135120d660501120de2f8870140','40288135120d660501120de4b9ee014b','40288135120d660501120de9c3ba016c','40288135120d660501120df0460c01b2','40288135120d660501120df1dc2d01d3')?and???c.field066?is?not??null?and??c.field197?between?
convert(datetime,?'2008-08-16')?and?convert(datetime,'2008-09-15')
? 查看執行計劃:
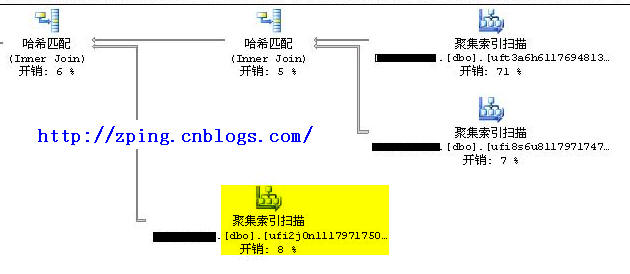
? 分析:這時發現執行計劃發生了變化,最外層的表變成了dbo.ufi2j0n11179717502375,執行結果如下:
(5?行受影響)
表?'Worktable'。掃描計數?0,邏輯讀取?0?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'ufi2j0n11179717502375'。掃描計數?1,邏輯讀取?46?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'ufi8s6u81179717475734'。掃描計數?1,邏輯讀取?37?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
表?'uft3a6h61176948132312'。掃描計數?1,邏輯讀取?421?次,物理讀取?0?次,預讀?0?次,lob?邏輯讀取?0?次,lob?物理讀取?0?次,lob?預讀?0?次。
?? 這時發現整個IO次數比先前少了很多。
? 總結:
????? 根據這兩個執行計劃分析,sql server 2005優化器對于in語句沒有正確選擇聯結算法,錯誤的采用了采用了”嵌套循環算法“。
????? 根據嵌套循環算法IO次數:421*(其他兩個表的關聯匹配行數)≈27163次 (訪問表“uft3a6h61176948132312”IO次數),而這時由于返回的行數比較多,又沒有建立索引,這時最佳的算法是使用“hash聯結算法“

)
_Java NIO系列教程(一) Java NIO 概述)

和Context.getExternalCacheDir()方法)







)




在工程中實際使用)
)
