Previous: elasticsearch外用與內觀(一)-常用功能與使用方法
在了解了es的基本用法之后,我們再來看看當插入文檔數據時,elasticsearch都在做什么。
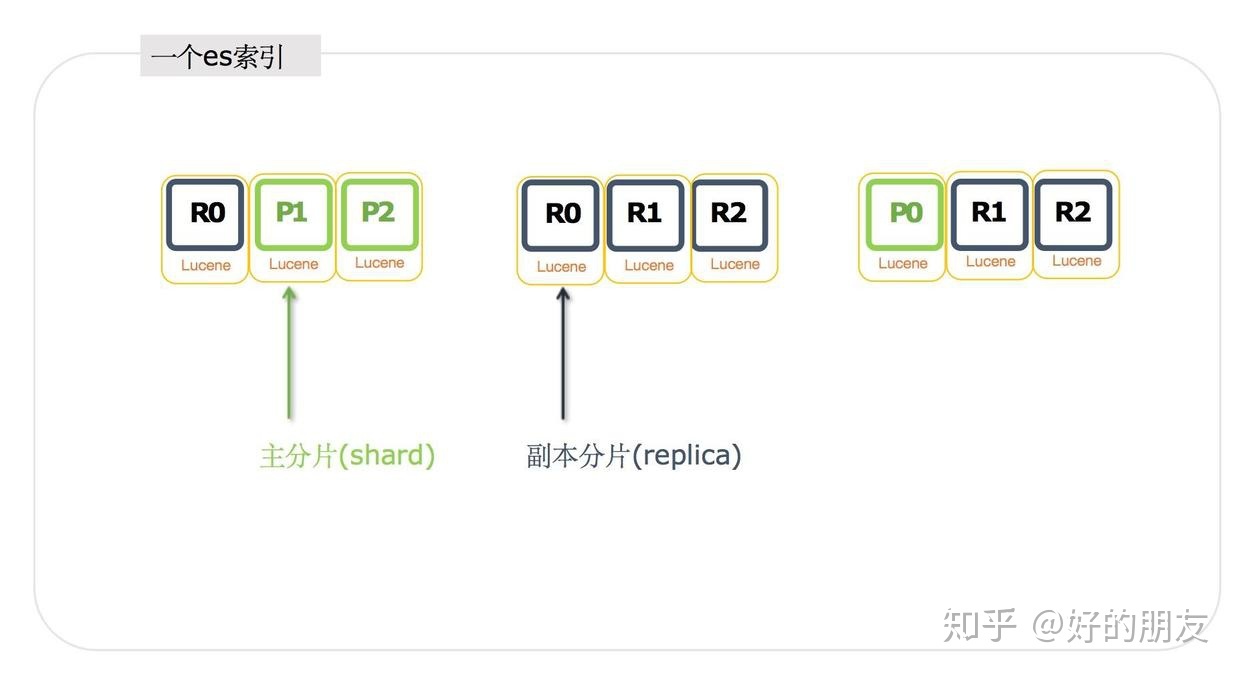
首先,es的索引只是一個邏輯概念,實際上是由一個個物理分片組成的,每個分片就是一個lucene實例,我們看到這里有9個分片,也就是有9個lucene實例,所以每個分片都能獨立完成搜索功能,最后由es對結果進行合并。
分片包括主分片shard和副本分片replica,副本分片僅僅是主分片的一個拷貝。
每個分片是分布在不同的節點上的,每啟動一個es實例,就是一個節點:
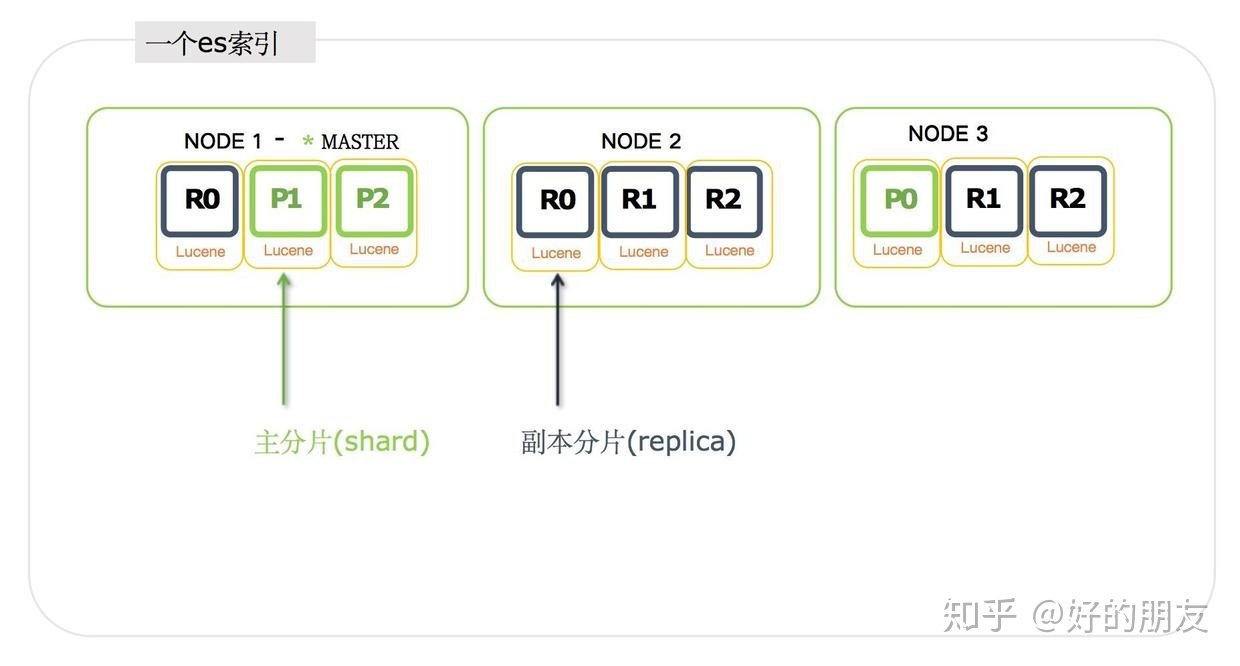
我們看到這里啟動了3個es實例,也就是有3個節點。
我們往es的索引里插入的文檔,首先被插入到主分片里:
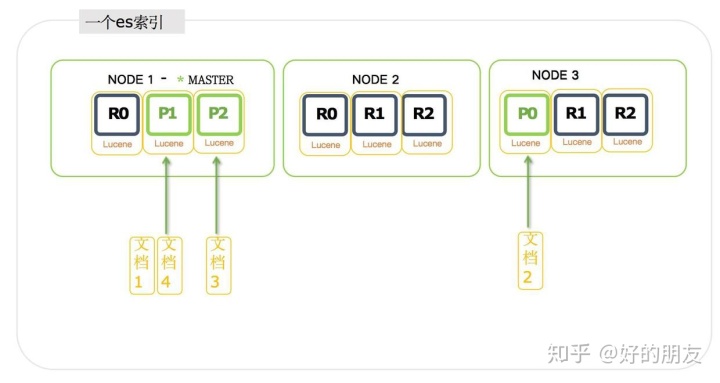
因為每個文檔只能屬于一個主分片,而es默認給索引設置了5個主分片,我們這里畫的是3個主分片,所以這些文檔在插入的時候,就會散列存儲到不同的主分片里,也就是存到lucne實例里, 而lucene實例的內部結構,又是由很多lucene索引組成:
我們建的es索引里的每個字段,就是一個個lucene索引:
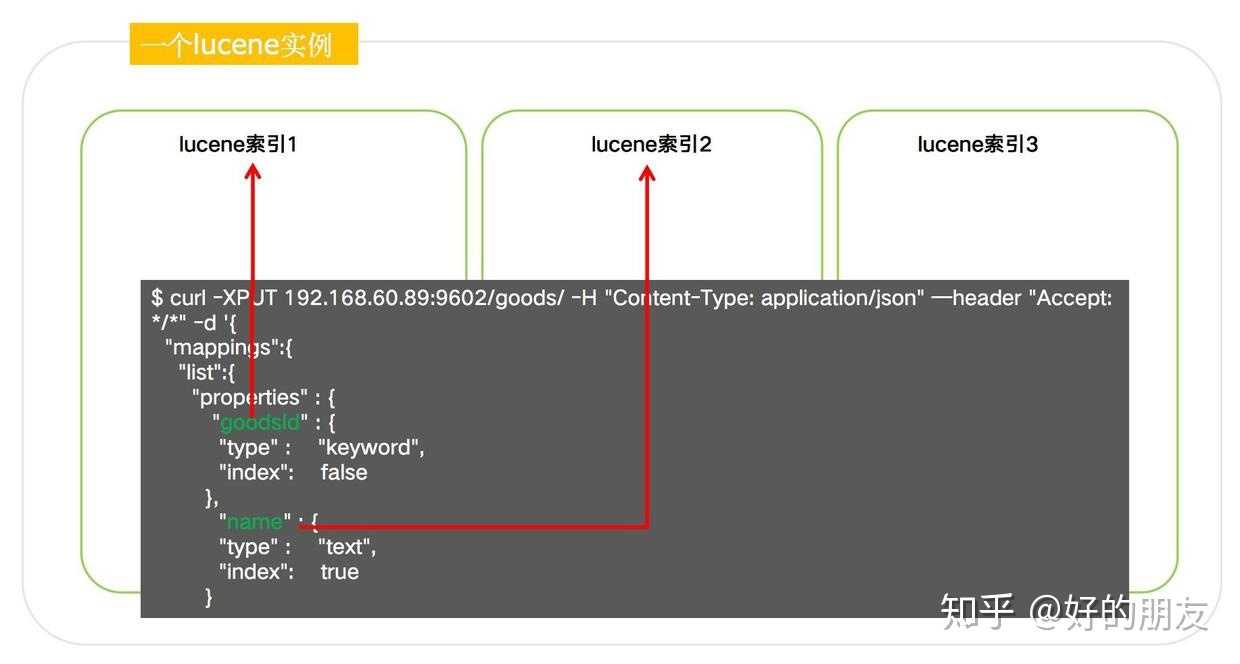
而lucene索引是由一個個segment組成的,每個segment大小是不一樣的,有大有小:
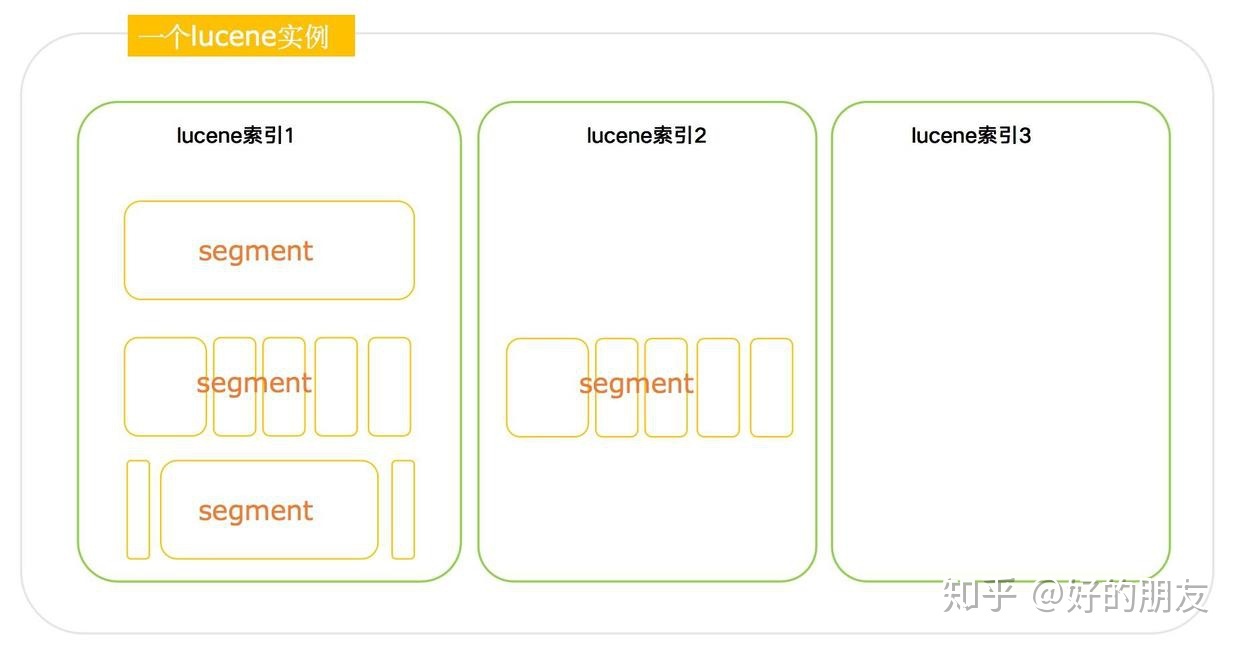
每個segment就是一個包含了一些倒排索引的獨立段:
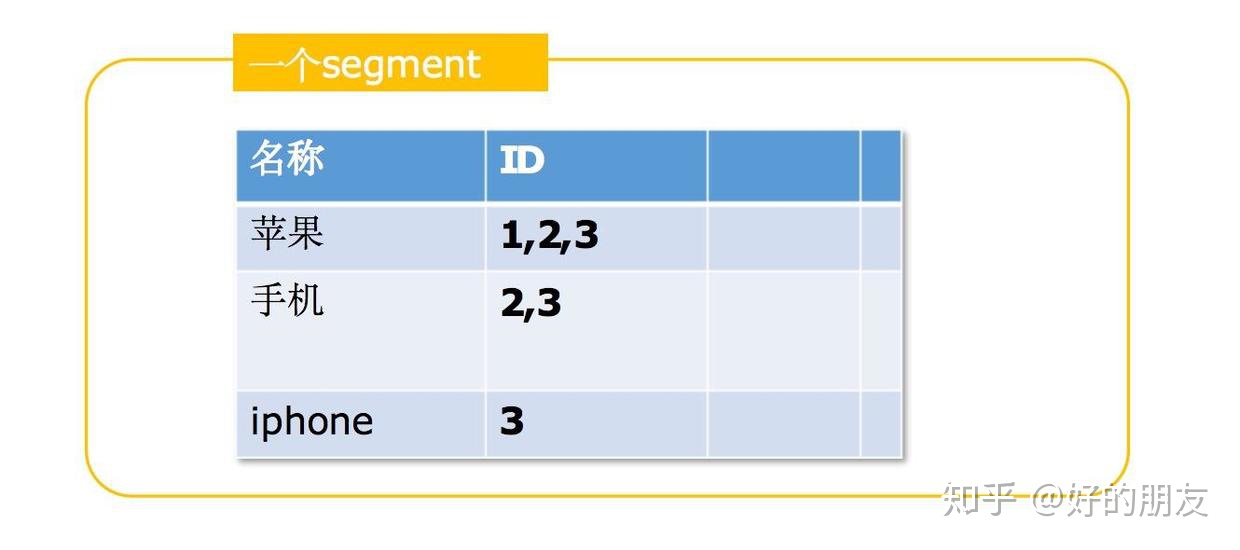
所以,我們在往es插入數據后,最后創建了很多包含了倒排索引的segment段,而搜索的時候,也是從這些segment段里的倒排索引進行搜索的:
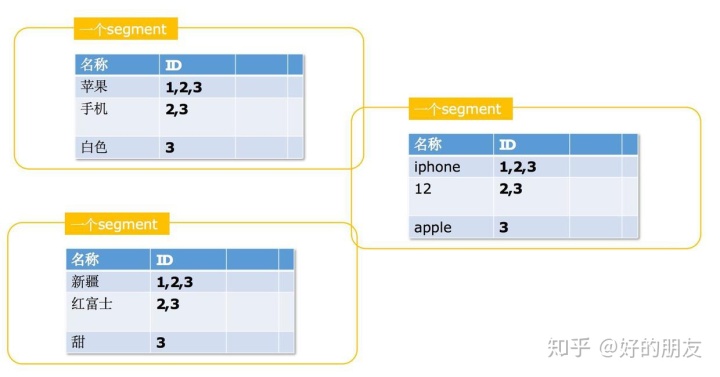
我們看一下整體的示意圖:
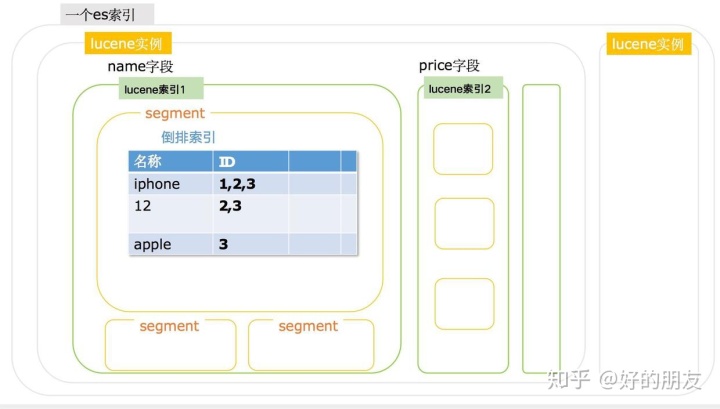
最外層的就是一個es索引,因為索引有很多分片,每個分片就是一個lucene實例, lucene實例里,由lucene索引構成,而每個es索引字段就是一個lucene索引,lucene索引里邊由segment組成,每個segment里邊就是一些倒排索引。
因為倒排索引是搜索引擎的核心,我們簡單介紹一下倒排索引
倒排索引
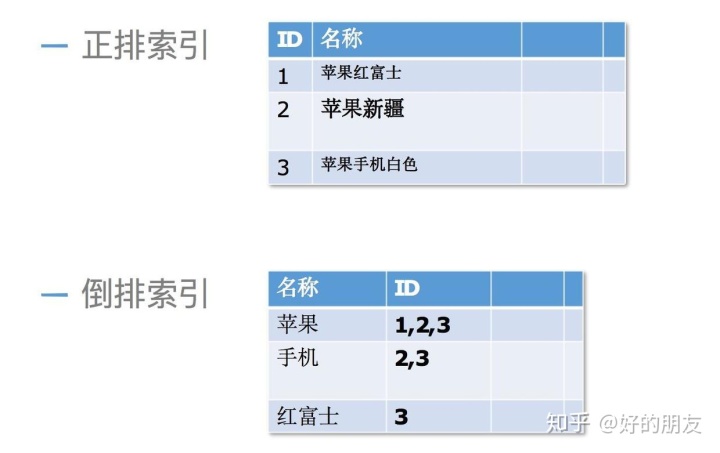
數據庫里的正排索引是這樣存儲的,數據以id為主鍵,然后是名稱字段。這樣雖然通過id獲取數據很快,但是通過名稱搜索就很慢。
而倒排索引是以拆分好的分詞作為主鍵,id放在后邊。這樣如果想用某個關鍵字獲取數據,就可以直接找到對應數據的id,從而獲取到數據。
es在插入數據的時候,除了會構建倒排索引這種存儲結構之外,還會構建另外一種存儲結構,doc values。
Doc values 只支持不需要分詞的字段:

也就是如果字段是text類型,那么就只有倒排索引,而其他類型除了有倒排索引,還會存一個doc values。
doc values大概的結構是這樣的,和數據庫的存儲結構類似:

為什么需要這種格式的數據,因為像聚合操作這種功能,需要使用某個字段來進行分類,這就需要知道這個字段里都有什么內容(包含哪些terms),而倒排索引是把一個字段的內容都打散了存儲的,所以需要使用doc values這種類似數據庫的存儲結構,來進行聚合操作。
這也引出了一個我們需要關注的點,即:聚合操作的字段,不能設置為text類型,因為text類型,沒有doc values。
Next: elasticsearch外用與內觀(三)-當搜索時,elasticsearch都在做什么(上)


)

)


)
:JavaScript圖表庫的比較)


)



)

)

