As a data scientist, you are developing notebooks that process large data that does not fit in your laptop using Spark. What would you do? This is not a trivial problem.
作為數據科學家,您正在開發使用Spark處理筆記本電腦無法容納的大數據的筆記本電腦。 你會怎么做? 這不是一個小問題。
Let’s start with the most naive solution without install anything on your laptop.
讓我們從最簡單的解決方案開始,而不在筆記本電腦上安裝任何東西。
- “No notebook”: SSH into the remote clusters and use Spark shell on the remote cluster. “無筆記本”:SSH進入遠程群集,并在遠程群集上使用Spark Shell。
- “Local notebook”: downsample the data and pull the data to your laptop. “本地筆記本”:對數據進行下采樣并將數據拉到您的筆記本上。
The problem of “No notebook” is the developer experience is unacceptable on Spark shell:
“沒有筆記本”的問題是在Spark shell上無法接受開發人員的體驗:
- You cannot easily change the code and get the result printed like what you have in Jupyter notebook or Zeppelin notebook. 您無法像Jupyter筆記本電腦或Zeppelin筆記本電腦那樣輕松地更改代碼并獲得打印結果。
- It is hard to show images/charts from Shell. 很難顯示來自Shell的圖像/圖表。
- It is painful to do version control by git on a remote machine because you have to set up from the very beginning and make git operations like git diff. 在遠程計算機上通過git進行版本控制很痛苦,因為您必須從一開始就進行設置并進行git diff之類的git操作。
The second option “Local notebook”: You have to downsample the data and pull the data to your laptop (downsample: if you have 100GB data on your clusters, you downsample the data to 1GB without losing too much important information). Then you could process the data on your local Jupyter notebook.
第二個選項“本地筆記本”:您必須對數據進行降采樣并將數據拉至筆記本電腦(降采樣:如果群集上有100GB數據,則可以將數據降采樣為1GB,而不會丟失太多重要信息)。 然后,您可以在本地Jupyter筆記本上處理數據。
it creates a few new painful problems:
它帶來了一些新的痛苦問題:
- You have to write extra code to downsample the data. 您必須編寫額外的代碼才能對數據進行下采樣。
- Downsampling could lose vital information about the data, especially when you are working on visualization or machine learning models. 下采樣可能會丟失有關數據的重要信息,尤其是在使用可視化或機器學習模型時。
- You have to spend extra hours to make sure your code for original data. If not, it takes extra extra hours to figure out what’s wrong. 您必須花費額外的時間來確保原始數據的代碼。 如果不是這樣,則需要花費額外的時間才能找出問題所在。
- You have to guarantee the local development environment is the same as the remote cluster. If not, it is error-prone and it may cause data issues that are hard to detect. 您必須保證本地開發環境與遠程集群相同。 如果不是這樣,則容易出錯,并且可能導致難以檢測的數據問題。
Ok, “No notebook” and “Local notebook” are obviously not the best approach. What if your data team has access to the cloud, e.g. AWS? Yes, AWS provides Jupyter notebook on their EMR clusters and SageMaker. The notebook server is accessed through AWS Web console and it is ready to use when the clusters are ready.
好的,“沒有筆記本”和“本地筆記本”顯然不是最好的方法。 如果您的數據團隊可以訪問云(例如AWS)怎么辦? 是的,AWS在其EMR群集和SageMaker上提供Jupyter筆記本。 筆記本服務器可通過AWS Web控制臺訪問,并且在群集準備就緒后即可使用。
This approach is called “Remote notebook on a cloud”.
這種方法稱為“云上的遠程筆記本”。
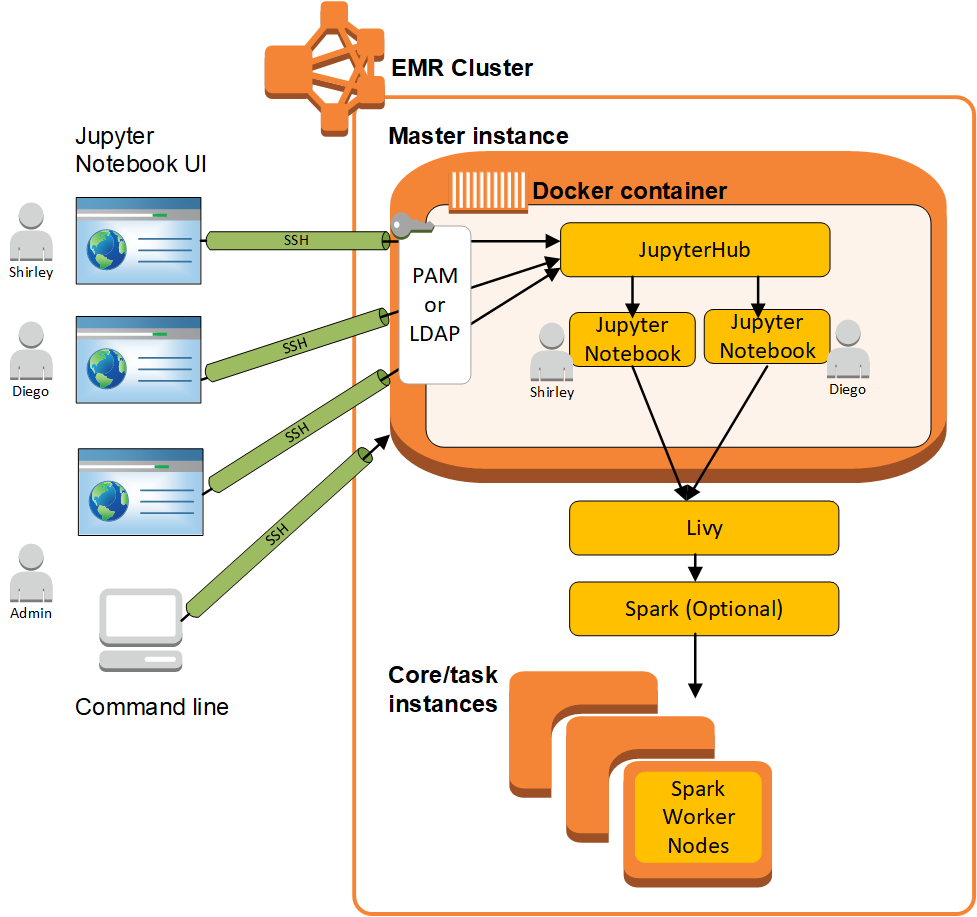
The problems of “remote notebook on the cloud” are
“遠程筆記本在云上”的問題是
- You have to set up your development environment every time the clusters get to spin up. 每次集群啟動時,您都必須設置開發環境。
- If you want your notebook run on different clusters or regions, you have to manually & repeatedly get it done. 如果要讓筆記本在不同的群集或區域上運行,則必須手動重復執行此操作。
- If the clusters are terminated unexpectedly, you lost your work on those clusters. 如果群集意外終止,則您將失去在這些群集上的工作。
This approach, ironically, is the most popular one among the data scientists who have access to AWS. This can be explained by the principle of least effort: It provides one-click access to remote clusters so that data scientists can focus on their machine learning models, visualization, and business impact without spending too much time on clusters.
具有諷刺意味的是,這種方法是可以訪問AWS的數據科學家中最受歡迎的一種。 可以用最少努力的原理來解釋: 一鍵式訪問遠程集群,因此數據科學家可以專注于他們的機器學習模型,可視化和業務影響,而無需在集群上花費太多時間。
Besides “No notebook”, “Local notebook”, and “Remote notebook on Cloud”, there are options that point spark on a laptop to remote spark clusters. The code is submitted via a local notebook and send to a remote spark cluster. This approach is called “Bridge local & remote spark”.
除了“無筆記本”,“本地筆記本”和“云上的遠程筆記本”之外,還有一些選項可將筆記本電腦上的火花指向遠程火花群集。 該代碼通過本地筆記本提交,并發送到遠程Spark集群。 這種方法稱為“橋接本地和遠程火花”。
You can use set the remote master when you create sparkSession
創建sparkSession時可以使用set remote master
val spark = SparkSession.builder()
.appName(“SparkSample”)
.master(“spark://123.456.789:7077”)
.getOrCreate()The problems are
問題是
- you have to figure out how to authenticate your laptop to remote spark clusters. 您必須弄清楚如何對遠程火花群集進行身份驗證。
it only works when Spark is deployed as Standalone not YARN. If your spark cluster is deployed on YARN, then you have to copy the configuration files
/etc/hadoop/confon remote clusters to your laptop and restart your local spark, assuming you have already figured out how to install Spark on your laptop.它僅在將Spark部署為獨立版本而不是YARN時有效。 如果您的Spark集群已部署在YARN上,那么您必須將遠程集群上的配置文件
/etc/hadoop/conf復制到您的筆記本電腦上,然后重新啟動本地spark,前提是您已經弄清楚了如何在筆記本電腦上安裝Spark。
If you have multiple spark clusters, then you have to switch back and forth by copy configuration files. If the clusters are ephemeral on Cloud, then it easily becomes a nightmare.
如果您有多個Spark集群,則必須通過復制配置文件來回切換。 如果集群是短暫的,那么它很容易成為噩夢。
“Bridge local & remote spark” does not work for most of the data scientists. Luckily, we can switch back our attention to Jupyter notebook. There is a Jupyter notebook kernel called “Sparkmagic” which can send your code to a remote cluster with the assumption that Livy is installed on the remote spark clusters. This assumption is met for all cloud providers and it is not hard to install on in-house spark clusters with the help of Apache Ambari.
“橋接本地和遠程火花”不適用于大多數數據科學家。 幸運的是,我們可以將注意力轉移到Jupyter筆記本上。 有一個名為“ Sparkmagic”的Jupyter筆記本內核,可以將Livy安裝在遠程Spark群集上,從而將您的代碼發送到遠程群集。 所有云提供商均滿足此假設,并且在Apache Ambari的幫助下將其安裝在內部Spark集群上并不困難。
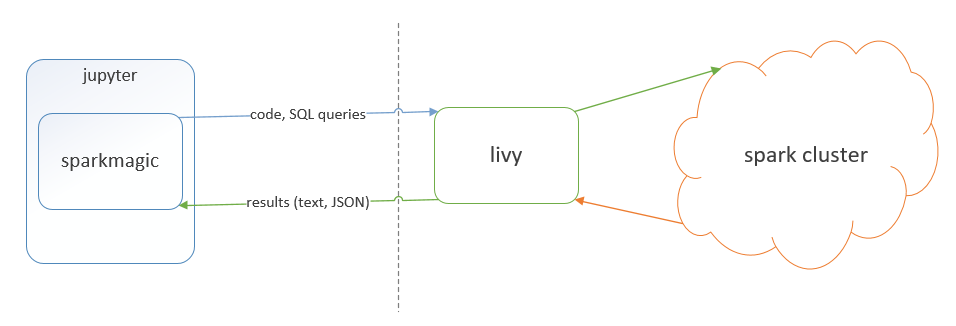
It seems “Sparkmagic” is the best solution at this point but why it is not the most popular one. There are 2 reasons:
目前看來,“ Sparkmagic”是最好的解決方案,但為什么它不是最受歡迎的解決方案。 有兩個原因:
- Many data scientists have not heard of “Sparkmagic”. 許多數據科學家還沒有聽說過“ Sparkmagic”。
- There are installation, connection, and authentication issues that are hard for data scientists to fix. 存在安裝,連接和身份驗證問題,數據科學家很難修復。
To solve problem 2, sparkmagic introduces Docker containers that are ready to use. Docker container, indeed, has solved some of the issues in installation, but it also introduces new problems for data scientists:
為了解決問題2,sparkmagic引入了可立即使用的Docker容器。 Docker容器確實解決了安裝中的一些問題,但是它也為數據科學家帶來了新的問題:
- Designed for shipping applications, the learning curve of docker container is not considered friendly for data scientists. Docker容器的學習曲線專為運輸應用而設計,對數據科學家而言并不友好。
- It is not designed to used intuitively for data scientists who come from diverse technical backgrounds. 它并不是為具有不同技術背景的數據科學家而直觀地使用的。
The discussion of docker containers will stop here and another article that explains how to make Docker containers actually work for data scientists will be published in a few days.
關于Docker容器的討論將在這里停止,另一篇文章將解釋如何使Docker容器真正為數據科學家服務,將在幾天后發布。
To summarize, we have two categories of solutions:
總而言之,我們有兩種解決方案:
- Notebook & notebook kernel: “No notebook”, “Local notebook”, “Remote notebook on cloud”, “Sparkmagic” 筆記本和筆記本內核:“無筆記本”,“本地筆記本”,“云上的遠程筆記本”,“ Sparkmagic”
- Spark itself: “Bridge local & remote spark”. Spark本身:“橋接本地和遠程火花”。
Despite installation and connection issues, “Sparkmagic” is the recommended solution. However, there are often other unsolved issues that reduce productivity and hurt developer experience:
盡管存在安裝和連接問題,但建議使用“ Sparkmagic”解決方案。 但是,通常還有其他未解決的問題會降低生產率并損害開發人員的經驗:
- What if other languages, python and R, are required to run on clusters? 如果要求其他語言python和R在群集上運行怎么辦?
- What if the notebook is going to be run everyday? What if the notebook is going to be run only if another notebook run succeed? 如果筆記本要每天運行怎么辦? 如果僅在另一個筆記本運行成功的情況下才要運行筆記本怎么辦?
Let’s go over the current solutions:
讓我們來看一下當前的解決方案:
Set up a remote Jupyter server and SSH tunneling (Reference). This definitely works but it takes time to set it up, and notebooks are on the remote servers.
設置遠程Jupyter服務器和SSH隧道(R eference )。 絕對可以,但是設置起來很費時間,并且筆記本在遠程服務器上。
- Set up a cron scheduler. Most data scientists are OK with cron scheduler, but what if the notebook failed to run? Yes, a shell script can help but are the most majority of data scientists comfortable writing shell script? Even if the answer is yes, data scientists have to 1. get access to finished notebook 2. to get a status update. Even if there are data scientists that are happy with writing shell scripts, why should every data scientist write their own scripts to automate the exact same stuff? 設置一個cron調度程序。 大多數數據科學家都可以使用cron計劃程序,但是如果筆記本無法運行怎么辦? 是的,shell腳本可以提供幫助,但是大多數數據科學家是否愿意編寫shell腳本? 即使答案是肯定的,數據科學家也必須1.可以訪問完成的筆記本電腦2.可以獲取狀態更新。 即使有些數據科學家對編寫Shell腳本感到滿意,但為什么每個數據科學家都應該編寫自己的腳本來自動化完全相同的東西呢?
- Set up Airflow. This is a very popular solution among data engineers and it can get stuff done. If there are Airflow servers supported by data engineers or data platform engineers, data scientists can manage to learn the operators of Airflow and get it to work for Jupyter Notebook. 設置氣流。 這是數據工程師中非常流行的解決方案,它可以完成工作。 如果有數據工程師或數據平臺工程師支持的Airflow服務器,則數據科學家可以設法學習Airflow的操作員,并使它適用于Jupyter Notebook。
- Set up Kubeflow and other Kubernetes-based solutions. Admittedly kubeflow can get stuff done, but in reality how many data scientists have access to Kubernetes clusters, including managed solutions running on the cloud? 設置Kubeflow和其他基于Kubernetes的解決方案。 誠然,kubeflow可以完成工作,但實際上有多少數據科學家可以訪問Kubernetes集群,包括在云上運行的托管解決方案?
Let’s reframe the problems:
讓我們重新構造問題:
- How to develop on the local laptop with access to remote clusters? 如何在可訪問遠程群集的本地筆記本電腦上進行開發?
- How to operate on the remote clusters? 如何在遠程集群上運行?
The solutions implemented by Bayesnote (a new open source Notebook project https://github.com/Bayesnote/Bayesnote) follows this principle:
Bayesnote(一個新的開源Notebook項目https://github.com/Bayesnote/Bayesnote )實現的解決方案遵循以下原則:
- “Auto installation, not manual”: Data scientists should not waste their time on installing anything on remote servers. “自動安裝,而不是手動”:數據科學家不應浪費時間在遠程服務器上安裝任何東西。
- “Local notebook, not remote notebooks”: local notebooks makes better development experience and makes version control easier. “本地筆記本,而不是遠程筆記本”:本地筆記本可提供更好的開發體驗,并使版本控制更加容易。
- “Works for everyone, not someone”: assuming data scientists have no access to help from the engineering team. Works for data scientists come from diverse technical backgrounds. “為所有人服務,而不是為每個人服務”:假設數據科學家無法獲得工程團隊的幫助。 數據科學家的作品來自不同的技術背景。
- “Works for every language/framework”. Works for any languages, python, SQL, R, and Spark, etc. “適用于每種語言/框架”。 適用于任何語言,python,SQL,R和Spark等。
- “Combining development and operation, not separate them”: development and operations of a notebook can be done in one place. Data scientists should not spend time on fix issues in the disparity of development and operation “將開發和操作結合在一起,而不是將它們分開”:筆記本的開發和操作可以在一個地方完成。 數據科學家不應將時間花在解決開發和運營差異方面的修復問題上
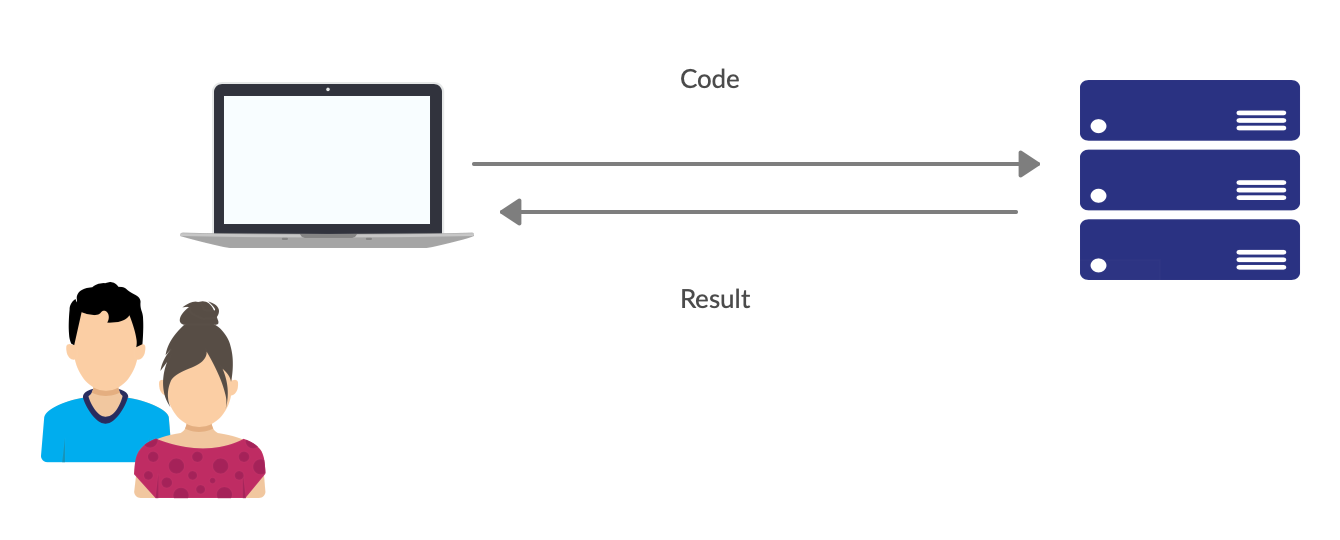
These ideas are implemented by feature “auto self-deployment” of Bayesnote. In the development phase, the only required input from data scientists is authentication information, like IP and password. Then Bayesnote deploys itself to remote servers and started to listen for socket messages. The code will be sent to a remote server and get results back for users.
這些想法是通過Bayesnote的功能“自動自我部署”實現的。 在開發階段,數據科學家唯一需要的輸入就是身份驗證信息,例如IP和密碼。 然后,Bayesnote將自己部署到遠程服務器,并開始偵聽套接字消息。 該代碼將被發送到遠程服務器,并為用戶返回結果。
In the operation phase, a YAML file is specified and Bayesnote would run notebooks on remote servers, get finished notebooks back, and send a status update to emails or slack.
在操作階段,將指定一個YAML文件,并且Bayesnote將在遠程服務器上運行筆記本,取回已??完成的筆記本,并將狀態更新發送到電子郵件或備用服務器。
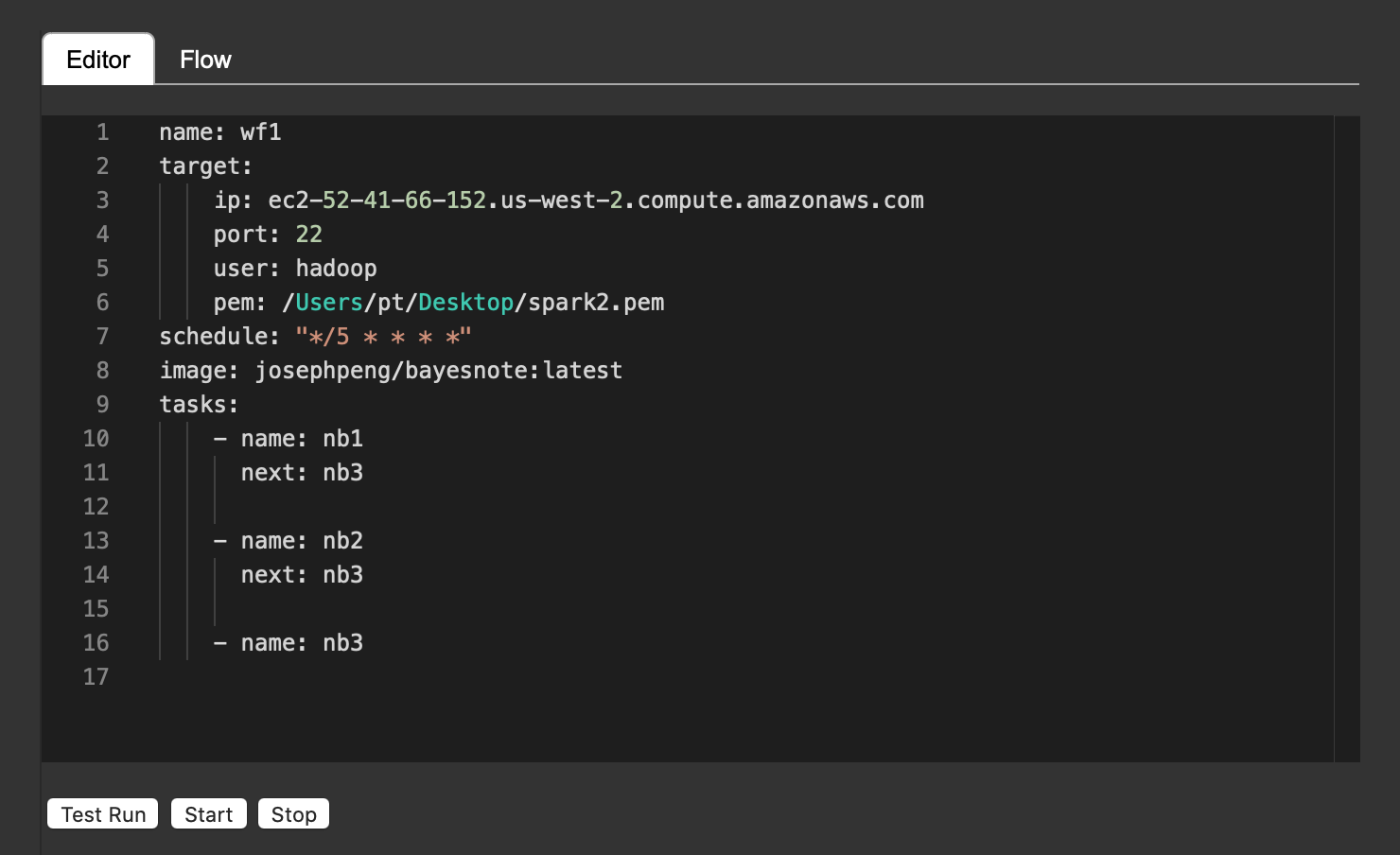
(Users will configure by filling out forms rather than YAML files, and the dependency of notebooks will be visualized nicely. )
(用戶將通過填寫表單(而不是YAML文件)進行配置,并且筆記本的依賴關系將得到很好的可視化。)
The (partial) implementation can be found on Github. https://github.com/Bayesnote/Bayesnote
可以在Github上找到(部分)實現。 https://github.com/Bayesnote/Bayesnote
Free data scientists from tooling issues so they can be happy and productive in their jobs.
使數據科學家從工具問題中解放出來,使他們在工作中感到快樂和高效率。
翻譯自: https://towardsdatascience.com/how-to-connect-jupyter-notebook-to-remote-spark-clusters-and-run-spark-jobs-every-day-2c5a0c1b61df
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392173.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392173.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392173.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

是銀彈嗎?業務基線方法論

linux core無權限,linux – 為什么編輯core_pattern受限制?

nsa構架_我如何使用NSA的Ghidra解決了一個簡單的CrackMe挑戰
)
分布與并行計算—生產者消費者模型隊列(Java)

python 日志內容提取

同一服務器部署多個tomcat時的端口號修改詳情
.doc)
linux優盤驅動目錄,Linux U盤加載陣列卡驅動步驟(.dd或img).doc

第一章-從雙向鏈表學習設計

twitter 數據集處理_Twitter數據清理和數據科學預處理

ios 動態化視圖_如何在iOS應用中使高度收集視圖動態化


思維導圖分析http之http協議版本
)
分布與并行計算—生產者消費者模型RabbitMQ(Java)

飛騰 linux 內核,FT2004-Xenomai

使用管道符組合使用命令_如何使用管道的魔力

關于網頁授權的兩種scope的區別說明

安卓流行布局開源庫_如何使用流行度在開源庫之間進行選擇
 協議概述)

window 下分linux分區,如何在windows9x下訪問linux分區
)