Scrapy框架安裝
1、首先,終端執行命令升級pip: python -m pip install --upgrade pip
2、安裝,wheel(建議網絡安裝) pip install wheel
3、安裝,lxml(建議下載安裝)
4、安裝,Twisted(建議下載安裝)
5、安裝,Scrapy(建議網絡安裝) pip install Scrapy
測試Scrapy是否安裝成功
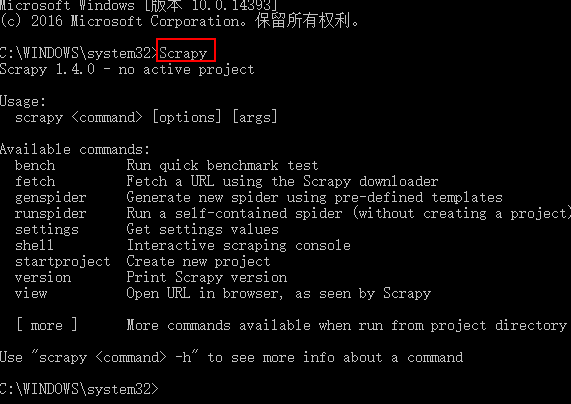
?
Scrapy框架指令
scrapy -h ?查看幫助信息
Available commands:
bench Run quick benchmark test?(scrapy bench??硬件測試指令,可以測試當前服務器每分鐘最多能爬多少個頁面)
fetch ? Fetch a URL using the Scrapy downloader?(scrapy fetch http://www.iqiyi.com/??獲取一個網頁html源碼)
genspider ??Generate new spider using pre-defined templates ()
runspider Run a self-contained spider (without creating a project) ()
settings ??Get settings values ()
shell Interactive scraping console ()
startproject Create new project?(cd 進入要創建項目的目錄,scrapy startproject 項目名稱?,創建scrapy項目)?
version ? Print Scrapy version ()
view ? ?Open URL in browser, as seen by Scrapy ()
?
創建項目以及項目說明
scrapy startproject adc ?創建項目
項目說明
目錄結構如下:
├── firstCrawler
│?? ├── __init__.py
│?? ├── items.py
│?? ├── middlewares.py
│?? ├── pipelines.py
│?? ├── settings.py
│?? └── spiders
│?? ? ? └── __init__.py
└── scrapy.cfg
scrapy.cfg: 項目的配置文件tems.py: 項目中的item文件,用來定義解析對象對應的屬性或字段。pipelines.py:?負責處理被spider提取出來的item。典型的處理有清理、 驗證及持久化(例如存取到數據庫)settings.py: 項目的設置文件.- spiders:實現自定義爬蟲的目錄
- middlewares.py:Spider中間件是在引擎及Spider之間的特定鉤子(specific hook),處理spider的輸入(response)和輸出(items及requests)。 其提供了一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能。
 ?
?
?
項目指令
項目指令是需要cd進入項目目錄執行的指令
scrapy -h ?項目指令幫助
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl ?? Run a spider
edit ?? Edit spider
fetch ?Fetch a URL using the Scrapy downloader
genspider ? Generate new spider using pre-defined templates
list ?List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings ? ?Get settings values
shell Interactive scraping console
startproject ?Create new project
version ? ? ?Print Scrapy version?(scrapy version??查看scrapy版本信息)
view ? Open URL in browser, as seen by Scrapy?(scrapy view http://www.zhimaruanjian.com/??下載一個網頁并打開)
?
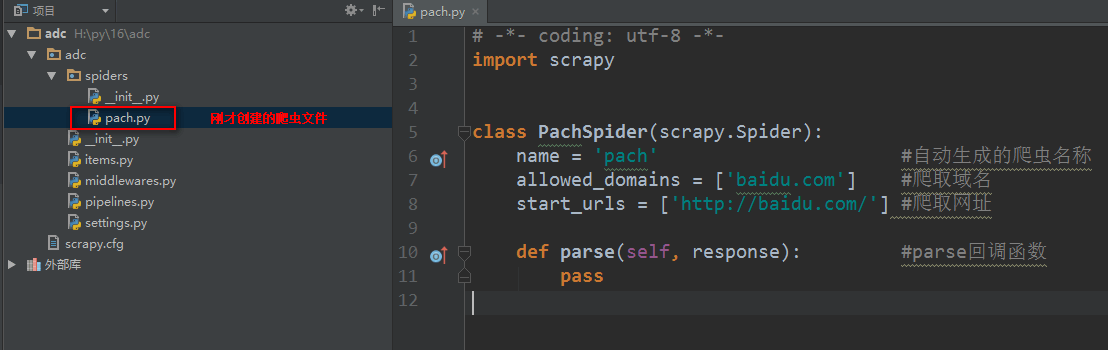
創建爬蟲文件
創建爬蟲文件是根據scrapy的母版來創建爬蟲文件的
scrapy genspider -l??查看scrapy創建爬蟲文件可用的母版
Available templates:母版說明
basic ? ? 創建基礎爬蟲文件
crawl ? ?創建自動爬蟲文件
csvfeed ? ? ?創建爬取csv數據爬蟲文件
xmlfeed ?創建爬取xml數據爬蟲文件
創建一個基礎母版爬蟲,其他同理
scrapy genspider ?-t ?母版名稱 ?爬蟲文件名稱 ?要爬取的域名?創建一個基礎母版爬蟲,其他同理
如:scrapy genspider ?-t ?basic ?pach ?baidu.com
?
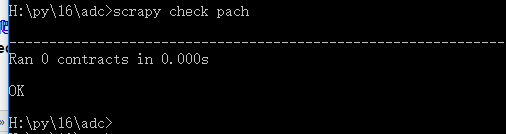
scrapy check 爬蟲文件名稱?測試一個爬蟲文件是否合規
如:scrapy check pach
?
?
scrapy crawl 爬蟲名稱??執行爬蟲文件,顯示日志 【重點】
scrapy crawl 爬蟲名稱 --nolog??執行爬蟲文件,不顯示日志【重點】
?






命令中文手冊)











)
