系統分析:
一般的抽象系統,如社會系統,經濟系統,農業系統,生態系統,教育系統等都包含有許多種因素,多種因素共同作用的結果決定了該系統的發展態勢。人們常常希望知道在眾多的因素中,哪些是主要因素,哪些是次要因素;哪些因素對系統發展影響大,哪些因素對系統發展影響小;那些因素對系統發展起推動作用需強化發展;那些因素對系統發展起阻礙作用需加以抑制;……這些都是系統分析中人們普遍關心的問題。例如,糧食生產系統,人們希望提高糧食總產量,而影響糧食總產量的因素是多方面的,有播種面積以及水利,化肥,土壤,種子,勞力,氣候,耕作技術和政策環境等。為了實現少投入多產出,并取得良好的經濟效益,社會效益和生態效益,就必須進行系統分析。
數理統計的不足之處:
灰色關聯的基本思想:
灰色關聯分析原理:灰色關聯分析(Grey Relational Analysis)是一種用于研究變量之間關聯性的方法,特別適用于樣本數據較少、樣本特征缺失或數據質量不高的情況下。它是由灰色系統理論發展而來,旨在分析和描述變量之間的關聯程度。
在灰色關聯分析中,首先將各個變量的數據進行數值化,常采用標準化或歸一化的方法,將變量的取值范圍轉化為[0, 1]之間。然后,通過計算變量之間的關聯度,確定它們之間的關聯程度。
灰色關聯分析的步驟主要包括以下幾個方面:
1.數據標準化:將原始數據進行標準化處理,通常采用歸一化或標準化方法,使得各個變量具有相同的數值范圍。
2.構建關聯系數矩陣:計算各個變量之間的關聯系數,一般采用灰色關聯度或灰色斜率關聯度。關聯系數表示了變量之間的相對關聯程度。
3.確定關聯度序列:根據計算得到的關聯系數,確定關聯度序列,即將各個變量按照關聯度的大小排序。
4.確定關聯度權重:根據關聯度序列,計算關聯度權重,即各個變量在總關聯系數中的貢獻比例。
5.計算灰色關聯度:通過將各個變量的關聯系數與關聯度權重相乘,并進行累加,計算出灰色關聯度。灰色關聯度可以反映變量之間的關聯程度。
通過灰色關聯度的計算,可以得到各個變量之間的關聯情況,進而進行數據分析和決策支持。灰色關聯分析常被應用于多個領域,包括經濟、管理、環境、工程等,用于評估指標之間的關聯強度、尋找關鍵因素等。
需要注意的是,灰色關聯分析的結果是相對的,不具備精確的定量意義,應結合實際問題和其他分析方法進行綜合評估和判斷。
例題以及Excel的實操: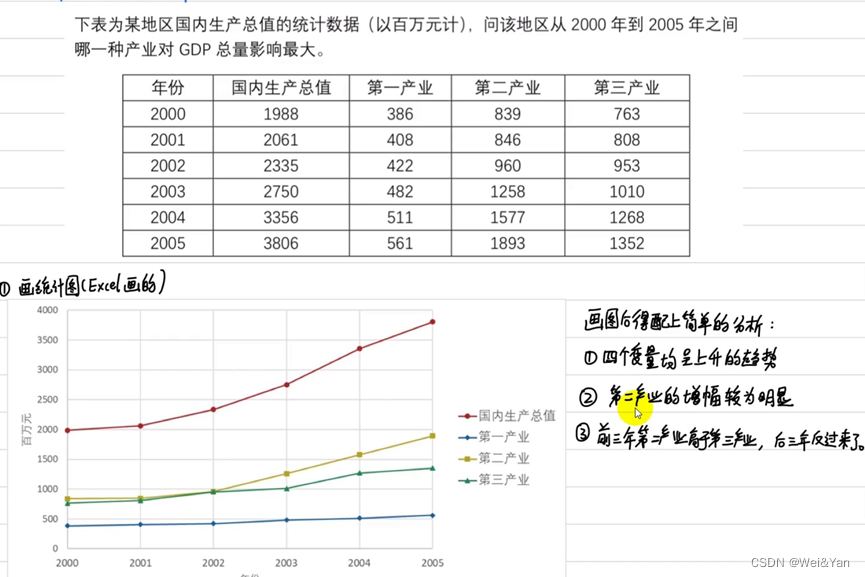 在excel中選擇數據-插入-推薦圖標-修改信息。
在excel中選擇數據-插入-推薦圖標-修改信息。
2.確定分析數列:
母序列:能反映系統特征值的數據序列,類似于因變量Y,此處記為X0
子序列:有影響系統行為的因素組成的數據序列。類似于自變量x,此處記為(x1,x2……xm)
3.對變量進行預處理:
目的:去量綱,縮小變量范圍簡化計算。
方法:每個元素/所在列的列向量的均值。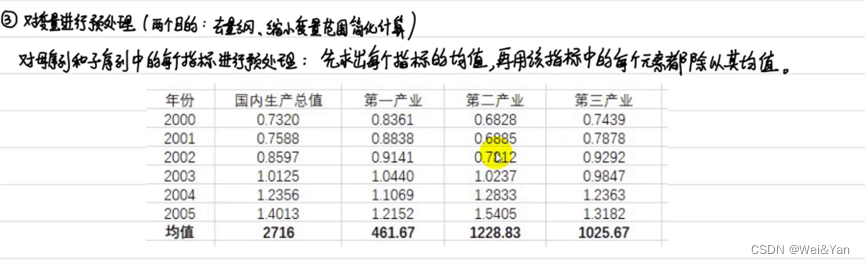
4.計算子序列中各個指標與母序列的關聯系數
先求每子列元素與母列之間差的絕對值,在求出矩陣中所有元素的最小值a和最大值b。且取分辨系數p/rho=0.5
在通過公式計算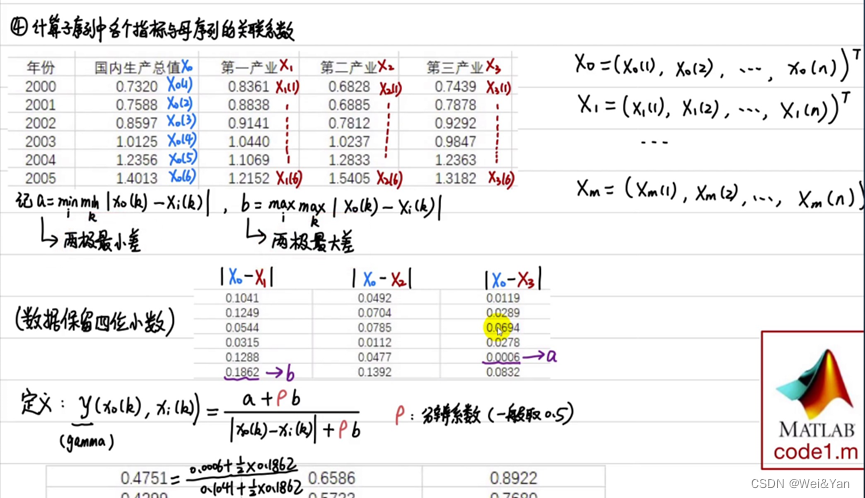
5.求灰色關聯度:
公式:每列子序列與母序列關聯系數的均值。
6.分析結果進行總結。
MATLAB代碼實現:
參考代碼:
%% 灰色關聯分析用于系統分析例題的講解
clear;clc
load gdp.mat % 導入數據 一個6*4的矩陣
% 不會導入數據的同學可以看看第二講topsis模型,我們也可以自己在工作區新建變量,并把Excel的數據粘貼過來
% 注意Matlab的當前文件夾一定要切換到有數據文件的這個文件夾內
Mean = mean(gdp); % 求出每一列的均值以供后續的數據預處理
gdp = gdp ./ repmat(Mean,size(gdp,1),1); %size(gdp,1)=6, repmat(Mean,6,1)可以將矩陣進行復制,復制為和gdp同等大小,然后使用點除(對應元素相除),這些在第一講層次分析法都講過
disp('預處理后的矩陣為:'); disp(gdp)
Y = gdp(:,1); % 母序列
X = gdp(:,2:end); % 子序列
absX0_Xi = abs(X - repmat(Y,1,size(X,2))) % 計算|X0-Xi|矩陣(在這里我們把X0定義為了Y)
a = min(min(absX0_Xi)) % 計算兩級最小差a
b = max(max(absX0_Xi)) % 計算兩級最大差b
rho = 0.5; % 分辨系數取0.5
gamma = (a+rho*b) ./ (absX0_Xi + rho*b) % 計算子序列中各個指標與母序列的關聯系數
disp('子序列中各個指標的灰色關聯度分別為:')
disp(mean(gamma))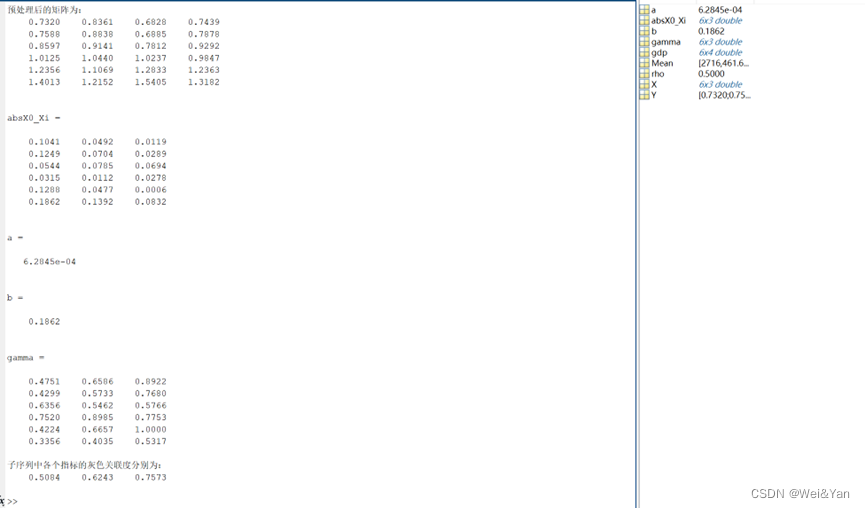
討論:
灰色分析用于綜合評價問題: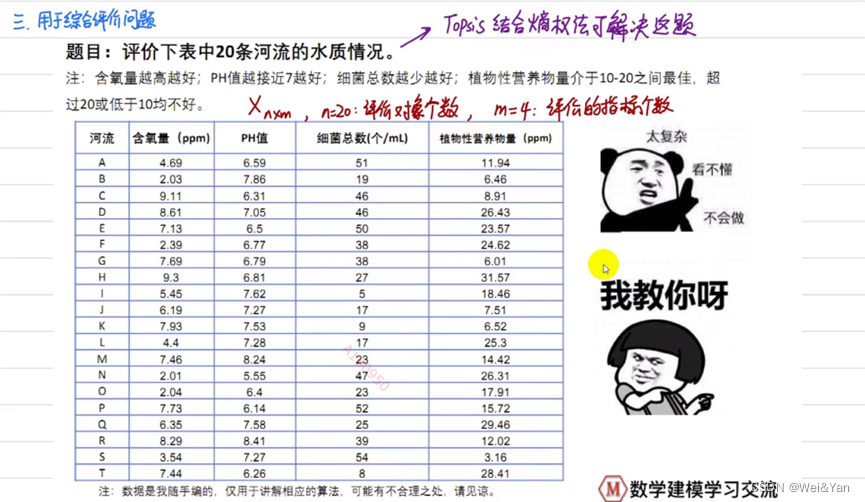
步驟:
MATLAB代碼實現:
這里的代碼和博主之前TOPSIS算法一文:數學建模——TOPSIS法_Wei&Yan的博客-CSDN博客
前面的操作都一致,只是在最后添加上了灰色相關分析的方法
步驟:
- 先對矩陣進行預處理:每個元素/所在列的均值
- 構造母序列和子序列
母序列:取每一行的max構成一個列向量
子序列:預處理后的矩陣
3.計算灰色關聯度
先求每個元素與母序列差的絕對值矩陣,再求兩級最大/小差。
最后利用公式求灰色關聯度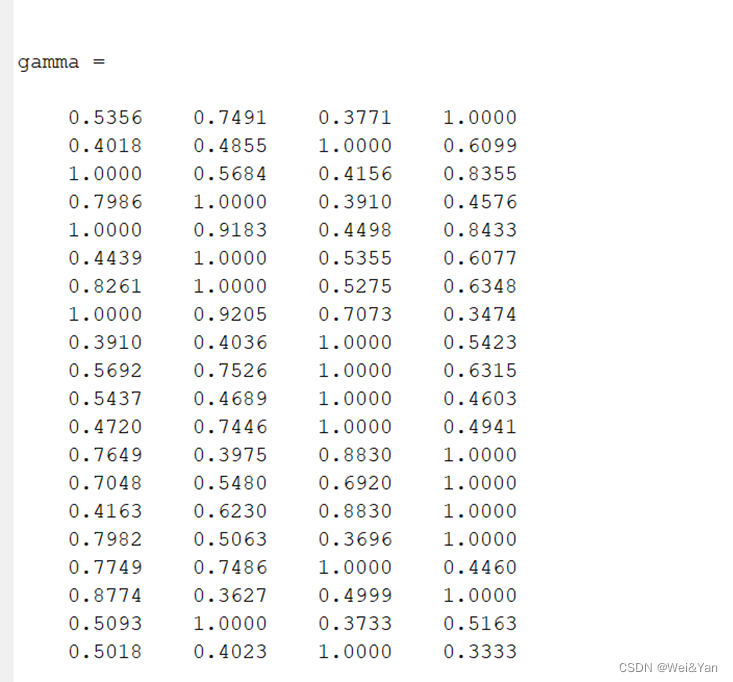
4.求權重:每列的均值/每列均值的和
5.求得分:(矩陣中每個元素*其所在列的權重)的矩陣的列和。(得到一個)
6.歸一化得分:每個元素/向量和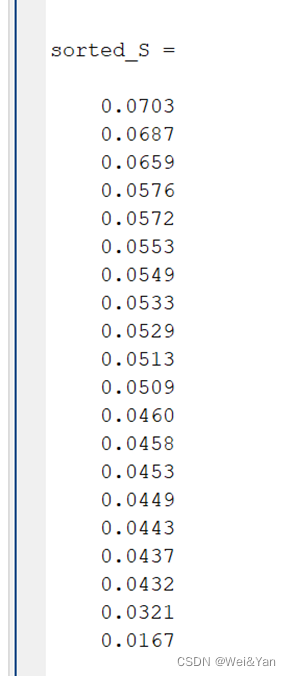
圖形對比: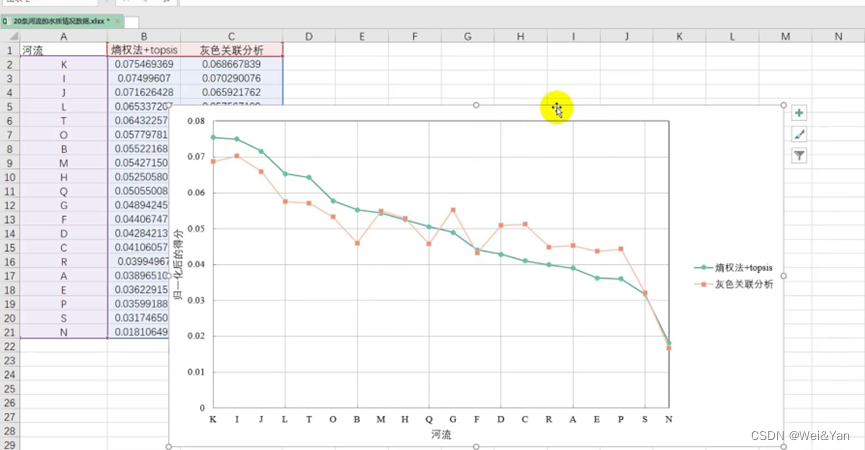
參考代碼:
這里只參考了主函數加上帶有灰色相關分析的代碼,其他自定義函數可參考博主原來的文章TOPSIS算法:數學建模——TOPSIS法_Wei&Yan的博客-CSDN博客
%% 灰色關聯分析用于綜合評價模型例題的講解
clear;clc
load data_water_quality.mat
% 不會導入數據的同學可以看看第二講topsis模型,我們也可以自己在工作區新建變量,并把Excel的數據粘貼過來
% 注意Matlab的當前文件夾一定要切換到有數據文件的這個文件夾內%% 判斷是否需要正向化
[n,m] = size(X);
disp(['共有' num2str(n) '個評價對象, ' num2str(m) '個評價指標'])
Judge = input(['這' num2str(m) '個指標是否需要經過正向化處理,需要請輸入1 ,不需要輸入0: ']); %1if Judge == 1Position = input('請輸入需要正向化處理的指標所在的列,例如第2、3、6三列需要處理,那么你需要輸入[2,3,6]: '); %[2,3,4]disp('請輸入需要處理的這些列的指 標類型(1:極小型, 2:中間型, 3:區間型) ')Type = input('例如:第2列是極小型,第3列是區間型,第6列是中間型,就輸入[1,3,2]: '); %[2,1,3]% 注意,Position和Type是兩個同維度的行向量for i = 1 : size(Position,2) %這里需要對這些列分別處理,因此我們需要知道一共要處理的次數,即循環的次數X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));% Positivization是我們自己定義的函數,其作用是進行正向化,其一共接收三個參數% 第一個參數是要正向化處理的那一列向量 X(:,Position(i)) 回顧上一講的知識,X(:,n)表示取第n列的全部元素% 第二個參數是對應的這一列的指標類型(1:極小型, 2:中間型, 3:區間型)% 第三個參數是告訴函數我們正在處理的是原始矩陣中的哪一列% 該函數有一個返回值,它返回正向化之后的指標,我們可以將其直接賦值給我們原始要處理的那一列向量enddisp('正向化后的矩陣 X = ')disp(X)
end%% 對正向化后的矩陣進行預處理
Mean = mean(X); % 求出每一列的均值以供后續的數據預處理
Z = X ./ repmat(Mean,size(X,1),1);
disp('預處理后的矩陣為:'); disp(Z)%% 構造母序列和子序列
Y = max(Z,[],2); % 母序列為虛擬的,用每一行的最大值構成的列向量表示母序列
X = Z; % 子序列就是預處理后的數據矩陣%% 計算得分
absX0_Xi = abs(X - repmat(Y,1,size(X,2))) % 計算|X0-Xi|矩陣
a = min(min(absX0_Xi)) % 計算兩級最小差a
b = max(max(absX0_Xi)) % 計算兩級最大差b
rho = 0.5; % 分辨系數取0.5
gamma = (a+rho*b) ./ (absX0_Xi + rho*b) % 計算子序列中各個指標與母序列的關聯系數
weight = mean(gamma) / sum(mean(gamma)); % 利用子序列中各個指標的灰色關聯度計算權重
score = sum(X .* repmat(weight,size(X,1),1),2); % 未歸一化的得分
stand_S = score / sum(score); % 歸一化后的得分
[sorted_S,index] = sort(stand_S ,'descend') % 進行排序







![任我行CRM系統存在 SQL注入漏洞[2023-HW]](http://pic.xiahunao.cn/任我行CRM系統存在 SQL注入漏洞[2023-HW])
數據類型(接口和對象類型、數組類型))





)



