什么是LCA?
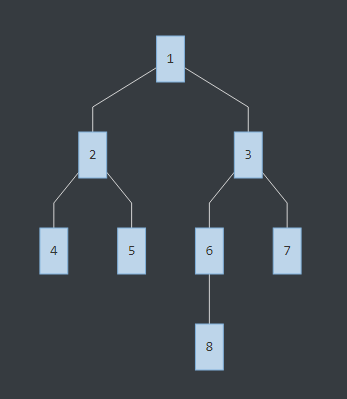
樹中節點8和7的LCA為3,節點4和7的LCA為1,節點5和2的LCA為2。
*可以寫成LCA(u,v)=w的形式
LCA的求法
問題:給出一棵有n(n≤500000)個節點的樹,并給出m(m≤500000)個詢問,每個詢問給出兩個點u,v,請你求出每個u,v的LCA。
1.向上標記法
首先根據定義來。LCA(u,v)是兩個點的祖先鏈的第一個交點(從下往上第一個)。那么我們可以先從u開始往根節點走,那么走到的點都是u的祖先,走出的路徑就是u的祖先鏈。那么我們在走的時候把祖先鏈上的點都標記一下,再從v開始往根節點走,走到的第一個被標記過的點就是LCA了。最壞的情況下時間復雜度為O(n),總共就是O(n*m)。顯然不能滿足題目的需要~
2.樹上倍增法
一個一個地跳顯然太慢,不如加加速?怎么加速呢?根據一貫套路,慢了就倍增~為什么這里不倍增呢?那就倍增一下咯~
樹上倍增的思路不同于標記的思路,因為倍增的時候是無法標記的。反正跳得快,就干脆讓u,v都跳一跳,跳到同一個點時就到了LCA了。不過不是一上來就一起跳的,樹上倍增的預處理可是很浩大的。
首先預處理出倍增之后跳到的點是誰。設f(i,j)為節點i往上跳2^j步到達的節點,那么
f(i,j)=f(f(i,j-1),j-1)?
初始化f(i,0)=fa(i),即i的父親。(剛才那里真的是零......)
設d(i)為i的深度,順便把這貨也處理出來(這么簡單就不講了)。
弄了這么多之后還不能直接兩個點倍增。首先需要將深度大的那個點(假設是v)往上倍增到和u深度相同為止。基于二進制轉化的思想,任何樹都可以用二進制表示出來,所以絕對是可以倍增到同一深度的。
接著,兩個點同時倍增。經過若干次倍增之后,若fa(u)==fa(v),那么fa(u)就是LCA了。
放上預處理的代碼:
xxxxxxxxxx
inline void bfs(){
? ?q.push(s);
? ?d[s] = 1;
? ?while(!q.empty()){
? ? ? ?int u = q.front(); q.pop();
? ? ? ?for(int i = head[u]; ~i; i = e[i].next){
? ? ? ? ? ?int v = e[i].to;
? ? ? ? ? ?if(d[v]) continue;
? ? ? ? ? ?d[v] = d[u] + 1,f[v][0] = u;
? ? ? ? ? ?for(int j = 1; j <= t; j++) f[v][j] = f[f[v][j - 1]][j - 1];
? ? ? ? ? ?q.push(v);
? ? ? }
? }
}
?
//在main函數中 t = (int)(log(n) / log(2)) + 1;
bfs(); 以及倍增的代碼:
xxxxxxxxxx
inline int lca(int &u, int &v){
? ?if(d[u] > d[v]) swap(u, v);
? ?for(int i = t; i >= 0; i--) if(d[f[v][i]] >= d[u]){
? ? ? ?v = f[v][i];
? }
? ?if(u == v) return u;
? ?for(int i = t; i >= 0; i--) if(f[u][i] != f[v][i]){
? ? ? ?u = f[u][i];
? ? ? ?v = f[v][i];
? }
? ?return f[u][0];
}
*一般數組會開成這樣:
xxxxxxxxxx
int f[maxn][20];
這樣一般就夠用了。
預處理的復雜度為O(nlogn),每個詢問的復雜度為O(logn),一共就是O((n+m)logn),可以跑過題目的數據。
3.Tarjan
不同于倍增,Tarjan是一種離線算法,并且很優秀很優秀(就是難寫)。考慮到剛接觸LCA的OIer可能難以理解Tarjan,這里我用幾種不同的方式來講。
本人的方式:你首先在心里構造出一棵樹來......標記祖先鏈的方式其實可以多個詢問一起進行。首先依照Tarjan的流程,遍歷這棵樹。假設現在遍歷到了點u,并且開始回溯,那么你可以想象在回溯的過程中實際上是從節點u往上拉出了一條祖先鏈。當拉鏈子拉到了一處分叉,并且分叉的另一邊還沒去過時,就停止拉鏈,往下走。假設這個過程中走到了節點v并開始回溯,并且詢問里有問u和v的LCA,那么在從v回溯的過程中相當于從v開始也拉上去了一條祖先鏈,會一直拉到之前的分叉處,此時u和v的祖先鏈便第一次相交,交于分叉處,這個分叉處便是LCA(u,v)。也就是說,當我們遍歷到一個點v,發現詢問里有LCA(u,v)這個詢問,并且從u已經拉出了祖先鏈,那么LCA(u,v)就是此時u的祖先鏈的頂端。其實我們不該只局限于這一個詢問,從宏觀上看,在遍歷的過程中我們其實從每個回溯過的點都拉出了一條祖先鏈來。如果你覺得拉的鏈子太多,我們可以剪掉一些:只留下詢問里涉及的點的祖先鏈。那么這些祖先鏈的交點就是遍歷過程中走到的那些分叉口,所以一次遍歷就可以求出所有詢問的LCA。
還是附個流程圖吧......

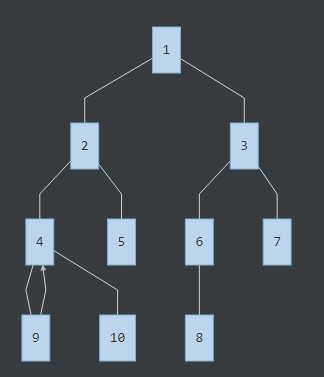
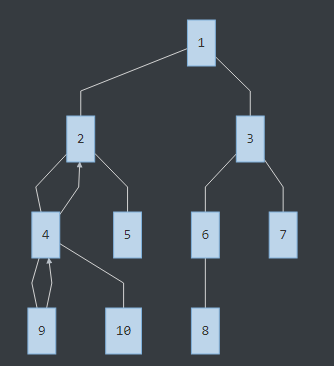
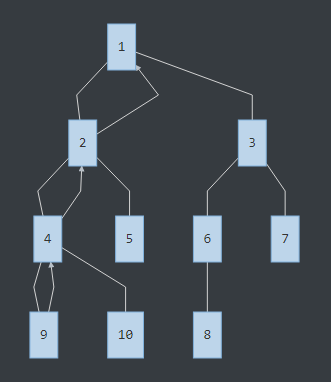

發現有分叉,往下走到7的位置,發現詢問里有LCA(8,7),那么LCA(8,7)就是此時8的祖先鏈的頂端:3號節點。
這樣應該就可以理解了......整個遍歷的復雜度為O(n),加上回答詢問的復雜度總共也才O(n+m)。像上面題目里的數據范圍可以隨便跑。
下面是教練的方式:拉祖先鏈的過程可以想象成灌水......當你往下灌到底部時,水就會慢慢往上漲,當漲到一個分岔口時就會往另一邊流。其實也差不多啦~
附上存詢問的代碼(用鄰接表來存,方便查詢):
xxxxxxxxxx
struct edge{
? ?int to, next, lca;
? ?edge(){} ? ?edge(register const int &_to, register const int &_next){
? ? ? ?to = _to,next = _next;
? }
}qe[maxm << 1];
int qhead[maxn], qk;
?
inline void qadd(register const int &u, register const int &v){
? ?qe[qk] = edge(v, qhead[u]);
? ?qhead[u] = qk++;
}
?
//main函數中 ? ?memset(qhead, -1, sizeof qhead);
? ?for(register int i = 1; i <= m; i++){
? ? ? ?scanf("%d%d", &u, &v);
? ? ? ?qadd(u, v),qadd(v, u);
? }
然后是Tarjan函數:
xxxxxxxxxx
inline int find(register const int &x){
? ?if(fa[x] == x) return x;
? ?return fa[x] = find(fa[x]);
}//用并查集的方式查找祖先鏈的頂端 ?
void LCA_tarjan(int u, int pre){
? ?vis[u] = true;
? ?for(register int i = head[u]; ~i; i = e[i].next){
? ? ? ?int v = e[i].to;
? ? ? ?if(v != pre){
? ? ? ? ? ?LCA_tarjan(v, u);
? ? ? ? ? ?fa[v] = u;//拉祖先鏈
? ? ? }
? }
? ?
? ?for(register int i = qhead[u]; ~i; i = qe[i].next){
? ? ? ?v = qe[i].to;
? ? ? ?//如果v已經拉出了祖先鏈,就回答詢問 ? ? ? ?if(vis[v]) qe[i].lca = qe[i ^ 1].lca = find(v);
? }
}
?
//main函數中 ? ?for(register int i = 1; i <= n; i++) fa[i] = i;
? ?LCA_tarjan(s, 0);//s為根
以及回答詢問:
xxxxxxxxxx
? ?for(int i = 0; i < qk; i += 2) printf("%d\n", qe[i].lca);
考慮到并查集的存在,Tarjan的復雜度其實為:O(n+mlogn),只不過實際遠遠達不到這個程度而已。
只有倍增和Tarjan兩種算法可以跑LCA?
4.樹鏈剖分
*聲明:如果你不會樹鏈剖分你可以不看這一塊。
樹上倍增嫌慢?Tarjan嫌內存太大操作太麻煩?樹鏈剖分求LCA,你值得擁有!類似于樹上倍增的思想,只不過加快了往上跳的速度而已。樹鏈剖分的方法是,一條鏈子一條鏈子地往上跳!當跳到兩個點所在的鏈子為同一條時,淺的那個點就是LCA。
xxxxxxxxxx
?
struct graph{
? ?struct edge{
? ? ? ?int to, next;
? ? ? ?edge(){} ? ? ? ?edge(const int &_to, const int &_next){
? ? ? ? ? ?to = _to;
? ? ? ? ? ?next = _next;
? ? ? }
? }e[maxm << 1];
? ?int head[maxn], k;
? ?inline void init(){
? ? ? ?memset(head, -1, sizeof head);
? ? ? ?k = 0;
? }
? ?inline void add(const int &u, const int &v){
? ? ? ?e[k] = edge(v, head[u]);
? ? ? ?head[u] = k++;
? }
}g; ?
int fa[maxn], son[maxn], size[maxn], dep[maxn];
int dfn[maxn], id[maxn], top[maxn], cnt[maxn], tot;
int n, m, s;
?
inline void swap(int &x, int &y){int t = x; x = y; y = t;}
?
inline void dfs_getson(int u){
? ?size[u] = 1;
? ?for(int i = g.head[u]; ~i; i = g.e[i].next){
? ? ? ?int v = g.e[i].to;
? ? ? ?if(v == fa[u]) continue;
? ? ? ?dep[v] = dep[u] + 1;
? ? ? ?fa[v] = u;
? ? ? ?dfs_getson(v);
? ? ? ?size[u] += size[v];
? ? ? ?if(size[v] > size[son[u]]) son[u] = v;
? }
}
?
inline void dfs_rewrite(int u, int tp){
? ?top[u] = tp;
? ?dfn[u] = ++tot;
? ?id[tot] = u;
? ?if(son[u]) dfs_rewrite(son[u], tp);
? ?for(int i = g.head[u]; ~i; i = g.e[i].next){
? ? ? ?int v = g.e[i].to;
? ? ? ?if(v != son[u] && v != fa[u]) dfs_rewrite(v, v);
? }
? ?cnt[u] = tot;
}
?
inline int lca(int u, int v){
? ?while(top[u] != top[v]){
? ? ? ?if(dep[top[u]] > dep[top[v]]) swap(u, v);
? ? ? ?v = fa[top[v]];
? }
? ?if(dep[u] > dep[v]) swap(u, v);
? ?return u;
}
?
int main(){
? ?g.init();
? ?scanf("%d%d%d", &n, &m, &s);
? ?for(int i = 1; i < n; i++){
? ? ? ?int u, v;
? ? ? ?scanf("%d%d", &u, &v);
? ? ? ?g.add(u, v);
? ? ? ?g.add(v, u);
? }
? ?dfs_getson(s);
? ?dfs_rewrite(s, s);
? ?
? ?for(int i = 1; i <= n; i++){
? ? ? ?int u, v;
? ? ? ?scanf("%d%d", &u, &v);
? ? ? ?printf("%d\n", lca(u, v));
? }
? ?
? ?return 0;
}





)




-TextBox RichTextBox PasswordBox樣式、水印、Label標簽、功能擴展...)








)