Sorting
排序如果可在內存里面排,用經典的排序算法就ok,比如快排
問題在于,數據表中的的數據是很多的,沒法一下都放到內存里面進行排序
所以就需要用到,外排,多路并歸排序

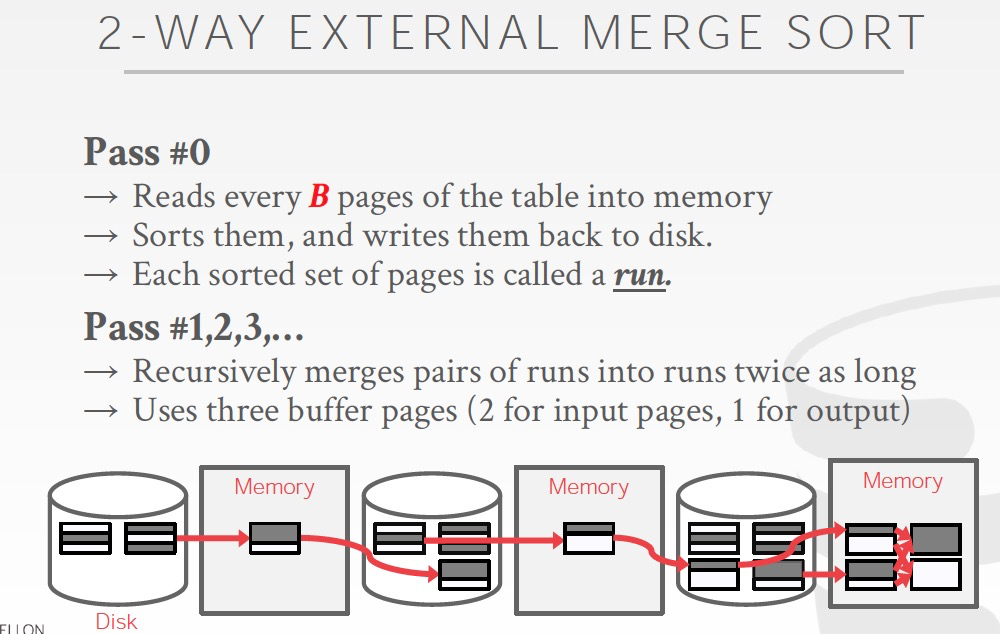
看下最簡單的,2路并歸排序,
設文件分為N個page,memory中一次最多可以放入B個pages
所以在sort過程,一次性可以載入B個page,在內存中page內排序,寫回disk,稱為一輪,run
那么如果一共N個page,需要N/B+1個run
在merge過程,如果雙路并歸排序,只需要用到3個page的buffer,多了也沒用
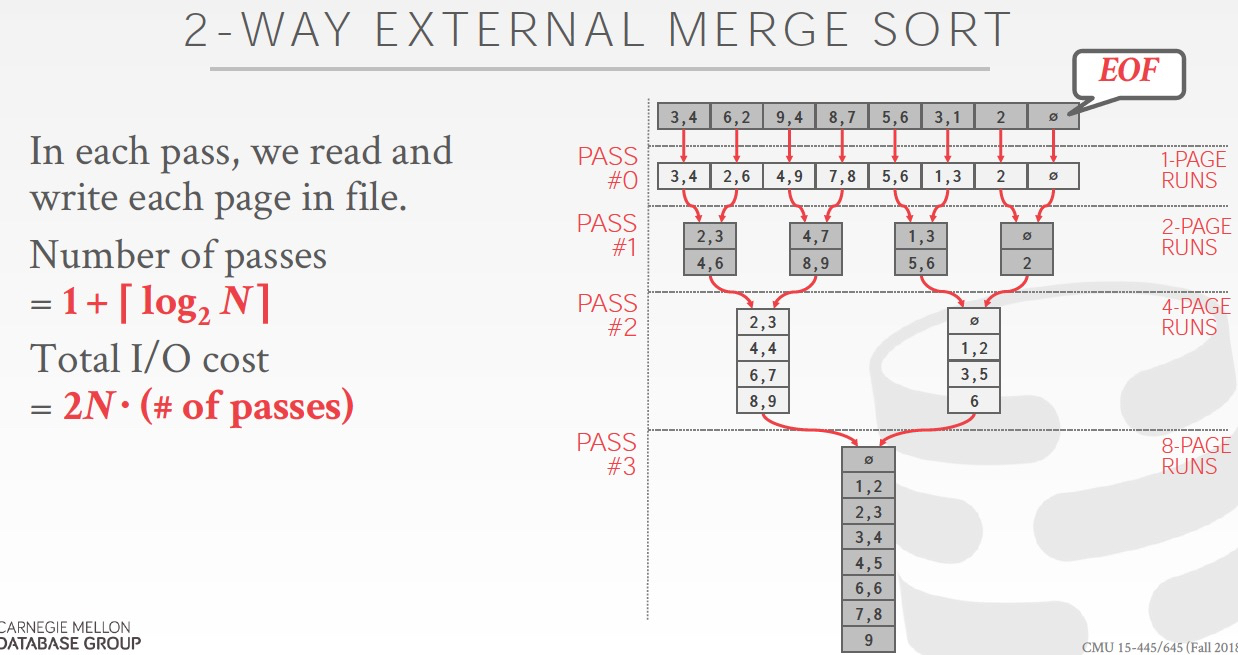
Merge過程的cost
每個pass都需要讀寫一遍所有的數據,cost為2N
2 way,所以一共有1 + logN個pass
多路并歸排序的通用公式如下,
其他都比較容易理解,為什么way數是B-1?
因為memory一共B個buffer,需要留一個output,剩下的用于merge,所以最多是B-1路并歸排序

?
如果我們有B+ index的情況下,
分兩種情況,要排序的字段有Clustered B+索引,那么直接從左到右遍歷葉子節點就好

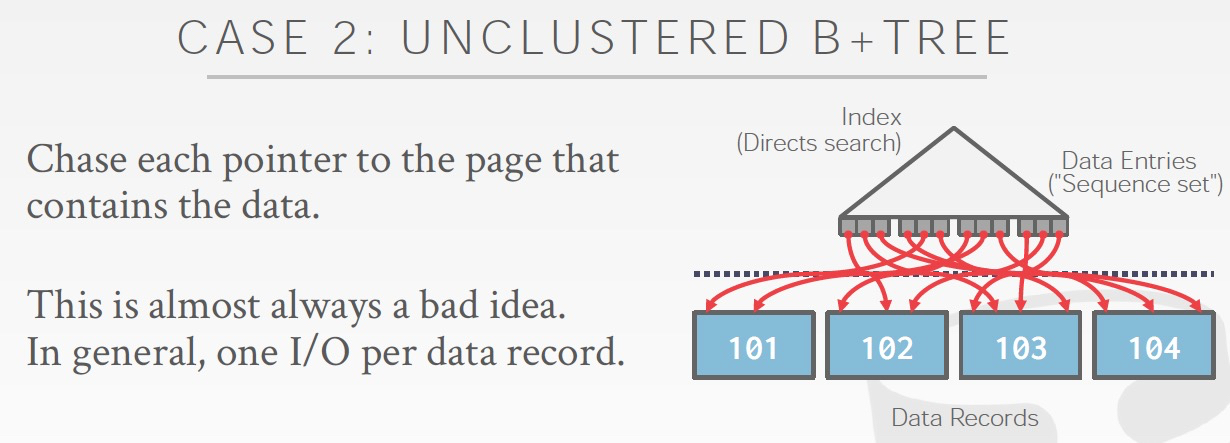
排序的字段不是Clustered B+索引,比如是secondary 索引
那么從索引里面只能獲取到排好序的id,然后要通過id去Clustered B+索引中取真正的value,效率也很低,每個record都需要一次io
?
Aggregation
Aggregation有兩種思路,
一種先排序sorting,然后再按順序做aggregate
這個方法明顯的問題,就是比較費,有些場景不需要sort,比如group by,distinct

所以第二種思路是Hashing,
在memory里面臨時維護一個hash table,去重或聚合都在hash table上完成
問題就是,如果hash table太大,內存放不下怎么辦?
所以解法的思路,放不下,就切開,切成能放下的一個個partition,并且要保證一個key的數據都在一個partition里面,這樣只要保證內存能夠放下一個partition就可以aggregate,不需要去讀其他的partition
第一次partition劃分成幾個partition,如果內存B個buffer,劃分成B-1個partition;如果劃分完了某個partition還是放不下怎么辦,那就繼續劃分,直到所有partition都可以放到內存中
這里有幾個問題,
首先,一個partition應該不止一個key,如果只有一個,第二步里面的h2感覺沒用
第二,假設數據是均勻分布的,不會出現太大的傾斜,不會有partition overflow


?
Join
為什么需要join?
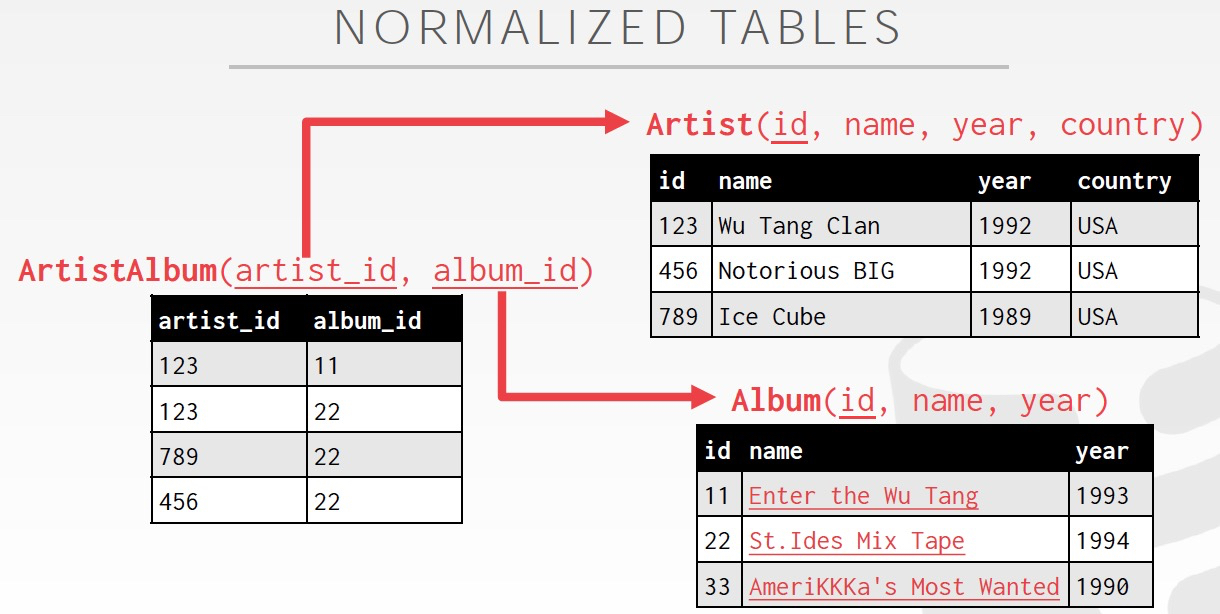
因為不同的數據存在不同的表里面,所以要查詢就需要關聯
那么為什么不能放在一張表里面,關系表的設計有范式的要求,避免大量的數據重復
?
Join Operator Output
直接輸出data,這樣好處是,后續operator不用回到數據表再去讀數據
這個方法比較實用于TP需求,結果數據較少的情況


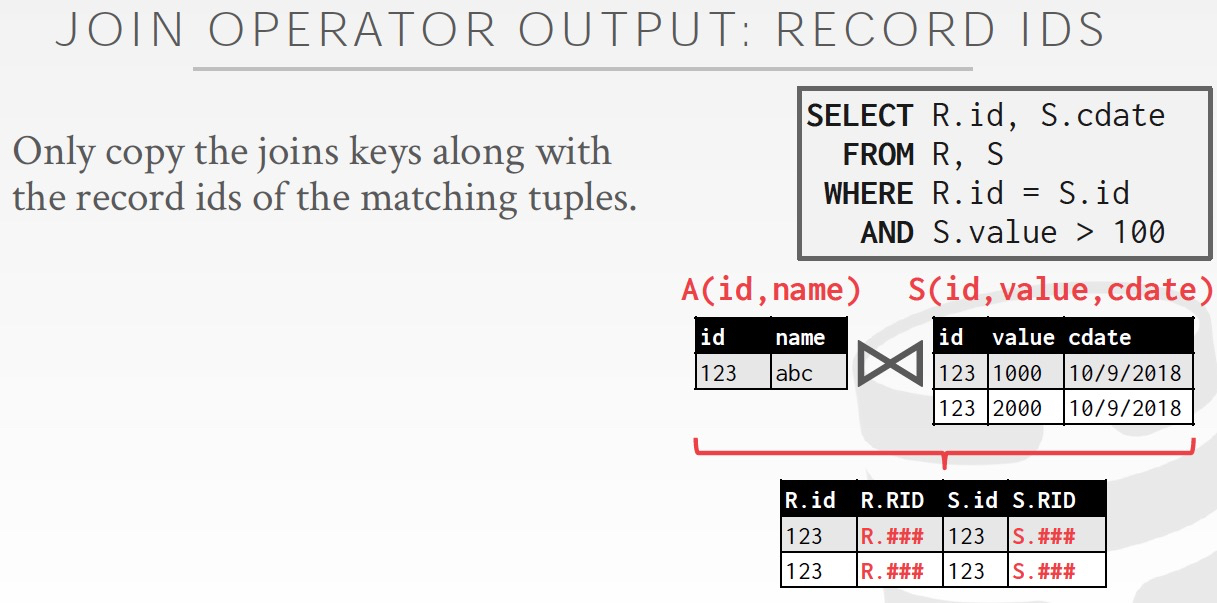
僅僅輸出ids,適合AP需求,join結果集非常大的情況
尤其適用于列存,因為這樣你只需要讀出join id列,也不浪費
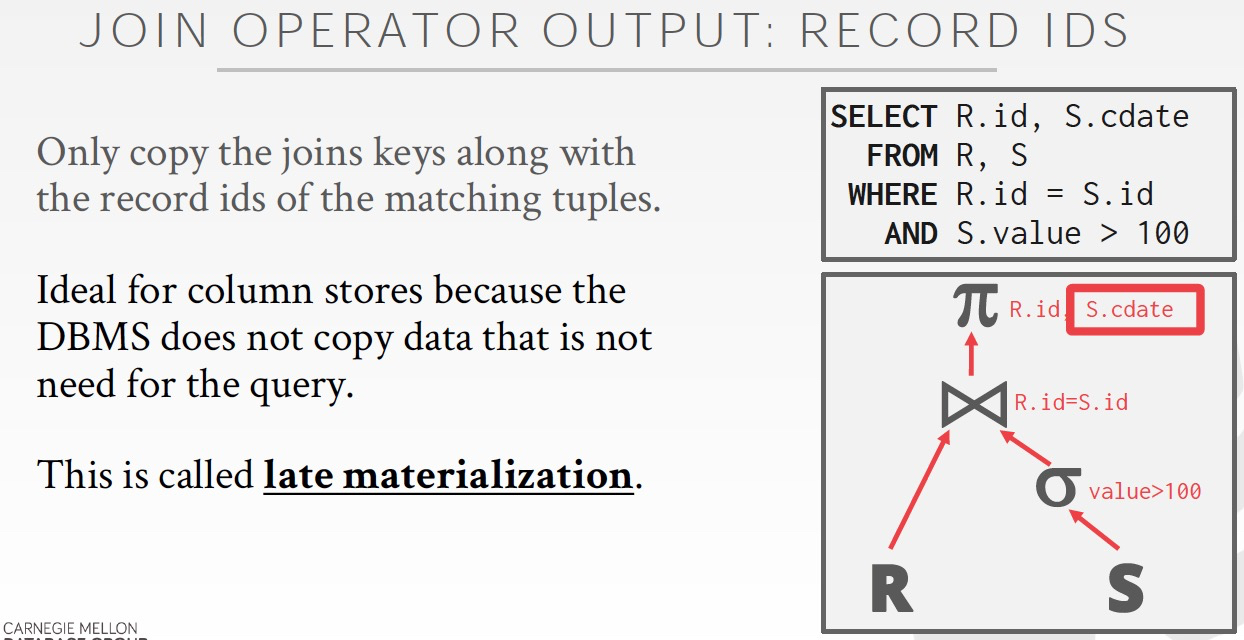
然后在最后要顯示的時候,才去把需要的數據從表里面查出來,這叫做late materialization
這樣的好處,過程中可能還有其他的join,過濾等,所以開始讀可能浪費,到最后真正需要的時候再讀
?
Join Cost
如何去評價join算法的好壞,就是要評價cost
傳統的數據庫的瓶頸在disk IO,所以這里就以磁盤IO的次數來評價join算法的好壞,這個和為何使用B+tree作為index的理由一樣
所以就是讀寫page的個數

?
Join算法?
Nested Loop Join
Simple,直覺的方式就是遍歷兩個表
這里的概念,分為Outer和Inner表
從Cost上看,最要取決于Outer的tuples數,所以如果把較小的表N作為Outer會效率高些


比較明顯的問題是,沒有必要讀那么多遍的inner表
如果我能把outer表直接放在內存中,那么只需要讀一遍inner就可以了,如果不行就用如下的block的方式
如果內存大小是B,那么要用兩塊來放inner和output,所以可以用B-2來放outer


Cost,outer表M需要讀一次,inner表需要讀M/(B-2)次
這里也寫了,如果memory比較大,那么cost就是M+N,只需要讀一遍inner

?
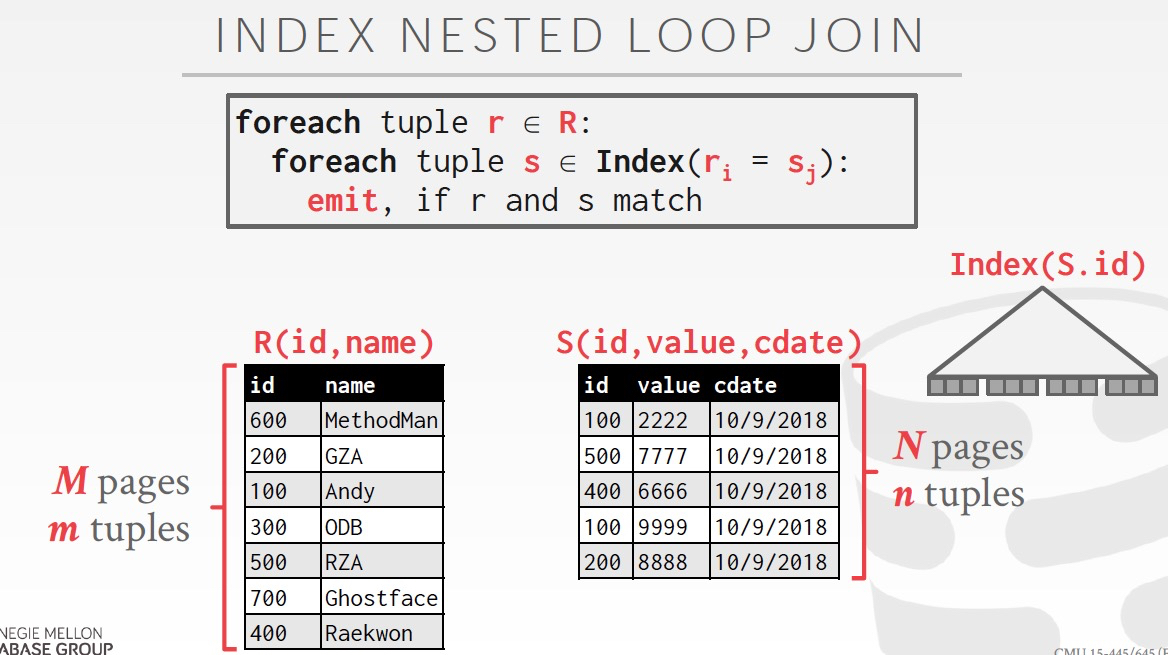
如果有index,是否可以加快join的效率?應該可以,但是效果要看是什么index,如果hash,C=O(1),B+tree,C=O(logn)

?
Sort-Merge Join?
這個方法要求,兩個表先排序,然后做一輪幷歸就可以完成join
所以這個方法適用于,兩個表本身就有序,或是在join key上有index
這個方法附帶的好處是結果有序
這個算法的Cost,主要是兩個表排序的cost,幷歸的cost就是M+N


?
Hash Join
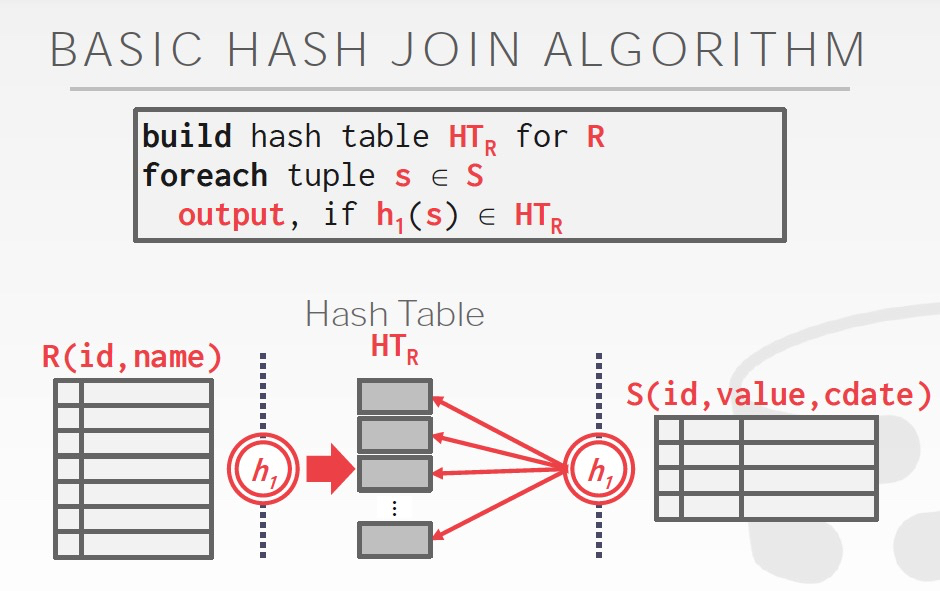
HashJoin分為兩步,兩步的hash函數用同一個
Build,對較小的表建臨時的hash table
Probe,讀取另一張表,進行join
這有個類似的問題,Hash Table里面存什么?
當然可以直接存join的結果,也可以存tuple id,這個選擇就取決于場景
?
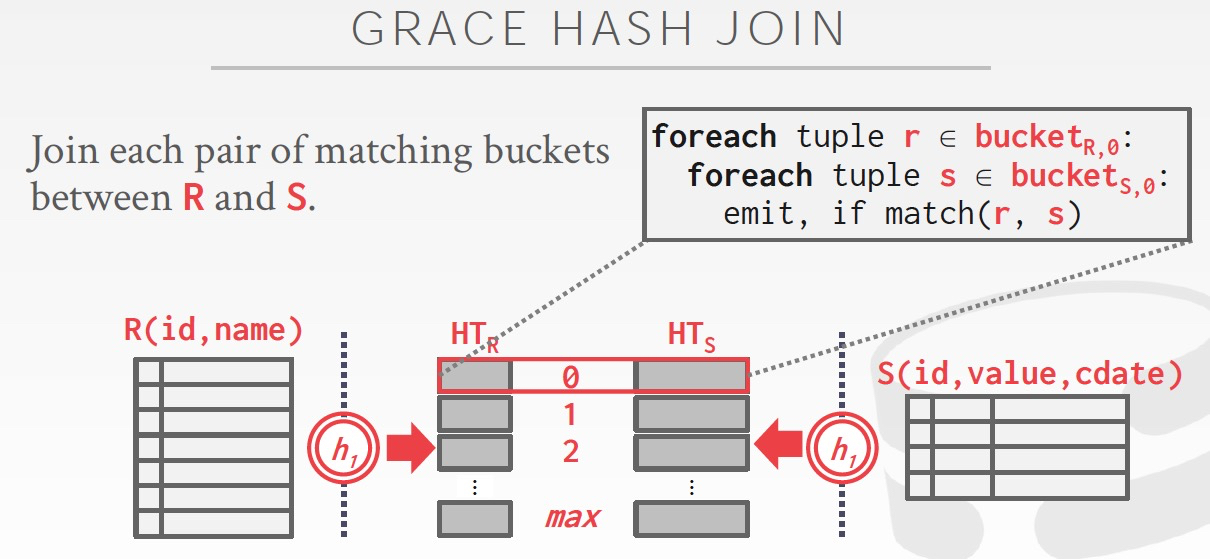
自然有個疑問,如果內存放不下這個hash table怎么辦?
既然放不下,就需要分而治之,兩個表用相同的hash函數,hash到相同數目的buckets里面去
在內存中,一次只讀一組bucket來進行join,是不是很ok
?
?那么如果hash成bucket的時候,不均衡,一個bucket也overflow,怎么辦?答案是繼續分
?

Grace Hash Join的cost

?
?所有join算法的Cost對比,
?
?





![SQL基礎培訓實戰教程[全套]](http://pic.xiahunao.cn/SQL基礎培訓實戰教程[全套])













