分布式系統特性與衡量標準
透明性:使用分布式系統的用戶并不關心系統是怎么實現的,也不關心讀到的數據來自哪個節點,對用戶而言,分布式系統的最高境界是用戶根本感知不到這是一個分布式系統
可擴展性:分布式系統的根本目標就是為了處理單個計算機無法處理的任務,當任務增加的時候,分布式系統的處理能力需要隨之增加。簡單來說,要比較方便的通過增加機器來應對數據量的增長,同時,當任務規模縮減的時候,可以撤掉一些多余的機器,達到動態伸縮的效果
可用性與可靠性:一般來說,分布式系統是需要長時間甚至7*24小時提供服務的。可用性是指系統在各種情況對外提供服務的能力,簡單來說,可以通過不可用時間與正常服務時間的必知來衡量;而可靠性而是指計算結果正確、存儲的數據不丟失。
高性能:不管是單機還是分布式系統,大家都非常關注性能。不同的系統對性能的衡量指標是不同的,最常見的:高并發,單位時間內處理的任務越多越好;低延遲:每個任務的平均時間越少越好。這個其實跟操作系統CPU的調度策略很像
一致性:分布式系統為了提高可用性可靠性,一般會引入冗余(復制集)。那么如何保證這些節點上的狀態一致,這就是分布式系統不得不面對的一致性問題。一致性有很多等級,一致性越強,對用戶越友好,但會制約系統的可用性;一致性等級越低,用戶就需要兼容數據不一致的情況,但系統的可用性、并發性很高很多。
組件、理論、協議
假設這是一個對外提供服務的大型分布式系統,用戶連接到系統,做一些操作,產生一些需要存儲的數據,那么在這個過程中,會遇到哪些組件、理論與協議呢
用一個請求串起來
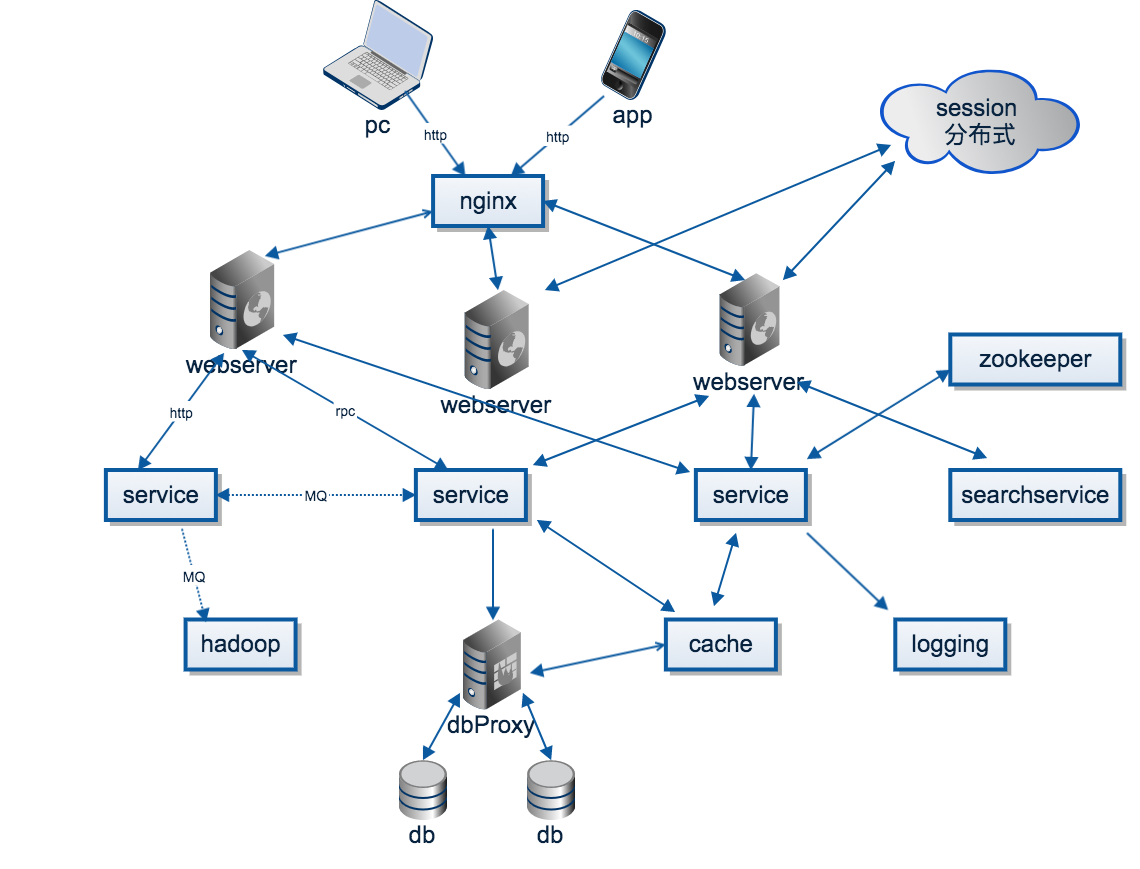
用戶使用Web、APP、SDK,通過HTTP、TCP連接到系統。在分布式系統中,為了高并發、高可用,一般都是多個節點提供相同的服務。那么,第一個問題就是具體選擇哪個節點來提供服務,這個就是負載均衡(load balance)。負載均衡的思想很簡單,但使用非常廣泛,在分布式系統、大型網站的方方面面都有使用,或者說,只要涉及到多個節點提供同質的服務,就需要負載均衡。
通過負載均衡找到一個節點,接下來就是真正處理用戶的請求,請求有可能簡單,也有可能很復雜。簡單的請求,比如讀取數據,那么很可能是有緩存的,即分布式緩存,如果緩存沒有命中,那么需要去數據庫拉取數據。對于復雜的請求,可能會調用到系統中其他的服務。
承上,假設服務A需要調用服務B的服務,首先兩個節點需要通信,網絡通信都是建立在TCP/IP協議的基礎上,但是,每個應用都手寫socket是一件冗雜、低效的事情,因此需要應用層的封裝,因此有了HTTP、FTP等各種應用層協議。當系統愈加復雜,提供大量的http接口也是一件困難的事情。因此,有了更進一步的抽象,那就是RPC(remote produce call),是的遠程調用就跟本地過程調用一樣方便,屏蔽了網絡通信等諸多細節,增加新的接口也更加方便。
一個請求可能包含諸多操作,即在服務A上做一些操作,然后在服務B上做另一些操作。比如簡化版的網絡購物,在訂單服務上發貨,在賬戶服務上扣款。這兩個操作需要保證原子性,要么都成功,要么都不操作。這就涉及到分布式事務的問題,分布式事務是從應用層面保證一致性:某種守恒關系。
上面說道一個請求包含多個操作,其實就是涉及到多個服務,分布式系統中有大量的服務,每個服務又是多個節點組成。那么一個服務怎么找到另一個服務(的某個節點呢)?通信是需要地址的,怎么獲取這個地址,最簡單的辦法就是配置文件寫死,或者寫入到數據庫,但這些方法在節點數據巨大、節點動態增刪的時候都不大方便,這個時候就需要服務注冊與發現:提供服務的節點向一個協調中心注冊自己的地址,使用服務的節點去協調中心拉取地址。
從上可以看見,協調中心提供了中心化的服務:以一組節點提供類似單點的服務,使用非常廣泛,比如命令服務、分布式鎖。協調中心最出名的就是chubby,zookeeper。
回到用戶請求這個點,請求操作會產生一些數據、日志,通常為信息,其他一些系統可能會對這些消息感興趣,比如個性化推薦、監控等,這里就抽象出了兩個概念,消息的生產者與消費者。那么生產者怎么講消息發送給消費者呢,RPC并不是一個很好的選擇,因為RPC肯定得指定消息發給誰,但實際的情況是生產者并不清楚、也不關心誰會消費這個消息,這個時候消息隊列就出馬了。簡單來說,生產者只用往消息隊列里面發就行了,隊列會將消息按主題(topic)分發給關注這個主題的消費者。消息隊列起到了異步處理、應用解耦的作用。
上面提到,用戶操作會產生一些數據,這些數據忠實記錄了用戶的操作習慣、喜好,是各行各業最寶貴的財富。比如各種推薦、廣告投放、自動識別。這就催生了分布式計算平臺,比如Hadoop,Storm等,用來處理這些海量的數據。
最后,用戶的操作完成之后,用戶的數據需要持久化,但數據量很大,大到按個節點無法存儲,那么這個時候就需要分布式存儲:將數據進行劃分放在不同的節點上,同時,為了防止數據的丟失,每一份數據會保存多分。傳統的關系型數據庫是單點存儲,為了在應用層透明的情況下分庫分表,會引用額外的代理層。而對于NoSql,一般天然支持分布式。
一個簡化的架構圖
下面用一個不大精確的架構圖,盡量還原分布式系統的組成部分(不過只能體現出技術,不好體現出理論)
Docker步步實踐
目錄文檔:


①Docker簡介
②基本概念
③安裝Docker

④使用鏡像:

⑤操作容器:

⑥訪問倉庫:

⑦數據管理:

⑧使用網絡:

⑨高級網絡配置:

⑩安全:

?底層實現:

?其他項目:
圖片轉存中…(img-aE0jzHRs-1626689072582)]
?其他項目:
[外鏈圖片轉存中…(img-Ht2MaPFs-1626689072583)]
有需要完整版源碼+筆記的朋友點擊這里免費獲取



















