本文基于Mysql5.7版本和InnoDB存儲引擎。
1、InnoDB索引組織表
在InnoDB引擎中,表都是按照主鍵順序組織存放的,這種存放方式的表稱為索引組織表。InnoDB存儲引擎中的表,都有主鍵,如果沒有顯式聲明主鍵,則采取以下措施:該表如果有非空唯一索引,則該列為主鍵;如果有多個,則取第一個;
如果沒有非空唯一索引,則InnoDB自動創建一個大小為6字節的指針作為主鍵;
為什么推薦使用自增ID做主鍵而不是UUID?
這是由于B+樹的性質決定的,UUID無序,占用空間大,每(磁盤)頁能存放的索引少,這會導致磁盤IO次數增加,效率變慢;
什么是堆表?
與索引組織表相對應,堆表是按照行數據的插入順序存放,無組織,在某些情況下,堆表比索引組織表更快;
2、索引原理
2.1、什么是索引?
索引是一個單獨的、存儲在磁盤上的數據庫結構。
InnoDB支持B+樹索引;B+樹索引由于一個結點存儲的是一個磁盤頁的數據,因此只能先找到被查找數據所在的頁,然后將頁讀進內存中,最后再在內存中查找;
關于B+樹數據結構的相關知識請看 什么是B-樹、B樹、B+樹、B*樹?
2.2、B+樹索引分類
聚集(主鍵)索引
輔助(非聚集、二級)索引
普通索引
唯一索引
聯合索引
聚集索引和主鍵索引的相同點:
葉子結點存放所有數據(這是由B+樹的性質所決定的);
不同點:
聚集索引的葉子結點存放一整行數據,而輔助索引的葉子結點只存放該列數據和主鍵;
2.3、聯合索引原理
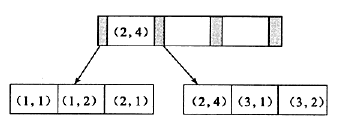
如上圖所示,聯合索引的結點以(a列的值,b列的值)形式存儲。
下面看看如何使用聯合索引進行查詢:
select * from tb1 where a=? and b=?,走聯合索引,因為a和b在一起是排序的;
select * from tb1 where a=?,走聯合索引,因為單獨的a是排序的;
select * from tb1 where b=?,不走聯合索引,因為單獨的b不是排序的,如上圖,b的順序為1,2,1,4,1,2;
聯合索引的好處:
首先,a列和b列都是排好序的;比如我要查詢用戶最近三次的購買記錄,可以使用user_id作為索引,也可以使用(user_id,buy_date)的聯合索引;如果使用user_id作為索引,則需要將查詢出來的結果再按buy_date進行一次排序,才能查出最近三次的購買記錄;而聯合索引已經將buy_date排好序了,只需要取最后三條數據,就是用戶最新三次的購買記錄;
2.4、什么是覆蓋索引?
定義:如果能直接從輔助索引上查找到所有想要的數據,而不需要回表(通過主鍵在聚集索引上做二次查詢),就稱該輔助索引覆蓋了這條select語句,又稱索引覆蓋;
優化器一般會傾向于使用覆蓋索引而不是聚集索引,因為聚集索引占用空間大,磁盤IO次數多;
聯合索引可以當做覆蓋索引使用。對于聯合索引(a,b)而言,使用b作為查詢條件則不走索引,但是如果此時沒有針對b的索引,且要查詢的列該聯合索引都有,則優化器會將該聯合索引視作覆蓋索引(聯合索引上單獨的b是無序的,所以是從頭到尾順序查找,盡管如此也比在聚集索引上順序查找效率高),explain的Extra中有Using index就表明使用了覆蓋索引;
2.5、操作索引
查看某個表的索引:show?index from?表名
下面解釋一下各字段的意思:
Table:索引所在表名;
Non_unique:值為0表示唯一;
Key_name:索引名稱;
Seq_in_index:索引中該列的位置;
Column:索引中列的名稱;
Collation:列以什么方式存儲在索引中,值為A或NULL,B+樹索引總是A,即排序的;
Cardinality:表示該列中唯一值數目的估計值。如果該值非常小,則表示該列重復數據較多;為什么是估計值呢?因為該值不是實時更新的(代價太大),可以用analyze table命令手動更新一次Cardinality值;
Sub_part:是否只對列的一部分索引;比如某個列類型為varchar(1000),可以設置只索引該列的前100個字符,則Sub_part的值為100,如果索引的是列的全部,則Sub_part為NULL;
Packed:關鍵字如何被壓縮。如果沒有被壓縮則為NULL;
Null:該列是否允許有NULL值;
Index_type:索引類型;
在select語句中使用force index(index_name)強制使用某個索引,而user index(index_name)則提示使用某個索引。
3、性能優化
3.1、執行計劃查看sql的執行計劃:explain?select ...
下面簡要介紹一下各字段的意思,詳細解釋請查閱Mysql5.7官方文檔:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
id:select的查詢序列號
select_type:查詢類型
simple:簡單查詢,不包括連接查詢和子查詢
primary:主要的查詢,最外層的查詢
subquery:子查詢
table:表示查詢的表
partitions:命中的分區,如果是非分區表則為NULL
type:表的連接類型
const:只返回一行數據,查詢速度很快,該列具有唯一索引或主鍵索引;如果是普通索引,即時真的只返回一行數據,也不會是const;
range:范圍查詢;
index:根據輔助索引全表掃描;
ALL:無索引(聚集索引)全表掃描;
possible_keys:通過檢測where子句獲得可用的索引;
key:實際使用的索引;
rows:顯示Mysql在表中進行查詢時必須檢查的行數;
extra:表示Mysql在處理查詢時的詳細信息;
3.2、索引設計原則
索引優點:
唯一索引可以保證唯一性;
加快速度:查詢速度、表與表連接速度、分組和排序的速度;
缺點:
索引需要占用磁盤空間;
索引的維護(增刪改)需要時間,尤其是數據量大的時候;
索引設計原則:
索引并非越多越好,索引太多會影響insert、update、delete的性能;
經常更新的列不使用索引,經常查詢(邏輯外鍵、where子句、group by子句、order by子句)的列使用索引;
數據量小的表不使用索引;
重復值很多的列不使用索引;
刪除長期未使用的索引,不用的索引會造成不必要的性能消耗;
避免使用冗余索引:如(name,city)和(name)就是冗余索引,因此一般應該擴展已有的索引,而不是創建新的索引;
3.3、索引失效的情況
避免where子句中對字段施加函數,會造成無法命中索引。這是因為b+樹只能對原值進行索引。
假設訂單表有1000萬數據,訂單號為null有100條,分析如下三條sql語句:
explain?select?order_num from?goods_order where?order_num ='f035a84a-4672-4517-bd8a-2c9f2d92423e'
explain?select?order_num from?goods_order where?order_num is?null
explain?select?order_num from?goods_order where?order_num is?not?null通過執行結果發現,只有is not null不走索引。
聯合索引遵循最左前綴原則,否則不走索引。使用in不走索引,用exists代替,如果是連續的數值則可以用between代替。
應盡量避免在 where 子句中使用 or 來連接條件,如果一個字段有索引,一個字段沒有索引,則不走索引。like子句不能前置百分比,否則不走索引,如果非要前置百分比不可,則考慮使用全文索引。where 子句中不要使用 != 或 <> ,否則不走索引。limit offset查詢緩慢時,可以借助主鍵索引來提高性能:select a.* from bigtable a inner join (select?id from bigtable LIMIT?6520000,10)?b on a.id=b.id
最后看一下下面這種情況:
比如select * from order where order_id>10000 and order_id<20000,注意order_id不是主鍵,此時有一個輔助索引order_id,由于該索引上不包含所有的字段(注意是select *),因此還要回表。通過order_id找到的對應主鍵是無序的,所以回表的過程是磁盤離散讀,而磁盤順序讀的速度是遠大于離散讀的(固態硬盤的隨機讀速度非常快),特別是數據量大的情況下差異更明顯,這時會優化器會放棄輔助索引而走全表掃描。
總體來說,優化器選擇走不走索引,也不是千篇一律的,有時候也要看實際情況。對于我們而言,要熟練使用explain查看sql執行計劃,在實際項目中分析sql性能的瓶頸,進行優化。




)






)




)

----GTID)
定義容器環境變量)