這是linux pwn系列的第二篇文章,前面一篇文章我們已經介紹了棧的基本結構和棧溢出的利用方式,堆漏洞的成因和利用方法與棧比起來更加復雜,為此,我們這篇文章以shellphish的how2heap為例,主要介紹linux堆的相關數據結構和堆漏洞的利用方式,供大家參考。
0.前置知識
0.0 編譯+patch方法
how2heap源碼地址https://github.com/shellphish/how2heap,為了方便調試編譯時使用gcc -g -fno-pie xx.c –o xx。這里先介紹一種linux下patch文件加載指定版本libc的方法,patchelf –set-interpreter 設置elf啟動時使用指定ld.so(elf文件在啟動時ld.so查找并加載程序所需的動態鏈接對象,加載完畢后啟動程序,不同libc版本需要不同的加載器,不同版本libc和加載器下載地址https://github.com/5N1p3R0010/libc-ld.so),然后patchelf –set-rpath :/設置elf啟動時加載指定libc。編譯+patch示例

0.1 linux堆管理簡圖及源碼地址
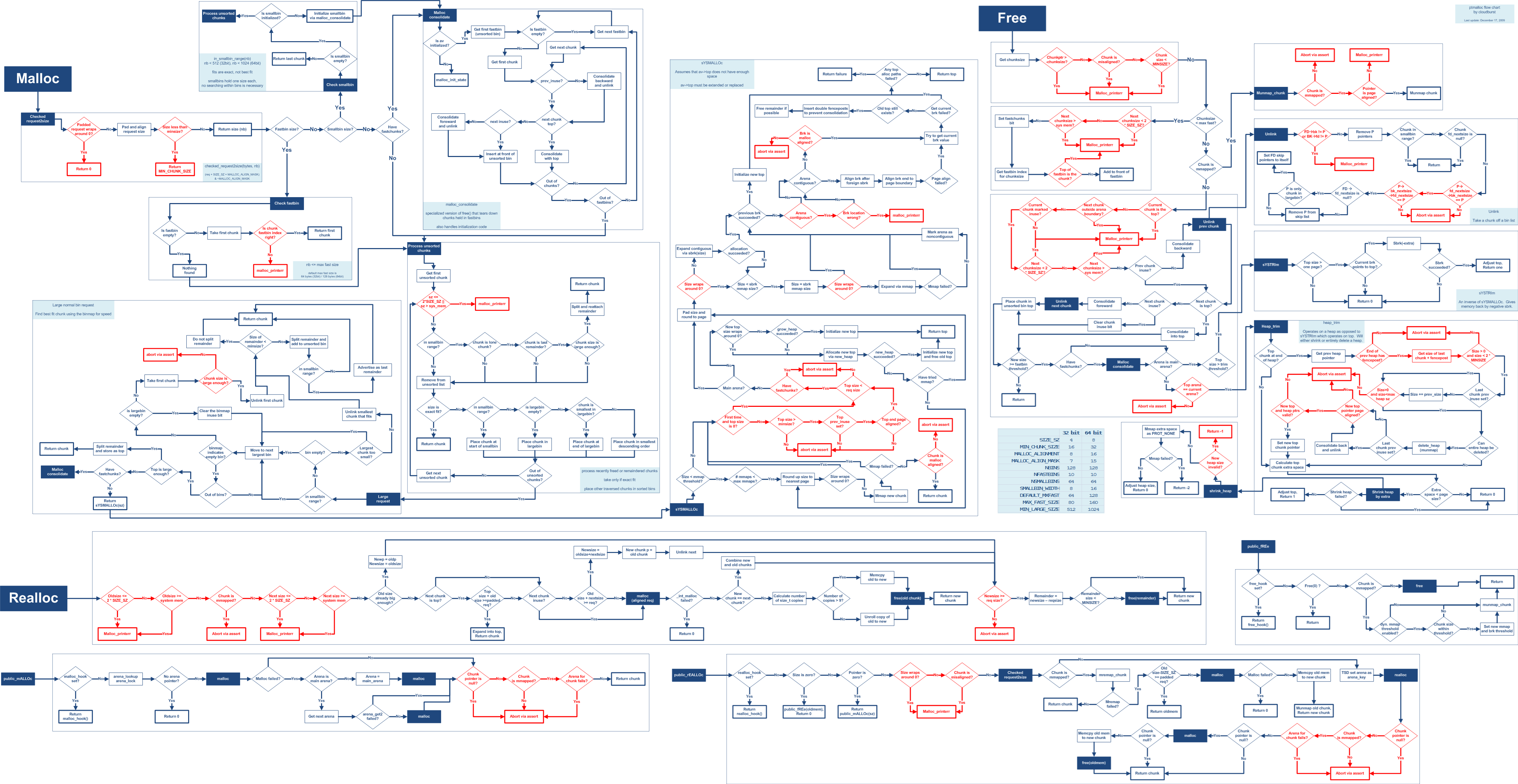
0.2 linux堆的數據結構
0.2.1堆塊數據結構
首先介紹下linux下堆的基本數據結構。

各字段含義如下:
0.mchunk_prev_size。當當前堆物理相鄰的前一個堆為空閑狀態時mchunk_prev_size記錄前一個空閑堆的大小,當當前堆物理相鄰的前一個堆為占用狀態時mchunk_prev_size可用于存儲前一個堆的數據。
1.mchunk_size,記錄當前堆包含堆頭的大小,堆的大小在申請時會進行對齊,對齊后堆的大小為2*size_t的整數倍,size_t為機器字長。mchunk_size的低三比特位對堆的大小沒有影響,ptmalloc用它來記錄當前堆的狀態,三個比特位從高到低依次:
NON_MAIN_ARENA,記錄當前堆是否不屬于主線程,1 表示不屬于,0 表示屬于。
IS_MAPPED,記錄當前堆是否是由 mmap 分配的。
PREV_INUSE,記錄前一個堆是否被分配。
2.fd、bk,堆處于分配狀態時,堆結構體偏移fd的位置存儲數據;堆處于空閑狀態時,fd、bk分別記錄物理相鄰的前一空閑堆、物理相鄰的后一空閑堆,即用于對應空閑鏈表的管理
3.fd_nextsize、bk_nextsize,large chunk處于空閑狀態時使用,分別用于記錄前一個與當前堆大小不同的第一個空閑堆、后一個與當前堆大小不同的第一個空閑堆
0.2.2 空閑鏈表
理解ptmalloc堆漏洞利用的另一個比較重要的結構體是bin,為了節省內存分配開銷,用戶釋放掉的內存并不會馬上返還給系統,而是保存在相應的空閑鏈表中以便后續分配使用。Ptmalloc使用的空閑鏈表bin有四種,fastbin、samllbin、largebin、unsortedbin ,一個好的內存分配器應該是內存碎片少、且能在較低算法復雜度和較少內存分配次數的情況下滿足用戶使用內存(申請和釋放)的需求,四種bin的實現就體現了這種思想。
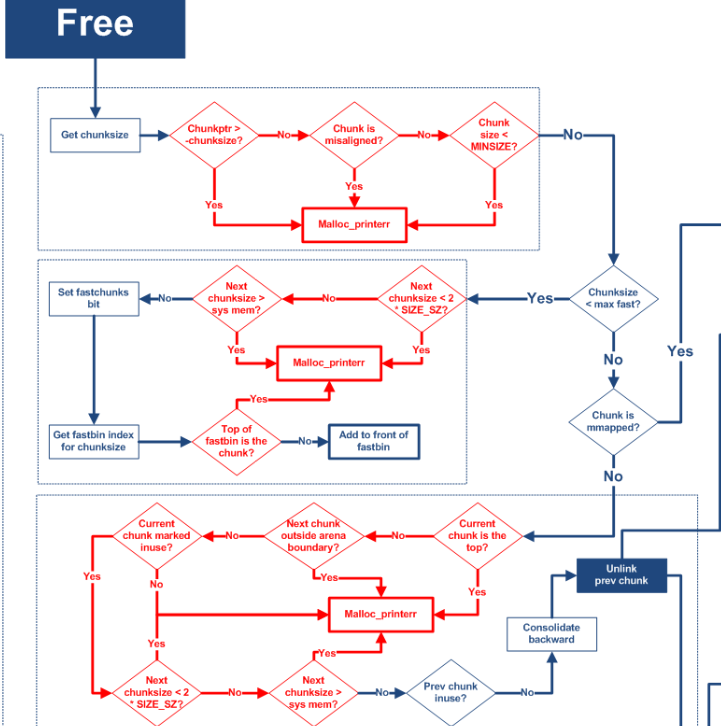
為了減少內存碎片,ptmalloc在釋放當前堆cur_chunk時會檢測cur_chunk的prev_inuse位(標識物理相鄰前一個堆(物理低地址)是否處于空閑狀態)和cur_chunk的物理相鄰下一個堆是否是top_chunk、物理相鄰下一個堆的prev_inuse位。若cur_chunk的prev_inuse位為0則合并后向堆并將后向堆的地址作為新的合并后的堆的起始地址;若cur_chunk的物理相鄰下一個堆的prev_inuse位為0則進行前向合并并將cur_chunk的地址作為新的合并后的堆的起始地址。若待釋放的cur_chunk的物理相鄰下一個堆為top_chunk則將cur_chunk和top_chunk合并,并將cur_chunk的地址作為新的top_chunk起點。
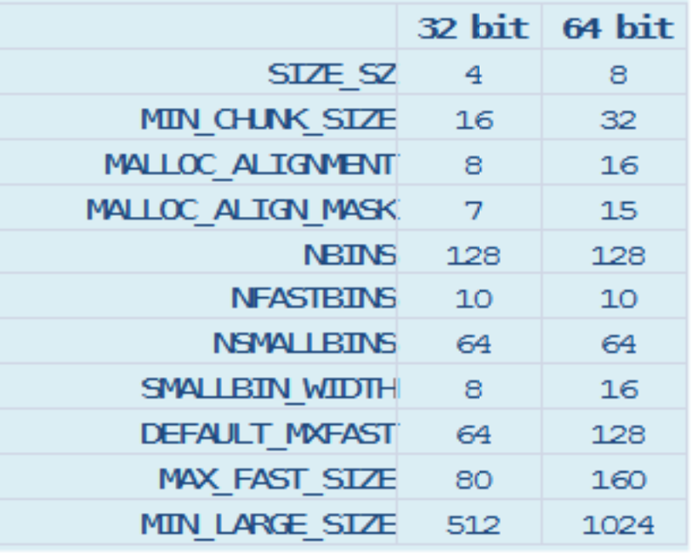
Ptmalloc堆的一些參數
0) fastbin
fastbin是保存一些較小堆(32位系統默認不超過64字節,64位系統默認不超過128字節)的單鏈表結構。由于fastbin中相同index鏈接的都是相同大小的堆,ptmalloc認為不同位置的相同大小的堆沒有區別,因此fastbin使用lifo的方法實現,即新釋放的堆被鏈接到fastbin的頭部,從fastbin中申請堆也是從頭部取,這樣就省去了一次遍歷單鏈表的過程。fastbin的內存分配策略是exact fit,即只釋放fastbin中跟申請內存大小恰好相等的堆。
1) smallbin
smallbin中包含62個循環雙向鏈表,鏈表中chunk的大小與index的關系是2* size_t* index。由于smallbin是循環雙向鏈表,所以它的實現方法是fifo;smallbin的內存分配策略是exact fit。
從實現中可以看出smallbin鏈接的chunk中包含一部分fastbin大小的堆,fastbin范圍的堆是有可能被鏈入其他鏈表的。當用戶申請smallbin大小的堆而smallbin又沒有初始化或者申請大于smallbin最大大小的堆時,fastbin中的堆根據prev_inuse位進行合并后會進入如上unsortedbin的處理流程,符合smallbin或largebin范圍的堆會被鏈入相應的鏈表。
2) largebin
largebin包含63個循環雙向鏈表,每個鏈表鏈接的都是一定范圍大小的堆,鏈表中堆的大小按從大到小排序,堆結構體中的fd_nextsize和bk_nextsize字段標識鏈表中相鄰largechunk的大小,即fd_nextsize標識比它小的堆塊、bk_nextsize標識比它大的堆塊。
對于相同大小的堆,釋放的堆插入到bin頭部,通過fd、bk與其他的堆鏈接形成循環雙向鏈表。
Largebin的分配策略是best fit,即最終取出的堆是符合申請內存的最小堆(記為chunk)。若取出的chunk比申請內存大至少minsize,則分割chunk并取合適大小的剩余堆做為last remainder;若取出的chunk比申請內存不大于minsize,則不分割chunk直接返回做為用戶申請內存塊。
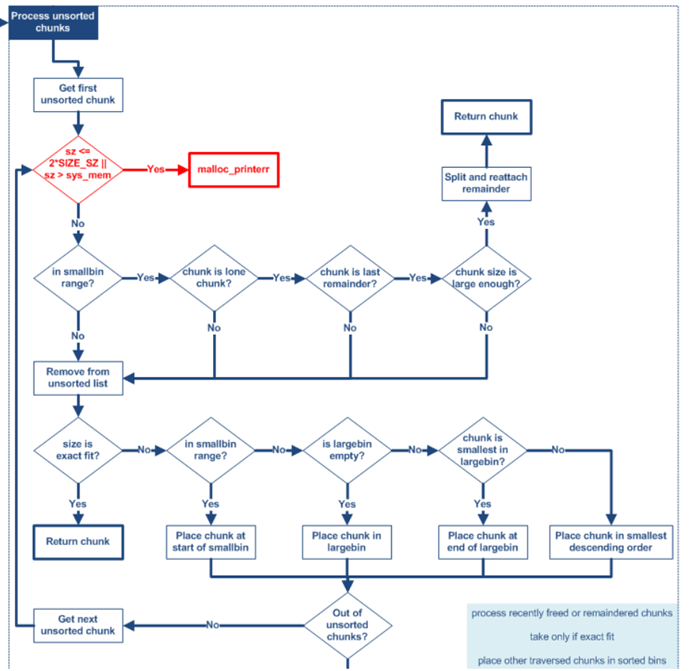
3) unsortedbin
unsortedbin可以視為空閑chunk回歸其所屬bin之前的緩沖區,分配策略是exact fit。可能會被鏈入unsortedbin的堆塊是申請largebin大小堆塊切割后的last remainder;釋放不屬于fastbin大小且不與topchunk緊鄰的堆塊時會被先鏈入unsortedbin;在特定情況下將fastbin內的堆合并后會進入unsortedbin的處理流程(特定情況為申請fastbin范圍堆fastbin為空;申請非fastbin范圍smallbin的堆但smallbin未初始化;申請largechunk)
1.how2heap調試
1.0 First_fit
這個程序闡釋了glibc分配內存的一個策略:first fit,即從空閑表中取出的堆是第一個滿足申請內存大小的堆(fastbin、smallbin exact fit,largebin best fit)
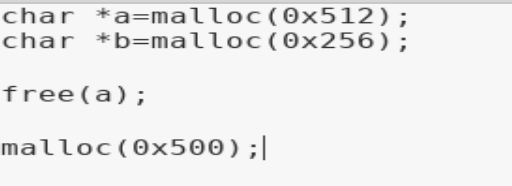
Shellphish給出的例子中先申請了0×512和0×256大小的兩個堆,然后釋放掉0×512大小的堆(申請0×256大小的堆的作用是避免釋放不是mmap分配的堆a的時候合并到topchunk),實例中再次申請0×500大小的堆由于largebin的best fit分配策略glibc會分割堆后返回堆a,即堆c等價于堆a,這時我們輸出堆a的內容即輸出修改后的堆c的內容。
glibc的first fit分配策略可用于use after free(uaf,釋放后重用)的利用,即修改新分配堆的內容等價于修改被釋放的堆,uaf一般是由于釋放堆后指針未置零造成的,不過在uaf的利用過程中我們一般使新分配的堆的大小等于被釋放的堆的大小。
1.1 fastbin_dup
fastbin下doublefree的一個示例(未加tcache機制)。
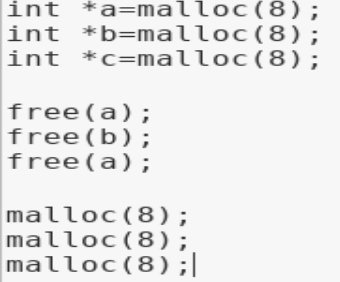
Shellphish給出的例子中先申請了3個0×8大小的堆(同樣地申請c的原因是避免合并到topchunk),然后釋放a(此時再次釋放a構成doublefree雙重釋放,但是由于glibc在釋放fastbin大小的堆時檢查且僅檢查fastbin頭部的堆和要釋放的堆是否相等,若相等則報錯),為了繞過glibc在釋放堆時對bin頭結點的檢查,我們free(b),此時fastbin如下(b=0×602020,a=0×602000;由于fastbin是單鏈表且LIFO,后釋放的b被插入到鏈表頭)
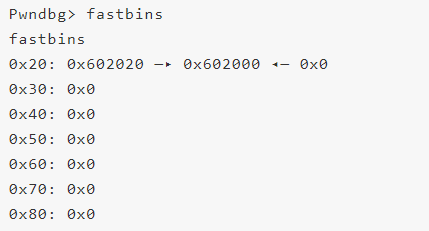
然后我們再次free(a),由于此時bin頭結點指向b,所以對頭結點的檢查被繞過,free(a)之后
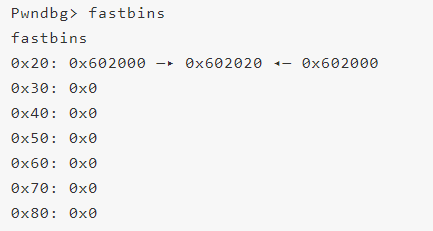
可以看到此時fastbin中有兩個a,如果此時我們申請三個0×8大小的堆,則依次從fastbin頭部取得到a、b、a三個堆。
1.2 fastbin_dup_into_stack
fastbin下doublefree的利用示例(未開啟tcache機制)。主要思路是在doublefree時我們有一次修改一個存在于fastbin鏈表的堆的機會,然后通過偽造堆的內容可以使得fastbin鏈入偽造的堆,再次申請內存可以得到偽造地址處的堆。
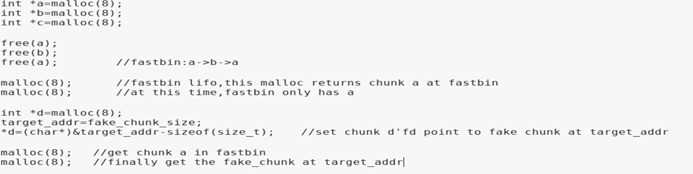
示例中先申請了3個0×8大小的堆,然后通過free(a)、free(b)、free(a)構成一次doublefree(原理同fastbin_dup),此時fastbin的連接狀態是a->b->a。再次申請兩個0×8大小的堆,由于fastbin的lifo,此時fastbin中只剩a,且此時堆a存在于fastbin和用戶申請的堆中,即我們可以控制一個存在于fastbin的堆的內容。容易想到的一種利用方式是偽造fastbin鏈表的內容,進而達到在偽造地址處申請堆的效果。
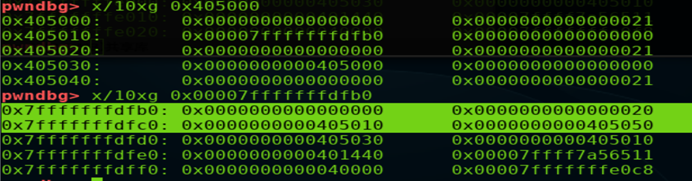
示例中在棧中偽造了一個0×20大小的堆(偽造堆頭如下圖選中部分,其中a=0×405000,&stack_var=0x00007fffffffdfb0),此時堆a的fd指向&stack_var,即fastbin:a->stack_var,此時第二次申請不超過0×18大小的堆(64位系統,跟申請堆時字節對齊有關,返回的堆的大小會被轉化成滿足條件的最小2*size_sz的倍數,最大0×10+8,8字節可占用下一個堆的prev_size)即可返回棧地址處的偽造堆。
1.3 fastbin_dup_consolidate
fastbin attack構成doublefree的一個示例。原理是利用申請一次largebin大小的堆會將fastbin的堆進行合并進入unsortedbin的處理流程,此時再次free fastbin中的堆會繞過free時對fastbin鏈表頭節點的檢查進而構成一次doublefree。
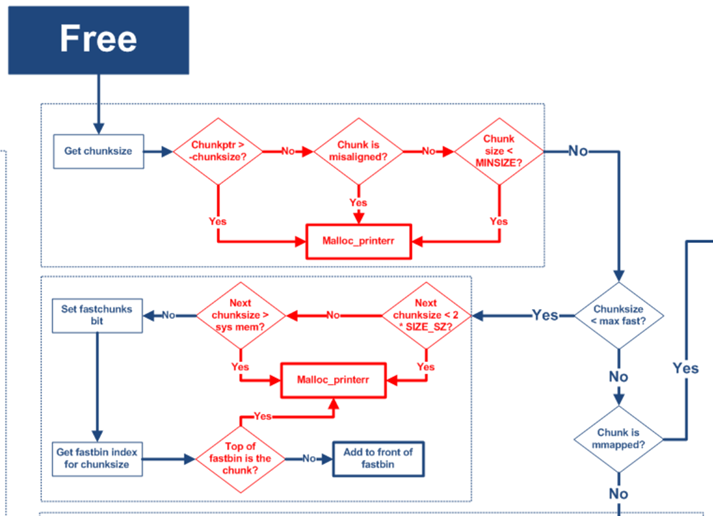
從下圖free的流程中我們可以看出free時只會檢查釋放fastbin大小的堆時被釋放的堆是否和fastbin的頭結點是否一致,而在申請0×400的largechunk時,fastbin鏈表非空,fastbin中的堆會進行合并并且進入unsortedbin的處理流程,在unsortedbin的處理流程中符合fastbin大小的堆會被放入smallbin,這樣就繞過了free時對fastbin頭結點的檢查,從而可以構成一次對fastbin大小的堆的doublefree。
1.4 unsafe_unlink
堆可以溢出到下一個堆的size域且存在一個指向堆的指針時堆溢出的一種利用方式。
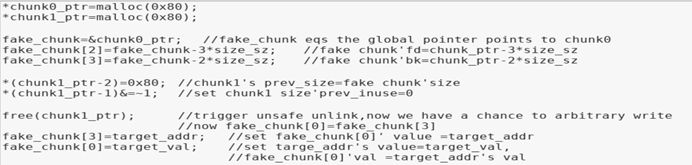
Unsafe unlink利用的前提是可以溢出到下一個堆的size域,利用的大致思路是在chunk0構造fakechunk且fakechunk可以繞過unlink雙向鏈表斷鏈的檢查,修改chunk1的pre_size使之等于fakechunk的大小,修改chunk1中size域的prev inuse位為0以便free(chunk1)時檢查前后向堆是否空閑時(這里是后向堆,即物理低地址)觸發unlink雙向鏈表斷鏈構成一次任意地址寫。下面看一下unlink的具體細節和原理。
示例中首先申請了兩個0×80大小的堆chunk0和chunk1(非fastbin大小,因為fastbin大小的堆為了避免合并pre_inuse總是為1),然后在chunk0中構造fake_chunk
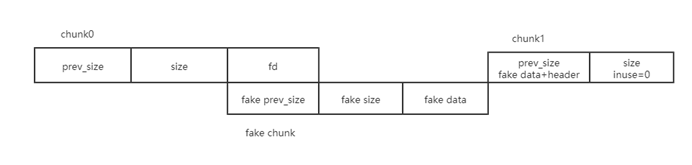
需要注意的是,我們構造的fake chunk的起點是chunk0的數據部分即fd,fake chunk的prev size和size域正常賦值即可(最新的libc加入了cur_chunk’size=next_chunk’s prev_size),fake chunk中關鍵的部分是fake data,這一部分要繞過unlink雙向鏈表斷鏈的檢查,即fd->bk=p&&bk->fd=p

chunk的結構體如下

所以由結構體的尋址方式可得
(fd->bk=fd+3* size_t)=p
(bk->fd=bk+2* size_t)=p
所以可得
fd=p-3* size_t
bk=p-2* size_t
即fakechunk中fd和bk域如上構造即可繞過unlink雙向鏈表的斷鏈檢查。
構造完fakechunk還需要修改下chunk1的prevsize和size的數據,
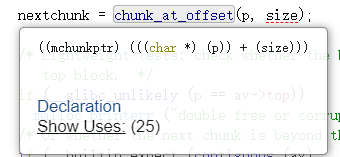
首先是prevsize要修改成fakechunk的大小(包含堆頭,原因是glibc尋找下一個堆的宏如下,即將當前堆偏移size的數據視為下一個堆)
chunk1 size部分的inuse位要置0,即標識物理相鄰低地址堆為空閑狀態(這也是unlink無法使用fastbin大小的堆的原因,fastbin大小的堆為了減少堆合并的次數inuse位總是置1)
最后構造的fakechunk+chunk1部分數據如下,chunk0堆頭0×405000,fakechunk堆頭0×405010,chunk1堆頭0×405090,圖中選中部分為fakechunk

其中fakechunk的fd要使用指向堆節點的指針(如指向該節點的全局變量,非堆地址)的原因是unlink源碼中傳入的第二個參數是struct malloc_chunk * p。下面分析下unsafeunlink是如何導致任意地址寫的。閱讀源碼可以發現smallbin范圍內非fastbin范圍的堆在unlink時只檢查了雙向鏈表的完整性,然后執行了雙向鏈表摘除節點的操作。

斷鏈的過程
fd->bk=bk 即(fd->bk=p)=(bk=p-2* size_t)
bk->fd=fd 即(bk->fd=p)=(fd=p-3* size_t)
最終相當于
p=p-3* size_t
即獲得了兩個相等的指針(struct malloc_chunk * p),試想如果此時我們可以修改一個指針指向的地址同時可以修改另一個指針指向的內容不就可以構成一次任意地址寫了嗎?巧的是(;p)我們恰好可以達到這樣的效果。
此時我們修改fake_chunk[3]為要寫的地址,修改fake_chunk[0]為要寫的地址的內容即可。原因是fake_chunk[3]-3*size_t=fake_chunk,這里相當于給fake_chunk指向一個新的地址;fake_chunk[0]訪問的是&fake_chunk[0]地址處的值,即上一步修改的地址處的內容。這樣就構成了一次任意地址寫^.^

1.5 house_of_spirit
利用fastbin范圍的堆釋放時粗糙的檢查可以在任意地址處偽造fastbin范圍fakechunk進而返回fakechunk的一種利用方式。思路是在指定地址處偽造fastbin范圍的fakechunk,釋放掉偽造的fakechunk,再次申請釋放掉的fakechunk大小的堆即可得到fakechunk。

其中fastbin范圍的堆釋放時的檢查如下圖所示,
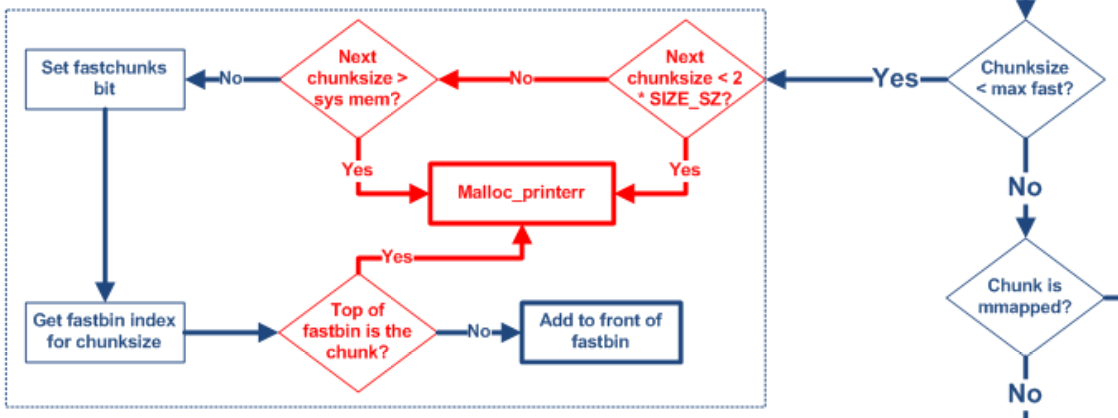
我們構造的fakechunk只需要繞過free時的檢查即可:
0.2*size_sz
1.偽造的fakechunk不能是fastbin的頭結點,即不能直接構成doublefree
利用house of spirit可以得到fakechunk處的堆,同時如果我們有fakechunk處寫的權限利用fastbinattack即可劫持控制流。
1.6 poison_null_byte
由于glibc在返回用戶申請的堆時不恰當的更新堆的presize域和錯誤的計算nextchunk的位置可以導致一次堆重疊。
方法是先申請堆然后釋放掉中間位置的一個堆bchunk(假設堆的大小都如圖所示),假設存在一個off by null的漏洞,由于前一個堆是占用狀態時prevsize域用來存儲前一個堆的數據,這樣我們可以從achunk溢出到bchunk的size域最低位將其置0。
此時申請一個0×100大小的堆會返回釋放掉的bchunk位置的堆。原因是在申請一個smallbin且非fastbin范圍的堆時會檢查smallbin是否為空,本例中smallbin為空則執行smallbin的初始化過程,即將可能的fastbin中的堆進行合并進入unsortedbin的處理流程,申請的堆的大小是smallbin范圍,此時會取largebin頭結點的一個堆進行切割返回(同樣地為了減少內存碎片,largebin的堆從大到小排序)。這里largebin中只含一個0×200大小的堆,則直接對其進行切割然后返回給用戶。

然后再次申請一個0×80大小的堆。原因是0×100+0×80+兩個堆頭=0×200使之結束的位置正好落于cchunk
這時free(b1)、free(c)釋放掉兩個堆,由于nextchunk即cchunk的preinuse為0會觸發前向合并(向物理高地址)過程。原因是fake了一個cchunk的presize,系統修改的是我們的fake presize,即下圖的0xf0,系統依然認為bchunk的位置有一個0×210的fakechunk。
此時再次申請一個0×300大小的堆,由于合并后bchunk和cchunk的大小為0×300,系統會返回合并后的bchunk。又由于此時b2chunk沒有被釋放處于占用態,b2chunk位于合并的bchunk內,此時構成一次堆重疊。
1.7 house_of_lore
利用偽造smallbin鏈表來最終達到一次任意地址分配內存的效果。前提是可以在要分配的地址處偽造堆(修改結構體中fd、bk的指向),且可以修改victim堆(被釋放的smallbin堆)的bk指針。
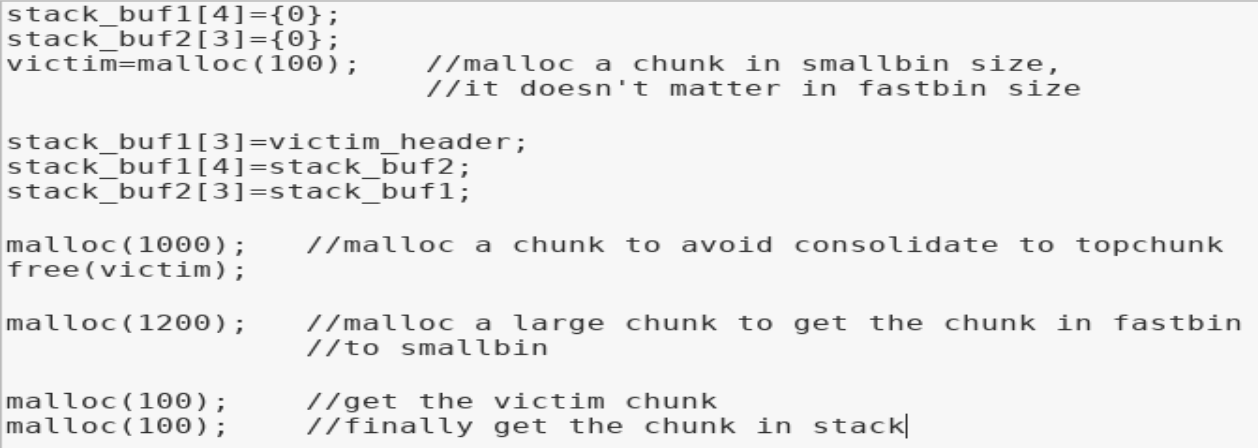
方法是在要分配的內存地址(如棧地址)處構造一個fake smallbin chunk鏈,使之如下圖所示。
然后申請一個堆防止釋放victim的時候合并到topchunk,釋放掉victim,此例中victim會進入fastbin鏈表。
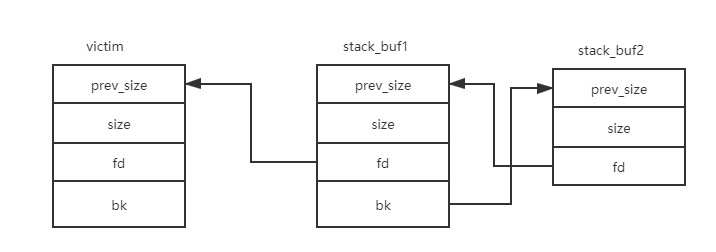
再次申請一個largechunk,觸發fastbin的合并過程并使fastbin的堆進入unsortedbin的處理流程,victim處于smallbin的范圍最終被鏈入smallbin頭結點。而由于我們事先構造了如上的fake smallbin鏈,此時smallbin的鏈接情況是smallbin:victim->stack_buf1->stack_buf2。
由于smallbin的exact fit和fifo策略,此時申請一個victim大小的堆會直接返回bin結點bk指向的victim(bin的結構體是mchunkptr*),然后斷鏈并修改bin的bk指針指向victim的bk節點即stack_buf1。glibc取smallbin的chunk源碼如下。

此時stack_buf1的結構如下(其中0x7fffffffdfb0=stack_buf1,0x7ffff7dd4b98=smallbin,0x7fffffffdf90=stack_buf2),即此時smallbin:stack_buf1->stack_buf2
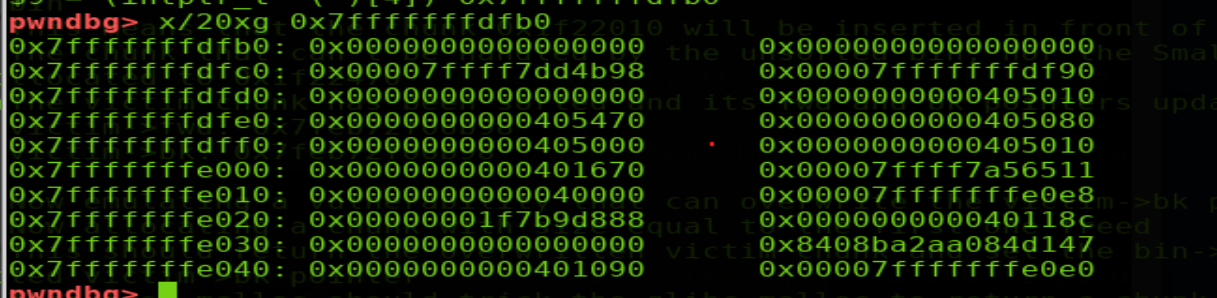
這樣此時再申請一個victim大小的堆直接取smallbin的bk指向的stack_buf1即得到相應地址處的堆,達到了任意地址分配內存的效果。
1.8 overlapping_chunks
通過修改一個位于空閑鏈表的堆的size域可以構成一次堆重疊

過程如上。修改位于bin的p2的size域,修改后p2結構如下(p2=0×405110,選中部分為p2 data部分)
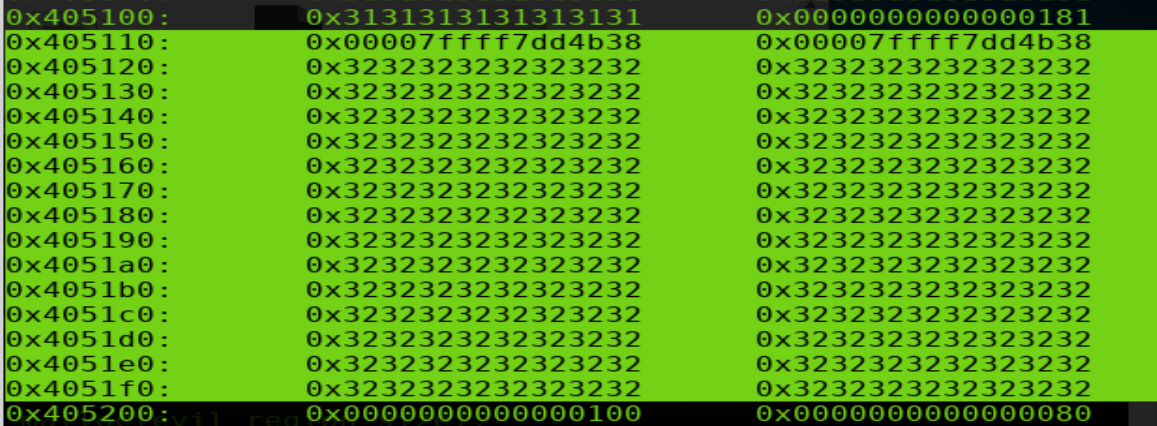
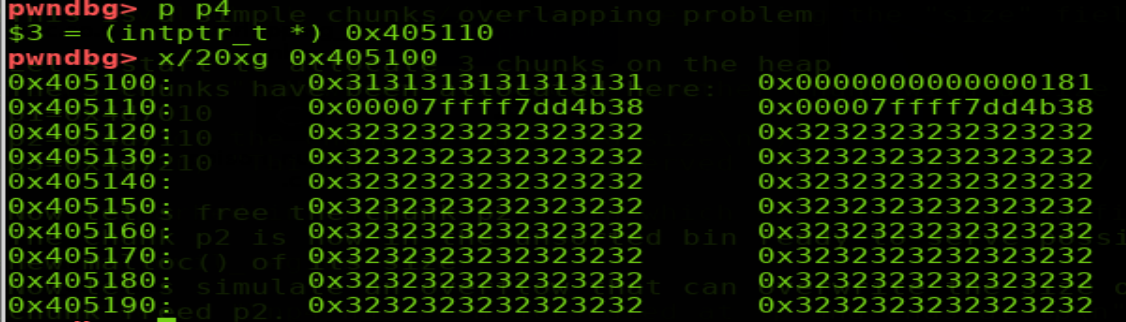
此時申請一個修改后的p2 size的堆會得到從p2位置起始的fake size大小的堆p4,如下圖
1.9 overlapping_chunks_2
通過堆溢出修改下一個占用態堆的size域構成一次堆重疊
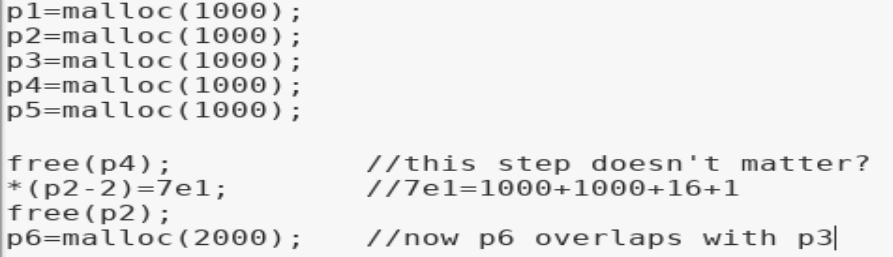
shellphish給出的示例中先free掉p4(我個人感覺這一步是沒有必要的,shellphish可能是出于演示的目的考慮?因為稍后可以看到我們可以觀察到p5的prevsize在free(p2)后會發生變化,如果有小伙伴看到這里可以一起交流,snip3r[at]163.com)。free p4后p5的prevsize為3f0
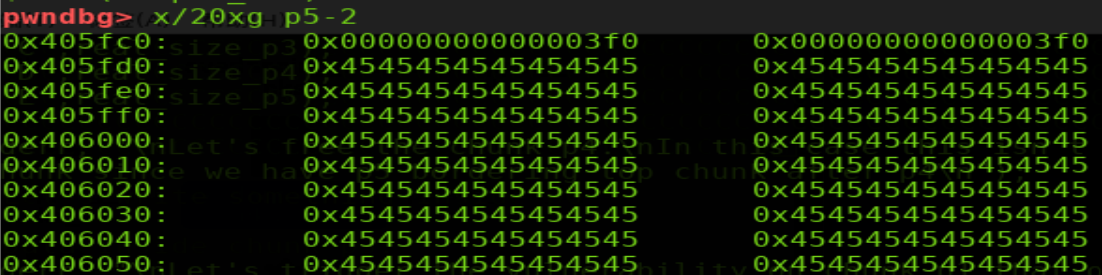
然后修改p2的size域為p2+p3+標志位,釋放掉。此時glibc會認為p2的size域的大小包圍的堆是要被釋放的,會錯誤的修改p5的prevsize值。free p2后p5的prevsize為bd0
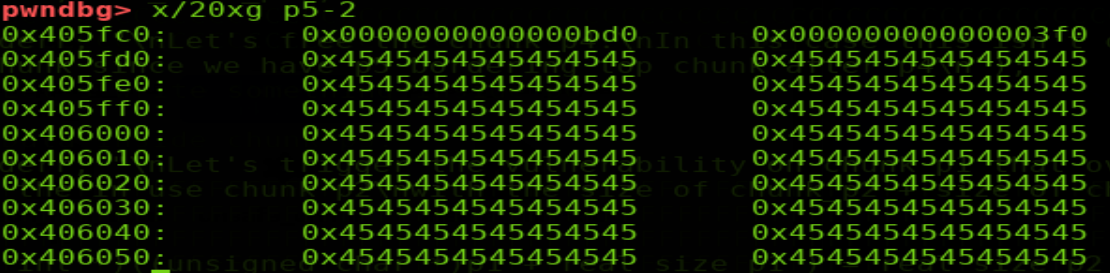
此時由于物理相鄰的前向堆p4處于空閑態,fake p2會和p4合并鏈入largebin。然后申請2000大小的largechunk會將上述合并后的堆切割后返回p2起始的堆,從而構成一次堆重疊。
1.10 house_of_force
利用topchunk分配內存的特點可以通過一次溢出覆蓋topchunk的size域得到一次任意地址分配內存的效果。

首先通過一次堆溢出覆蓋topchunk的size域為一個超大的整數(如-1),避免申請內存時進入mmap流程。
然后申請一個evilsize大小的堆改變topchunk的位置。evilsize的計算如下,這么計算的原因是當bin都為空時會從topchunk處取堆

修改topchunk到目標地址后在申請一次堆即可對目標地址處的內存進行改寫。
1.11 unsorted_bin_into_stack
通過修改位于unsortedbin的堆的size域和bk指針指向目標fakechunk,在目標地址構造fakechunk(構造size和bk指針。我們也可以不修改victim的size,malloc兩次得到目標地址的fakechunk;原理都是構造fake unsortedbin鏈表)可以得到一次任意地址申請內存的機會。

其中如果要偽造victim的size的話要滿足check 2*SIZE_SZ (> 16 on x64) && < av->system_mem
通過溢出修改位于unsortedbin的victim的size和bk,并構造fakechunk,最終構造出如下fake smallbin鏈表
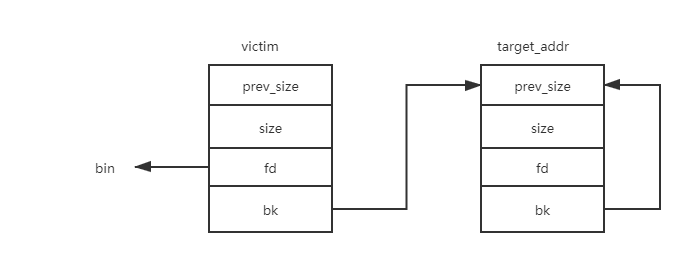
在下一次申請內存時glibc遍歷unsortedbin找到exact fit的堆塊并返回,最終可以得到目標地址處的偽造堆。
1.12 unsorted_bin_attack
通過偽造unsortbin鏈表進行unsortedbin attack泄露信息(libc基址)的一種方法。

方法是構造如下fake unsortedbin鏈表,

這樣在申請得到victim后會將victim斷鏈,從而target_addr fake chunk的fd會指向相應的bin,進而可以泄露libc基址。(當然也可以泄露bk之類位置的其他信息,如果有的話;p)
1.13 large_bin_attack
利用malloc進行unsortedbin處理時插入largebin通過修改largebin鏈表上的堆的bk、bk_nextsize均可以得到任意地址寫的機會。

首先要申請如上圖3個堆和相應的為了避免合并到topchunk的barrier(只申請barrier3應該就夠用了,shellphish這么寫可能是在之后復雜的申請釋放中不在考慮合并到topchunk的情況),其中p1要保證是smallbin且非fastbin范圍(且保證在后續申請堆時堆大小夠用),p2、p3要保證是largebin范圍。
(1)然后依次釋放p1、p2,由于非fastbin范圍的堆在釋放后會首先鏈入unsortedbin,此時unsortedbin的情況是。(簡單說就是unsortedbin:p2->p1,其中各個指針的指向如圖)
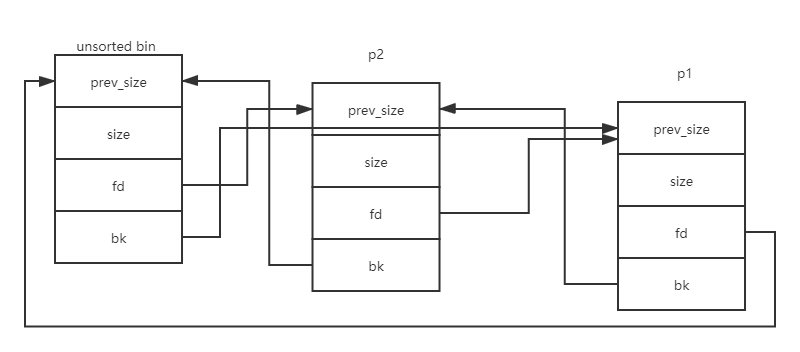
(2)此時申請一個0×90大小的堆,從glibc的源碼中可以看到遍歷unsortedbin的過程是從bin頭結點的bk指針開始遍歷。這樣取到的第一個堆是0×320大小的p1,p1滿足0×90的申請,glibc會從p1中分割出0×90的大小,然后繼續遍歷unsortedbin直至遍歷結束;此時得到鏈表的第二個堆0×400大小的p2,p2非smallbin范圍且largebin為空,被鏈入largebin

此時unsortbin:(p1-0×90),largebin:p2.
(3)然后釋放0×400大小的p3,p3非fastbin范圍被鏈入unsortedbin頭結點(fd指向p3)。
(4)此時利用溢出或其他手段修改largebin中的p2的bk、bk_nextsize(或、且)和size。可以看到p2修改前的size為0×411,shellphish把它修改成了0x3f1,這樣做是因為largebin中鏈接的一定范圍的堆是從大到小降序排列的,修改后0×400大小的p3被鏈入largebin時會被鏈入頭結點。
在做好以上的準備工作后再次申請一個0×90大小的堆,同(2)過程依然由p2分割得到堆,由于p3>修改后的p2的size,p3被鏈入largebin頭結點。鏈入的過程類似unlink,類似的我們得到了一次任意地址寫的機會。

1.14 house_of_einherjar
利用一次off by null修改下一個占用態chunk的prev_inuse位,同時修改下一個下一個占用態chunk的prev_size值,利用top chunk和后向合并(物理低地址)機制得到一次任意地址分配內存的機會。這種off by null利用的前提是可以在目標地址處(最終分配內存的地址處)構造fakechunk。

利用的方法是在目標地址處構造fakechunk,由于稍后會看到fakechunk處會觸發unink,為了繞過雙向鏈表完整性的檢測fd、和bk均可置為fakechunk。其中設置fakechunk的prev_size和size的值是可以但沒必要的。
由于占用態的堆prev_size會用來存儲前一個堆的數據,所以天然的prev_size域可以修改;當存在off by null時可以將下一個占用態堆的prev inuse置0。我們修改a的prev_size為fake_size,b的prev_inuse為0。這時我們釋放掉b,由于b和topchunk緊鄰,b會和topchunk合并;同時由于b的prev_inuse為0會觸發后向合并(物理低地址),glibc尋找下一個空閑堆的方式是chunk_at_offset(p, -((long) prevsize)),即將當前位置偏移prev_size的位置視為nextchunk,這樣(b+b.prev_size)得到下一個堆位于fakechunk,合并到topchunk并最終得到新的topchunk起點為fakechunk。此時再次申請堆從topchunk處取即可得到target處的fakechunk。

這樣通過反推target=b_chunk_header-fake_size得到fake_size=b_chunk_header-target。
2.總結
本文到這里就結束了,linux pwn基礎知識的介紹到這里也就結束了,但是glibc還在不斷更新,堆管理一些細節也在不斷微調,一些新的提高性能的機制如tcache也開始應用于新版本的libc,關于不斷更新的新版本libc的漏洞利用方式的探索還遠遠沒有結束。




)




)

)







