
R與RStudio
R是一種統計學編程語言,在科學計算領域非常流行。它是由Ross Ihaka和Robert Gentleman開發的,是 "S "編程語言的開源實現。R也是使用這種語言進行統計計算的軟件的名字。它有一個龐大的在線支持社區和專門的軟件包,可以為幾乎所有的應用和研究領域提供豐富的功能,幾乎沒有什么事情是你在R中做不到的。
如果你已經熟悉了像Minitab或SPSS這樣的統計軟件,那么主要的區別在于R沒有圖形化的用戶界面(graphical user interface),這意味著沒有可以點擊的按鈕,也沒有下拉菜單。R可以完全通過在文本界面中輸入命令來運行。這似乎有點讓人望而生畏,但這也意味著更多的靈活性,因為你不需要依賴預先設定的各種軟件進行分析。
如果你覺得說服力還不夠強,為什么我們要用R,而不是 MATLAB、Minitab、甚至是Microsoft Excel等眾多統計軟件中的一個?好吧,R非常好,因為以下三點:
- R是免費和開放源代碼的,而且永遠都是免費的!任何人都可以使用它的代碼,并且可以看到它的數據。任何人都可以使用這些代碼,并且可以看到它到底是如何工作的。
- 因為R是一種編程語言而不是圖形界面,用戶可以很容易地將腳本保存為小的文本文件,以便將來使用,或者與合作者分享。
- R有一個非常活躍和有幫助的在線社區--通常情況下,只要快速搜索一下,就會發現有人已經解決了你的問題。
下載R和RStudio
正如我們之前所說,R本身并沒有圖形化的界面,但大多數人都是通過圖形化平臺與R進行交互,這些平臺提供了額外的功能。我們將使用一個叫RStudio的IDE作為R的圖形化前端,這樣我們就可以在一個地方訪問我們的腳本和數據,找到幫助,預覽圖和輸出。
你可以從CRAN(The Comprehensive R Archive Network)下載R。選擇適合你的操作系統的版本。
然后,從RStudio網站下載RStudio(選擇免費的開源桌面版)。
打開RStudio。依次選擇左上角的File → New File → R script。
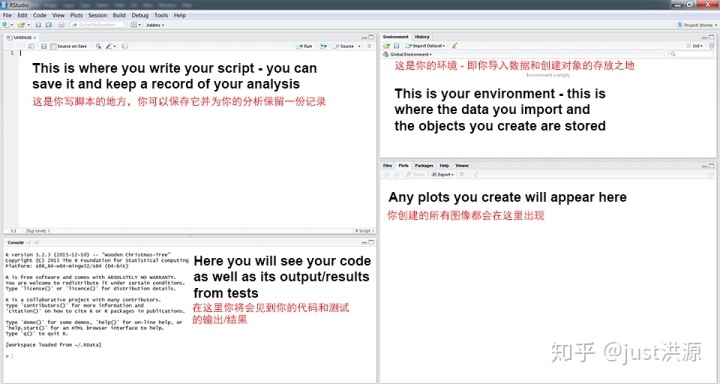
你現在會看到一個像上面這樣的窗口。你可以直接在左下角的控制臺(console)中輸入代碼。在代碼行的最后按回車鍵就可以運行代碼(試著輸入2+2并運行它)。你也可以在左上方窗口的腳本文件中寫下你的代碼。要從腳本中運行一行代碼,在Windows上按Ctrl+Enter,或在Mac上按Cmd+Enter。在右上角的環境窗口(environment window)中,你可以看到當前工作區(workspace)的概覽。你會看到你已經導入的數據,已經創建的對象,已經定義的函數等。最后,右下角的面板有多個標簽頁,會預覽你的繪圖,并允許你在文件夾中進行導航,查看你當前已經安裝和加載的軟件包。
關于腳本的注意事項:請記住,如果你直接在控制臺中輸入代碼,它不會被R保存:它會運行并消失(盡管你可以通過鍵盤上的 "up "鍵來訪問最后的幾個操作)。相反,通過將代碼輸入到腳本文件中,你將創建一個可重現的分析記錄。在腳本中寫代碼就像在Word中寫論文一樣:它可以保存你的進度,而且你可以隨時從頭開始,或者對它做一些修改。(記得經常點擊保存(Ctrl+S),這樣你就能真正的保存你的腳本了!)
在編寫腳本時,通過在一行文字前插入井號#來添加注釋,描述你正在做的事情是很有用的。R 會把任何以#開頭的東西看成是文本,而不是代碼,所以它不會嘗試運行它,但這些文本將為閱讀你腳本的人(包括未來的你!)提供有價值的代碼信息。就像任何文章一樣,腳本將從結構和清晰度中受益。關于工作區的快速說明:工作區會在電腦內存中存儲一個會話使用過的所有內容。當你退出時,R會問你是否要保存當前工作區。通常你幾乎不需要保存工作區,最好是每次都點擊 "不",然后下次打開時可以從頭開始運行腳本。(一定要確保保存你的腳本!)
控制臺 (console) 中的操作
當我們在使用R工作時,經常會使用命令行(command line)來完成我們的任務。在命令行中我們輸入命令,它就會對這些命令做出響應。在最簡單的情況下,如果我們只要輸入一個數字,它就會簡單的用這個數字來響應。進入RStudio左下角的控制臺,輸入數字3。你應該會看到這樣的結果。
> 3
[1] 3> 符號是命令提示符(command prompt),提示你輸入一些東西。下一行([[1] 3)是R的答案。讓我們試試更復雜一點的東西。
> 3 + 4
[1] 7只要R能夠明白你輸入了什么,它就能回應任何你的輸入。現在,讓我們試著輸入一個單詞。
> hello
Error: object 'hello' not found 為什么會報錯呢?因為當R遇到一個字母或單詞時,會假定它指的是一個變量(variable)的名字--想想高中代數中的X。我們稍后再講變量,但如果我們想讓R打印出hello這個詞,那么我們需要用引號來包含它,告訴R它是一個字符串(character string)。
> "hello"
[1] "hello" R中的變量有很多類型,你已經看到了兩個例子:整數(如數字3)和字符串(如 "hello "一詞)。另一個重要的是實數(real numbers),也就是我們在統計學中要處理的最常見的一種數。實數沒有整數的限制,包括了整數之間的空間,舉個例子:
> 1/3
[1] 0.33在現實中,結果應該是0.33,后面接著無數的3,但R在這個例子中只向我們展示了兩位小數。
另一種變量被稱為邏輯變量(logical variable),因為它基于邏輯學中的思想,即一個語句可以是真或假。在R中,這些變量都是大寫的(TRUE和FALSE)。
為了判斷一個語句是否為真,我們使用邏輯運算符(logical operators)。你已經熟悉其中的一些運算符,如大于(>)和小于(<)運算符。
> 1 < 3
[1] TRUE
> 2 > 4
[1] FALSE通常情況下,我們想知道兩個數字是否相等或不相等。在R中,有一些特殊的運算符可以做到這一點:==表示等號,和 !=表示不等號。
> 3 == 3
[1] TRUE
> 4 != 4
[1] FALSE開始寫你的腳本
現在,我們可以在RStudio左上角的文本編輯器內編輯自己的腳本了。先記錄誰在寫,日期和主要目標--在我們的例子中,確定在愛丁堡有多少個不同分類群的物種被記錄下來。這里有一個例子,你可以復制,粘貼和編輯到你的新腳本。
# Coding Club Workshop 1 - R Basics
# Learning how to import and explore data, and make graphs about Edinburgh's biodiversity
# Written by Gergana Daskalova 06/11/2016 University of Edinburgh接下來的幾行代碼通常會加載你的分析所需要的包。包(package)是一個可以加載到R中的程序集,以提供額外的功能。例如,你可能會加載一個用于格式化數據,或者制作地圖的包。
要安裝一個包,鍵入install.package("package-name")。你只需要安裝一次包,所以在這種情況下,你可以直接在控制臺框中輸入,而不是在腳本中保存這一行,然后每次重新安裝包。
安裝完成后,你只需要使用library(package-name)加載包就可以了。今天我們將使用dplyr包來提供額外的命令來格式化和處理數據。
接下來的代碼行應該定義你的工作目錄(working directory)。這是你計算機上的一個文件夾,R將在其中尋找數據,保存你的作圖等。為了使你的工作流程更容易,將所有與一個項目相關的東西都保存在同一個地方是很好的做法,因為這將為你節省大量的時間,輸入計算機路徑或尋找被R-know-where保存的文件。例如,你可以將你的腳本和本教程的所有數據保存在一個名為 "Intro_to_R "的文件夾中(避免文件名中的空格是很好的做法) 。對于較大的項目,可以考慮用項目名稱的根目錄(例如 "My_PhD")作為你的工作目錄,其他的文件夾也可以嵌套在其中,將數據、腳本、圖像等分開(例如:My_PhD/Chapter_1/data、My_PhD/Chapter_1/plots、My_PhD/Chapter_2/data等)。
要知道你現在的工作目錄在哪里,請運行代碼getwd()。如果你想改變它,可以使用setwd()。將你的工作目錄設置為你剛才從GitHub上下載的文件夾。
install.packages("dplyr")
library(dplyr)
# 注意,安裝包的時候有引號,但加載包的時候沒有引號,記住#可以讓你在代碼中添加有用的注釋! setwd("C:/User/CC-1-RBasics-master")
# 這是一個示例的文件路徑,請修改成你自己的文件路徑。注意,在Windows電腦上,復制粘貼的文件路徑會用反斜杠分隔文件夾("C:folderdata"),但在R中輸入的文件路徑應該使用正斜杠(forward slashes)("C:/folder/data")。
導入和檢查數據
練習是學習任何新語言的最好方法,所以讓我們直接開始,用一個公開的動物、植物和真菌物種發現記錄的數據集來做一些自己的統計分析。我們下載了2000-2016年的記錄(從NBN Gateway中下載),并保存為edidiv.csv。首先,你需要下載數據。
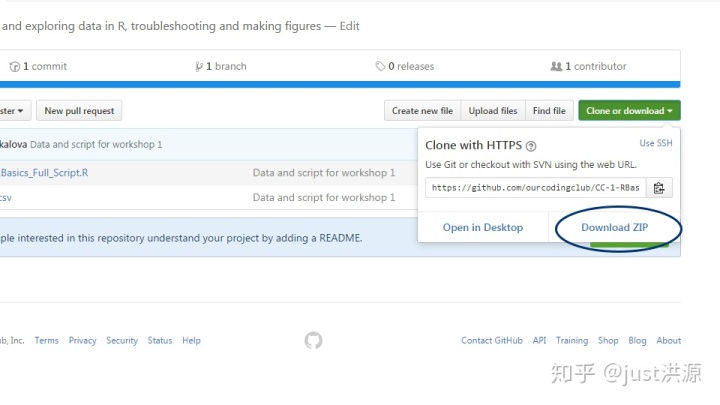
按照鏈接,點擊 "下載Zip",然后保存并解壓到你電腦上的某個文件夾。
你可以在這個Github倉庫中找到完成本教程所需的所有文件。
R處理的是.csv(逗號分隔的值)文件,如果你在Excel中輸入數據,你需要點擊另存為并選擇csv作為文件擴展名。在Excel中輸入數據時,不要在行名中加上空格,因為它們會使R以后混淆(例如:使用像height_meters這樣的東西而不是height (m)。有些計算機在保存.csv文件時,會用分號 ; 而不是逗號 , 作為分隔符。這通常發生在你的計算機上的第一種或唯一的語言不是英語的情況下。如果你的文件被分號分隔,請使用read.csv2代替read.csv,或者在read.csv函數中使用參數 "sep"(用于分隔符):read.csv("your-file-path", sep = ";")。
edidiv <- read.csv("C:/Users/user/Desktop/Intro_to_R/edidiv.csv") # 這是基于我保存數據的文件路徑,你的文件路徑會有所不同。記得偶爾保存一下你的腳本! 如果你還沒有保存,嘗試著把它保存在和其他教程文件一樣的目錄下,并給它起一個有意義的名字。
關于對象的說明:R是一種基于對象的語言--這意味著你導入的數據,以及以后創建的任何值,都存儲在你命名的對象中。上面的代碼中的箭頭<-代表賦值操作 。這里,我們將csv文件分配給對象edidiv。我們可以將其命名為mydata或hello或biodiversity_recorded_around_Edinburgh_Scotland,但最好選擇一個獨特的、信息量大且簡短的名稱。在RStudio的右上角窗口中,你可以看到當前加載到R中的任何對象的名稱,看到你的edidiv對象了嗎?
當你把數據導入到R中時,它很可能會變成一個叫做數據框(dataframe)的對象。數據框就像一個表格,或電子表格--它有行和列,包含不同的變量和觀察結果。
一個真正重要的步驟是檢查你導入了的數據是否沒有任何錯誤。好的做法是始終運行這段代碼,并檢查控制臺中的輸出--你是否看到任何缺失的值,數字/名稱是否合理?如果你直接進入分析,你就有可能在以后發現R沒有正確讀取你的數據而不得不重新做,或者更糟糕的是,在不知不覺中分析出錯誤的數據。要想預覽更多的數據,你也可以在環境面板中點擊對象,在你打開的腳本旁邊的新選項卡中以電子表格的形式顯示。大的文件可能不會完全顯示,所以請記住你可能會丟失行或列。
head(edidiv) # 展示開始的幾行
tail(edidiv) # 展示最后的幾行
str(edidiv) # 告訴你變量是連續的、整數的、分類的還是字符的。str(object.name)是一個很好的命令,可以顯示你的數據結構。R運行過程中經常出現的錯誤是:R確定了一個變量是某種類型的數據,而它實際上不是。比如說,你可能有四個研究組,你把它們簡單地稱為 "1、2、3、4",雖然你知道它應該是一個分類分組變量(即因子(factor)),但R可能認為這是一列包含數字(numeric)(數字)或整數(integer)(整數)數據。如果你的研究組被稱為 "一、二、三、四",R可能會認為它是一個字符(character)變量(單詞或單詞字符串),如果你想比較組間的均值,這不會讓你的分析順利走下去!
你會注意到taxonGroup變量顯示為一個字符變量,但它應該是一個因子(分類變量),所以我們將強制把它變成因子。當你只想訪問一個數據框中的一列時,你會在對象名后面附加一個$標志的變量名。這個語法可以讓你查看、修改和/或重新分配這個變量。
head(edidiv$taxonGroup) # 只顯示該列的前幾行
class(edidiv$taxonGroup) # 告訴你我們要處理的是什么類型的變量:它現在是字符,但我們希望它是一個因子。edidiv$taxonGroup <- as.factor(edidiv$taxonGroup) # 轉換某一列的數據類型在最后一行代碼中,as.factor()函數把你在里面輸入的任何值都變成了一個因子(這里,我們指定了要從edidiv對象中轉換taxonGroup列中的字符值)。然而,如果你只運行箭頭右側的代碼,它將會工作一次,但不會修改存儲在對象中的數據。通過用箭頭將函數的輸出賦值給變量,原來的edidiv$taxonGroup實際上被覆蓋了:轉換后被存儲在對象中。再試著運行class(edidiv$taxonGroup)--你發現了什么?
# 更多的解釋
dim(edidiv) # 展示行數和列數
summary(edidiv) # 關于數據的總結
summary(edidiv$taxonGroup) # 為您提供數據集中的特定變量(列)的總結計算物種豐富度
我們的edidiv對象有2000年至2016年在愛丁堡收集的各種物種的發現記錄。 為了探索愛丁堡的生物多樣性,我們將創建一個圖表,顯示每個分類組中記錄了多少物種。 你可以在Excel中計算物種豐富度,但這有幾個缺點,尤其是在處理像我們這樣的大數據集時--你沒有辦法記錄你點擊了什么,如何排序數據,以及你復制/刪除了什么--錯誤可能會在你不知不覺中發生。而在R中,你有保存的腳本,所以你可以回去檢查所有的分析步驟。
物種豐富度是指在一個給定的地方或群體中不同物種的總數量。要知道我們在愛丁堡有多少鳥類、植物、哺乳動物等物種,我們首先需要將edidiv分成多個對象,每個對象只包含一個分類組的行。我們用dplyr程序包中的filter()函數來完成。
Beetle <- filter(edidiv, taxonGroup == "Beetle")
# 函數的第一個參數是數據框,第二個參數是你要過濾的條件。因為我們在這里只想要甲蟲,所以我們說:變量 taxonGroup 必須嚴格等于 (==) Beetle - 丟棄數據集中的其他東西。(R是區分大小寫的,所以注意拼寫很重要! "beetle "或 "Beetles "在這里是行不通的。)Bird <- filter(edidiv, taxonGroup == "Bird") # 你可以為剩下的分類群創建對象。如果你忘記了物種的名字和拼寫,請輸入 summary(edidiv$taxonGroup)你需要對數據中的所有分類群進行這些步驟,這里我們給出了前兩個的例子。如果你看到一個錯誤,說R無法找到Beetle或類似的對象,那么很可能是你沒有安裝和/或加載dplyr包。返回并使用install.packages("dplyr")安裝它,然后使用 library(dplyr)加載它。
一旦你為每個分類群創建了對象,我們就可以計算物種豐富度,也就是每個組中不同物種的數量。為此,我們將把兩個函數嵌套在一起: unique(),用于識別不同的物種,和 length(),用于計數。你可以在控制臺中分別嘗試一下它們,看看它們返回的結果是什么!
a <- length(unique(Beetle$taxonName))
b <- length(unique(Bird$taxonName))
# 你可以為你的對象選擇任何你想要的名字,這里我用了a、b、c、d......為了簡潔起見,我用了a、b、c、d......如果你在控制臺中鍵入a(或者無論你如何命名你的計數變量),它會返回什么?它是什么意思呢?它應該代表記錄中獨特的甲蟲物種的數量。
再次,計算數據集中其他分類群的物種豐富度。你可能注意到這是相當枯燥的,并且使用了大量的復制和粘貼!-- 在數據集中,這不是特別有效的方法。
創建一個變量并畫出它
現在我們有了每個分類群的物種豐富度,我們可以把所有這些值組合成一個向量(vector)。向量是R對象的另一種存儲值的類型。相對于數據框,數據框有兩個維度(行和列),向量只有一個。當你調用數據框中的一個列時,就像我們之前用edidiv$taxonGroup調用數據框中的一個列時,你基本上就是在產生一個向量--但你也可以從頭開始創建它們。
我們使用c()函數(c代表的是聚合(concatenate))。我們還可以用names()函數來添加標簽,這樣就可以知道數值的來源。
biodiv <- c(a,b,c,d,e,f,g,h,i,j,k) # 我們正在將所有的值串聯在一起;注意你計算出的對象名稱和它們的名稱。
names(biodiv) <- c("Beetle","Bird","Butterfly","Dragonfly","Flowering.Plants","Fungus","Hymenopteran","Lichen","Liverwort","Mammal","Mollusc")請注意。
<-和,后面的空格是為了方便閱讀代碼而添加的。- 所有的標簽都已經縮進到了新的行中--否則這行代碼會變得很長,很難讀懂。
- 注意檢查你的矢量值和標簽是否匹配正確--你不會想把甲蟲的數量標注為地衣類的數量!你可以在此基礎上再加上一個新的標簽。保存一個腳本的好處是,我們可以回過頭來檢查我們確實把甲蟲的數量分配給了
a。更好的做法是給我們的對象起更有意義的名字,比如beetle_sp、bird_sp等。 - 如果你用鼠標突出顯示一個括號
),RStudio會在你的代碼中突出顯示其匹配的括號。缺少括號,特別是當你開始像我們之前用length(unique())之類的嵌套函數時,缺失的括號是你開始寫代碼時最常見的挫折和錯誤的來源之一!
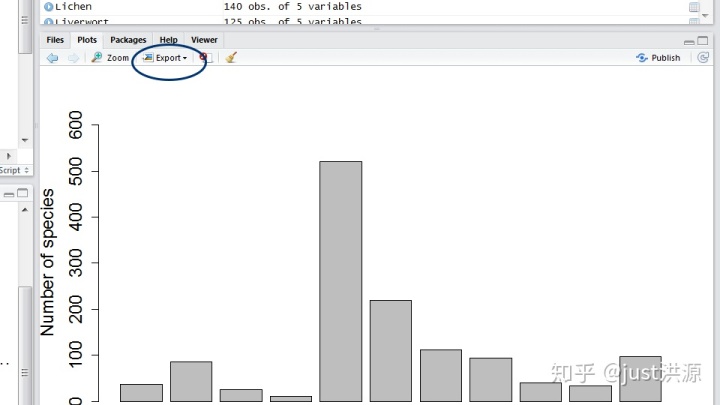
我們現在可以用barplot()函數來可視化物種豐富度。在RStudio中的右下角窗口中顯示出圖。
barplot(biodiv)但是有一些不太正確的地方需要修正--沒有軸標題,不是所有的列標簽都是可見的,而且植物種類的值(n = 521)超過了y軸上的最高值,所以我們需要擴展它。R的好處在于,你不需要自己想出所有的代碼--你可以使用help()函數,看看需要添加哪些參數。看一下幫助的輸出,你需要添加哪些代碼?
help(barplot) # 關于barplot()函數的幫助
help(par) # 對于一般繪圖的幫助我們還想保存我們的作圖。要做到這一點,請單擊 "Plots "窗口中的導出。如果你不更改目錄,文件將保存在你的工作目錄中。你可以調整尺寸以使條形圖看起來像你喜歡的那樣,你還應該添加一個有意義的文件名--如果它叫Rplot01.png,當你以后試圖找到該文件時,它將無法提供有效信息。
你也可以通過將代碼封裝在png()和dev.off()函數中來保存你的文件,這兩個函數分別表示打開和關閉繪圖設備。
png("barplot.png", width=1600, height=600) # 查看此功能的幫助:你可以自定義圖像的大小和分辨率
barplot(biodiv, xlab="Taxa", ylab="Number of species", ylim=c(0,600), cex.names= 1.5, cex.axis=1.5, cex.lab=1.5)
dev.off()
# cex代碼在大于1時增加字體大小(小于1時減小)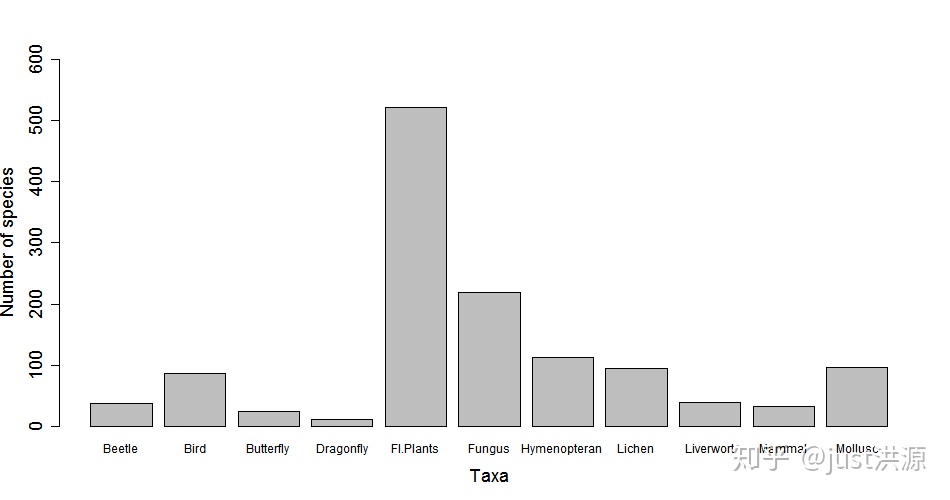
圖1 愛丁堡幾個分類群的物種豐富度。記錄基于2000-2016年期間國家生物資源網門戶的數據。
創建一個數據框并且畫出它
在上一節中,我們創建了向量,即一系列的值,每個值都有一個標簽。這種對象類型適用于只處理一類值的時候。但是,通常情況下,你會有多個變量,并且有多個數據類型--例如,有些是連續的,有些是分類的。在這種情況下,我們使用數據框架對象。數據框架是數值的表:它們有行和列的二維結構,其中每一列可以有不同的數據類型。 例如,一個名為 "Wingspan "的列將有不同鳥類上測量的數值(21.3,182.1,25.1,8. 9),而 "物種 "一列中的 "物種 "將包含有物種名稱的字符值("麻雀"、"金鷹"、"歐亞翠鳥"、"紅喉蜂鳥")。比如說它們都是數值型的,并且在行數上長度相同。
關于良好數據管理的注意事項:永遠保留一份原始數據的副本,就像你第一次收集的那樣。在R腳本中操作一個文件的好處是,修改是在腳本上,而不是在數據中。對于精通Photoshop的人來說,這就像在圖片上添加圖層一樣:你并沒有改變原始照片,只是在上面創建新的東西。話雖如此,但如果你寫了一長段代碼來整理一個大數據集并準備好分析,你可能不想每次需要訪問干凈的數據時都要重新運行整個腳本。因此,最好將你的新對象保存為一個新的csv文件,只需一個命令就可以加載,準備就緒。現在,我們將用我們的物種豐富度數據創建一個數據框,然后使用write.csv()保存它。我們將使用data.frame()函數,但首先我們將創建一個包含所有分類群名稱的對象(一列)和另一個包含每個分類群的物種豐富度的所有值的對象(另一列)。
# 創建一個名為 "taxa "的對象,該對象包含所有的taxa名稱。
taxa <- c("Beetle","Bird","Butterfly","Dragonfly","Flowering.Plants","Fungus","Hymenopteran","Lichen","Liverwort","Mammal","Mollusc")
# 把這個對象變成一個因子,即分類變量
taxa_f <- factor(taxa)# 將一個對象中的物種數量的所有值合并起來,稱為豐富度。
richness <- c(a,b,c,d,e,f,g,h,i,j,k)# 從兩個向量中創建數據框
biodata <- data.frame(taxa_f, richness)# 保存文件
write.csv(biodata, file="biodata.csv") # 它將被保存在你的工作目錄中如果我們想使用數據框創建并保存一個條形圖,我們需要稍微改變一下代碼--因為數據框可以包含多個變量,所以我們需要告訴R我們希望它繪制的是哪個變量。就像之前一樣,我們可以使用 $ 指定數據框中的列。
png("barplot2.png", width=1600, height=600)
barplot(biodata$richness, names.arg=c("Beetle","Bird","Butterfly","Dragonfly","Flowering.Plants","Fungus","Hymenopteran","Lichen","Liverwort","Mammal","Mollusc"),xlab="Taxa", ylab="Number of species", ylim=c(0,600))
dev.off()幾個重要術語
- 參數(argument): 函數的一個元素,可以是必需的,也可以是可選的,它可以是函數的一個元素,它可以是告知或改變函數的工作方式。例如,它可以是函數應該從哪個文件路徑導入或保存到哪個文件路徑:
file = "file-path"。它可以修改繪圖中的顏色:col = "blue"。你可以通過在命令行中鍵入?function-name來查找函數的參數。 - 類型(class): 變量中包含的數據類型:通常是字符(文本/文字),數字(數字),整數(整數),或因子(分組值,當你的數據中包含多個觀測點或治療方法時,非常有用)。
- 命令(command):執行一個動作的代碼塊,通常包含一個或多個函數。您可以通過按 "運行 "或使用鍵盤快捷鍵如
Cmd+Enter、Ctrl+Enter或Ctrl+R來運行命令。 - 注釋(comment):腳本中以
#開頭的文本,不是作為命令來讀的。注釋使你的代碼可以被其他人閱讀:用它們來創建你的腳本中的章節,并對分析的每一步進行注釋。 - 控制臺(console): 你可以直接在命令行中輸入代碼的窗口(
2+2跟著Enter會返回4),你運行的命令的輸出會在這里顯示。 - 數據框(data frame):R對象的一種類型,由許多行和列組成,類似于Excel電子表格。通常情況下,列是不同的變量(如年齡、顏色、體重、翼展),行是這些變量的觀測值(如鳥類1、鳥類2、鳥類3)。
- csv文件(csv file):一種常用于在R中導入數據的文件類型,不同變量的值被壓縮在一起(一個字符串,或每行的值行),并且只用逗號分隔(表示列)。R也可以接受Excel(.xlsx)文件,但我們不建議使用,因為格式化錯誤比較難避免。
- 函數(function):執行一個動作的代碼,也就是你在R中做任何事情的方式,通常是接收一個輸入,對它做一些事情,然后返回一個輸出(一個對象,一個測試結果,一個文件,一個繪圖)。有用于導入、轉換和處理數據的函數,有用于執行特定計算的函數(你能猜到min(10,15,5)和max(10,15,5)會返回什么嗎?
- 對象(object):R的構件。如果R是一種口語化的語言,函數是動詞(動作),對象是名詞(這些動作的主體或對象!)。對象是通過鍵入它們的名字來調用的,沒有引號。對象存儲數據,可以采取不同的形式。最常見的對象是數據框和向量,但還有很多,比如列表和矩陣。
- 包(package):為R提供功能的函數包,很多包都是R自動附帶的,其他的包你可以根據特定的需要下載。
- 腳本(script):是一種腳本。類似于文本編輯器,這是你編寫和保存代碼的地方,以便將來參考。它包含了代碼和注釋的混合,并以簡單的文本文件的形式保存,你可以方便地分享,這樣任何人都可以復制你的工作。
- 向量(vector):R對象的一種類型,有一個維度:它存儲的是一行的值,可以是字符、數字等。
- 工作目錄(working directory):你的計算機上與當前R會話鏈接的文件夾,你從那里導入數據并保存文件。你可以在會話開始時用setwd()函數設置它。
- 工作空間(workspace):這是你的虛擬工作環境,它包含了你所加載的包的所有函數,你所導入的數據以及你所創建的對象等等。通常情況下,最好是以一個干凈的工作空間開始一個工作會話。




方法與示例)




移動語義底層分析)
的矩陣| 使用Python的線性代數)

![Xpath[轉]](http://pic.xiahunao.cn/Xpath[轉])

的底層分析)




)