
眾所周知,因為疫情的原因,很多高校和公司都要求員工每日在微信上進行打卡,來匯報自己的當前身體狀態和所處地區。但絕大多數情況下,每天打卡的信息其實是不會變的,我們要做的就是進入公眾號——自動登錄點進打卡頁面——完成打卡,這樣重復的操作。
這樣的操作在手機上需要花費的時間應該不足一分鐘,但依舊每天都會有懶得或者忘了進行操作的人。所以就想到能不能用python寫一個腳本,在PC端進行自動打卡呢。
(本操作僅提供思路參考,大家還是要重視防疫打卡操作)
以下所有操作均以某高校頁面為例
1.代碼前準備
由于微信的普及,所以基本各高校和公司每日打卡都是在微信端進行,所以我們需要通過微信找到我們的登錄頁。

我們最終希望用Requests模擬發包登錄,而平時都是直接用微信進行自動登錄。顯然在只用腳本的情況下沒辦法實現微信自動登錄跳轉,所以我們需要先找到能輸入賬號密碼的頁面。(此時沒有用Cookie是因為實驗之后發現,Cookie有效期不到2小時,沒辦法支撐每日用同一個Cookie登錄打卡)
此時,我們通過PC微信找到該鏈接:http://****app.i****.info/NYDXY/#/,但是如果直接用瀏覽器打開該鏈接,會跳轉”請用微信客戶端打開鏈接“的頁面。

因此,需要想辦法繞過該限制,思路有兩個:1.通過Fiddler等抓包軟件,找找有沒有其他登錄頁面。2.模擬微信瀏覽器的請求頭和Cookie進入。但是正如前文所說,經過嘗試思路2,確實能夠完成全流程,但該頁面Cookie有效期很短,沒辦法每日均進行自動打卡,因此我們選擇嘗試思路1,還是通過賬號密碼登錄。
沿著思路1,我們打開Fiddler,啟動抓包。然后回到PC微信,和剛才同樣的操作進入打卡頁面自動登錄,再回到Fiddler,發現剛才進入打卡頁面的所有操作已經被記錄在軟件里了。接下來就是通過url和請求頭等信息,來判斷是否存在其他的登錄頁面。
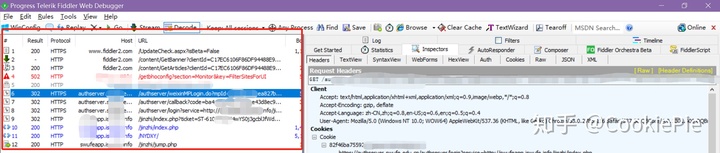
經過分析和嘗試,前兩個鏈接都會提示400或其他錯誤,但嘗試到第三個鏈接https://authserver.******.edu.cn/authserver/login時,會跳轉到學校的統一登陸頁面,同時還在下方發現微信快捷登錄圖表。通過該頁面輸入賬號密碼后,瀏覽器自動跳轉到了我們所需的打卡頁面了。此時,我們實現了PC端模擬登錄微信打卡頁面。

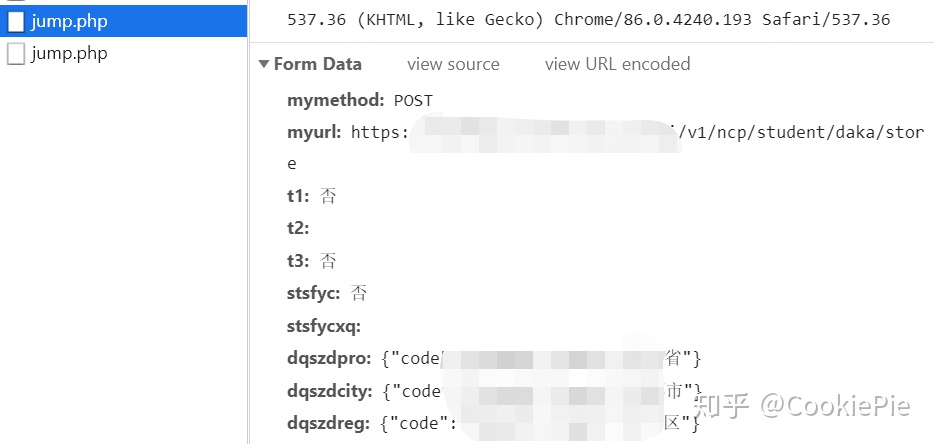
第二步,我們需要看我們打卡到底在瀏覽器端是如何完成的。在手動進行打卡操作之后,經過瀏覽器的F12,看到有四個php提供了post操作,而通常我們的表單數據都是由post方法完成的。排除掉之前就存在的第一二個php,所以我們強烈懷疑就是通過這剩余兩個php完成的打卡操作。
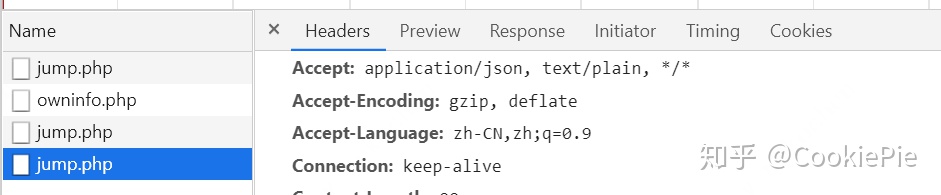
具體來看發現,最后一個jump.php實際上返回的是個人基本信息,以供自動填充用的,提交的表單也與打卡無關。
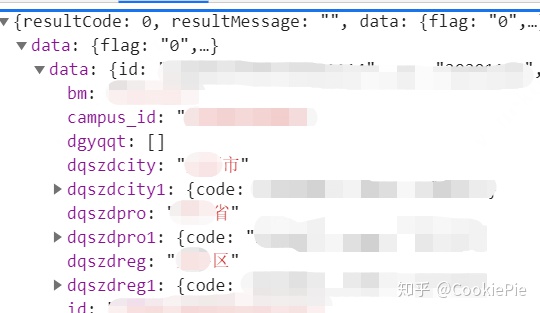
但到了倒數第二個jump.php,通過其提交的Form數據,我們發現就是通過這個php我們完成了打卡操作。因此,我們最終的目標,就是通過該php來完成我們的自動打卡。至此,我們的代碼前分析全部完成,接下來進入代碼環節。
2.代碼實現(Cookie+純requests版本)
( 本文使用requests包進行python代碼實現。)
因為我們已經通過瀏覽器進行過登錄,獲得了Cookie,所以我們先嘗試通過Cookie進行直接打卡。先通過瀏覽器F12獲得Cookie和其余請求頭,然后根據需要放在Python文件中。(這里的請求頭大家可以選擇需要的來放,一般加上Cookie和User-Agent即可,如果失敗還可以嘗試將User-Agent換為Android或ios的模擬請求)
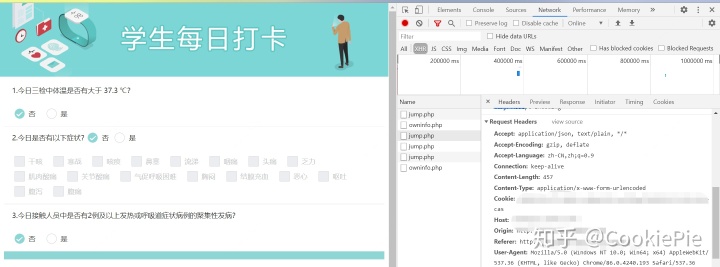
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36','Cookie': '瀏覽器上找到的Cookie'
}然后再根據From Data的數據,按照字典格式一一放進Python文件中去。
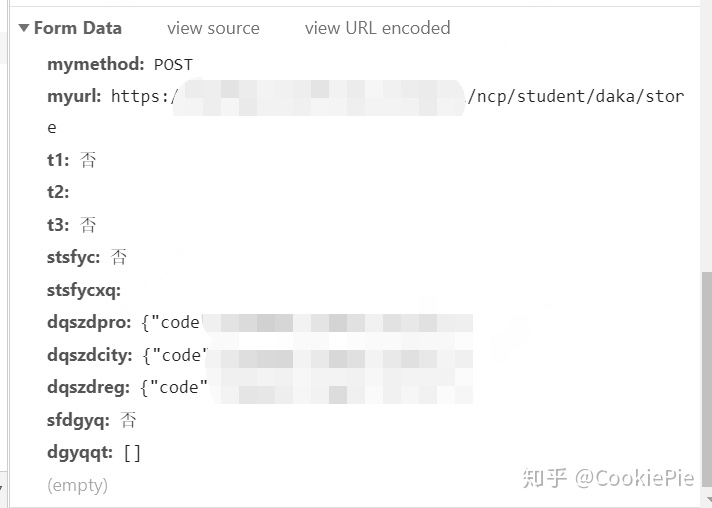
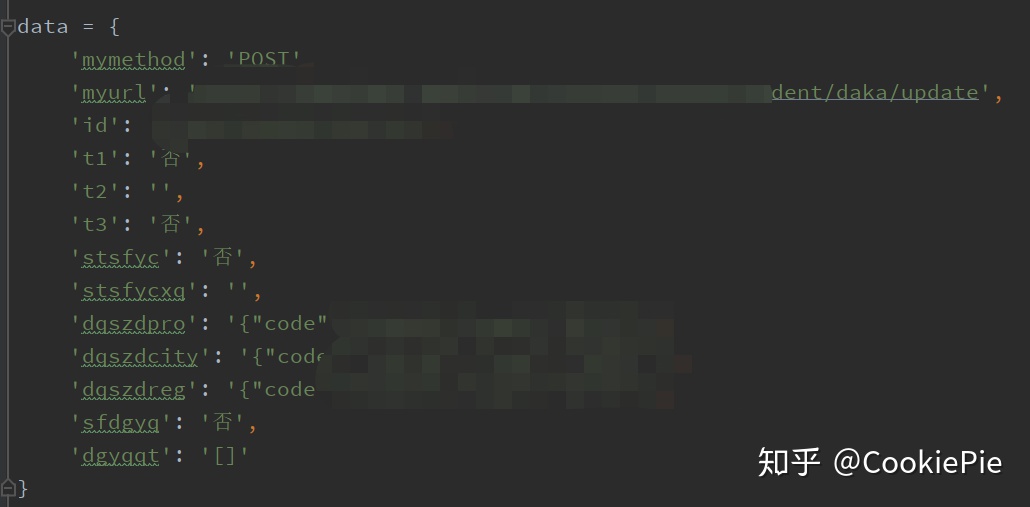
最后再嘗試post即可。發現最后返回值和瀏覽器返回值相同,打卡成功。
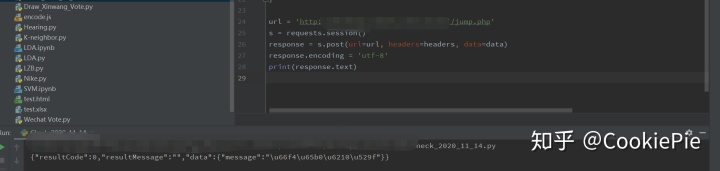

3.代碼實現(賬號密碼+Selenium+Requests版本)
前文已經實現在知道Cookie的前提下,可以直接通過固定php頁面進行表單上傳打卡。但是由于Cookie有效期極短,所以我們明顯需要有一個每次打卡前自動獲取Cookie的方法。
回到一開始的Login頁面,同樣我們通過F12抓包,看每次登錄時提交的表單具體值有些什么。在用戶名和密碼,我們嘗試性的輸入123456之后點擊提交,會發現在login文件下會POST一個表單,里面所包含的就是每次登錄要傳給服務器的信息了。
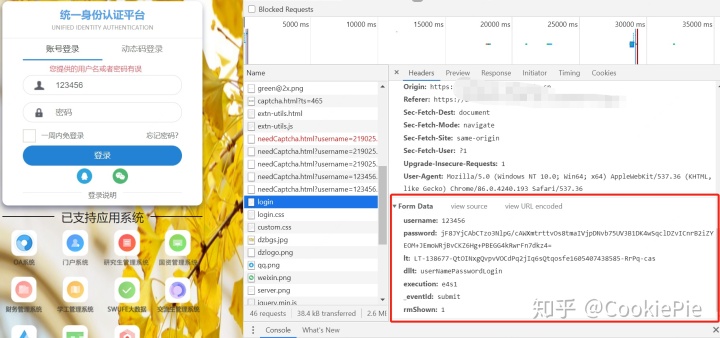
但是從表單我們看到,除了我們填寫的賬號密碼,還有包括lt,execution等信息。經過查找,我們發現這些信息是在加載網頁時就自動生成的,所以我們可以通過request.session()的方法進入頁面后,再通過正則表達式將所需信息找出來,和賬號密碼一起形成表單。

但是我們還可以看到,password明顯是經過加密處理后的信息,所以我們不能直接明文提交密碼,要想辦法將密碼進行處理。而這個加密后的密碼,是我們點擊提交后網頁自動將我們的明文密碼進行的加密,所以大概率就是一個js的處理,因此需要找到網頁上加密的js文件。查找login頁面和js之后,最終找到是encrypt.js這個文件完成了明文密碼的加密。
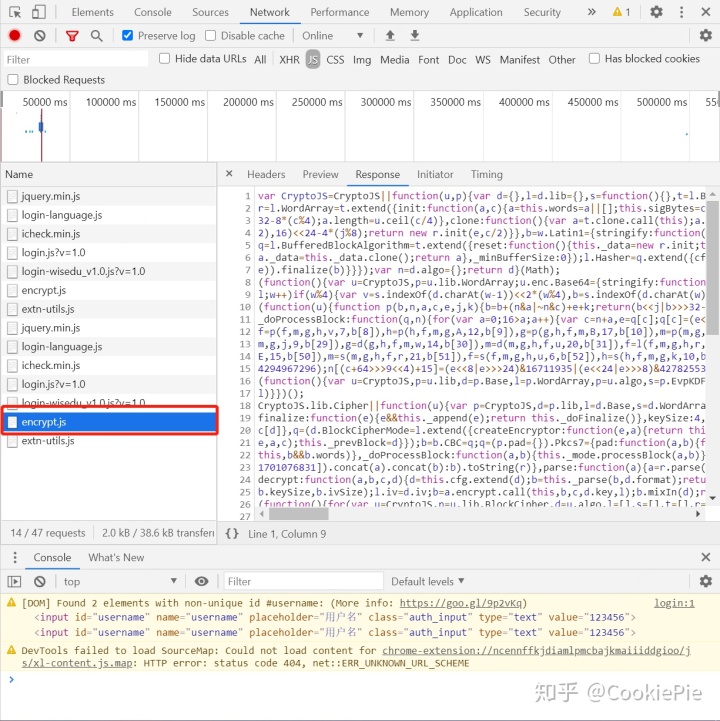
按邏輯來說,我們此時就可以查找傳遞該js所需參數,得到加密后的密碼,連同其他信息一起post給login就可以完成我們的登錄和cookie獲取了。但是這個js真是又長又混淆,以現在的水平暫時不能找到其所需參數。所以換了個思路,通過Selenium來模擬登錄,直接獲取Cookie。
(這里如果可以看懂這個js加密的話,是完全可以不依靠Selenium獲取Cookie的,大家有興趣可以嘗試一下)
Selenium就比較簡單了,通過分析登錄頁面,找到需要Input的地方,獲取Xpath,再通過Selenium填寫,并獲取Cookie就可以了。
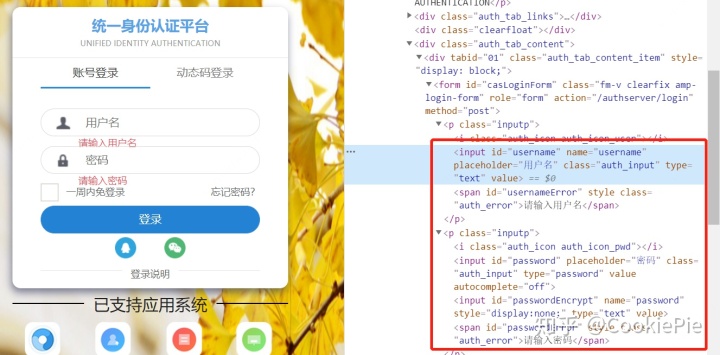
def get_cookie(url_, user_):driver = webdriver.Chrome()driver.get(url_)driver.find_element_by_xpath('//*[@id="username"]').send_keys(user_['name'])driver.find_element_by_xpath('//*[@id="password"]').send_keys(user_['password'])driver.find_element_by_xpath('//*[@id="casLoginForm"]/p[4]/button').click()sleep(3)cookie_ = driver.get_cookies()[0]driver.quit()return cookie_['name']+'='+cookie_['value']獲取cookie后,和之前操作相同,提交表單即可,完整代碼如下。
import requests
from selenium import webdriver
from time import sleepdef get_cookie(url_, user_):driver = webdriver.Chrome()driver.get(url_)driver.find_element_by_xpath('//*[@id="username"]').send_keys(user_['name'])driver.find_element_by_xpath('//*[@id="password"]').send_keys(user_['password'])driver.find_element_by_xpath('//*[@id="casLoginForm"]/p[4]/button').click()sleep(2)cookie_ = driver.get_cookies()[0]driver.quit()return cookie_['name']+'='+cookie_['value']user = {'name': ******', 'password': '******'}
cookie = get_cookie('https://authserver.******.edu.cn/authserver/login?service=http://s******app.i******.info/jinzhi/index.php', user)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36','Cookie': cookie
}data = {'mymethod': 'POST','myurl': '','id': '','t1': '否','t2': '','t3': '否','stsfyc': '否','stsfycxq': '','dqszdpro': '','dqszdcity': '','dqszdreg': '','sfdgyq': '否','dgyqqt': '[]'
}url = 'http://******app.i******.info/jinzhi/jump.php'
s = requests.session()
response = s.post(url=url, headers=headers, data=data)
html = response.text
print(html)
4.總結
其實在類似需求中,代碼部分相對而言占比更少,重要的地方在于找到提交的表單數據和頁面鏈接
![[原創]INI文件的讀寫操作](http://pic.xiahunao.cn/[原創]INI文件的讀寫操作)
方法及示例)
隊列取數據到SDL輸出))
)

![pandas 根據列名索引多列數據_Pandas 數據聚合與分組運算[groupby+apply]速查筆記](http://pic.xiahunao.cn/pandas 根據列名索引多列數據_Pandas 數據聚合與分組運算[groupby+apply]速查筆記)

方法與示例)
隊列取數據到SDL輸出))
)



方法與示例)
)
)
![源碼 狀態機_[源碼閱讀] 阿里SOFA服務注冊中心MetaServer(1)](http://pic.xiahunao.cn/源碼 狀態機_[源碼閱讀] 阿里SOFA服務注冊中心MetaServer(1))


方法與示例)