生成式AI技術無疑是當前最大的時代想象力之一。
?資本、創業者、普通人都在涌入生成式AI里去一探究竟:“百模大戰”連夜打響,融資規模連創新高,各種消費類產品概念不斷涌現……根據Bloomberg Intelligence 的報告,2022年生成式AI 市場規模僅為400 億美元,預計到2032年這一數字將突破1.3 萬億美元,未來10 年的年均復合增速高達42%。
?然而,表面上看著熱鬧非凡,但生成式AI技術的普及和轉化真的有我們想象的那么高嗎?
?在經歷了爆發式增長之后,6月以來,生成式AI聊天產品訪問量幾乎都出現了不同程度的下降。最新用戶調查顯示,有80%-90%以上的受訪者表示未來六個月都完全不會使用ChatGPT、Bard等聊天工具。從消費端看,大家目前似乎更多地把生成式AI產品當成了一種追趕時尚潮流的玩具,而非持續使用的工具。
?而在企業端,這樣的現象就更為明顯。一旦人們切換到工作模式時,生成式AI工具便很少出現在大家的工作流程中,甚至還被很多大型公司等明令禁止或限制性使用。
?
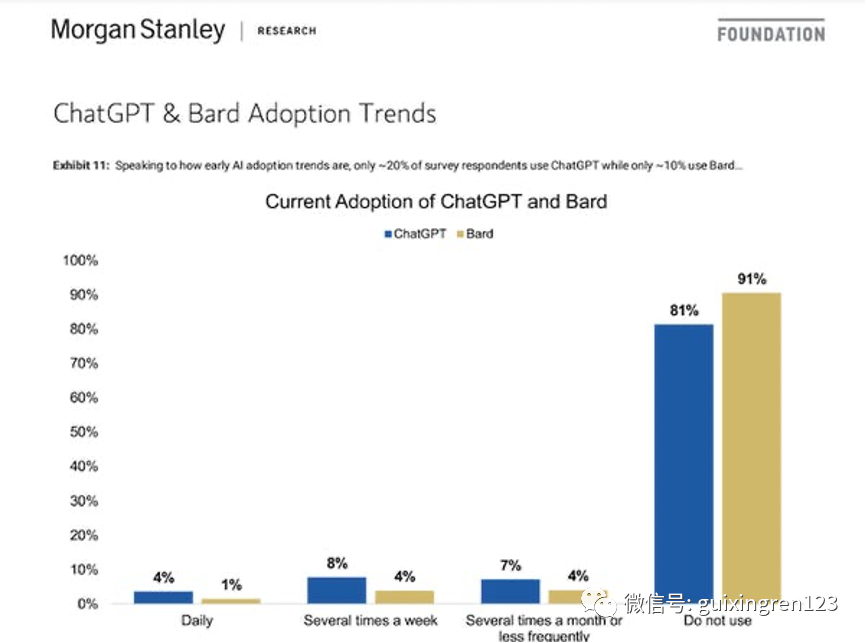
?對于一個比較成熟技術的商業轉化來說,6個多月的時間并不算短。但目前,關于生成式AI的狂想焦點似乎仍然還停留在大模型和產品概念上,人們預期所想看到的繁榮生態和對經濟社會所產生的變革性影響還尚未到來。
?那么,究竟是什么桎梏著它的發展?
?生成式AI的落地之困:如何打破基礎模型和開發者之間的“墻”?
?所有人都不想錯過生成式AI浪潮。但當前生成式AI的超高進入門檻,把大部分玩家擋在了門外。
?過去這些年來,通過“深度學習+大算力”進行模型訓練是實現人工智能最主流的技術途徑。但大模型的商業化落地,必須得先回到成本核算上。
?首先,大模型對算力的需求極大,是一個巨型“吞金獸”。GPT-3.5模型的訓練一次的成本約在300萬到460萬美元之間,一些更大的語言模型訓練成本甚至高達1200 萬美元。自研大模型是一個“無底洞”,不具備雄厚資金實力的創業公司根本無法承擔。
?此外,通用模型并不能解決所有問題,能幫企業完成的事情非常有限。大模型的訓練都是基于互聯網上的公開數據完成,很多產品也相對孤立沒有形成一個連貫的、整體的工作流,不具備定制化能力。意味著開發人員需要結合私有數據做大量個性化調試,開發訓練門檻極高。
?而由于前期的巨額投入,就算大模型開始商業化之后,要實現盈利也往往需要長時間的積累。因此,要想生成式AI技術真正落地到各行各業中發揮效力,當前急需一種可負擔、高效率、低門檻的解決方案,讓更多人參與到入生成式AI的開發中來。
?那么,如何才能彌合從基礎模型到終端應用之間的鴻溝?目前來看,提供一站式AI專業托管服務的云平臺或許是當前的最佳解決路徑。
?云平臺擁有充足、靈活的算力資源,中小型企業不必自行購買和維護昂貴的硬件設備,即可滿足個性化的開發需求。用戶可以通過 API和SDK,便捷地調用云平臺上的第三方資源和大包服務,將他們的應用和服務與云平臺無縫銜接,最大化簡化開發流程。
?此外,云平臺還能夠幫助解決數據的隱私安全問題。過去幾個月來,包括蘋果、三星、臺積電、美國銀行等很多大型企業都相繼出臺相關政策明令禁止員工使用ChatGP,紛紛開始自研大模型。而對于那些不具備自研實力的中小型企業來說,選擇能夠提供包括數據加密、身份驗證、合規性工具等安全措施的云平臺則是一個很好的低成本選項。

?針對當前的生成式AI浪潮,云平臺是否已經具備大模型開發的相當能力,能夠提供生成式AI的全流程服務呢?
?在剛剛落幕的亞馬遜云科技紐約峰會上,我們看到了一份基于云的生成式AI完整解決方案。
?亞馬遜云科技,創建生成式AI普惠新范式
?此次,亞馬遜云科技延續了過去一貫的“務實”風格,瞄準當前生成式AI應用轉化所面臨的痛點問題,上新了一系列全新的功能和服務。從硬件到軟件,從開發端到應用端,試圖打造一個功能最全、能力最強的生成式AI服務平臺。
-
Amazon Bedrock服務:搭建生成式AI開發的“快速通道”
?針對開發層面基礎模型訓練成本昂貴、環境部署復雜的問題,今年4月,亞馬遜云科技首次宣布推出Amazon Bedrock服務,允許用戶通過可擴展、可靠且安全的亞馬遜云科技托管服務,用API來便捷地訪問來自不同供應商的基礎模型,并利用它們來構建生成式AI應用程序。
?當時,除了自家的Titan大模型之外,首發第三方合作商及基礎模型還包括AI21 Labs的Jurassic-2,Anthropic的Claude,以及Stability AI的Stable Diffusion。在這次的紐約峰會上,亞馬遜宣布再次增加前生成式AI領域的最大獨角獸之一的Cohere作為供應商,也新增了包括Anthropic最新的語言模型 Claude 2,和Stability AI最新版文生圖模型套件 Stable Diffusion XL 1.0等基礎模型。
?亞馬遜云科技認為,未來一定不會是一個模型統管一切,Amazon Bedrock通過不斷集成業界最領先的基礎模型,用戶將可以根據自身需求來便捷地調用最合適的模型。

?但基礎模型有了之后,還有一個棘手的問題沒有解決——如何使用這些模型進行個性化的應用開發?云平臺還要進一步解決私有數據學習、系統集成和調試以及任務自動執行的問題。
?舉一個我們在日常生活中經常會遇到的電商退換貨的例子。你在電商平臺買了雙鞋子不太滿意想要找客服換一個顏色,如果此時客服是ChatGPT等通用聊天機器人,他會怎么回答你?——“抱歉,我的訓練數據截止日期是2021年9月,沒有這雙鞋的相關信息。”
?要想讓大模型真正發揮作用,首先要做的就是提前把公司內部跟這雙鞋所有有關的信息都“喂”給模型,包括鞋的型號顏色、平臺的退換貨政策、庫存信息等等,模型才能準確地給出反饋。在給出信息的同時,還需要AI一邊聊天一邊能在后臺有序、安全地執行有關換貨的所有操作。
?在過去這對于開發者來說是一個龐大的工程,但現在,亞馬遜新推出了一項名為Amazon Bedrock Agents服務,讓這一切變得觸手可及。
?最新的Amazon Bedrock Agents服務能夠在基礎模型的基礎上,把對話的定義、模型外部信息獲取和解析、API調用、任務執行等打包成為一個全托管式的服務,從而能夠及時、有針對性的輸出結果。
?如此一來,開發者不必重巨資從頭開發自己的基礎模型,也不要花費大量的時間和人力去進行模型的個性化部署和調試,從而能讓開發者把更多的精力放在AI應用的構建和運營上,讓不具備雄厚資金和技術實力的中小型開發者都可以加入到生成式AI浪潮中來。
-
“向量數據+硬件算力”雙護航,鑄造應用開發的最強大腦+最強底座
?進行模型的定制開發,除了需要如Amazon Bedrock這樣的專業托管服務,也需要計算、存儲、安全等其他相關能力,來保證模型的持續可用、和迭代升級。
?毋庸置疑,數據是人工智能出現和發展的基底。生成式AI為了學習和理解人類語言的復雜性,需要大量的訓練數據,而這些訓練數據通常是以“向量”的形式存在,也就是把自然語言轉化為計算機可以理解和處理的數字。
?那么,什么是向量數據,為什么它對生成式AI的發展至關重要呢?
?假設你正在使用一個音樂推薦軟件,我們可以把每首歌分別按照節奏、歌詞、旋律等三個特征進行量化標記,比如第一首歌是(120,60,80),第二首歌是(100,80,70),當你告訴系統你喜歡第一首歌的節奏時,系統便會找到這首歌的節奏向量數據“120”,在數據庫中查找與這個向量相似的其他向量,接著再把有相似特征的歌曲推薦給你。
?當然,不止是三維,一個數據還可以被標注成更多緯度。在自然語言處理中,使用詞嵌入技術表示的“詞向量”通常是幾百維的,而在圖像處理中,使用像素值表示的圖像向量可能有數千到數百萬的維度。被“向量化”之后的數據將被存儲在向量數據庫之中,在高維空間中去高效地檢索和生成最相關或最相似的數據。
?然而,要將數據進行向量化處理和儲存并不是一件容易的事,往往要耗費大量的人力和時間。針對這一問題,亞馬遜云科技此次推出了適用于 Amazon OpenSearch Serverless 的向量引擎,該向量引擎能夠支持簡單的 API 調用,可用于存儲和查詢數十億個 Embeddings(將高維度的數據映射到低維度空間的過程)。亞馬遜云科技還表示,未來所有亞馬遜云科技的數據庫都將具有向量功能,在AI數據層面成為開發者的“最強大腦”。
?

?除了向量引擎的支持,在算力層面,亞馬遜云科技也一直致力于構建低成本、低延遲的云上基礎設施。
?亞馬遜云科技和英偉達合作已超過12年,為人工智能、機器學習、圖形、游戲和高性能計算等各種應用提供了大規模、低成本的 GPU 解決方案,在交付基于 GPU 的實例方面擁有無比豐富的經驗。此次,亞馬遜云科技展示了最新基于英偉達 H100 Tensor Core GPU 提供支持的P5實例,能夠實現更低的延遲和高效的橫向擴展性能。
?P5 實例將是第一個利用亞馬遜云科技第二代 Amazon Elastic Fabric Adapter(EFA)網絡技術的 GPU 實例。與上一代相比,P5實例的訓練時間最多可縮短6倍,從幾天縮短到幾小時,這一性能提升將幫助客戶降低高達40%的訓練成本。借助第二代 Amazon EFA,用戶能夠將其 P5 實例擴展到超過 2 萬個英偉達 H100 GPU,為包括初創公司、大企業在內的所有規模客戶提供所需的超級計算能力。
-
降低生成式AI門檻,用產品最大化賦能用戶
?除了面向生成式AI開發的工具和平臺之外,在企業的日常運營之中需要一些能夠拿來即用的生成式AI產品,來幫助提升工作和管理效率。關于這一點,亞馬遜云科技也陸續推出了一些在工作場景中直接可以使用的產品,這些產品既覆蓋底層開發人員也關注到了企業中大量的非技術人員。
?比如在代碼開發領域,自從亞馬遜云科技在去年6月首次推出AI編程助手Amazon CodeWhisperer之后,現在該功能已經成為了很多開發者日常必備工具之一。
?Amazon CodeWhisperer基于幾十億行開源代碼訓練,可以根據代碼注釋和現有代碼實時生成代碼建議,另外還能進行安全漏洞掃描。目前支持包括 Python、Java 和 JavaScript 15 種編程語言和包括 VS Code、IntelliJ IDEA、JupyterLab 和 Amazon SageMaker Studio等集成開發環境。
?為了進一步提高開發效率,在紐約峰會上,亞馬遜云科技正式宣布 Amazon Glue Studio Notebooks 也能支持 Amazon CodeWhisperer。通過 Amazon Glue Studio Notebooks,開發人員可以用自然語言編寫特定任務,接著Amazon CodeWhisperer 可以直接在 Notebooks 中推薦一個或多個可完成此任務的代碼片段,供開發人員直接使用和編輯。

Amazon CodeWhisperer支持語言和環境,圖片來自亞馬遜云科技官網
?而對于非開發類工作場景,通過將 Amazon Bedrock的大語言模型能力與支持自然語言問答的 Amazon QuickSight Q 相結合,為用戶提供了基于生成式AI的商業智能新服務。
?比如你是一個財務分析師,你可以像跟ChatGPT聊天一樣用自然語言下達命令,在幾秒鐘內Amazon QuickSight Q就能完成搜索關鍵財務信息或創建公司財務可視化圖表的操作,同時還能幫你總結出趨勢特點并提出建議。
?類似拿來即用的產品還有幫助企業打破內部信息孤島、加快數據驅動決策的Amazon Entity Resolution,以及能夠幫助醫療軟件供應商便捷地構建基于生成式AI的臨床應用程序的Amazon HealthScribe等等,在各行各業擴大著生成式AI產品的使用場景。
?釋放AI時代的“云力量”
?生成式AI的發展需要云,更需要大量基于云的工具和服務。
?大模型之后,下一階段生成式AI技術一定會朝著多樣性和個性化方向發展,我們既可以看到比較通用的生產力工具,也會看到各種瞄準特定場景的AI產品。而在這個過程中,云平臺會起到越來越關鍵的作用。
?一方面,云平臺會大大降低AI應用開發的門檻。在平臺的算力和基礎模型支持下,開發者們基本無需關心硬件和基礎設施的問題,從而把更多的時間和精力放在業務和運營上。另一方面,云平臺能夠持續加快AI應用的開發和運營效率。用戶可以通過直接調用API的方式進行應用的開發和管理,并安全、便捷地在團隊或組織之間共享。
?在云平臺的助力之下,未來的生成式AI將不再只是一場巨頭才能玩的“燒錢游戲”,更多普通人也將可以坐上牌桌。
?作為云服務領域的行業領導者之一,亞馬遜云科技提供了200多種服務,涵蓋了計算、存儲、數據庫、網絡、開發者工具、安全、分析、物聯網、企業應用等廣泛領域,云基礎設施覆蓋全球。同時,亞馬遜云科技還是人工智能和機器學習領域的領先者,多年來持續提供和更新著一系列端到端的AI相關服務,讓開發者可以靈活、便捷、低成本的開發和部署生成式AI應用。
?此次,亞馬遜云科技發布生成式AI工具“全家桶”,其核心目的就是要進一步降低生成式AI開發的門檻,讓更多不懂大模型、不懂人工智能的普通人也能快速加入生成式AI的開發和應用之中。
?生成式AI的重要性不在于模型有多大能力有多強,更重要的還是如何能夠從基礎模型演變成各個領域中的具體應用,從而賦能整個經濟社會的發展。
?現在,亞馬遜云科技正在成為那個橋梁。



![【Linux】Shell腳本之流程控制語句 if判斷、for循環、while循環、case循環判斷 + 實戰詳解[?建議收藏!!?]](http://pic.xiahunao.cn/【Linux】Shell腳本之流程控制語句 if判斷、for循環、while循環、case循環判斷 + 實戰詳解[?建議收藏!!?])







![[HDLBits] Exams/m2014 q4d](http://pic.xiahunao.cn/[HDLBits] Exams/m2014 q4d)

)





