目錄
- 一、環境準備
- 1.進入ModelArts官網
- 2.使用CodeLab體驗Notebook實例
- 二、環境準備與數據讀取
- 三、模型解析
- Transformer基本原理
- Attention模塊
- Transformer Encoder
- ViT模型的輸入
- 整體構建ViT
- 四、模型訓練與推理
- 模型訓練
- 模型驗證
- 模型推理
近些年,隨著基于自注意(Self-Attention)結構的模型的發展,特別是Transformer模型的提出,極大地促進了自然語言處理模型的發展。由于Transformers的計算效率和可擴展性,它已經能夠訓練具有超過100B參數的空前規模的模型。
ViT則是自然語言處理和計算機視覺兩個領域的融合結晶。在不依賴卷積操作的情況下,依然可以在圖像分類任務上達到很好的效果。
模型結構
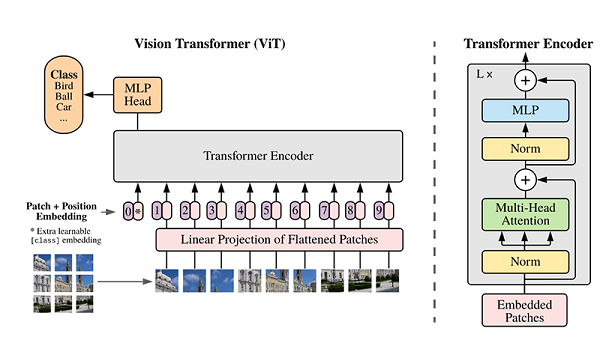
ViT模型的主體結構是基于Transformer模型的Encoder部分(部分結構順序有調整,如:Normalization的位置與標準Transformer不同),其結構圖[1]如下:
模型特點
ViT模型主要應用于圖像分類領域。因此,其模型結構相較于傳統的Transformer有以下幾個特點:
數據集的原圖像被劃分為多個patch后,將二維patch(不考慮channel)轉換為一維向量,再加上類別向量與位置向量作為模型輸入。
模型主體的Block結構是基于Transformer的Encoder結構,但是調整了Normalization的位置,其中,最主要的結構依然是Multi-head Attention結構。
模型在Blocks堆疊后接全連接層,接受類別向量的輸出作為輸入并用于分類。通常情況下,我們將最后的全連接層稱為Head,Transformer Encoder部分為backbone。
下面將通過代碼實例來詳細解釋基于ViT實現ImageNet分類任務。
如果你對MindSpore感興趣,可以關注昇思MindSpore社區
一、環境準備
1.進入ModelArts官網
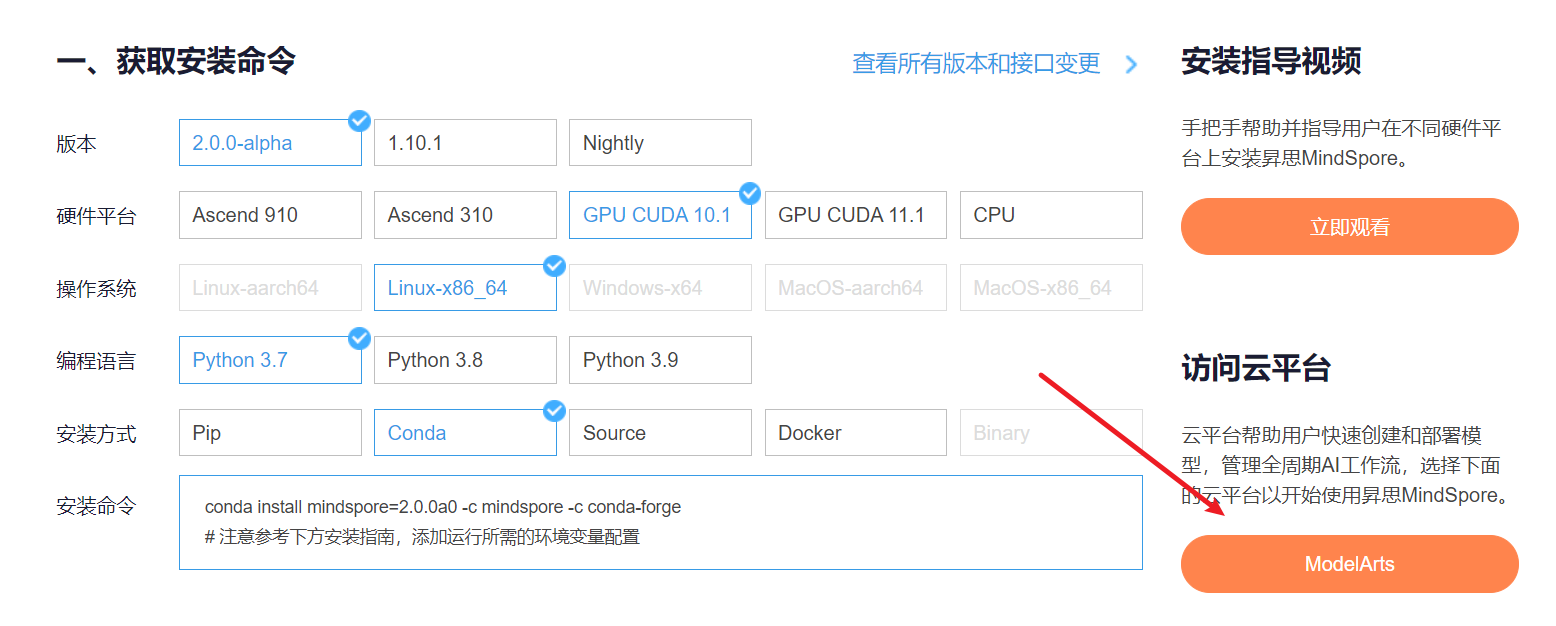
云平臺幫助用戶快速創建和部署模型,管理全周期AI工作流,選擇下面的云平臺以開始使用昇思MindSpore,獲取安裝命令,安裝MindSpore2.0.0-alpha版本,可以在昇思教程中進入ModelArts官網
選擇下方CodeLab立即體驗
等待環境搭建完成
2.使用CodeLab體驗Notebook實例
下載NoteBook樣例代碼,Vision Transformer圖像分類 ,.ipynb為樣例代碼
選擇ModelArts Upload Files上傳.ipynb文件
選擇Kernel環境
切換至GPU環境,切換成第一個限時免費
進入昇思MindSpore官網,點擊上方的安裝

獲取安裝命令

回到Notebook中,在第一塊代碼前加入命令
conda update -n base -c defaults conda
安裝MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安裝mindvision
pip install mindvision
安裝下載download
pip install download
二、環境準備與數據讀取
開始實驗之前,請確保本地已經安裝了Python環境并安裝了MindSpore。
首先我們需要下載本案例的數據集,可通過http://image-net.org下載完整的ImageNet數據集,本案例應用的數據集是從ImageNet中篩選出來的子集。
運行第一段代碼時會自動下載并解壓,請確保你的數據集路徑如以下結構。
.dataset/├── ILSVRC2012_devkit_t12.tar.gz├── train/├── infer/└── val/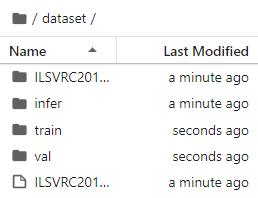
from download import downloaddataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/vit_imagenet_dataset.zip"
path = "./"path = download(dataset_url, path, kind="zip", replace=True)
import osimport mindspore as ms
from mindspore.dataset import ImageFolderDataset
import mindspore.dataset.vision as transformsdata_path = './dataset/'
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]dataset_train = ImageFolderDataset(os.path.join(data_path, "train"), shuffle=True)trans_train = [transforms.RandomCropDecodeResize(size=224,scale=(0.08, 1.0),ratio=(0.75, 1.333)),transforms.RandomHorizontalFlip(prob=0.5),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_train = dataset_train.map(operations=trans_train, input_columns=["image"])
dataset_train = dataset_train.batch(batch_size=16, drop_remainder=True)
三、模型解析
下面將通過代碼來細致剖析ViT模型的內部結構。
Transformer基本原理
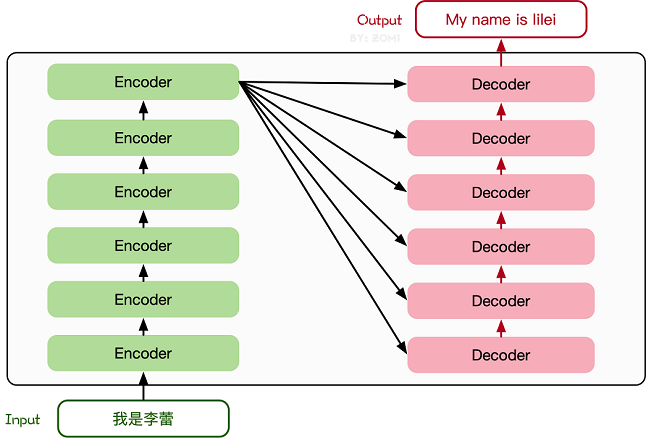
Transformer模型源于2017年的一篇文章[2]。在這篇文章中提出的基于Attention機制的編碼器-解碼器型結構在自然語言處理領域獲得了巨大的成功。模型結構如下圖所示:
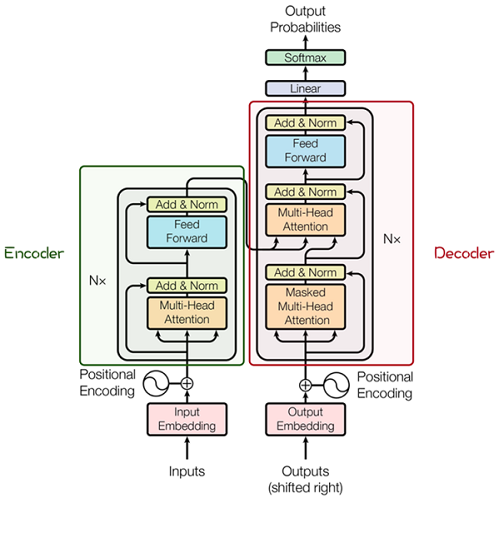
其主要結構為多個Encoder和Decoder模塊所組成,其中Encoder和Decoder的詳細結構如下圖[2]所示:
Encoder與Decoder由許多結構組成,如:多頭注意力(Multi-Head Attention)層,Feed
Forward層,Normaliztion層,甚至殘差連接(Residual
Connection,圖中的“Add”)。不過,其中最重要的結構是多頭注意力(Multi-Head
Attention)結構,該結構基于自注意力(Self-Attention)機制,是多個Self-Attention的并行組成。所以,理解了Self-Attention就抓住了Transformer的核心。
Attention模塊
from mindspore import nn, opsclass Attention(nn.Cell):def __init__(self,dim: int,num_heads: int = 8,keep_prob: float = 1.0,attention_keep_prob: float = 1.0):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = ms.Tensor(head_dim ** -0.5)self.qkv = nn.Dense(dim, dim * 3)self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob)self.out = nn.Dense(dim, dim)self.out_drop = nn.Dropout(p=1.0-keep_prob)self.attn_matmul_v = ops.BatchMatMul()self.q_matmul_k = ops.BatchMatMul(transpose_b=True)self.softmax = nn.Softmax(axis=-1)def construct(self, x):"""Attention construct."""b, n, c = x.shapeqkv = self.qkv(x)qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))q, k, v = ops.unstack(qkv, axis=0)attn = self.q_matmul_k(q, k)attn = ops.mul(attn, self.scale)attn = self.softmax(attn)attn = self.attn_drop(attn)out = self.attn_matmul_v(attn, v)out = ops.transpose(out, (0, 2, 1, 3))out = ops.reshape(out, (b, n, c))out = self.out(out)out = self.out_drop(out)return out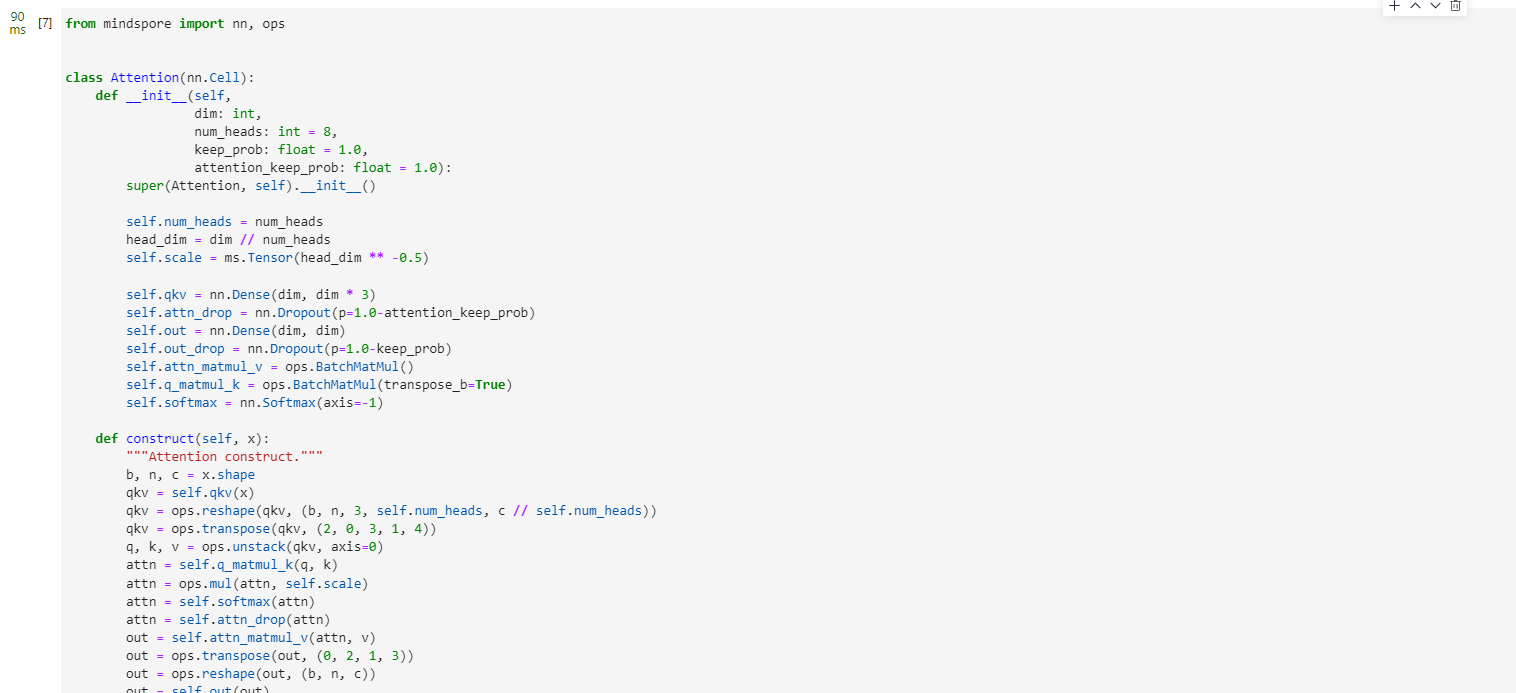
Transformer Encoder
在了解了Self-Attention結構之后,通過與Feed Forward,Residual
Connection等結構的拼接就可以形成Transformer的基礎結構,下面代碼實現了Feed Forward,Residual
Connection結構。
from typing import Optional, Dictclass FeedForward(nn.Cell):def __init__(self,in_features: int,hidden_features: Optional[int] = None,out_features: Optional[int] = None,activation: nn.Cell = nn.GELU,keep_prob: float = 1.0):super(FeedForward, self).__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.dense1 = nn.Dense(in_features, hidden_features)self.activation = activation()self.dense2 = nn.Dense(hidden_features, out_features)self.dropout = nn.Dropout(p=1.0-keep_prob)def construct(self, x):"""Feed Forward construct."""x = self.dense1(x)x = self.activation(x)x = self.dropout(x)x = self.dense2(x)x = self.dropout(x)return xclass ResidualCell(nn.Cell):def __init__(self, cell):super(ResidualCell, self).__init__()self.cell = celldef construct(self, x):"""ResidualCell construct."""return self.cell(x) + x
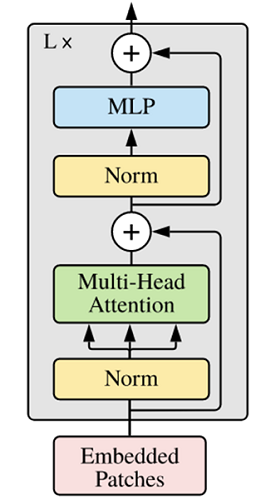
接下來就利用Self-Attention來構建ViT模型中的TransformerEncoder部分,類似于構建了一個Transformer的編碼器部分,如下圖[1]所示:
vit-encoder
ViT模型中的基礎結構與標準Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed
Forward之前,其他結構如Residual Connection,Feed
Forward,Normalization都如Transformer中所設計。從Transformer結構的圖片可以發現,多個子encoder的堆疊就完成了模型編碼器的構建,在ViT模型中,依然沿用這個思路,通過配置超參數num_layers,就可以確定堆疊層數。
Residual
Connection,Normalization的結構可以保證模型有很強的擴展性(保證信息經過深層處理不會出現退化的現象,這是Residual
Connection的作用),Normalization和dropout的應用可以增強模型泛化能力。從以下源碼中就可以清晰看到Transformer的結構。將TransformerEncoder結構和一個多層感知器(MLP)結合,就構成了ViT模型的backbone部分。
class TransformerEncoder(nn.Cell):def __init__(self,dim: int,num_layers: int,num_heads: int,mlp_dim: int,keep_prob: float = 1.,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: nn.Cell = nn.LayerNorm):super(TransformerEncoder, self).__init__()layers = []for _ in range(num_layers):normalization1 = norm((dim,))normalization2 = norm((dim,))attention = Attention(dim=dim,num_heads=num_heads,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob)feedforward = FeedForward(in_features=dim,hidden_features=mlp_dim,activation=activation,keep_prob=keep_prob)layers.append(nn.SequentialCell([ResidualCell(nn.SequentialCell([normalization1, attention])),ResidualCell(nn.SequentialCell([normalization2, feedforward]))]))self.layers = nn.SequentialCell(layers)def construct(self, x):"""Transformer construct."""return self.layers(x)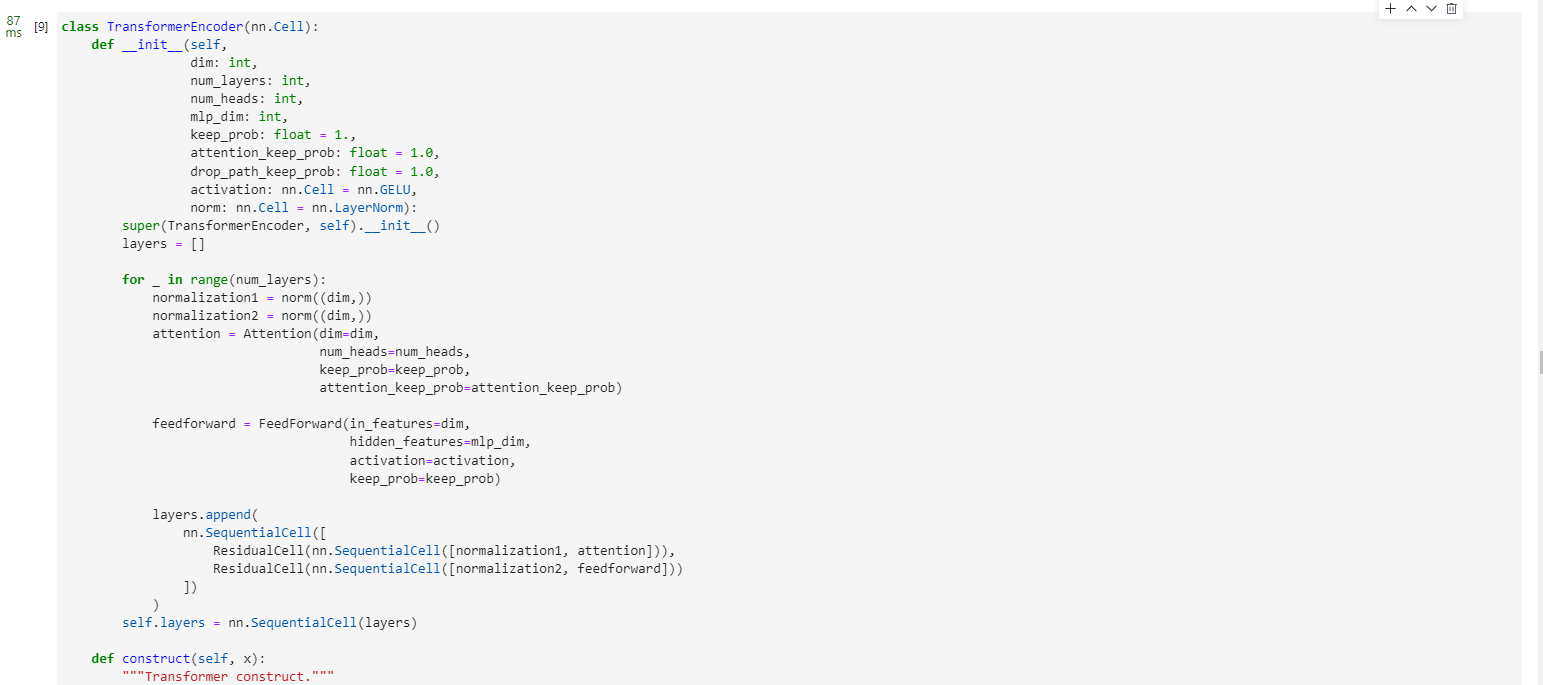
ViT模型的輸入
傳統的Transformer結構主要用于處理自然語言領域的詞向量(Word Embedding or Word Vector),詞向量與傳統圖像數據的主要區別在于,詞向量通常是一維向量進行堆疊,而圖片則是二維矩陣的堆疊,多頭注意力機制在處理一維詞向量的堆疊時會提取詞向量之間的聯系也就是上下文語義,這使得Transformer在自然語言處理領域非常好用,而二維圖片矩陣如何與一維詞向量進行轉化就成為了Transformer進軍圖像處理領域的一個小門檻。
在ViT模型中:
通過將輸入圖像在每個channel上劃分為16*16個patch,這一步是通過卷積操作來完成的,當然也可以人工進行劃分,但卷積操作也可以達到目的同時還可以進行一次而外的數據處理;例如一幅輸入224
x 224的圖像,首先經過卷積處理得到16 x 16個patch,那么每一個patch的大小就是14 x 14。
再將每一個patch的矩陣拉伸成為一個一維向量,從而獲得了近似詞向量堆疊的效果。上一步得到的14 x 14的patch就轉換為長度為196的向量。
這是圖像輸入網絡經過的第一步處理。具體Patch Embedding的代碼如下所示:
class PatchEmbedding(nn.Cell):MIN_NUM_PATCHES = 4def __init__(self,image_size: int = 224,patch_size: int = 16,embed_dim: int = 768,input_channels: int = 3):super(PatchEmbedding, self).__init__()self.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)def construct(self, x):"""Path Embedding construct."""x = self.conv(x)b, c, h, w = x.shapex = ops.reshape(x, (b, c, h * w))x = ops.transpose(x, (0, 2, 1))return x
輸入圖像在劃分為patch之后,會經過pos_embedding 和 class_embedding兩個過程。
class_embedding主要借鑒了BERT模型的用于文本分類時的思想,在每一個word
vector之前增加一個類別值,通常是加在向量的第一位,上一步得到的196維的向量加上class_embedding后變為197維。增加的class_embedding是一個可以學習的參數,經過網絡的不斷訓練,最終以輸出向量的第一個維度的輸出來決定最后的輸出類別;由于輸入是16 x 16個patch,所以輸出進行分類時是取 16 x 16個class_embedding進行分類。
pos_embedding也是一組可以學習的參數,會被加入到經過處理的patch矩陣中。
由于pos_embedding也是可以學習的參數,所以它的加入類似于全鏈接網絡和卷積的bias。這一步就是創造一個長度維197的可訓練向量加入到經過class_embedding的向量中。
實際上,pos_embedding總共有4種方案。但是經過作者的論證,只有加上pos_embedding和不加pos_embedding有明顯影響,至于pos_embedding是一維還是二維對分類結果影響不大,所以,在我們的代碼中,也是采用了一維的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的維度會比patch拉伸后的維度加1。
總的而言,ViT模型還是利用了Transformer模型在處理上下文語義時的優勢,將圖像轉換為一種“變種詞向量”然后進行處理,而這樣轉換的意義在于,多個patch之間本身具有空間聯系,這類似于一種“空間語義”,從而獲得了比較好的處理效果。
整體構建ViT
以下代碼構建了一個完整的ViT模型。
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameterdef init(init_type, shape, dtype, name, requires_grad):"""Init."""initial = initializer(init_type, shape, dtype).init_data()return Parameter(initial, name=name, requires_grad=requires_grad)class ViT(nn.Cell):def __init__(self,image_size: int = 224,input_channels: int = 3,patch_size: int = 16,embed_dim: int = 768,num_layers: int = 12,num_heads: int = 12,mlp_dim: int = 3072,keep_prob: float = 1.0,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: Optional[nn.Cell] = nn.LayerNorm,pool: str = 'cls') -> None:super(ViT, self).__init__()self.patch_embedding = PatchEmbedding(image_size=image_size,patch_size=patch_size,embed_dim=embed_dim,input_channels=input_channels)num_patches = self.patch_embedding.num_patchesself.cls_token = init(init_type=Normal(sigma=1.0),shape=(1, 1, embed_dim),dtype=ms.float32,name='cls',requires_grad=True)self.pos_embedding = init(init_type=Normal(sigma=1.0),shape=(1, num_patches + 1, embed_dim),dtype=ms.float32,name='pos_embedding',requires_grad=True)self.pool = poolself.pos_dropout = nn.Dropout(p=1.0-keep_prob)self.norm = norm((embed_dim,))self.transformer = TransformerEncoder(dim=embed_dim,num_layers=num_layers,num_heads=num_heads,mlp_dim=mlp_dim,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob,drop_path_keep_prob=drop_path_keep_prob,activation=activation,norm=norm)self.dropout = nn.Dropout(p=1.0-keep_prob)self.dense = nn.Dense(embed_dim, num_classes)def construct(self, x):"""ViT construct."""x = self.patch_embedding(x)cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1))x = ops.concat((cls_tokens, x), axis=1)x += self.pos_embeddingx = self.pos_dropout(x)x = self.transformer(x)x = self.norm(x)x = x[:, 0]if self.training:x = self.dropout(x)x = self.dense(x)return x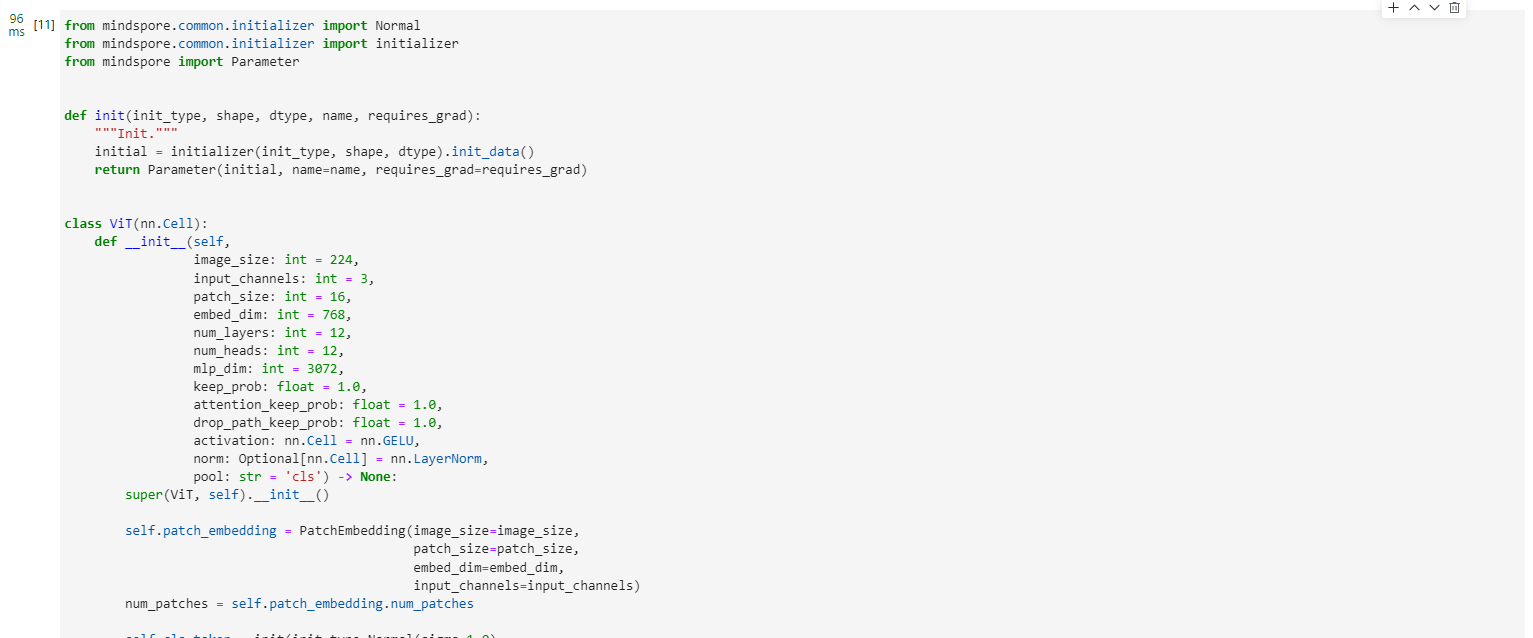
整體流程圖如下所示:
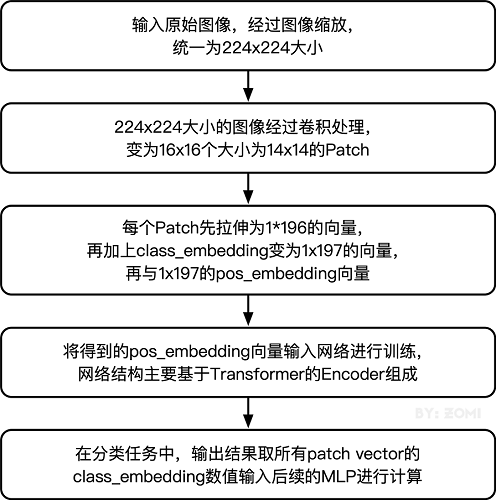
四、模型訓練與推理
模型訓練
from mindspore.nn import LossBase
from mindspore.train import LossMonitor, TimeMonitor, CheckpointConfig, ModelCheckpoint
from mindspore import train# define super parameter
epoch_size = 10
momentum = 0.9
num_classes = 1000
resize = 224
step_size = dataset_train.get_dataset_size()# construct model
network = ViT()# load ckpt
vit_url = "https://download.mindspore.cn/vision/classification/vit_b_16_224.ckpt"
path = "./ckpt/vit_b_16_224.ckpt"vit_path = download(vit_url, path, replace=True)
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)# define learning rate
lr = nn.cosine_decay_lr(min_lr=float(0),max_lr=0.00005,total_step=epoch_size * step_size,step_per_epoch=step_size,decay_epoch=10)# define optimizer
network_opt = nn.Adam(network.trainable_params(), lr, momentum)# define loss function
class CrossEntropySmooth(LossBase):"""CrossEntropy."""def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):super(CrossEntropySmooth, self).__init__()self.onehot = ops.OneHot()self.sparse = sparseself.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)def construct(self, logit, label):if self.sparse:label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)loss = self.ce(logit, label)return lossnetwork_loss = CrossEntropySmooth(sparse=True,reduction="mean",smooth_factor=0.1,num_classes=num_classes)# set checkpoint
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config)# initialize model
# "Ascend + mixed precision" can improve performance
ascend_target = (ms.get_context("device_target") == "Ascend")
if ascend_target:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O2")
else:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"}, amp_level="O0")# train model
model.train(epoch_size,dataset_train,callbacks=[ckpt_callback, LossMonitor(125), TimeMonitor(125)],dataset_sink_mode=False,)
模型驗證
dataset_val = ImageFolderDataset(os.path.join(data_path, "val"), shuffle=True)trans_val = [transforms.Decode(),transforms.Resize(224 + 32),transforms.CenterCrop(224),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_val = dataset_val.map(operations=trans_val, input_columns=["image"])
dataset_val = dataset_val.batch(batch_size=16, drop_remainder=True)# construct model
network = ViT()# load ckpt
param_dict = ms.load_checkpoint(vit_path)
ms.load_param_into_net(network, param_dict)network_loss = CrossEntropySmooth(sparse=True,reduction="mean",smooth_factor=0.1,num_classes=num_classes)# define metric
eval_metrics = {'Top_1_Accuracy': train.Top1CategoricalAccuracy(),'Top_5_Accuracy': train.Top5CategoricalAccuracy()}if ascend_target:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O2")
else:model = train.Model(network, loss_fn=network_loss, optimizer=network_opt, metrics=eval_metrics, amp_level="O0")# evaluate model
result = model.eval(dataset_val)
print(result)
模型推理
dataset_infer = ImageFolderDataset(os.path.join(data_path, "infer"), shuffle=True)trans_infer = [transforms.Decode(),transforms.Resize([224, 224]),transforms.Normalize(mean=mean, std=std),transforms.HWC2CHW()
]dataset_infer = dataset_infer.map(operations=trans_infer,input_columns=["image"],num_parallel_workers=1)
dataset_infer = dataset_infer.batch(1)
import os
import pathlib
import cv2
import numpy as np
from PIL import Image
from enum import Enum
from scipy import ioclass Color(Enum):"""dedine enum color."""red = (0, 0, 255)green = (0, 255, 0)blue = (255, 0, 0)cyan = (255, 255, 0)yellow = (0, 255, 255)magenta = (255, 0, 255)white = (255, 255, 255)black = (0, 0, 0)def check_file_exist(file_name: str):"""check_file_exist."""if not os.path.isfile(file_name):raise FileNotFoundError(f"File `{file_name}` does not exist.")def color_val(color):"""color_val."""if isinstance(color, str):return Color[color].valueif isinstance(color, Color):return color.valueif isinstance(color, tuple):assert len(color) == 3for channel in color:assert 0 <= channel <= 255return colorif isinstance(color, int):assert 0 <= color <= 255return color, color, colorif isinstance(color, np.ndarray):assert color.ndim == 1 and color.size == 3assert np.all((color >= 0) & (color <= 255))color = color.astype(np.uint8)return tuple(color)raise TypeError(f'Invalid type for color: {type(color)}')def imread(image, mode=None):"""imread."""if isinstance(image, pathlib.Path):image = str(image)if isinstance(image, np.ndarray):passelif isinstance(image, str):check_file_exist(image)image = Image.open(image)if mode:image = np.array(image.convert(mode))else:raise TypeError("Image must be a `ndarray`, `str` or Path object.")return imagedef imwrite(image, image_path, auto_mkdir=True):"""imwrite."""if auto_mkdir:dir_name = os.path.abspath(os.path.dirname(image_path))if dir_name != '':dir_name = os.path.expanduser(dir_name)os.makedirs(dir_name, mode=777, exist_ok=True)image = Image.fromarray(image)image.save(image_path)def imshow(img, win_name='', wait_time=0):"""imshow"""cv2.imshow(win_name, imread(img))if wait_time == 0: # prevent from hanging if windows was closedwhile True:ret = cv2.waitKey(1)closed = cv2.getWindowProperty(win_name, cv2.WND_PROP_VISIBLE) < 1# if user closed window or if some key pressedif closed or ret != -1:breakelse:ret = cv2.waitKey(wait_time)def show_result(img: str,result: Dict[int, float],text_color: str = 'green',font_scale: float = 0.5,row_width: int = 20,show: bool = False,win_name: str = '',wait_time: int = 0,out_file: Optional[str] = None) -> None:"""Mark the prediction results on the picture."""img = imread(img, mode="RGB")img = img.copy()x, y = 0, row_widthtext_color = color_val(text_color)for k, v in result.items():if isinstance(v, float):v = f'{v:.2f}'label_text = f'{k}: {v}'cv2.putText(img, label_text, (x, y), cv2.FONT_HERSHEY_COMPLEX,font_scale, text_color)y += row_widthif out_file:show = Falseimwrite(img, out_file)if show:imshow(img, win_name, wait_time)def index2label():"""Dictionary output for image numbers and categories of the ImageNet dataset."""metafile = os.path.join(data_path, "ILSVRC2012_devkit_t12/data/meta.mat")meta = io.loadmat(metafile, squeeze_me=True)['synsets']nums_children = list(zip(*meta))[4]meta = [meta[idx] for idx, num_children in enumerate(nums_children) if num_children == 0]_, wnids, classes = list(zip(*meta))[:3]clssname = [tuple(clss.split(', ')) for clss in classes]wnid2class = {wnid: clss for wnid, clss in zip(wnids, clssname)}wind2class_name = sorted(wnid2class.items(), key=lambda x: x[0])mapping = {}for index, (_, class_name) in enumerate(wind2class_name):mapping[index] = class_name[0]return mapping# Read data for inference
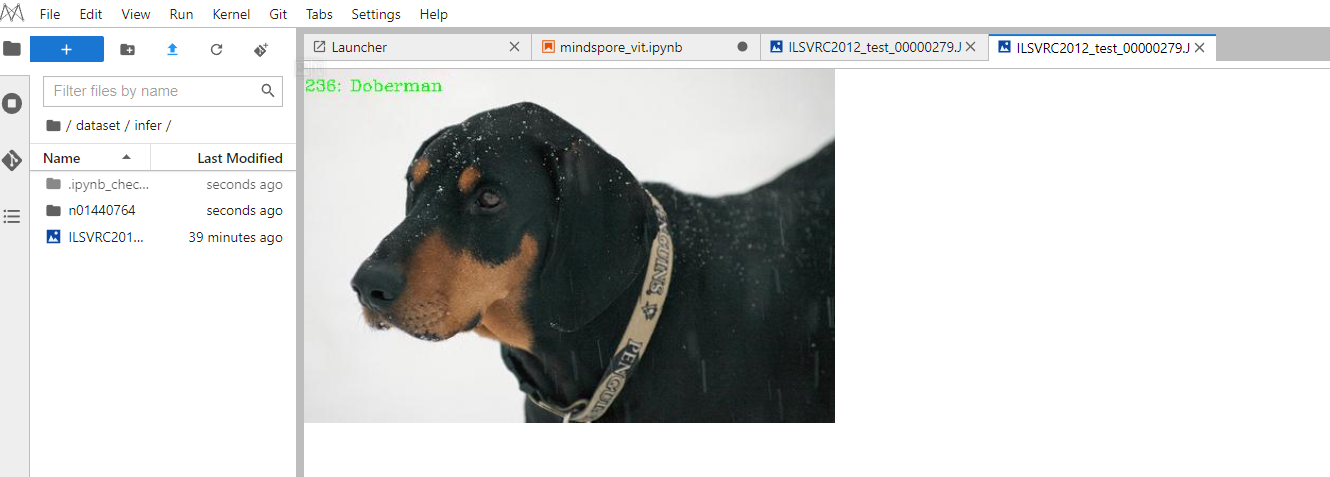
for i, image in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):image = image["image"]image = ms.Tensor(image)prob = model.predict(image)label = np.argmax(prob.asnumpy(), axis=1)mapping = index2label()output = {int(label): mapping[int(label)]}print(output)show_result(img="./dataset/infer/n01440764/ILSVRC2012_test_00000279.JPEG",result=output,out_file="./dataset/infer/ILSVRC2012_test_00000279.JPEG")
推理過程完成后,在推理文件夾下可以找到圖片的推理結果,可以看出預測結果是Doberman,與期望結果相同,驗證了模型的準確性。





--自定義的框架完成)
)

)







之安裝SonarQube)

)
)