目錄
- NestLoopJoin算法
- Simple Nested-Loop Join
- Index Nested-Loop Join
- Block Nested-Loop Join
- Batched Key Access
- Hash Join算法
- In-Memory Join(CHJ)
- On-Disk Hash Join
- 參考鏈接
在8.0.18之前,MySQL只支持NestLoopJoin算法,最簡單的就是Simple NestLoop Join,MySQL針對這個算法做了若干優化,實現了Block NestLoop Join,Index NestLoop Join和Batched Key Access等,有了這些優化,在一定程度上能緩解對HashJoin的迫切程度。但是HashJoin的支持使得MySQL優化器有更多選擇,SQL的執行路徑也能做到更優,尤其是對于等值join的場景。
NestLoopJoin算法
長期以來,在MySQL中執行聯接的唯一算法是嵌套循環算法的變體。
Simple Nested-Loop Join
如果我們執行這樣一條等值查詢語句:
select * from t1 straight_join t2 on (t1.a=t2.b);
由于表 t2 的字段 b 上沒有索引,每次到 t2 去匹配的時候,就要做一次全表掃描。就相當于是雙for循環。如果 t1 和 t2 都是 10 萬行的表(當然了,這也還是屬于小表的范圍),就要掃描 100 億行。
SimpleNestLoopJoin顯然是很低效的,對內表需要進行N次全表掃描,實際復雜度是N*M,N是外表的記錄數目,M是記錄數,代表一次掃描內表的代價。為此,MySQL針對SimpleNestLoopJoin做了若干優化。
Index Nested-Loop Join
如果我們能對內表的join條件建立索引,那么對于外表的每條記錄,無需再進行全表掃描內表,只需要一次Btree-Lookup即可,整體時間復雜度降低為N*O(logM)。
再來看看這一句
select * from t1 straight_join t2 on (t1.a=t2.a);
在這條語句里,被驅動表 t2 的字段 a 上有索引,join 過程用上了這個索引,因此這個語句的執行流程是這樣的:

執行流程示意圖如下:
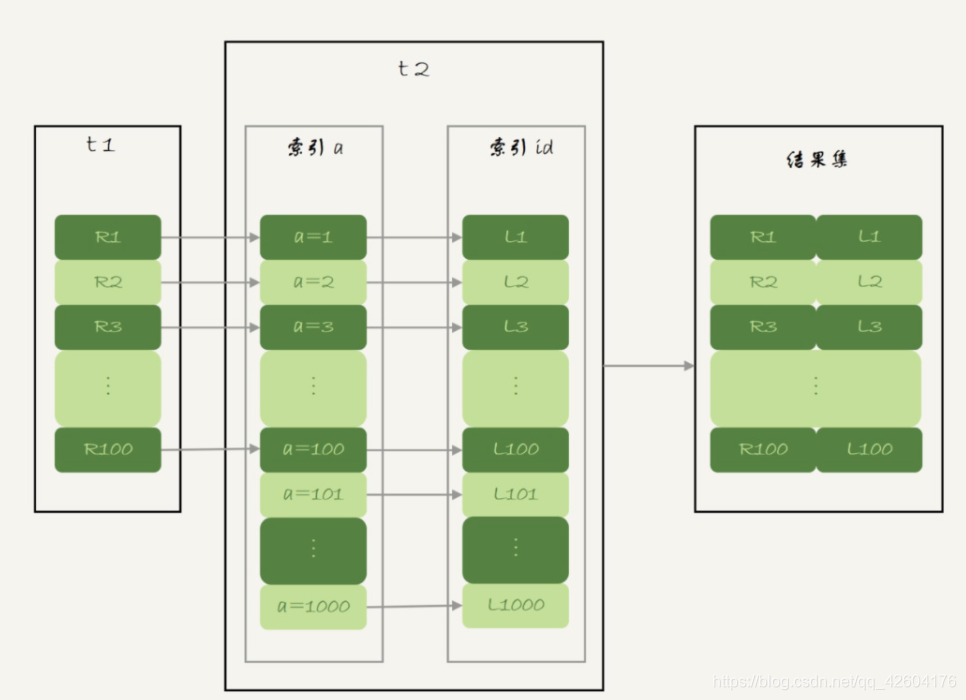

對比HashJoin,對于外表每條記錄,HashJoin是一次HashTable的search,當然HashTable也有build時間,還需要處理內存不足的情況,不一定比INLJ好。
Block Nested-Loop Join
MySQL采用了批量技術,即一次利用join_buffer_size緩存足夠多的記錄,每次遍歷內表時,每條內表記錄與這一批數據進行條件判斷,這樣就減少了掃描內表的次數,如果內表比較大,間接就緩解了IO的讀壓力。
Simple Nested-Loop Join 與 Block Nested-Loop Join從時間復雜度上來說,這兩個算法是一樣的。但是,Block Nested-Loop Join是內存操作,速度上會快很多,性能也更好。
示意圖如下:
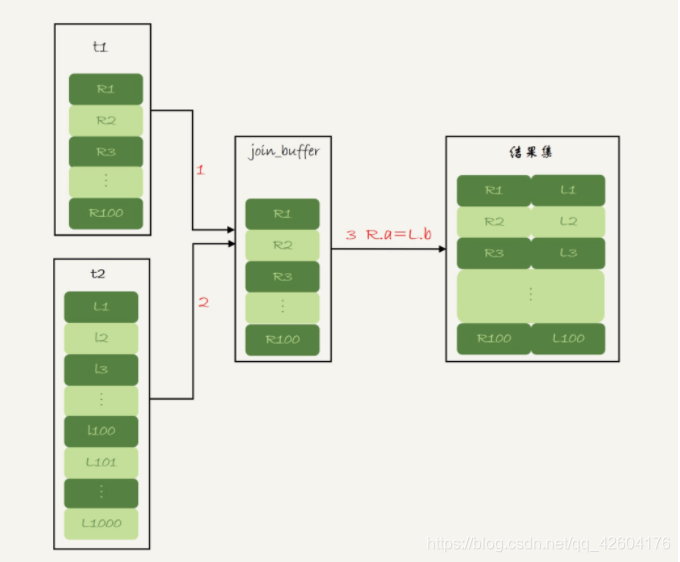
Batched Key Access
IndexNestLoopJoin利用join條件的索引,通過Btree-Lookup去匹配減少了遍歷內表的代價。如果join條件是非主鍵列,那么意味著大量的回表和隨機IO。BKA優化的做法是,將滿足條件的一批數據按主鍵排序,這樣回表時,從主鍵的角度來說就相對有序,緩解隨機IO的代價。BKA實際上是利用了MRR特性(MultiRangeRead),訪問數據之前,先將主鍵排序,然后再訪問。主鍵排序的緩存大小通過參數read_rnd_buffer_size控制。
Hash Join算法
NestLoopJoin算法簡單來說,就是雙重循環,遍歷外表(驅動表),對于外表的每一行記錄,然后遍歷內表,然后判斷join條件是否符合,進而確定是否將記錄吐出給上一個執行節點。從算法角度來說,這是一個M*N的復雜度。HashJoin是針對equal-join場景的優化,基本思想是,將外表數據load到內存,并建立hash表,這樣只需要遍歷一遍內表,就可以完成join操作,輸出匹配的記錄。如果數據能全部load到內存當然好,邏輯也簡單,一般稱這種join為CHJ(Classic Hash Join),之前MariaDB就已經實現了這種HashJoin算法。如果數據不能全部load到內存,就需要分批load進內存,然后分批join,下面具體介紹這幾種join算法的實現。
In-Memory Join(CHJ)
HashJoin一般包括兩個過程,創建hash表的build過程和探測hash表的probe過程。
1).build phase
遍歷外表,以join條件為key,查詢需要的列作為value創建hash表。這里涉及到一個選擇外表的依據,主要是評估參與join的兩個表(結果集)的大小來判斷,誰小就選擇誰,這樣有限的內存更容易放下hash表。
2).probe phase
hash表build完成后,然后逐行遍歷內表,對于內表的每個記錄,對join條件計算hash值,并在hash表中查找,如果匹配,則輸出,否則跳過。所有內表記錄遍歷完,則整個過程就結束了

On-Disk Hash Join
CHJ的限制條件在于,要求內存能裝下整個外表。在MySQL中,Join可以使用的內存通過參數join_buffer_size控制。如果join需要的內存超出了join_buffer_size,那么CHJ將無能為力,只能對外表分成若干段,每個分段逐一進行build過程,然后遍歷內表對每個分段再進行一次probe過程。假設外表分成了N片,那么將掃描內表N次。這種方式當然是比較弱的。
在MySQL8.0中,如果join需要內存超過了join_buffer_size,build階段會首先利用hash算將外表進行分區,并產生臨時分片寫到磁盤上;然后在probe階段,對于內表使用同樣的hash算法進行分區。由于使用分片hash函數相同,那么key相同(join條件相同)必然在同一個分片編號中。接下來,再對外表和內表中相同分片編號的數據進行CHJ的過程,所有分片的CHJ做完,整個join過程就結束了。這種算法的代價是,對外表和內表分別進行了兩次讀IO,一次寫IO。相對于之之前需要N次掃描內表IO,現在的處理方式更好。
順序為:外表的分片、內表分片、哈希連接

參考鏈接
join語句怎么優化?
MySQL8.0 新特性 Hash Join
哈希加入MySQL 8
MySQL · 新特征 · MySQL 哈希連接實現介紹


)










)

知識總結以及源碼分析》)
)


