多臺計算機共享內存
共享內存多處理器 (Shared Memory Multiprocessor)
There are three types of shared memory multiprocessor:
共有三種類型的共享內存多處理器:
UMA (Uniform Memory Access)
UMA(統一內存訪問)
NUMA (Non- uniform Memory Access)
NUMA(非統一內存訪問)
COMA (Cache Only Memory)
COMA(僅緩存內存)
1)UMA(統一內存訪問) (1) UMA (Uniform Memory Access))
In this type of multiprocessor, all the processors share a unique centralized memory so, that each CPU has the same memory access time.
在這種類型的多處理器中,所有處理器共享唯一的集中式內存,以便每個CPU具有相同的內存訪問時間。
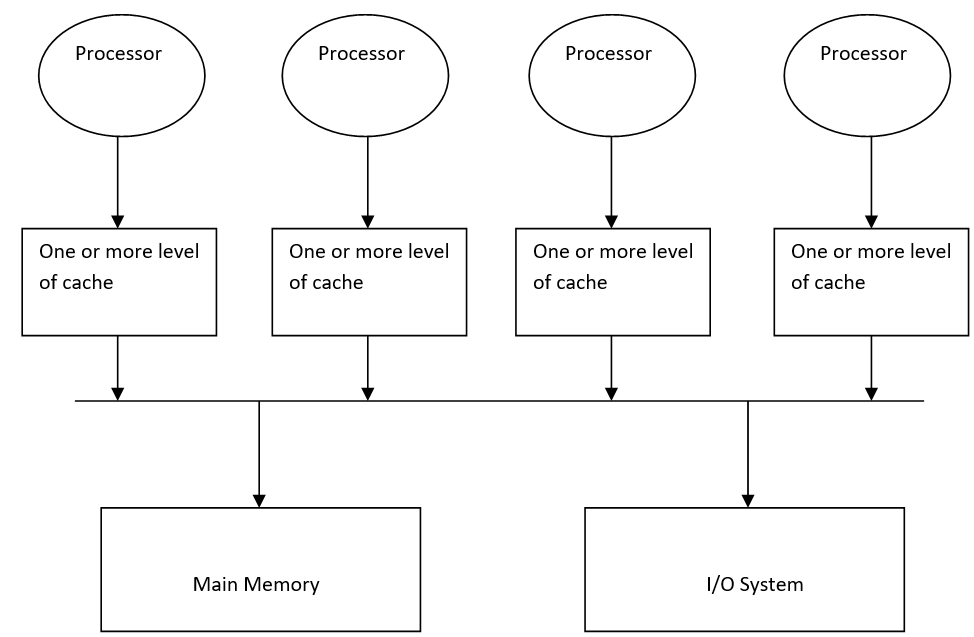
2)NUMA(非統一內存訪問) (2) NUMA (Non- uniform Memory Access))
In the NUMA multiprocessor model, the access time varies with the location of the memory word. Here the shared memory is physically distributed among all the processors called local memories.
在NUMA多處理器模型中 ,訪問時間隨存儲字的位置而變化。 在這里,共享內存在物理上分布在所有稱為本地內存的處理器之間。
So, we can call this as a distributed shared memory processor.
因此,我們可以稱其為分布式共享內存處理器。
3)COMA(僅緩存內存) (3) COMA (Cache Only Memory))
The COMA model is a special case of a non-uniform memory access model; here all the distributed local memories are converted into cache memories. Data can migrate and can be replicated in various memories but cannot be permanently or temporarily stored.
COMA模型是非均勻內存訪問模型的特例; 在這里,所有分布式本地內存都轉換為高速緩存。 數據可以遷移并可以在各種內存中復制,但是不能永久或臨時存儲。
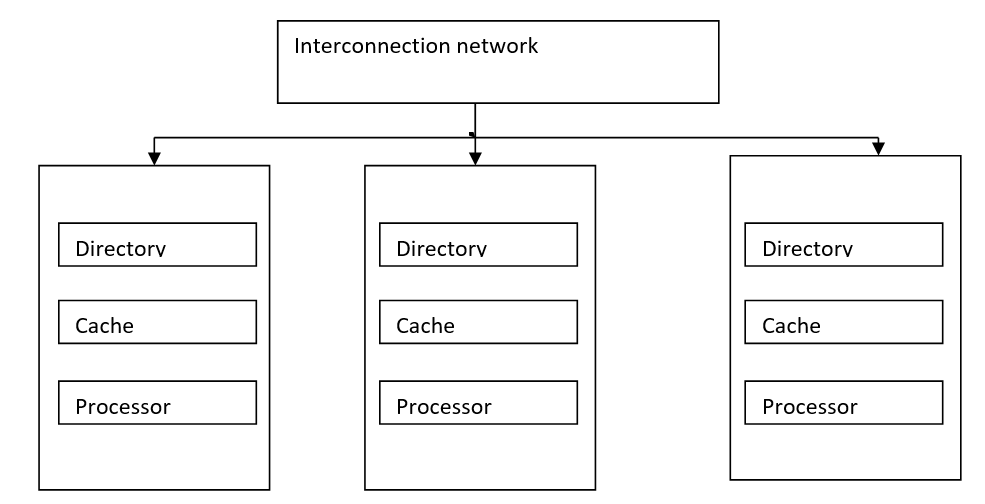
We have discussed different types of shared-memory multiprocessors. Now we are moving forward to take a short overview of instruction execution.
我們討論了不同類型的共享內存多處理器 。 現在,我們將對指令執行進行簡要概述。
指令執行 (Instruction Execution)
Now, first of all, what is an instruction, any command that we pass to a computer or system to perform is known as an instruction. A typical instruction consists of a sequence of operations that are fetched, decode, operand fetches, execute and write back. These phases are ideal for overlap execution on a pipeline.
現在,首先,什么是指令,我們傳遞給計算機或系統要執行的任何命令都稱為指令。 典型的指令由一系列的操作組成,這些操作被提取,解碼,取操作數,執行和回寫。 這些階段非常適合在管道上執行重疊。
There are two ways of executing an instruction in a pipeline system and a non-pipeline system.
在管道系統和非管道系統中有兩種執行指令的方式。
In a non-pipeline system single hardware component which can take only one task at a time from its input and produce the result at the output.
在非管道系統中,單個硬件組件一次只能從其輸入執行一項任務,并在輸出端產生結果。
On the other hand in case of a pipeline system single hardware component we can split the hardware resources into small components or segments.
另一方面,在流水線系統中,只有一個硬件組件,我們可以將硬件資源拆分為較小的組件或段。
Disadvantages of non-pipeline
非管道的缺點
We process only one input at a single time.
我們一次只能處理一個輸入。
Production of partial or segmented output is not possible in the case of the non-pipeline system.
在非管道系統中,無法產生部分或分段輸出。
When you will read in deep about pipeline system you will discover pipeline are linear and non-linear also and further linear pipelines are also classified into synchronous and asynchronous.
當您深入了解管道系統時,您會發現管道也是線性和非線性的,進一步的線性管道也分為同步和異步。
As this article was only about the introduction of instruction execution so, we will get further inside the pipeline system.
由于本文僅是關于指令執行的介紹,因此,我們將深入了解流水線系統。
Conclusion:
結論:
In the above article we have discussed the shared memory multiprocessor and introduction instruction execution, I hope you all have gathered the concepts strongly. For further queries, you shoot your questions in the comment section below.
在以上文章中,我們討論了共享內存多處理器和入門指令的執行 ,希望大家都認真收集了這些概念。 如有其他疑問,請在下面的評論部分中提出問題。
翻譯自: https://www.includehelp.com/basics/shared-memory-multiprocessor-and-instruction-execution-computer-architecture.aspx
多臺計算機共享內存



 使用Python的線性代數)

)
從同事那里取來的工程不能編譯運行,出現以下錯誤,求幫助)







,isdigit(),isnumeric()和Methods之間的區別)


![bzoj1699[Usaco2007 Jan]Balanced Lineup排隊](http://pic.xiahunao.cn/bzoj1699[Usaco2007 Jan]Balanced Lineup排隊)
 套裝1)
