文章目錄
- 系統大致架構
- 可擴展性
- 負載均衡器與會話保持
- 引入冗余增強系統可用性
- 緩存減輕數據庫壓力
- 異步處理
- 參考
系統大致架構
當一個用戶請求從客戶端出發,經過網絡傳輸,達到 Web 服務層,接著進入應用層,最后抵達數據層,它所途徑的過程如下:

對應到系統設計的邏輯層:
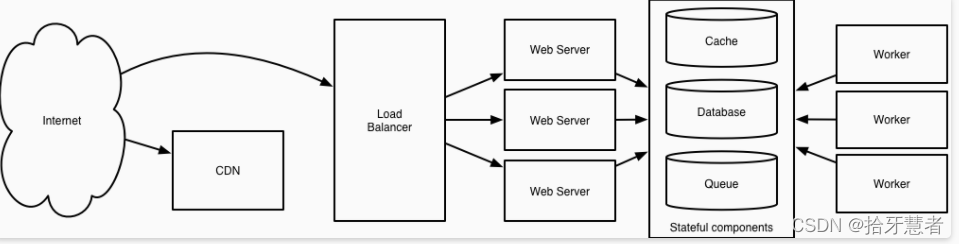
運作機制如下:
1、客戶端查DNS得到服務對應的IP地址,可能指向位于Web服務之前的負載均衡器,也可能是CDN,就近提供對象存儲中的靜態資源
2、發向Web服務的請求被負載均衡器(如反向代理)按照既定策略分給相應的Web服務器,進入應用層
3、請求到達應用層后,經過Service Discovery、Service Mesh等服務查詢機制找到目標微服務,開始處理請求
4、數據請求會通過一系列讀寫操作轉移到數據層,異步的操作還會進入消息隊列排隊,但最終都會抵達數據層
5、對熱點數據的請求會被數據庫之前的緩存層擋下,其余的落到數據庫,可能是經過分庫分表、反范式優化,并由復制機制保證數據一致性的SQL數據庫,也可能是查詢性能更好的Nosql數據庫抑或是對象存儲來保存數據。
接下來的系統設計主要就是圍繞這幾個關鍵的邏輯組件展開。
可擴展性
可擴展性,意味著能夠通過向系統添加資源的方式應對不斷增加的工作量。而加資源有兩種方式:
- 縱向擴展(Vertical scaling):即提升單機配置,對單臺機器加內存、處理器、硬盤等硬件資源。投入足夠多的預算,就能砸出一臺配置豪華的服務器
- 橫向擴展(Horizontal scaling):即加機器,數量上從一臺擴展到多臺,多服務器形成拓撲結構。投入足夠多的預算,就能擁有一個機房,甚至遍布全球的數據中心
對于系統設計而言,可擴展性要求系統能夠將加入進來的更多資源(如多核、多機)利用起來。
機器由一臺變成多臺之后,面臨的最大問題是資源分配,如何充分利用這些機器?即,如何均衡負載?
負載均衡器與會話保持
負載均衡器(Load Balancer)負責把用戶請求分發到多個服務器上,具體的,公網 Load Balancer 根據路由規則分發入站 HTTP 請求,決定把數據包實際發送給哪個內網服務器。常見的策略是基于負載情況分發、輪流均分、基于資源依賴情況分發。不建議用 DNS 來充當負載均衡器,因為操作系統以及應用層的 DNS 緩存會破壞這種輪流均分的機制。另一方面,不同類型的服務對資源的依賴情況(帶寬、存儲、計算能力等)可能不一樣,所以也可以采用專用服務器,并根據資源依賴情況分發,比如對 gif、jpg、image、video 等使用不同的專用服務器,并通過子域名等方式來區分
會話保持:
加一層 Load Balancer 解決了資源分配的問題,但又帶來了一個新問題:前后兩個請求可能被負載均衡器轉發到不同的服務器上,如果這兩個請求有關聯(比如登錄和下單),前置的狀態就會丟失(用戶剛登錄完點擊下單接著可能又要求登錄)
一種解決辦法是粘滯會話(Sticky sessions),把相關聯的請求轉發給同一臺服務器:
比如在 Cookie 中帶上服務器的標識信息,之后的一系列請求都轉給那臺服務器,但 Cookie 可能會被禁用,因此一般會綜合使用多種方式來保持會話
另一種方案是把 Session“外包”出去,存放到公共的地方,供其它服務器共享訪問:
每臺服務器都包含完全相同的代碼庫,不在本地光盤或內存中存儲任何與用戶相關的數據,如會話或個人資料圖片。會話需要存儲在所有應用服務器都可以訪問的集中數據存儲中。
至此,我們增加了一些機器,并通過一個負載均衡器讓多臺機器共同分擔運轉起來了,看起來一切都很完美……那么,如果這個負載均衡器 down 掉了呢?
引入冗余增強系統可用性
引入負載均衡器之后,所有請求都要先經過負載均衡器,負載均衡器就成為了網絡拓撲結構中脆弱的單點,一旦發生故障,身后的所有服務器就都無法訪問了。
為了避免單點故障(Single Point of Failure),負載均衡器同樣需要引入冗余(比如使用一對兒負載均衡器),一般有兩種故障轉移(Fail-over)模式:
- 主動-被動(Active-passive):主動的工作,被動的備用,主動的 down 掉后被動的上
- 主動-主動(Active-active):同時工作,一個 down 掉之后不影響
無論采用哪種工作模式,引入冗余都能縮短宕機時間,提升系統可靠性與可用性
理論上,有了可靠的負載均衡機制,我們就能將 1 臺服務器輕松擴展到 n 臺,然而,如果這 n 臺機器仍然使用同一數據庫的話,很快數據庫就會成為系統的性能瓶頸和可靠性瓶頸
如法炮制,我們可以擴展數據庫的處理能力,多加幾個庫,即引入冗余,一般有兩種模式:
- 主從復制:主庫直接讀寫,從庫在主庫收到查詢時,執行相同的查詢。如果主庫 down 掉了,就在從庫里面提升一個作為主庫
- 主主復制:都可以寫,寫操作也會被復制到另一個庫中
數據庫引入冗余之后,甚至還能對多個從庫進行負載均衡(尤其適用于讀密集的場景):
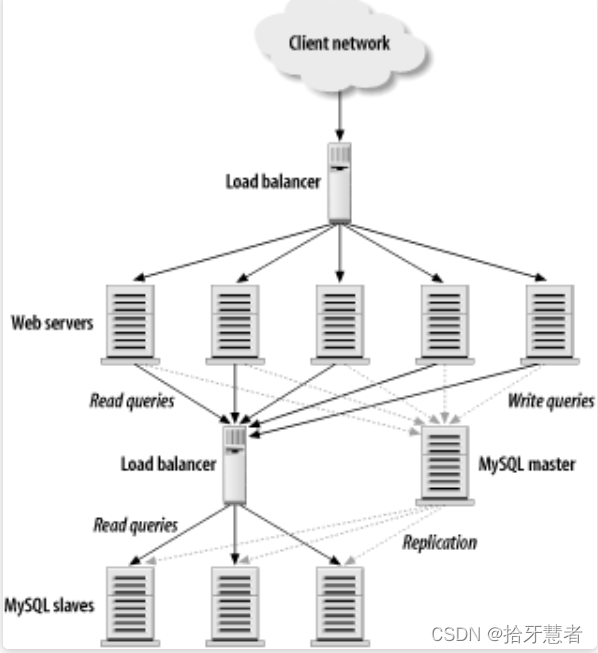
以及按內容特點分區存儲(Partitioning):
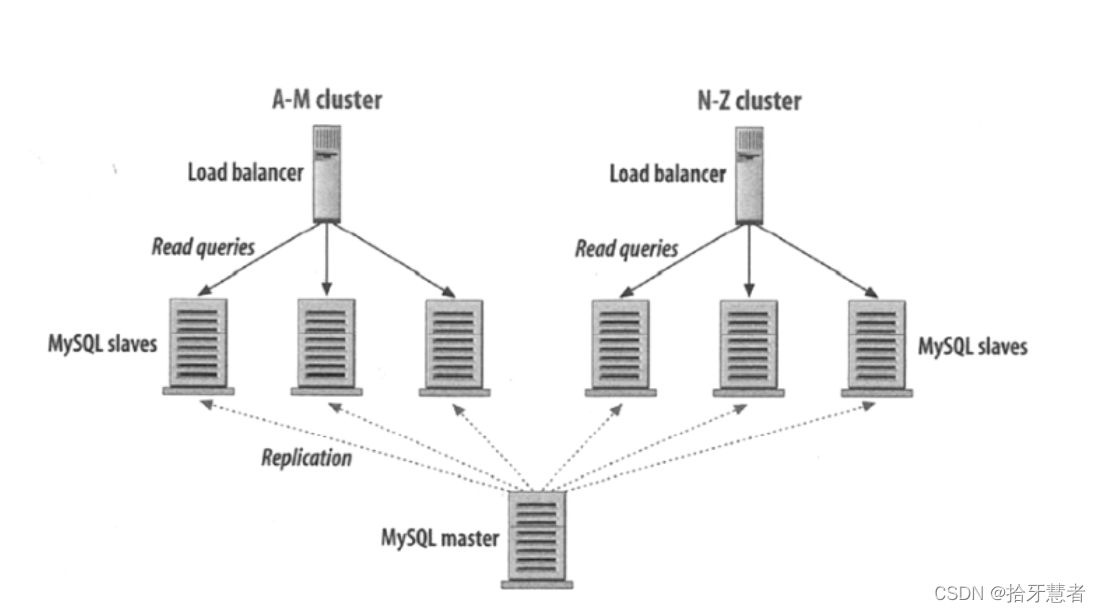
將姓名以 A-M 開頭的數據存放到左邊的幾個數據庫,N-Z 開頭的存放到右邊
同時,也可以通過分庫分表(Sharding)、反范式化(Denormalization)、SQL 調優(SQL tuning)等方式優化查詢
緩存減輕數據庫壓力
盡可能減少數據庫操作,比如在 Web 服務與數據之間增加一層內存緩存,查詢時優先走緩存,緩存中沒有才從數據庫中取。
一般有兩種緩存模式:
- 緩存查詢結果
- 緩存對象
緩存所有查詢結果最大的問題在于,數據發生變化后,很難判定緩存是否過期:
在緩存復雜查詢時,很難刪除緩存的結果(誰沒有?)。
當一段數據發生更改(例如表單元格)時,需要刪除可能包含該表單元格的所有緩存查詢。
而緩存對象是指緩存根據原始數據組裝出的數據模型(比如一個 Java 類實例),優勢在于獲知數據變化之后,能夠丟棄與之具有邏輯關聯的數據對象,從而解決緩存過期的難題。
至此,我們已經自下而上地討論了包括硬件資源、數據庫、緩存在內的可擴展性問題,那么,Web 服務自身應該如何擴展?
異步處理
對于 Web 服務而言,提升可擴展性的主要途徑是將耗時的同步工作改成異步處理,從而允許將這些工作“外包”給多個 Worker 去做,或者提前完成能夠預知的部分.
參考
1、http://gotocon.com/dl/goto-aar-2012/slides/MartinThompson_ItsAllANumbersGameTheDirtyLittleSecretOfScalableSystems.pdf
2、http://www.ayqy.net/blog/scalability-in-the-real-world/
3、https://github.com/donnemartin/system-design-primer/blob/master/README-zh-Hans.md
)

權衡取舍)


DNS機制原理)

CDN機制原理)

負載均衡)

![[LeetCode]Find Minimum in Rotated Sorted Array](http://pic.xiahunao.cn/[LeetCode]Find Minimum in Rotated Sorted Array)
反向代理)
單鏈表)
,sigprocmask())
Service Discovery與微服務)
幾天真是累死了。。。先寫一個幻方的程序吧)

Service Mesh)
