文章目錄
- 數據庫擴展
- 一致性問題
- Replication (復制)
- 異步復制
- 同步復制
- 半同步復制
- 拓撲結構
- 單主結構
- 多主結構
- 無主結構
- 復制具體措施
- 參考
數據庫擴展
之前在第一章后臺系統可擴展性學習筆記(一)概要談到:理論上,有了可靠的負載均衡機制,我們就能將 1 臺服務器輕松擴展到 n 臺,然而,如果這 n 臺機器仍然使用同一數據庫的話,很快數據庫就會成為系統的性能瓶頸和可靠性瓶頸,所以我們需要對于數據庫進行擴展。
- 縱向擴展:提升單機配置(硬盤、內存、CPU 等等),但同樣會遭遇單機性能瓶頸
- 橫向擴展:增加機器,數量上從單數據庫實例擴展到多實例
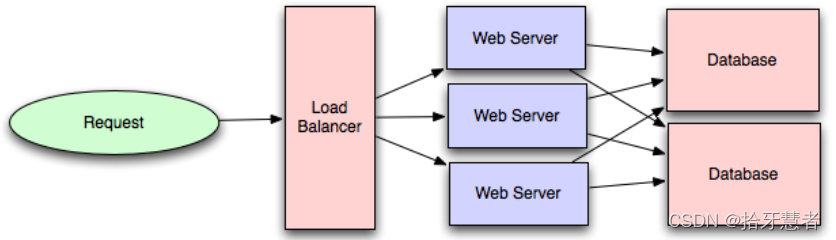
加幾個數據庫,共同分擔來自應用層的流量就完成了從單庫到多庫的擴展,但是此時最重要的就是考慮到一致性問題了。
一致性問題
如果同一數據存在多份拷貝,那么就需要考慮如何保證其一致性
數據庫與應用服務最大的區別在于,應用服務可以是無狀態的(或者可以將共享狀態抽離出去,比如放到數據庫),而數據庫操作一定是有狀態的,在擴展數據庫時必須要考慮數據的一致性。
具體的,一致性分為 3 種,嚴格程度依次遞減:
- 強一致性(Strong consistency):寫完之后,立即就能讀到
- 最終一致性(Eventual consistency):寫完之后,保證最終能讀到
- 弱一致性(Weak consistency):寫完之后,不一定能讀到
Replication (復制)
所以,從單庫擴展成多庫,至少要有一種數據更新同步機制,稱之為Replication(復制)
計算中的復制涉及共享信息,以確保冗余資源(如軟件或硬件組件)之間的一致性,從而提高可靠性、容錯性或可訪問性。
即,通過復制(寫操作)來保證多份數據拷貝的信息一致性。例如,向數據庫實例 A 寫入數據時,也要把相同的數據寫入到實例 B、C、D 等.下面談談復制的手法:
異步復制
具體的,可以在寫完之后,再告知其它實例更新數據,即異步復制(Asynchronous replication):
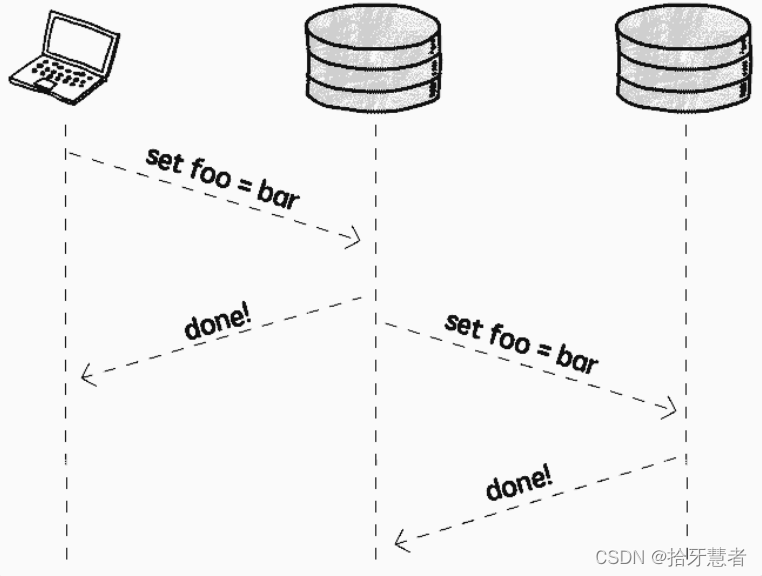
這種模式下,客戶端無需等待復制操作完成,不存在額外的性能影響。但問題在于:
- 有數據丟失風險
- 無法保證強一致性,因為存在復制延遲(Replication lag)
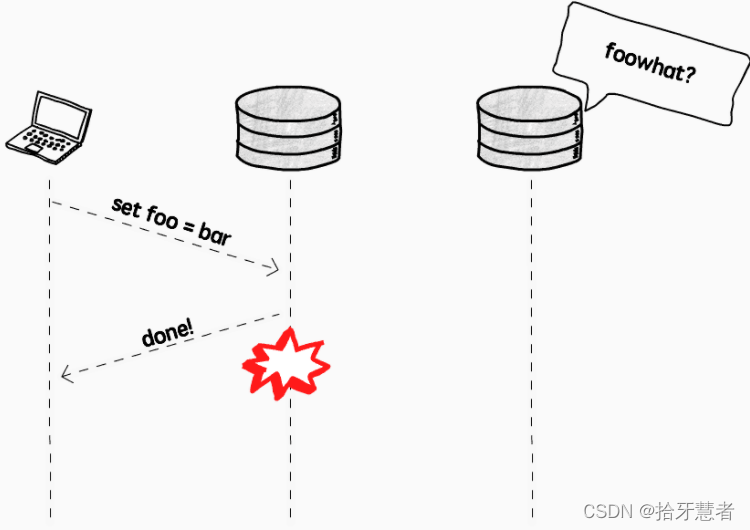
如果實例 A 在寫完之后,還沒來得及告知其它實例,自己卻 down 掉了,就會出現數據丟失:
另一方面,由于復制操作是異步完成的,數據更新實際上是滯后的:
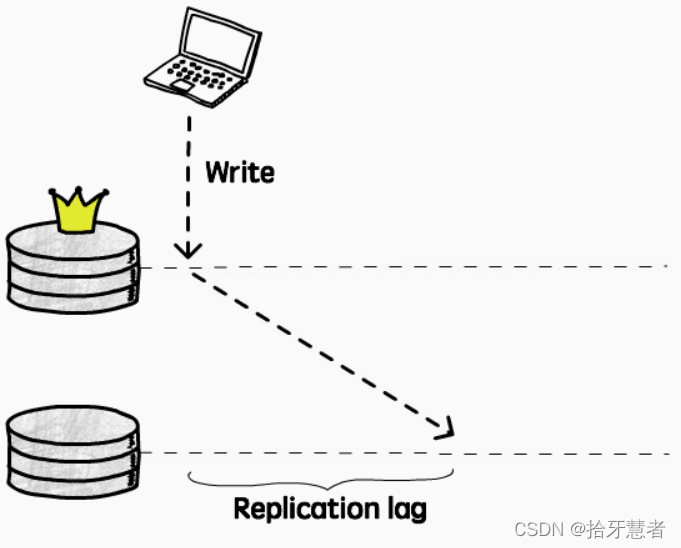
從當前實例上一個寫操作完成,到該操作被應用到其它實例的時間差稱為復制延遲(Replication lag)。在這期間,客戶端從其它實例上讀到的仍然是舊數據,顯然不滿足強一致性的要求(僅能保證最終一致性)
同步復制
想要達到嚴格的一致性要求,不得不考慮同步復制(Synchronous replication):
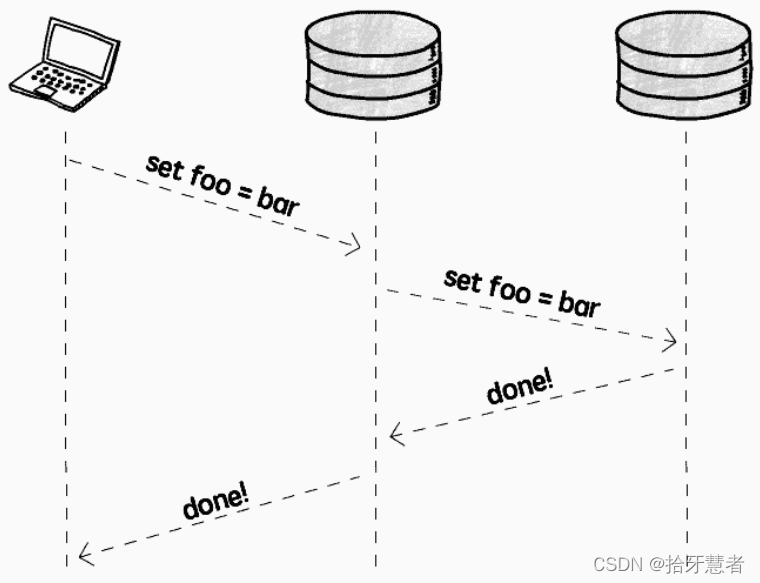
發生寫操作時,立即將操作同步到其它所有實例,復制完成之后才算寫完,以確保嚴格的一致性。
但同步復制會影響性能和可用性,代價頗高:
- 性能影響:需要等待整個復制過程完成
- 可用性影響:只要有一個實例出現故障(網絡等原因),整個寫操作就會失敗
并且數據庫實例數量越多,這兩方面的影響越大
半同步復制
特殊地,可以將兩種方式結合使用,稱之為半同步復制(Semi-synchronous replication):
一些數據庫和復制工具允許我們定義一些跟隨者來同步復制,而其他的只是使用異步方法。這有時被稱為半同步復制。
即要求一部分數據庫實例同步復制,其余的異步復制。
拓撲結構
拓撲結構上,復制可以分為 3 類:
- 單主結構(Single leader replication)
- 多主結構(Multi leader replication)
- 無主結構(Leaderless replication)
單主結構
即最常見的一主多從結構:
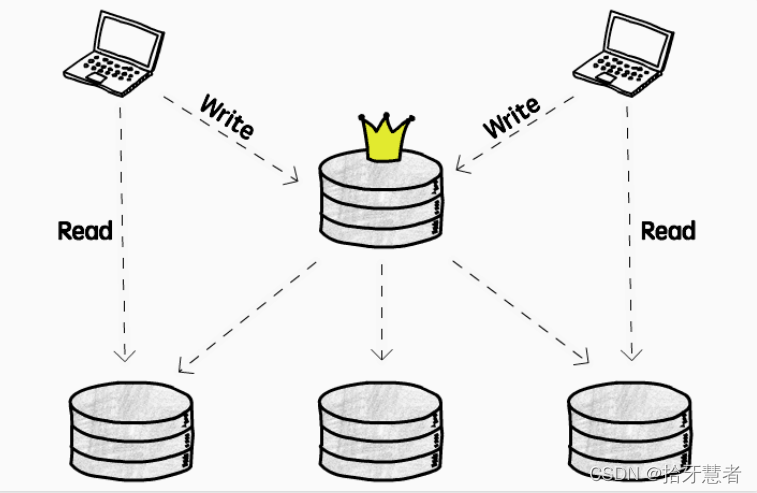
這種結構下,寫操作(增/刪/改)只允許發生在主庫,由主庫將寫操作復制到其它所有從庫,從庫只支持讀操作(查)。
由于所有客戶端都寫同一個庫,成功避免了寫操作沖突的大麻煩。但要注意的是:
- 承載寫操作壓力的仍然是單庫:不適用于寫密集(write-intensive)的應用,但好在大多數應用都是讀密集的
- 訪問主庫的延遲問題:主庫只有一個,只能放在某個確定的地理位置,意味著在某些區域發起寫操作(訪問主庫)可能要承擔較高的延遲
如果主庫 down 掉了,需要立即在從庫中選出一個接班人,擔起主庫的職責,保證這套機制正常運轉,但是這種故障轉移策略卻不那么容易實現。
- 如何確定主庫真的 down 掉了?
- 如何選擇新任主庫?
- 如何將寫操作轉到新任主庫上?
實際上,我們無法區分高延遲和不可用,通常認為超時就算不可用(無論是不是真的 down 掉了),接著啟動故障轉移預案,開始選擇新任主庫。選出一個不難,關鍵在于所選的新任主庫要被其它所有從庫認可其地位才算(即共識問題),比如預先定好接班次序。新任主庫選出來之后,要將所有寫操作轉發過來,比如增加一層分發機制,以允許路由控制。另外,如果采用的是異步復制,舊主庫恢復之后,尚未復制到其它從庫的數據與掉線期間新任主庫寫入的數據可能會出現沖突,此時通常采用 LWW(last-write-win)策略,直接丟棄舊數據,但同樣存在風險。
特殊的,一種有意思的情況是舊主庫恢復過來以為自己還是主庫,出現分裂(Split-brain):
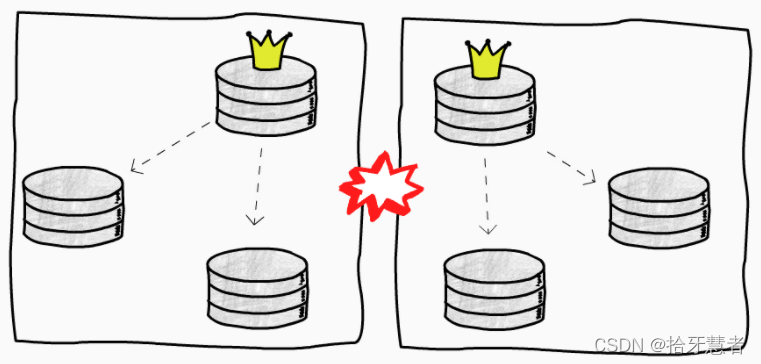
網絡故障也會導致這樣的情況,例如兩個集群之間出現網絡故障,無法互相訪問,都以為另一隊人馬掛掉了,于是各自開始大選。簡單的處理辦法是 STONITH(Shoot The Other Node In The Head),一旦發現存在多個主庫,直接停掉一個。
多主結構
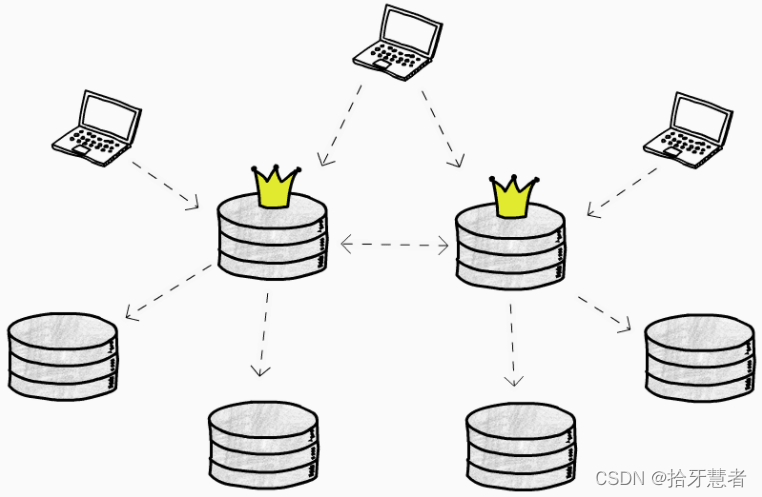
現在有了多個可寫的主庫,可以分擔寫操作,也可以多地部署,單主結構的 2 個問題迎刃而解。然而,大麻煩卻出現了,由于寫操作能夠同時發生在(異步復制的)多個庫,我們必須考慮如何解決寫入沖突。一般有 3 種思路:
- 避免沖突:比如按內容特征分庫存儲,互不相干,比如對于國內國外兩個主庫,如果能夠保證所有對國內數據的寫操作都能落到國內主庫上,所有對國外數據的寫操作都能落在國外主庫上,就不存在沖突了
- LWW(last-write-win)策略:給每個寫操作帶上時間戳,只保留最新版本
- 交由用戶來解決:記下沖突,應用程序提示給用戶,由用戶決定保留哪一份
無主結構
當然,還有一種不區分主庫的結構,所有庫都可讀可寫
看起來像是“全主結構”,那么可預見的,寫沖突將變得非常普遍,所以我們需要調整策略,避免使之成為“全主結構”:
- 寫:客戶端同時向多個數據庫寫,只要有一些成功了就算寫完
- 讀:客戶端同時從多個數據庫讀,各個庫返回數據及其對應的版本號,客戶端根據版本號來決定采用哪個
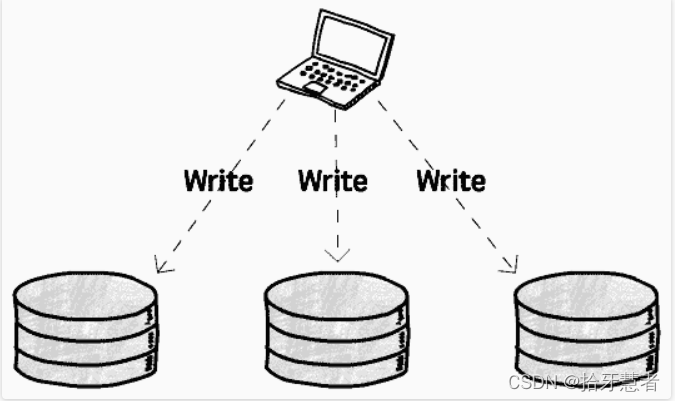
好處就是 沒有主庫,意味著不需要考慮故障轉移,單庫故障不影響整體,選擇新任主庫的各種麻煩問題都不復存在了。
沒有主庫也意味著沒有了數據同步機制,讀到的舊值無法自動更正。
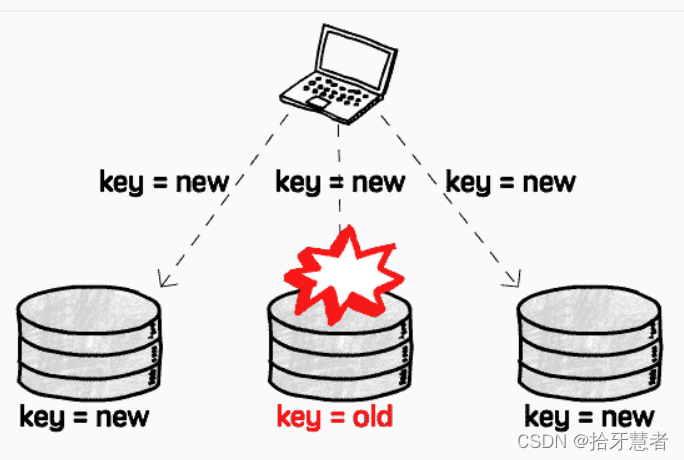
所以需要額外的糾錯機制,客戶端在讀到舊值時將新值寫回去(稱為Read repair),或者由獨立的進程專門負責找出舊值并糾正回來
另一個關鍵因素是讀/寫操作的目標庫數量,至少幾個庫寫入成功后,至少從幾個庫成功讀取才能保證一定能讀到新值?
如果w個庫寫入成功,接著成功讀到了r個庫的數據,那么必須滿足w + r > 庫的總數
相當于把冗余措施轉移給操作DB的一端了。
復制具體措施
具體的,把一些數據從一個庫拷貝到另一個庫有 3 種方式:
- 基于語句的復制:將寫操作語句原樣發一份給其它庫執行
- 日志傳送式復制:也叫物理復制,將數據庫日志傳遞給其它庫,從日志恢復出完全一致的數據。例如 PostgreSQL 提供的Streaming Replication
- 基于行的復制:也叫邏輯復制,傳遞專門用于復制的日志,按行復制。例如MySQL提供的的Mixed Binary Logging Format
一些問題:
按語句復制的問題在于,并不是所有語句的執行結果都是確定的,例如CURRENT_TIME()、RANDOM(),雖然一些數據庫會在復制時對這些值進行替換,但仍無法保證觸發器,以及用戶定義的函數有確定的執行結果。另一方面,還要確保事務操作在所有數據庫上的原子性,要么全都完成了,要么全都一點兒沒做。
日志傳送式復制能夠保證數據完全一致,但(面向存儲引擎的)日志通常無法跨數據庫版本使用,因為在不同版本的數據庫下,數據的物理存儲方式可能會發生變化。并且,日志傳送不適用于多主結構,因為無法把多份日志合并成一份
而基于行的復制是前兩種方式的結合,采用一種專門用于復制的日志,不再與存儲引擎耦合,因而能夠跨數據庫版本使用。與按語句復制相比,按行復制需要記錄更多的信息(比如一個語句影響了 100 行,需要按行都記下)
參考
http://www.ayqy.net/blog/database-replication/
)
Database Partitioning)

Database Denormalization)


NoSQL)
)
緩存)
![[linux]gdb調試](http://pic.xiahunao.cn/[linux]gdb調試)
異步機制與MQ)



)




)