目錄
- 1、基于鎖的并發數據結構
- 1、并發計數器
- 2、懶惰計數器
- 3、并發鏈表
- 4、并發隊列
- 5、并發散列表
- 總結
- 2、條件變量
- 使用(POSIX)
- 生產者/消費者 (有界緩沖區問題)
- 覆蓋條件
- 擴展
- 3、信號量
- 使用
- 二值信號量(鎖)
- 0值信號量(條件變量)
- 生產者消費者問題
- 讀寫鎖
- 哲學家就餐問題
- 使用鎖+條件變量實現信號量
- 擴展
- 4、并發問題總結
- 1、預防循環等待
- 2、使用非搶占鎖
- 3、完全避免互斥,使用CAS
- 4、調度避免死鎖
- 5、檢測死鎖并恢復
- 5、事件并發
- 時間并發與線程并發的區別
- 狀態管理問題
- 缺點
1、基于鎖的并發數據結構
一個標準的方法來創建一個并發數據結構:添加一把大鎖。
1、并發計數器
typedef struct counter_t {int value;pthread_mutex_t lock;
} counter_t;void init(counter_t *c) {c->value = 0;Pthread_mutex_init(&c->lock, NULL);
}void increment(counter_t *c) {Pthread_mutex_lock(&c->lock);c->value++;Pthread_mutex_unlock(&c->lock);
}void decrement(counter_t *c) {Pthread_mutex_lock(&c->lock);c->value--;Pthread_mutex_unlock(&c->lock);
}int get(counter_t *c) {Pthread_mutex_lock(&c->lock);int rc = c->value;Pthread_mutex_unlock(&c->lock);return rc;
}
它只是加了一把鎖,在調用函數操作該數據結構時獲取鎖,從調用返回時釋放鎖。
同步的計數器擴展性不好。單線程完成100萬次更新只需要很短的時間(大約0.03s),而兩個線程并發執行,每個更新100萬次,性能下降很多(超過5s!)。線程更多時,性能更差。
理想情況下,你會看到多處理上運行的多線程就像單線程一樣快。達到這種狀態稱為完美擴展(perfect scaling)。
2、懶惰計數器
懶惰計數器的基本思想是這樣的。如果一個核心上的線程想增加計數器,那就增加它的局部計數器,訪問這個局部計數器是通過對應的局部鎖同步的。因為每個CPU有自己的局部計數器,不同CPU上的線程不會競爭,所以計數器的更新操作可擴展性好。
懶惰計數器通過多個局部計數器和一個全局計數器來實現一個邏輯計數器,其中每個CPU核心有一個局部計數器。具體來說,在4個CPU的機器上,有4個局部計數器和1個全局計數器。除了這些計數器,還有鎖:每個局部計數器有一個鎖,全局計數器有一個。
但是,為了保持全局計數器更新(以防某個線程要讀取該值),局部值會定期轉移給全局計數器,方法是獲取全局鎖,讓全局計數器加上局部計數器的值,然后將局部計數器置零。
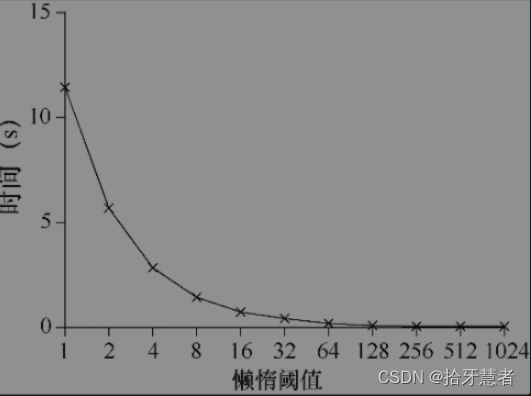
這種局部轉全局的頻度,取決于一個閾值,這里稱為S(表示sloppiness)。S越小,懶惰計數器則越趨近于非擴展的計數器。S越大,擴展性越強,但是全局計數器與實際計數的偏差越大。
在4個CPU上的4個線程,分別增加計數器100萬次。如果S小,性能很差(但是全局計數器精確度高)。如果S大,性能很好,但是全局計數器會有延時。懶惰計數器就是在準確性和性能之間折中。
typedef struct counter_t {int global;pthread_mutex_t glock;int local[NUMCPUS];pthread_mutex_t llocal[NUMCPUS];int threshold;
} counter_t;void init(counter_t *c, int threshold) {c->threshold = threshold;c->global = 0;for (int i = 0; i < NUMCPUS; i++) {c->local[i] = 0;Pthread_mutex_init(&c->llocal[i], NULL);}
}void update(counter_t *c, int threadID, int amt) {Pthread_mutex_lock(&c->llocal[threadID]);c->local[threadID] += amt;if (c->local[threadID] >= c->threshold) {// transfer to globPthread_mutex_lock(&c->glock);c->global += c->local[threadID];Pthread_mutex_unlock(&c->glock);c->local[threadID] = 0;}Pthread_mutex_unlock(&c->llocal[threadID]);
}int get(counter_t *c) {Pthread_mutex_lock(&c->glock);int rc = c->global;Pthread_mutex_unlock(&c->glock);return rc;
}
3、并發鏈表
typedef struct node_t {int key;struct node_t* next;
} node_t;typedef struct list_t {node_t* head;pthread_mutex_t lock;
} list_t;void init(list_t* list) {list->head = NULL;Pthread_mutex_init(&list->lock, NULL);
}void insert(list_t *list, int key)
{node_t* p = malloc(sizeof(node_t)); if (p == NULL) {perror("malloc");return -1;} p->key = key;// 假定malloc()是線程安全的,每個線程都可以調用它,不需要擔心競爭條件和其他并發缺陷。// 只有在更新共享列表時需要持有鎖Pthread_mutex_lock(&list->lock);p->next = list->head; // 頭插法list->head = p;Pthread_mutex_unlock(&list->lock);return 0;
}void find(list_t *list, int key)
{int ret = -1;Pthread_mutex_lock(&list->lock);node_t* cur = list->head;while (cur) {if (cur->key == key) {ret = 0;break;}cur = cur->next;}Pthread_mutex_unlock(&list->lock);return ret;
}
擴展,上面的代碼demo是一個鏈表一個鎖,這樣性能不大行。介紹一個過手鎖(hand-over-hand locking,也叫作鎖耦合,lock coupling)
原理也很簡單。每個節點都有一個鎖,替代之前整個鏈表一個鎖。遍歷鏈表的時候,首先搶占下一個節點的鎖,然后釋放當前節點的鎖。
增加了鏈表操作的并發程度。但是實際上,在遍歷的時候,每個節點獲取鎖、釋放鎖的開銷巨大,很難比單鎖的方法快。即使有大量的線程和很大的鏈表,這種并發的方案也不一定會比單鎖的方案快。也許某種雜合的方案(一定數量的節點用一個鎖)值得去研究。
4、并發隊列
typedef struct node_t {int value;struct node_t* next;
} node_t;typedef struct queue_t {node_t* head;node_t* tail;pthread_mutex_t headLock;pthread_mutex_t tailLock;
} queue_t;void init(queue_t* q) {node_t* tmp = malloc(sizeof(node_t));tmp->next = NULL;q->head = q->tail = tmp;Pthread_mutex_init(&q->headLock, NULL);Pthread_mutex_init(&q->tailLock, NULL);
}void enqueue(queue_t *q, int value)
{node_t* tmp = malloc(sizeof(node_t));assert(tmp != NULL);tmp->value = value;tmp->next = NULL;// 隊尾入隊Pthread_mutex_lock(&q->tailLock);q->tail->next = tmp;q->tail = tmp;Pthread_mutex_unlock(&q->tailLock);
}int dequeue(queue_t *q, int* value)
{Pthread_mutex_lock(&q->headLock);node_t* tmp = q->head;node_t* newHead = q->next;if (newHead == NULL) {Pthread_mutex_unlock(&q->headLock);return -1; // queue was empty}*value = newHead->value;q->head = newHead;Pthread_mutex_unlock(&q->headLock);free(tmp);return 0;
}
有兩個鎖,一個負責隊列頭,另一個負責隊列尾。這兩個鎖使得入隊列操作和出隊列操作可以并發執行,因為入隊列只訪問tail鎖,而出隊列只訪問head鎖。
使用了一個技巧,添加了一個假節點(在隊列初始化的代碼里分配的)。該假節點分開了頭和尾操作。
5、并發散列表
基于3的并發鏈表
#define BUCKETS (101)typedef struct hash_t {list_t lists[BUCKETS];
} hash_t;void Hash_Init(hash_t* H) {for (int i = 0; i < BUCKETS; i++) {init(&H->lists[i]);}
}void Hash_Insert(hash_t* H, int key) {int bucket = key % BUCKETS;return insert(&H->lists[bucket], key);
}int Hash_find(hash_t* H, int key) {int bucket = key % BUCKETS;return find(&H->lists[bucket], key);
}
每個散列桶(每個桶都是一個鏈表)都有一個鎖,而不是整個散列表只有一個鎖,從而支持許多并發操作。
總結
實現并發數據結構時,先從最簡單的方案開始,也就是加一把大鎖來同步。這樣做,你很可能構建了正確的鎖。如果發現性能問題,那么就改進方法,只要優化到滿足需要即可。
關于并發隊列的更多內容,查看:
https://www.cnblogs.com/lijingcheng/p/4454848.html
2、條件變量
多線程程序中,一個線程等待某些條件是很常見的。簡單的方案是自旋直到條件滿足,這是極其低效的,某些情況下甚至是錯誤的。那么,線程應該如何等待一個條件?
線程可以使用條件變量(condition variable),來等待一個條件變成真。條件變量是一個顯式隊列,當某些執行狀態(即條件,condition)不滿足時,線程可以把自己加入隊列,等待(waiting)該條件。另外某個線程,當它改變了上述狀態時,就可以喚醒一個或者多個等待線程(通過在該條件上發信號),讓它們繼續執行。
使用(POSIX)
// 聲明
pthread_cond_t c;
// op
wait()和signal()。
線程要睡眠的時候,調用wait()。
當線程想喚醒等待在某個條件變量上的睡眠線程時,調用signal()。
pthread_cond_wait(pthread_cond_t* c, pthread_mutex_t* m);
pthread_cond_signal(pthread_cond_t* c);wait()調用有一個參數,它是互斥量。
它假定在wait()調用時,這個互斥量是已上鎖狀態。
wait()的職責是釋放鎖,并讓調用線程休眠(原子地)。
當線程被喚醒時(在另外某個線程發信號給它后),它必須重新獲取鎖,再返回調用者。
這樣復雜的步驟也是為了避免在線程陷入休眠時,產生一些競態條件。父線程等待子線程:使用條件變量
Pthread_cond_wait(pthread_cond_t* c, pthread_mutex_t* m);
Pthread_cond_signal(pthread_cond_t* c);int done = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c = PTHREAD_COND_INITIALIZER;void thread_exit() {Pthread_mutex_lock(&m);done = 1;Pthread_cond_signal(&c);Pthread_mutex_unlock(&m);
}void thread_join() {Pthread_mutex_lock(&m);while (done == 0) {Pthread_cond_wait(&c, &m);}// 你可能看到父線程使用了一個while循環,而不是if語句來判斷是否需要等待。// 雖然從邏輯上來說沒有必要使用循環語句,但這樣做總是好的Pthread_mutex_unlock(&m);
}void* child(void* arg) {printf("child\n");thread_exit();return NULL;
}int main(int argc, char* argv[]) {printf("parent:begin\n");pthread_t p;Pthread_create(&p, NULL, child, NULL);thread_join();printf("parent:end\n");return 0;
}
盡管并不是所有情況下都嚴格需要,但有效且簡單的做法,還是在使用條件變量調用signal和wait時要持有鎖(hold the lock when calling signal or wait)
生產者/消費者 (有界緩沖區問題)
假設有一個或多個生產者線程和一個或多個消費者線程。生產者把生成的數據項放入緩沖區;消費者從緩沖區取走數據項,以某種方式消費。
int buffer[MAXN];
int fill_ptr = 0;
int use_ptr = 0;
int count = 0;void put(int value) {buffer[fill_ptr] = value;fill_ptr = (fill_ptr + 1) % MAXN;count++;
}int get() {int tmp = buffer[use_ptr];use_ptr = (use_ptr + 1) % MAXN;count--;return tmp;
}cond_t empty, fill;
mutex_t mutex;void* producer(void* arg) {for (int i = 0; i < loops; i++) {Pthread_mutex_lock(&mutex);while (count == MAXN) { // 如果隊列滿了,那就不生產了,進行睡眠等待// 等待到隊列空了Pthread_cond_wait(&empty, &mutex);}// 當隊列還可以進行放入值的時候put(i);// 喚醒消費者Pthread_cond_signal(&fill);Pthread_mutex_unlock(&mutex);}
}void* consumer(void* arg) {for (int i = 0; i < loops; i++) {Pthread_mutex_lock(&mutex);while (count == 0) { // 如果隊列空了,那就不消費了,進行睡眠等待// 等待到隊列不為空Pthread_cond_wait(&fill, &mutex);}// 當隊列還可以進行放入值的時候int tmp = get();// 喚醒生產者者Pthread_cond_signal(&empty);Pthread_mutex_unlock(&mutex);printf("%d\n", tmp);}
}
要記住一條關于條件變量的簡單規則:總是使用while循環(always use while loop)。雖然有時候不需要重新檢查條件,但這樣做總是安全的,做了就開心了。
消費者不應該喚醒消費者,而應該只喚醒生產者,反之亦然。使用兩個條件變量,而不是一個,以便正確地發出信號,在系統狀態改變時,哪類線程應該喚醒。
覆蓋條件
一個簡單的多線程內存分配庫:
// free heap nums
int byteLeft = MAX_HEAP_SIZE;cond_t c;
mutex_t m;void* allocate(int size) {Pthread_mutex_lock(&m);while (byteLeft < size) { // 如果剩余的內存小于申請的內存,線程進入休眠Pthread_cond_wait(&c, &m);}// 等待線程有足夠內存了void* ptr = ...; // get mem from heapbytesLeft -= size;Pthread_mutex_unlock(&m);return ptr;
}void free(void* ptr, int size) {Pthread_mutex_lock(&m);bytesLeft += size;// 釋放出內存了,喚醒休眠的allocate線程:應該喚醒哪個等待線程(可能有多個線程)?Pthread_cond_signal(&c); Pthread_mutex_unlock(&m);
}應該喚醒哪個等待線程(可能有多個線程)?可能喚醒了一個線程后檢查條件發現不滿足喚醒,從而導致符合條件的沒有被喚醒。
解決方法:
用pthread_cond_broadcast()代替上述代碼中的pthread_cond_signal(),喚醒所有的等待線程。這樣做,確保了所有應該喚醒的線程都被喚醒。當然,不利的一面是可能會影響性能,因為不必要地喚醒了其他許多等待的線程,它們本來(還)不應該被喚醒。這些線程被喚醒后,重新檢查條件,馬上再次睡眠。
這種條件變量叫作覆蓋條件(covering condition),因為它能覆蓋所有需要喚醒線程的場景(保守策略)
擴展
關于c++中的條件變量使用之前有寫過相關筆記:
https://hanhandi.blog.csdn.net/article/details/120914038
3、信號量
使用
#include <semaphore.h>
sem_t s;
sem_init(&s, 0, 1);
// param2:0:信號量在同進程的多線程中共享
// param3:信號量的值
int sem_wait(sem_t* s) {// s--;s>=0 -> 立即返回s<0 線程掛起,直到之后的post操作
}int sem_post(sem_t* s) {// s++;直接增加信號量的值,如果有等待的線程,喚醒其中一個。
}
// 當信號量 < 0 時,s的val就是等待線程的個數。
二值信號量(鎖)
信號量的第一種用法:作為鎖來使用
直接把臨界區用一對sem_wait() / sem_post()包括起來。
sem_t m;
sem_init(&m, 0, 1); // 初始化值為1sem_wait(&m);
// 臨界區代碼
sem_post(&m);
0值信號量(條件變量)
信號量的第一種用法:作為條件變量來使用
父線程wait等待子線程
子線程done后調用post進行signal
sem_t* s;
void* child(void* arg) {printf("child\n");sem_post(&s); // signal : child donereturn NULL;
}int main() {sem_init(&s, 0, 0); // 初始化值為0printf("parent:begin\n");pthread_t p;Pthread_create(p, NULL, child, NULL);sem_wait(&s); // wait : wait for child doneprintf("parent:end\n");return 0;
}
生產者消費者問題
綜合使用條件變量和
nt buffer[MAXN];
int fill_ptr = 0;
int use_ptr = 0;
int count = 0;void put(int value) {buffer[fill_ptr] = value;fill_ptr = (fill_ptr + 1) % MAXN;count++;
}int get() {int tmp = buffer[use_ptr];use_ptr = (use_ptr + 1) % MAXN;count--;return tmp;
}sem_t empty;
sem_t full;
sem_t mutex;void* producer(void* arg) {for (int i = 0; i < loops; i++) {sem_wait(&empty); // 等到空的時候進行生產sem_wait(&mutex); // 為了保證生產者互斥插入,需要加鎖put(i);sem_post(&mutex); // 解鎖sem_post(&full); // 生產好了,提醒消費者進行消費}
}void* consumer(void* arg) {for (int i = 0; i < loops; i++) {sem_wait(&full); // 等到生產好了進行消費sem_wait(&mutex); // 為了保證消費者互斥插入,需要加鎖put(i);sem_post(&mutex); // 解鎖sem_post(&empty); // 消費好了,提醒生產者進行生產}
}注意這里和https://www.wolai.com/dNjJbFaR3fYqd6CXP27HAe中對于條件變量和鎖的使用順序不同
舉例:
假設有兩個線程,一個生產者和一個消費者。消費者首先運行,獲得鎖,然后對full信號量執行sem_wait() 。因為還沒有數據,所以消費者阻塞,讓出CPU。但是,重要的是,此時消費者仍然持有鎖。然后生產者運行。假如生產者能夠運行,它就能生產數據并喚醒消費者線程。遺憾的是,它首先對二值互斥信號量調用sem_wait()(。鎖已經被持有,因此生產者也被卡住。
在這里出現了死鎖,因為sem_wait在讓出CPU時并沒有釋放鎖,而在https://www.wolai.com/dNjJbFaR3fYqd6CXP27HAe中,我們使用的Pthread_cond_wait(&empty, &mutex);會對鎖進行釋放,從而避免死鎖。這兩個API的區別注意一下。
所以我們把獲取和釋放互斥量的操作調整為緊挨著臨界區,把full、empty的喚醒和等待操作調整到鎖外面。結果得到了簡單而有效的有界緩沖區。
讀寫鎖
訪問同一個數據結構可能需要不同類型的鎖。讀寫鎖就是一種。
下面是不公平的讀寫鎖:寫鎖只能在最后讀者釋放之后才能被寫者獲取。
rwlock_acquire_writelock() 獲得寫鎖
rwlock_release_writelock() 釋放寫鎖typedef struct _rwlock_t {sem_t lock; // 二值信號量作為basic locksem_t writelock; // 用于一個寫者 or 多個讀者int readers; // 在臨界區讀取的讀者數
} rwlock_t;void rwlock_init(rwlock_t* rw) {rw->readers = 0;sem_init(&rw->lock, 0, 1);sem_init(&rw->writelock, 0, 1);
} void rwlock_acquire_readlock(rwlock_t* rw) {sem_wait(&rw->lock);rw->readers++;if (rw->readers == 1) {sem_wait(&rw->writelock); // 第一個讀者需要持有寫鎖}sem_post(&rw->lock);
}void rwlock_release_readlock(rwlock_t* rw) {sem_wait(&rw->lock);rw->readers--;if (rw->readers == 0) {sem_post(&rw->writelock); // 最后一個讀者釋放寫鎖}sem_post(&rw->lock);
}void rwlock_acquire_writelock(rwlock_t* rw) {sem_wait(&rw->writelock);
}void rwlock_release_writelock(rwlock_t* rw) {sem_post(&rw->writelock);
}一旦一個讀者獲得了讀鎖,其他的讀者也可以獲取這個讀鎖。
但是,想要獲取寫鎖的線程,就必須等到所有的讀者都結束。
最后一個退出的寫者在“writelock”信號量上調用sem_post(),從而讓等待的寫者能夠獲取該鎖。
讀者很容易餓死寫者,我們應該思考有寫者等待時,如何能夠避免更多的讀者進入并持有鎖。
這里TODO一下,以后看到有好的代碼寫過來。
哲學家就餐問題
假定有5位“哲學家”圍著一個圓桌。每兩位哲學家之間有一把餐叉(一共5把)。哲學家有時要思考一會,不需要餐叉;有時又要就餐。而一位哲學家只有同時拿到了左手邊和右手邊的兩把餐叉,才能吃到東西。
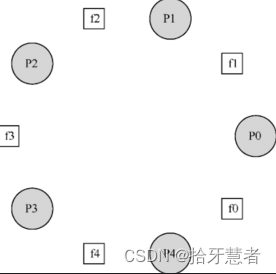
每個哲學家(線程)的自我循環:
while (1) {think();getforks();eat();putforks();
}
關鍵的挑戰就是如何實現getforks()和putforks()函數,保證沒有死鎖,沒有哲學家餓死,并且并發度更高。
輔助函數:
int left(int p) { // 使用左邊的叉子return p;
}
int right(int p) { // 使用右邊的叉子return (p + 1) % 5;
}
每個叉子作為一個信號量:
sem_t forks[5];
void getforks() {sem_wait(forks[left(p)]);sem_wait(forks[right(p)]);
}
依次獲取每把餐叉的鎖——先是左手邊的,然后是右手邊的。結束就餐時,釋放掉鎖。假設每個哲學家都拿到了左手邊的餐叉,他們每個都會阻塞住,并且一直等待另一個餐叉。
解決上述問題最簡單的方法,就是修改某個或者某些哲學家的取餐叉順序。
假定哲學家4(編寫最大的一個)取餐叉的順序不同。
void getforks() {if (p == 4) {sem_wait(forks[right(p)]);sem_wait(forks[left(p)]);} else {sem_wait(forks[left(p)]);sem_wait(forks[right(p)]);}
}
因為最后一個哲學家會嘗試先拿右手邊的餐叉,然后拿左手邊,所以不會出現每個哲學家都拿著一個餐叉,卡住等待另一個的情況,等待循環被打破了。
使用鎖+條件變量實現信號量
信號量可以作為鎖和條件變量來使用。而我們用底層的同步原語(鎖和條件變量),也可以來實現自己的信號量,名字叫作Zemaphore。
typedef struct _Zem_t {int value;pthread_cond_t cond;pthread_mutex_t lock;
} Zem_t;// only one thread can call it
void Zem_init(Zem_t* s, int value) {s->value = value;
}void Zem_wait(Zem_t* s) {Pthread_mutex_lock(&s->lock);while (s->value <= 0) { // 當小于0 阻塞 并在睡眠前將鎖釋放,這樣下面的unlock就不會出錯Pthread_cond_wait(&s->cond, &s->lock);}s->value--;Pthread_mutex_unlock(&s->lock);
}void Zem_post(Zem_t* s) {Pthread_mutex_lock(&s->lock);s->value++;Pthread_cond_signal(&s->cond);Pthread_mutex_unlock(&s->lock);
}擴展
關于信號量的之前也有部分筆記:
https://hanhandi.blog.csdn.net/article/details/123576424
4、并發問題總結
1、非死鎖問題
- 違反原子性:加鎖解決
- 錯誤順序:通過強制順序方法,利用條件變量
這里針對第二點做一下闡述:
錯誤代碼:
thread1:
void init() {...mThread = createThread(mMain, ...);...
}thread2:
void mMain(...) {...mState = mThread->State;...
}
如果線程1并沒有首先執行,線程2就可能因為引用空指針奔潰.
修改后的代碼:
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;
int mtInit = 0;thread1:
void init() {...mThread = createThread(mMain, ...);// signal threadpthread_mutex_lock(&mtLock);mtInit = 1;pthread_cond_signal(&mtCond);pthread_mutex_unlock(&mtLock);...
}thread2:
void mMain(...) {...// wait for thread to be initializedpthread_mutex_lock(&mtLock);while (mtInit == 0) {pthread_cond_wait(&mtLock);}pthread_mutex_unlock(&mtLock);mState = mThread->State;...
}
我們增加了一個鎖(mtLock)、一個條件變量(mtCond)以及狀態的變量(mtInit)
請注意,我們可以用mThread本身作為狀態變量,但為了簡潔,我們沒有這樣做。當線程之間的順序很重要時,條件變量(或信號量)能夠解決問題。
2、死鎖問題

當線程1占有鎖L1,上下文切換到線程2。線程2鎖住L2,試圖鎖住L1。這時才產生了死鎖,兩個線程互相等待。
死鎖產生的條件:
● 互斥:線程對于需要的資源進行互斥的訪問(例如一個線程搶到鎖)。
● 持有并等待:線程持有了資源(例如已將持有的鎖),同時又在等待其他資源(例如,需要獲得的鎖)。
● 非搶占:線程獲得的資源(例如鎖),不能被搶占。
● 循環等待:線程之間存在一個環路,環路上每個線程都額外持有一個資源,而這個資源又是下一個線程要申請的。
解決方案:
1、預防循環等待
通過預防,獲取鎖的時候提供全序。若有兩個鎖,每次都先申請L1再申請L2,可以避免死鎖。
也可以采用偏序來安排鎖的獲取,人為定義某些不同的加鎖順序。
也可以根據鎖的地址作為獲取鎖的順序。按照地址從高到低,或者從低到高的順序加鎖。
void do_something(mutex_t* m1, mutex_t* m2) {if (m1 > m2) {pthread_mutex_lock(m1); pthread_mutex_lock(m2); } else {pthread_mutex_lock(m2); pthread_mutex_lock(m1); }
}
// assume m1 != m2
2、使用非搶占鎖
unlock之前默認鎖被占有,釋放后會引起多個搶鎖操作,可以使用trylock來嘗試獲得鎖,或者返回-1,表示鎖已經被占用。這樣就不會出現死鎖等待了。
thread1:
...
label:
lock(L1);
if (trylock(L2) == -1) { // 如果創建鎖失敗 unlock(L1);goto label;
}
...thread2:
...
label:
lock(L2);
if (trylock(L1) == -1) { // 如果創建鎖失敗 unlock(L2);goto label;
}
...這樣也會帶來活鎖問題,兩個線程可能一直重復這段代碼,但是這個不是死鎖。
解決方法:可以在循環結束的時候,先隨機等待一個時間,然后再重復整個動作,這樣可以降低線程之間的重復互相干擾。
3、完全避免互斥,使用CAS
通過硬件指令,構造出不需要鎖的數據結構。
下面是一個常用的指令:CAS(compare and swap)比較并交換,是硬件提供的原子指令。
int CompareAndSwap(int* address, int expected, int new) {if (*address == expected) { // 如果舊值和理想值一樣*address = new; // 更新舊值return 1; // success} else {return 0; // failure}
}
如果我們想原子地增加一個數,可以這樣寫:
void AtomicIncrement(int* value, int amount) {do {int old = *value;} while (CompareAndSwap(value, old, old + amount) == 0); // 如果更新失敗,繼續嘗試
}
// 使用鎖
void LockIncrement(mutex_t* lock, int* value, int amount) {Pthread_mutex_lock(lock);int new = *value + amount;*value = new;Pthread_mutex_unlock(lock);
}這樣避免了加鎖、解鎖,而是使用CAS指令,反復嘗試將值更新到最新的值。這樣也就避免了死鎖。
關于CAS的詳細理解見文章:
https://www.wolai.com/9aopYQvrCHJ8i8MWJhjMCa
在之前的筆記中,有談到并發鏈表,當時并發頭插法的核心代碼如下:
void insert(list_t *list, int key)
{node_t* p = malloc(sizeof(node_t)); if (p == NULL) {perror("malloc");return -1;} p->key = key;// 假定malloc()是線程安全的,每個線程都可以調用它,不需要擔心競爭條件和其他并發缺陷。// 只有在更新共享列表時需要持有鎖Pthread_mutex_lock(&list->lock);p->next = list->head; // 頭插法list->head = p;Pthread_mutex_unlock(&list->lock);return 0;
}這里我們試著使用CAS
void insert(list_t *list, int key)
{node_t* p = malloc(sizeof(node_t)); if (p == NULL) {perror("malloc");return -1;} p->key = key;do {p->next = list->head; // old = address} while (CompareAndSwap(&list->head, p->next, p) == 0); // address old newreturn 0;
}
4、調度避免死鎖
2核4線程,有兩把鎖L1 L2,不同線程對于鎖的需求程度。yes表示要用到,no表示用不到

只要T1和T2不同時運行就不會產生死鎖。

5、檢測死鎖并恢復
很多數據庫系統使用了死鎖檢測和恢復技術。死鎖檢測器會定期運行,通過構建資源圖來檢查循環。這里可以參考一下之前的筆記的最后一部分關于死鎖檢測的部分,本質上就是有向圖判斷環。
5、事件并發
在之前的兩個文章:
https://hanhandi.blog.csdn.net/article/details/120998962
https://hanhandi.blog.csdn.net/article/details/121052560
我們使用了基于事件的服務器,他們都是基于事件循環的簡單結構:
while (1) {events = getEvents();for (e in events) {processEvent(e);}
}
這也屬于并發的一種,基本方法就是基于事件的并發。我們等待某事(即“事件”)發生;當它發生時,檢查事件類型,然后做少量的相應工作(可能是I/O請求,或者調度其他事件準備后續處理)。
主循環等待事件發生,然后一次處理這些發生的事件。
具體處理事件交由事件處理程序(event handler)處理。
當event handler處理一個事件時,它是CPU中執行的唯一進程。
這樣就可以進行顯式調度了。
不過這也帶來了下面的思考:
基于事件的服務器如何決定哪個事件發生,尤其是對于網絡和磁盤的IO。
也就是說服務器如何確定是否有消息到達,這里主要牽扯到select 和epoll兩個機制。
基于事件的服務器不能被另一個線程中斷,因為它確實是單線程的。因此,線程化程序中常見的并發性錯誤并沒有出現在基本的基于事件的方法中。這就要求我們的服務器不能阻塞調用。
時間并發與線程并發的區別
使用基于線程的服務器時,在發出I/O請求的線程掛起(等待I/O完成)時,其他線程可以運行,從而使服務器能夠取得進展。
使用基于事件的方法時,沒有其他線程可以運行:只是主事件循環。這意味著如果一個事件處理程序發出一個阻塞的調用,整個服務器就會這樣做:阻塞直到調用完成。當事件循環阻塞時,系統處于閑置狀態。
對于基于事件并發、基于線程并發我有些疑惑,記錄于此:
https://www.wolai.com/3irCkAHj3DzWFdLs6j8kCo
關于線程并發與事件并發還可以參考一下:
http://www.imxmx.com/Item/1/117655.html
在事件并發服務器中,為了克服阻塞調用限制,我們使用非阻塞IO
非阻塞IO我們又稱異步IO,最起碼需要有下面幾個接口支持:
1、有接口使得應用程序能夠發出IO請求,并在IO完成前立即將控制權返回給調用者。
2、有接口使得應用程序能夠確定IO是否完成
它基于AIO控制塊實現。
struct aiocb {int aio_fildes; // 文件描述符off_t aio_offset; //文件內偏移量volatile void *aio_buf; // 復制讀取結果的目標內存位置size_t aio_nbytes; // 請求的長度
};
要向文件發出異步的read,應用程序應該先填充aiocb,之后發出異步調用讀取文件
int aio_read(struct aiocb *aiocbp) {...};
該函數嘗試發起IO,成功的話立即返回,事件服務器也可以繼續其工作。
不成功也會立即返回,事件服務器得做好相關處理。
那么我們改如何獲知IO何時完成呢?一般有兩種思路:1、周期輪詢2、系統中斷告知
對于第一種,需要用到api:
int aio_error(const struct aiocb *aiocbp);
若已完成,接口返回0;
否則,返回EINPROGRESS。
對于第二種,使用UNIX信號異步IO完成時通知,消除了重復詢問系統的需要。
信號和嵌入式中的中斷差不多,將信號傳遞給應用程序。這樣做會讓應用程序停止當前的任何工作,開始運行信號處理程序(signal handler)。完成后,該進程就恢復其先前的行為。
#include <stdio.h>
#include <signal.h>void handle(int arg) {printf("xxxx\n");
}int main(int argc, char *argv[]) {signal(SIGHUP, handle);while (1) ; // do nothing except catch some signal
}
在沒有異步I/O的系統中,純基于事件的方法無法實現。
狀態管理問題
當事件處理程序發出異步I/O時,它必須打包一些程序狀態,以便下一個事件處理程序在I/O最終完成時使用。這個額外的工作在基于線程的程序中是不需要的,因為程序需要的狀態在線程棧中。
在線程服務器中:當read()最終返回時,代碼立即知道要寫入哪個套接字,因為該信息位于線程堆棧中(在變量sd中)
int rc = read(fd, buffer, size);
rc = write(sd, buffer, size);
在基于事件的系統中,為了執行相同的任務,我們需要自己存儲并管理。
我們首先使用上面描述的AIO調用異步地發出讀取。
然后將套接字描述符sd記錄在由文件描述符fd作為索引的散列表中,當磁盤IO完成時,事件處理程序將用fd來查找sd,將sd返回給對應的調用者。
缺點
1、當系統從單個CPU轉向多個CPU時,為了利用多個CPU,事件服務器必須并行運行多個事件處理程序。就會出現常見的同步問題(例如臨界區),并且必須采用通常的解決方案(例如鎖定)
2、如果事件處理程序發生頁錯誤,它將被阻塞,并且因此服務器在頁錯誤完成之前不會有進展。盡管服務器的結構可以避免顯式阻塞,但由于頁錯誤導致的這種隱式阻塞很難避免,因此在頻繁發生時可能會導致較大的性能問題。
3、隨著時間的推移,基于事件的代碼可能很難管理。如果函數從非阻塞變為阻塞,調用該例程的事件處理程序也必須更改以適應其新性質。













)
)

)


