Detecting Twenty-thousand Classes using Image-level Supervision
- 摘要
- 背景方法
- Preliminaries
- Detic:具有圖像類別的檢測器
- loss
- 技術細節擴展
- Grad-CAM
- Grad-CAM原理
- 總結
摘要

摘要 由于檢測數據集的規模較小,目前的物體檢測器在詞匯量方面受到限制。而圖像分類器的數據集更大,也更容易收集,因此它們的詞匯量要大得多。我們提出的 Detic 只需在圖像分類數據上訓練檢測器的分類器,從而將檢測器的詞匯量擴展到數以萬計的概念。與之前的工作不同,Detic 不需要復雜的分配方案,就能根據模型預測將圖像標簽分配給方框,因此更容易實現,并與一系列檢測架構和骨干兼容。我們的研究結果表明,即使對于沒有方框注釋的類別,Detic 也能生成出色的檢測器。它在開放詞匯和長尾檢測基準上的表現都優于之前的工作。在開放詞匯 LVIS 基準上,Detic 為所有類別帶來了 2.4 mAP 的增益,為新類別帶來了 8.3 mAP 的增益。在標準 LVIS 基準上,如果對所有類別或僅對稀有類別進行評估,Detic 可獲得 41.7 mAP,從而縮小了樣本較少的對象類別的性能差距。我們首次使用 ImageNet 數據集的全部 21000 個類別來訓練檢測器,并證明它無需微調即可泛化到新的數據集。代碼見 https://github.com/facebookresearch/Detic 。
現階段的目標檢測器的性能已經到了一個瓶頸。
- 作者認為限制其性能進一步提升的主要原因是其可獲得的訓練數據量規模太小。
- 另一方面,圖像分類的數據量就相對來說大得多同時更加容易收集,也因此圖像分類可以在更大規模的詞匯表上進行推理。
作者基于此,提出了自己命名為Detic的目標檢測訓練方法,其可以非常簡單的使用圖像分類的數據集來對目標檢測器的分類頭進行訓練。簡單,是Detic的最大賣點,之前的類似弱監督的工作都是基于預測然后進行box-class的分配,實現起來十分繁瑣且兼容性很差,只能在特定的檢測器結構上進行訓練,Detic則可易于實現,在大部分的檢測建構和backbone上都可以接入使用。
背景方法

物體檢測包括兩個子問題:尋找物體(定位)和命名物體(分類)。傳統方法將這兩個子問題緊密結合在一起,因此依賴于所有類別的盒式標簽。盡管做了很多數據收集工作,但檢測數據集 [18 , 28 , 34 , 49] 的總體規模和詞匯量都遠遠小于分類數據集 [10]。例如,最近的 LVIS 檢測數據集 [18] 有 1000 多個類別,12 萬張圖像;OpenImages [28] 有 500 個類別,180 萬張圖像。此外,并非所有類別都包含足夠的注釋來訓練強大的檢測器(見圖 1 頂部)。在分類方面,即使是已有十年歷史的 ImageNet [10] 也有 21K 個類別和 1400 萬張圖片(圖 1 底部)。
現階段目標檢測的標注數據量相對于圖像分類來說少得太多,LVIS 120K的圖片,包含了1000+類,OpenImages 1.8M的圖片,包含了500+類,而10年前的古董級圖像分類數據集ImageNet就有21K個類別、14M的圖片數目。在有限的類別上訓練出來的目標檢測器,總是會出現差錯。而Detic使用了圖像分類的數據,能夠檢測出得類別就更加多樣、更加精確。如下圖所示,一個普通的LVIS檢測器將獅子檢測成了熊,將狐貍檢測成了水獺,而Detic則檢測正確。
傳統的目標檢測將分類和定位耦合在一起,對訓練的數據集有較高的要求,數據集需要包括物體的種類,以及bbox位置信息,這就導致了要檢測多少類就需要多少類的數據標注。
而detic將分類與定位解耦成兩個問題,在定位時不再那么依賴標注數據。

在本文中,我們提出了帶圖像類別的檢測器(Detic),它除了檢測監督外,還使用圖像級監督。我們發現,定位和分類子問題可以解耦

因此,我們將重點放在分類子問題上,使用圖像級標簽來訓練分類器并擴大檢測器的詞匯量。我們提出了一種簡單的分類損失,將圖像級監督應用于規模最大的提案,而不對其他有圖像標簽的數據輸出進行監督。這種方法易于實現,并能大量擴展詞匯量。
對于采用第二種數據如何定位,文中沒有細說(文中的重點是分類),但是提到了用的是弱監督學習的思想,目前在弱監督學習的定位中采用最多的方法是 Gard-Cam(detic可能不是用的這個,但是感覺應該是一樣的思想)。Gard-cam起初是用來可視化CNN任務的,稍作修改即可用來定位。

我們發現問題,并提出一個更簡單的替代現有的弱監督檢測技術在開放詞匯設置。
我們提出的損失族顯著提高了新類別的檢測性能,與監督性能上限非常匹配。
我們的檢測器無需微調即可轉換到新的數據集和詞匯
- 作者找到現階段目標檢測弱監督訓練出現的問題,并使用了更簡單易用的替換方案。
- 作者為了使用圖像級別的監督信號,提出了一個新的損失函數,實驗表明,這個損失函數可以非常有效地提升目標檢測器的性能,尤其是在novel class的檢測中。
- 作者訓練出來的目標檢測器可以無需微調,直接遷移到新的數據集和檢測詞匯表上。
Preliminaries

我們使用對象檢測和圖像分類數據集來訓練對象檢測器。我們提出了一種簡單的方法來利用圖像監督來學習對象檢測器,包括沒有盒子標簽的類。我們首先描述目標檢測問題,然后詳細說明我們的方法

問題設置。給定一幅圖像,目標檢測解決兩個子問題:( 1)定位:找到所有目標及其位置,表示為一個盒子 😭 2)分類:給第j個目標分配一個類別標簽cj 。這里C test是用戶在測試時提供的類詞匯。
在訓練期間,我們使用檢測數據集,詞匯C det既有類標簽又有box標簽。我們還使用圖像分類數據集,詞匯表C cls只有圖像級類標簽。詞匯C test、C det、C cls可能重疊,也可能不重疊。

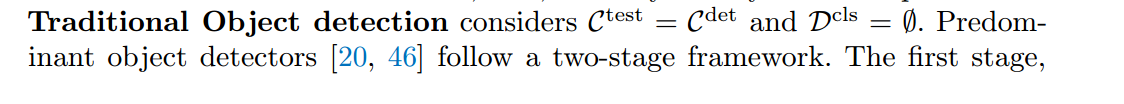

傳統的對象檢測認為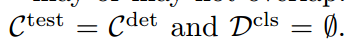 ,主要的目標檢測器遵循兩階段框架。
,主要的目標檢測器遵循兩階段框架。
第一階段,稱為區域建議網絡(RPN),取圖像I并生成一組對象建議: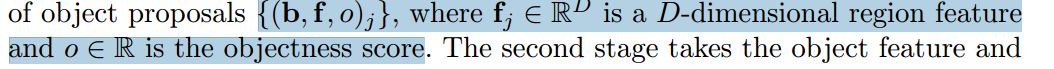
第二階,段取對象特征,輸出每個對象的分類評分和細化后的盒子位置。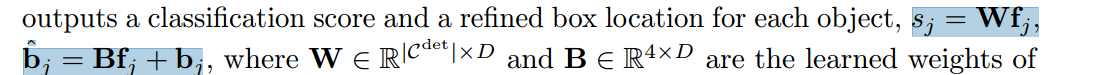
w,b分別是分類層和回歸層的學習權重。

我們的工作重點是在第二階段提高分類。在我們的實驗中,RPN和邊界框回歸器并不是當前的性能瓶頸,因為現代探測器在測試中使用了過多的建議數量(每張圖像< 20個對象使用1K個建議)。
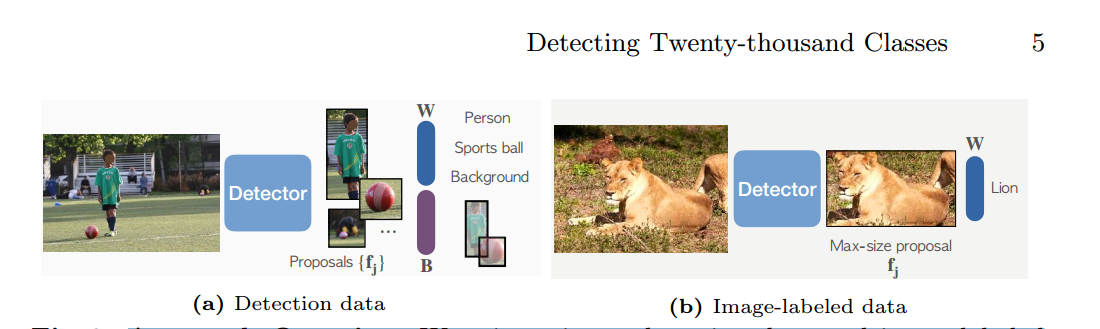

方法概述。我們在檢測數據和圖像標記數據上混合訓練。當使用檢測數據時,我們的模型使用標準檢測損失來訓練檢測器的分類器(W)和盒預測分支(B)。當使用圖像標記的數據時,我們僅使用我們修改的分類損失來訓練分類器。
我們的損失訓練從最大尺寸的提議中提取的特征。
Detic的數據集分為兩類,一種是傳統目標檢測數據集,一種是label-image數據(可以類比為圖像分類的數據,沒有bbox信息)。
對于第一種數據來說,訓練時就按照傳統目標檢測的流程進行,得到分類權重
以及bbox預測分支
,對于第二種數據來說,我們只訓練來自固定區域的特征進行分類。使用這兩種數據可以訓練種類更多的分類器(跟傳統的目標檢測相比降低了數據獲取的成本)。
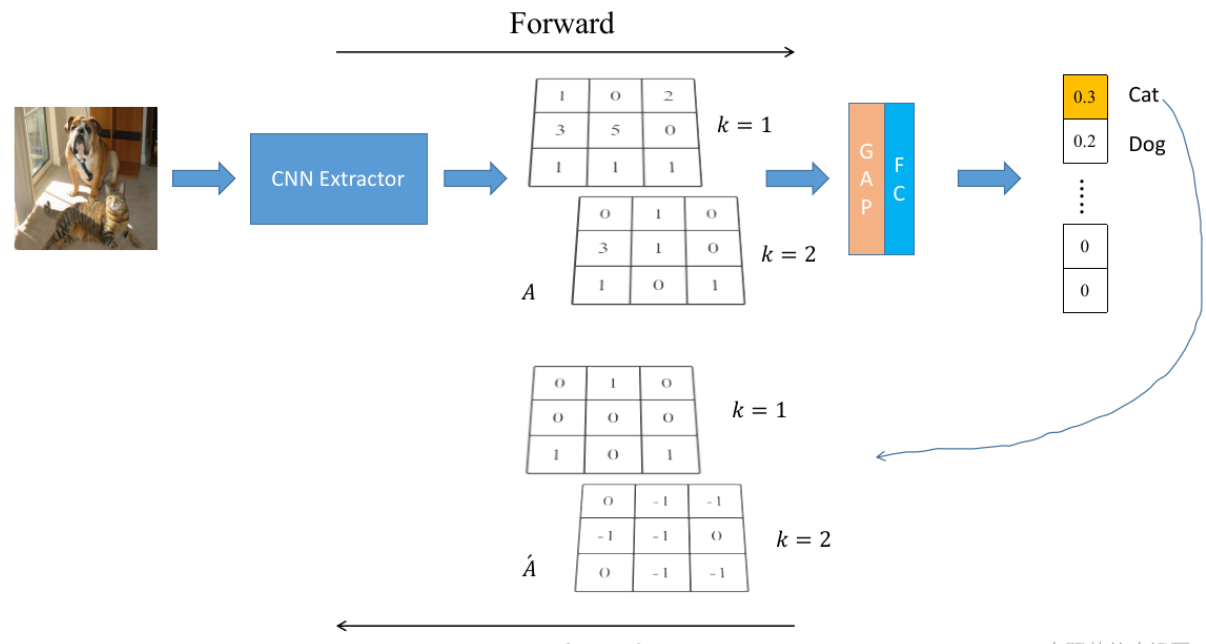
Detic:具有圖像類別的檢測器

如圖3所示,我們的方法利用了來自檢測數據集Ddet的盒子標簽和來自分類數據集Dcls的圖像級標簽。在訓練期間,我們使用來自兩種類型的數據集的圖像組成一個小批量。對于帶有方框標簽的圖像,我們遵循標準的兩階段檢測器訓練[46]。對于圖像級標記圖像,我們只訓練來自固定區域的特征進行分類。因此,我們只計算具有GT標簽的圖像的定位損失(RPN損失和邊界盒回歸損失)。下面,我們描述我們改進的圖像級標簽的分類損失。

如上圖所示,一個普通的LVIS檢測器將獅子檢測成了熊,將狐貍檢測成了水獺,而Detic則檢測正確。
loss
弱監督目標檢測
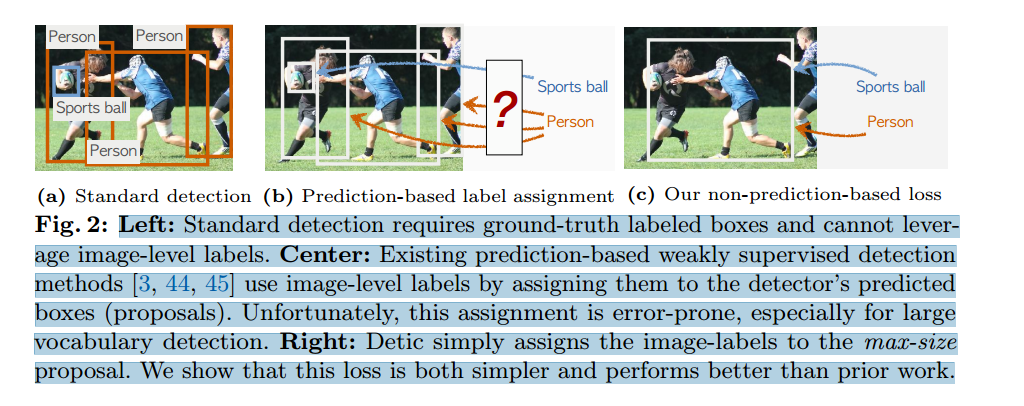
左圖:標準檢測需要地面實況標簽盒,無法利用圖像級標簽。
中間: 現有的基于預測的弱監督檢測方法[3, 44, 45]通過將圖像級標簽分配給檢測器的預測框(建議)來使用圖像級標簽。遺憾的是,這種分配容易出錯,尤其是在大詞匯量檢測中。
右圖 Detic 只需將圖像標簽分配給最大尺寸的提議。我們的研究表明,這種損失比之前的工作更簡單,性能也更好。


其中 f 代表proposal對應的RoI feature,c是最大的proposal對應的類別,也就是是該圖片對應的類別,W是分類器的權重。同時,再加上傳統目標檢測器里使用的loss,就組成了Detic的最終loss。
參考文獻1
參考文獻2
技術細節擴展
關于使用分類數據集訓練網絡模型,完成定位,文中沒有細說(文中的重點是分類),但是提到了用的是弱監督學習的思想,目前在弱監督學習的定位中采用最多的方法是gard-cam(detic可能不是用的這個,但是感覺應該是一樣的思想)…
Grad-CAM
論文名稱:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
論文下載地址:https://arxiv.org/abs/1610.02391
推薦代碼(Pytorch):https://github.com/jacobgil/pytorch-grad-cam
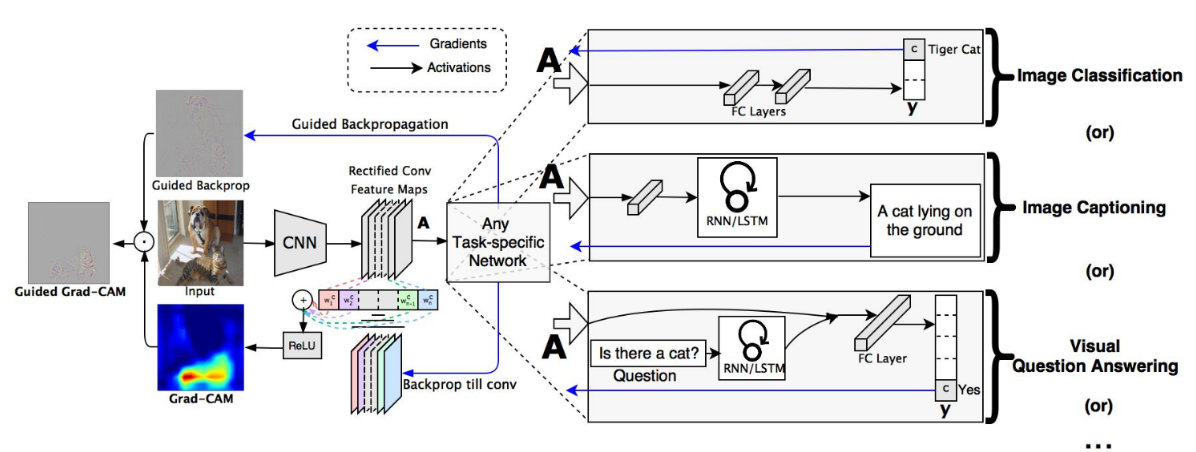
對于常用的深度學習網絡(例如CNN),普遍認為是個黑盒可解釋性并不強(至少現在是這么認為的),它為什么會這么預測,它關注的點在哪里,我們并不知道。很多科研人員想方設法地去探究其內在的聯系,也有很多相關的論文。通過Grad-CAM我們能夠繪制出如下的熱力圖(對應給定類別,網絡到底關注哪些區域)。Grad-CAM(Gradient-weighted Class Activation Mapping)是CAM(Class Activation Mapping)的升級版(論文3.1節中給出了詳細的證明),Grad-CAM相比與CAM更具一般性。CAM比較致命的問題是需要修改網絡結構并且重新訓練,而Grad-CAM完美避開了這些問題。本文不對CAM進行講解,有興趣的小伙伴自行了解。
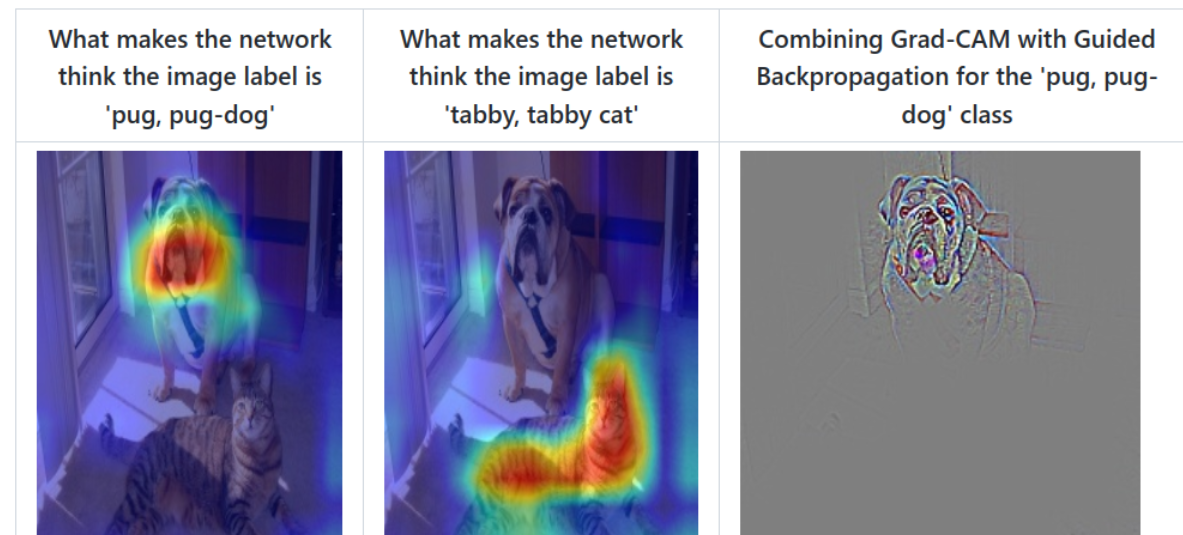
我們通過網絡關注的區域能夠反過來分析網絡是否學習到正確的特征或者信息。在論文6.3章節中舉了個非常有意思的例子,作者訓練了一個二分類網絡,Nurse和Doctor。如下圖所示,第一列是預測時輸入的原圖,第二列是Biased model(具有偏見的模型)通過Grad-CAM繪制的熱力圖。第三列是Unbiased model(不具偏見的模型)通過Grad-CAM繪制的熱力圖。通過對比發現,Biased model對于Nurse(護士)這個類別關注的是人的性別,可能模型認為Nurse都是女性,很明顯這是帶有偏見的。比如第二行第二列這個圖,明明是個女Doctor(醫生),但Biased model卻認為她是Nurse(因為模型關注到這是個女性)。而Unbiased model關注的是Nurse和Doctor使用的工作器具以及服裝,明顯這更合理。

Grad-CAM原理



參考文獻3
參考文獻4
總結
Unfortunately, this assignment requires good initial detections which leads to a chicken-and-egg problem–we need a good detector for good label assignment, but we need many boxes to train a good detector. Our method completely side steps the label assignment process by supervising the classification sub-problem alone when using classification data.
不幸的是,這種分配需要良好的初始檢測,這會導致先有雞還是先有蛋的問題——我們需要一個好的檢測器來實現良好的標簽分配,但我們需要很多盒子來訓練一個好的檢測器。 我們的方法通過在使用分類數據時單獨監督分類子問題來完全回避標簽分配過程
這里說的是弱監督檢測器:對于完全的弱監督學習來說,定位依賴于檢測結果
Detic解決的問題:對于傳統目標檢測任務,數據標注比較麻煩;對于完全的弱監督學習來說,定位依賴于檢測結果。
所以detic采取了一個中合的辦法










)
)




、國測局坐標(火星坐標,GCJ02)、和WGS84坐標系之間的轉換)
(單片機--單片機通信)示例代碼 附proteus圖)

