Python部落(python.freelycode.com)組織翻譯,禁止轉載,歡迎轉發。
作者:Omer Lachish
最近,我們已經開始使用RQ庫代替Celery庫作為我們的任務運行引擎。第一階段,我們只遷移了那些不直接進行查詢工作的任務。這些任務包括發送電子郵件,確定哪些查詢需要刷新、記錄用戶事件和其他維護工作。
在部署完成之后我們注意到,任務數量相同的情況下,與Celery庫相比,RQ庫需要更多的CPU去執行這些任務。我想我應該分享一下我是如何分析和解決這個問題的。
關于Celery庫和RQ庫的區別
Celery庫和RQ庫都有工作進程的概念,而且都使用分支來允許多種任務并行運行。當你啟動一個Celery工作進程時,它會分到幾個不同的進程,每個進程會自主地處理任務。使用RQ庫,一個主進程將只會實例化一個子進程(稱為“Worker Horse”),該子進程在執行完一個單獨的任務后將會結束。當主進程從隊列中提取另一項任務時,它將會派出一個新的Work Horse。
在RQ庫中,通過使用更多的工作進程,即可實現與Celery相同的并行性。 但是,Celery庫和RQ庫之間存在著細微的區別:Celery進程在啟動時會實例化多個子進程,并將其重用于多個任務。 而使用RQ庫時,你必須給每一個任務分配進程。 兩種方法都有優點和缺點,但這些內容不在本文討論范圍之內。
標桿分析法
在介紹任何內容之前,我想要確定一個基準,即一個工作容器處理1000項任務需要多長時間。我決定把重心放在record_event工作上,因為它是一種頻繁的,輕量級的操作。我使用time命令來衡量性能,這里需要修改一下源代碼:為了得出完成1000項任務所需的時間,我傾向于采用RQ庫的burst模式,該模式在處理完作業后會退出流程。
我想避免測量那些被安排在基準測試時間段的任務。因此,在task/general.py中的record_event聲明上方,通過將@job('default')替換為@job('benchmark'),可以將record_event移至一個名為benchmark的專用隊列。
現在我們可以開始計時了。首先,我想查看一個進程啟動和停止需要多長時間(沒有任何工作)以便之后可以從任何結果中減去該時間:

在我的計算機上,進程初始化需要14.7秒。我會記住這個時間。
然后,我將1000個虛擬的record_event任務添加進benchmark隊列中:

現在,運行相同的命令,看看處理1000項任務需要多長時間:

減去14.7秒的啟動時間,我們看到4個進程處理1000項任務需要102秒。現在,讓我們嘗試找出原因!為此,在進程工作的同時,我們將使用py_spy模塊。
分析
讓我們再增加1000項任務(因為上次的測試已經刪除了所有任務),運行進程并同時監控它們所耗費的時間:
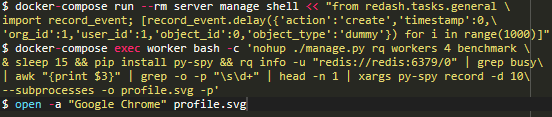
我知道,最后一條命令非常短。 理想情況下,出于可讀性考慮,我會在每個“ &&”上都打斷該命令,但是這些命令應該在同一個docker-compose exec worker bash session中按順序運行。所以,以下是其功能的快速分析:在后臺中,burst模式下,開啟了4個進程。
等待15秒(大致讓它們完成啟動。
安裝py-spy模塊。
運行rq-info命令,并且為其中一個進程進行分層控制。
在該控制過程中記錄10秒中的活動情況并將其保存到profile.svg文件中。
結果如下火焰圖所示:
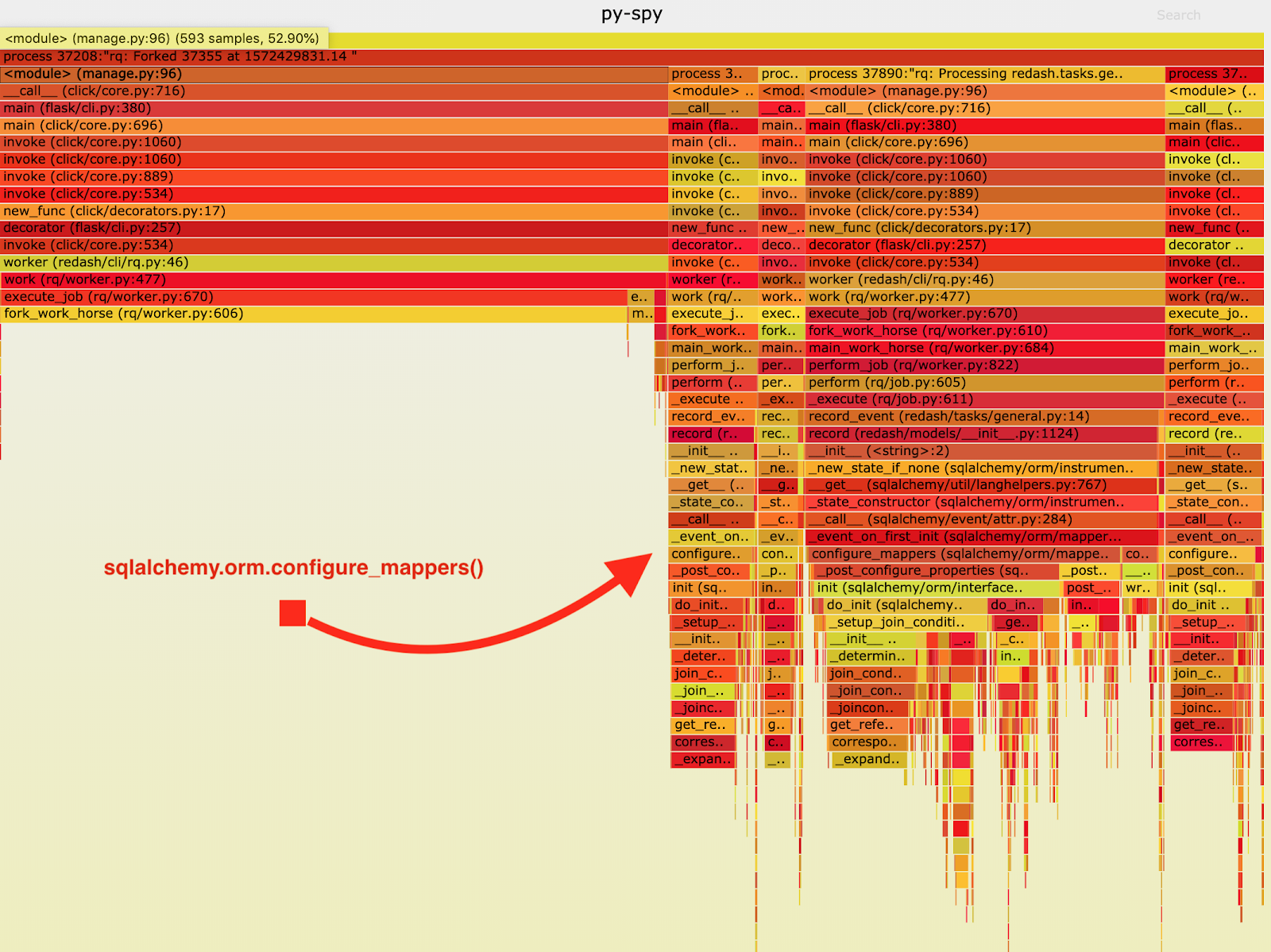
從火焰圖中,我注意到record_event在sqlalchemy.orm.configure_mappers中花費了很大一部分的執行時間,并且每次處理一項工作時這種情況都會出現。從它們的文檔當中,我知道了:初始化到目前為止已構建的所有映射器的映射器間關系。
的確不需要在每一個分支上都發生這種事情。所以,我們可以在主進程當中一次性地初始化這些關系,避免在多個子進程當中重復性這些工作。
因此,在啟動進程之前,我已經對sqlalchemy.org.configure_mappers()進行了調用,并再次進行了測試:
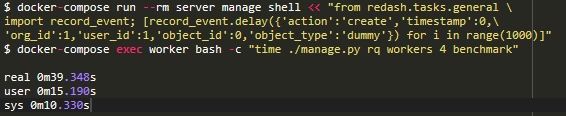
如果我們減去14.7秒的啟動時間,4個線程處理1000項任務的時間將從102秒減少到24.6秒。 比以前提高了4倍! 通過修復此程序,我們成功地將RQ生產資源減少了4倍,并保持了相同的吞吐量。
我認為,你應該記住,在單線程和多線程的情況下,應用的行為是有所不同的。如果每一項任務沒有繁重的重復的工作要做,通常最好在分到多個線程之前進行一次。這些事情在測試和開發過程中不會出現,因此請確保您進行充分的測試并挖掘出任何會出現的性能問題。英文原文:https://blog.redash.io/how-we-spotted-and-fixed-a-performance-degradation-in-our-python-code/
譯者:Lyx


浮點型變量邏輯比較)




筆試題:不使用任何中間變量如何將a、b的值進行交換)
)


#define)




使用const修飾值不允許改變的變量)


