那么,批處理如何神奇地減少延遲呢? 這取決于采用什么算法和數據結構。 在分布式環境中,我們經常不得不將消息/事件分批放入網絡數據包中以實現更大的吞吐量。 我們還采用類似的技術來緩沖對存儲的寫入,以減少IOPS的數量。 該存儲可以是塊設備支持的文件系統或關系數據庫。 大多數IO設備每秒只能處理少量的IO操作,因此最好高效地填充這些操作。 許多批處理方法都涉及等待超時發生,這本質上會增加等待時間。 批處理也可以在超時發生之前被填滿,從而使延遲更加不可預測。
 |
| 圖1 |
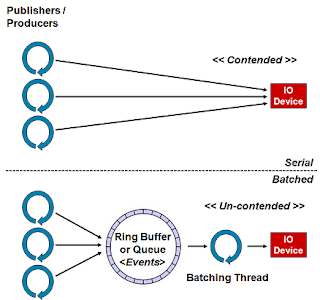
上面的圖1.描繪了通過引入類似隊列的結構來暫存要發送的消息/事件,以及通過進行批量處理以寫入到設備的線程,將對IO設備的訪問以及對訪問它的爭用分離。
算法
批處理方法使用Java偽代碼中的以下算法:
public final class NetworkBatcherimplements Runnable
{private final NetworkFacade network;private final Queue<Message> queue;private final ByteBuffer buffer;public NetworkBatcher(final NetworkFacade network,final int maxPacketSize,final Queue<Message> queue){this.network = network;buffer = ByteBuffer.allocate(maxPacketSize);this.queue = queue;}public void run(){while (!Thread.currentThread().isInterrupted()){while (null == queue.peek()){employWaitStrategy(); // block, spin, yield, etc.}Message msg;while (null != (msg = queue.poll())){if (msg.size() > buffer.remaining()){sendBuffer();}buffer.put(msg.getBytes());}sendBuffer();}}private void sendBuffer(){buffer.flip();network.send(buffer);buffer.clear();}
}基本上,等待數據可用,并立即將其發送。 在發送前一條消息或等待新消息時,可能會到達一連串的流量,所有流量都可以批量發送,直到緩沖區的大小,然后發送到基礎資源。 此方法可以使用ConcurrentLinkedQueue ,它提供低延遲并避免鎖定。 但是,如果線程的速度超過批處理程序的速度,則不會產生使生產/發布線程停頓的反壓力,因為隊列不受限制,因此隊列可能會失去控制。 我經常不得不包裝ConcurrentLinkedQueue來跟蹤其大小,從而產生背壓。 根據我的經驗,此大小跟蹤可以使使用此隊列的處理成本增加50%。
該算法遵循單一寫入器原理 ,可在寫入網絡或存儲設備時經常使用,因此避免了第三方API庫中的鎖爭用。 通過避免爭用,由于對鎖的排隊效應,我們避免了通常與資源爭用相關的J曲線延遲配置文件。 使用此算法,隨著負載的增加,延遲會保持恒定,直到底層設備的流量飽和為止,從而導致比“ J曲線”更多的“浴缸”配置文件。
讓我們舉一個處理10個消息的示例,這些消息作為流量突發而到達。 在大多數系統中,流量是突發的,很少在時間上均勻地間隔開。 一種方法將假定不進行批處理,并且線程將直接寫入設備API,如上面的圖1所示。 另一個將使用無鎖數據結構來收集消息,并按照上述算法在循環中收集消耗消息的單個線程。 對于該示例,我們假設花費100 μs的時間將單個緩沖區作為同步操作寫入網絡設備并得到確認。 當等待時間很關鍵時,緩沖區的大小最好小于網絡的MTU。 許多網絡子系統都是異步的,并且支持流水線化,但是我們將做出上述假設以闡明示例。 如果網絡操作在REST或Web服務下使用HTTP之類的協議,則此假設與基礎實現相匹配。
| 最佳(μs) | 平均值(μs) | 最差(μs) | 發送的數據包 | |
|---|---|---|---|---|
| 序列號 | 100 | 500 | 1,000 | 10 |
| 智能配料 | 100 | 150 | 200 | 1-2 |
如果從線程發起數據直接將消息發送到資源(如果資源無競爭),則將實現絕對最低的延遲。 上表顯示了發生爭用并產生排隊效應時發生的情況。采用串行方法時,將必須發送10個單獨的數據包,并且這些數據包通常需要排隊等待管理對資源的訪問的鎖,因此將按順序進行處理。 上圖假定鎖定策略在沒有可察覺開銷的情況下完美工作,而這在實際應用中是不可能的。
對于批處理解決方案,如果并發隊列有效,則很有可能在首批中拾取所有10個數據包,從而提供最佳的延遲情況。 在最壞的情況下,在第一批中僅發送一條消息,在下一批中發送其他九條消息。 因此,在最壞的情況下,一條消息的延遲為100 μs,隨后的9條消息的延遲為200 μs,因此,最壞情況的平均值為190 μs,這比串行方法要好得多。
當最簡單的解決方案由于爭用而過于簡單時,這就是一個很好的例子。 批處理解決方案有助于在突發條件下實現一致的低延遲,并且最適合吞吐量。 它在接收端的整個網絡上也具有很好的效果,因為接收器必須處理更少的數據包,因此使兩端的通信效率更高。
大多數硬件都會處理緩沖區中的數據(最大固定大小)以提高效率。 對于存儲設備,通常為4KB塊。 對于網絡,這將是MTU,對于以太網,通常為1500字節。 批處理時,最好了解底層硬件并以理想的緩沖區大小寫下批處理,以實現最佳效率。 但是請記住,某些設備需要封裝數據,例如,網絡數據包的以太網和IP標頭,因此緩沖區需要考慮到這一點。
線程切換總是會增加等待時間,并且通過數據結構進行交換的成本也會增加。 但是,使用無鎖技術可以使用許多非常好的非阻塞結構。 對于Disruptor,這種類型的交換可以在短短的50-100ns內完成,因此對于低延遲或高吞吐量的分布式系統而言,選擇智能批處理方法毫無困難。
這項技術可以用于許多問題,而不僅僅是IO。 當發布者突發事件并超過EventProcessor時,Disruptor的核心使用此技術來幫助重新平衡系統。 可以在BatchEventProcessor內部看到該算法。
注意:為了使該算法起作用,排隊結構必須比基礎資源更好地處理爭用。 許多隊列實現在管理爭用方面非常差。 在得出結論之前,請運用科學和測量。
使用干擾器批量處理
下面的代碼顯示了使用Disruptor的EventHandler機制執行的相同算法。 以我的經驗,這是一種非常有效的技術,可以有效地處理任何IO設備,并在處理負載或突發流量時保持較低的延遲。
public final class NetworkBatchHandlerimplements EventHander<Message>
{private final NetworkFacade network;private final ByteBuffer buffer;public NetworkBatchHandler(final NetworkFacade network,final int maxPacketSize){this.network = network;buffer = ByteBuffer.allocate(maxPacketSize);}public void onEvent(Message msg, long sequence, boolean endOfBatch) throws Exception{if (msg.size() > buffer.remaining()){sendBuffer();}buffer.put(msg.getBytes());if (endOfBatch){sendBuffer();}} private void sendBuffer(){buffer.flip();network.send(buffer);buffer.clear();}
}與上述算法中的double循環相比,endOfBatch參數大大簡化了批處理。
我簡化了示例以說明算法。 顯然,需要考慮錯誤處理和其他邊緣條件。
IO與工作處理的分離
還有另一個很好的理由將IO與執行工作處理的線程分開。 將IO移交給另一個線程意味著一個或多個工作線程可以繼續處理而不會以一種友好的緩存友好方式進行阻塞。 我發現這對于實現高性能吞吐量至關重要。
如果基礎IO設備或資源短暫飽和,則可以將消息排隊等待批處理程序線程,以允許工作處理線程繼續進行。 然后,批處理線程以最有效的方式將消息饋送到IO設備,從而允許數據結構處理突發數據,如果已完全施加必要的反壓力,則可以很好地分離工作流程中的關注點。
結論
所以你有它。 智能批處理可與適當的數據結構配合使用,以實現一致的低延遲和最大吞吐量。
參考:來自Mechanical慰問博客的JCG合作伙伴 Martin Thompson提供的智能配料 。
翻譯自: https://www.javacodegeeks.com/2012/08/smart-batching.html











 中國姓氏數據)






:require.js的用法)
![[KISSY5系列]淘寶全終端框架 KISSY 5--從零開始使用](http://pic.xiahunao.cn/[KISSY5系列]淘寶全終端框架 KISSY 5--從零開始使用)