關于網絡入侵檢測領域使用Spark/Flink等計算框架做分布式
- 0、引言
- 1 基于LightGBM的網絡入侵檢測研究
- 2 基于互信息法的智能化運維系統入侵檢測Spark實現
- 3 基于Spark的車聯網分布式組合深度學習入侵檢測方法
- 4 基于Flink的分布式在線集成學習框架研究
- 5 基于Flink的分布式并行邏輯回歸算法的研究
- 6 Flink平臺下的分布式平衡級聯支持向量機
- 7 Flink水位線動態調整策略
- 8 面向Flink的負載均衡任務調度算法的研究與實現
- 9 面向云環境的Flink負載均衡策略
- 10 Network intrusion detection in big dataset using spark
- 11 Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018
- 12 Research of intrusion detection algorithm based on parallel SVM on spark
- 13 Development of a network intrusion detection system using Apache Hadoop and Spark
- 14 Implementing a deep learning model for intrusion detection on apache spark platform
- 15 Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system
?申明: 未經許可,禁止以任何形式轉載,若要引用,請標注鏈接地址。 全文共計5277字,閱讀大概需要5分鐘
🌈更多學習內容, 歡迎👏關注👀【文末】我的個人微信公眾號:不懂開發的程序猿
個人網站:https://jerry-jy.co/
0、引言
本篇博客是我在做基于Spark/Flink大數據環境下網絡入侵檢測的小論文過程中,閱讀的一些參考文獻,并把我認為對我有用的地方記錄下來,希望也能打開你的研究思路
1 基于LightGBM的網絡入侵檢測研究
[1]唐朝飛,努爾布力,艾壯.基于LightGBM的網絡入侵檢測研究[J].計算機應用與軟件,2022,39(08):298-303+311.
針對傳統的常用機器學習算法在網絡入侵檢測中存在準確率不夠高、訓練速度慢的缺點,提出基于特征選擇、LightGBM 的網絡入侵檢測系統。 使用 PCA 進行特征選擇,采用 QPSO 為 LightGBM 算法選擇最優參數,在 Spark 集群上運行,縮短了訓練時間。 此外,由于使用了基于 PCA 的特征選擇方法,僅使用了 41 個特征中的 9個(21. 95% ),達到優于使用全部特征訓練模型的性能。 在 NSL?KDD 數據集上測試了提出的系統的性能,其能準確、快速地對入侵行為樣本進行識別。

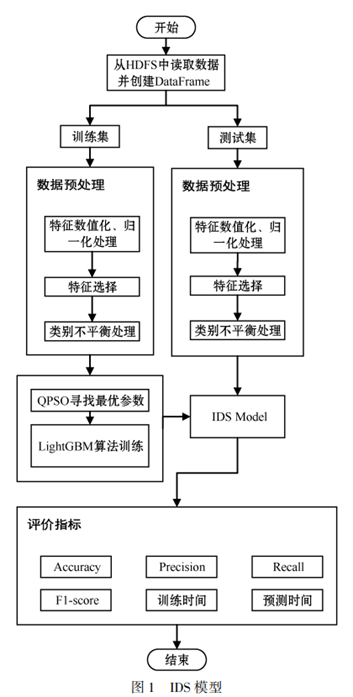
算法流程:
基于 PCA 的特征選擇 —> 基于 LightGBM 的機器學習算法檢測 —> 基于 QPSO 的智能優化算法進行超參數尋優算法
2 基于互信息法的智能化運維系統入侵檢測Spark實現
[1]葛軍凱,李震,張秀峰等.基于互信息法的智能化運維系統入侵檢測Spark實現[J].自動化儀表,2022,43(03):26-28+33.DOI:10.16086/j.cnki.issn1000-0380.2020120064.
為了提高大數據平臺處理海量數據的性能和準確性,在分析互信息(MI)算法的基礎上,設計了基于 MI 算法的智能化運維系統入侵檢測系統。 選取 UNSW-NB15 數據集,以 Spark 平臺進行試驗設計并完成測試過程。 通過 Spark 主執行器實現對從節點的控制功能。 在入侵檢測階段,分別采用 3 種機器學習方法進行檢測,分別通過試驗對比檢測率,誤報率和精確度。 相對于主成分分析(PCA)算法,MI 算法可以獲得更高的特征提取精度,檢測率明顯提升,降低了誤報率。 雖然 MI 算法具備較高精度,但也因此消耗較長時間。 當數據量快速增加后,分布式模型表現出了更短的入侵檢測時間。 該研究對提高運維系統入侵檢測穩定性具有一定的實踐指導意義,但在小概率攻擊類型中該算法存在導致檢測率為零結果,有后續進一步的加強
3 基于Spark的車聯網分布式組合深度學習入侵檢測方法
[1]俞建業,戚湧,王寶茁.基于Spark的車聯網分布式組合深度學習入侵檢測方法[J].計算機科學,2021,48(S1):518-523.
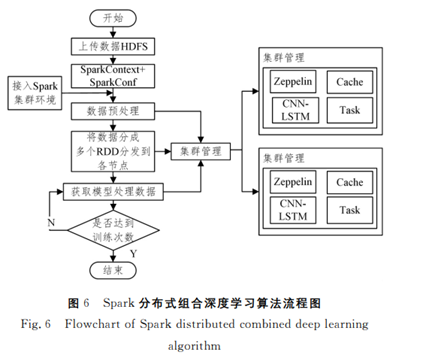

4 基于Flink的分布式在線集成學習框架研究
[1]曹張宇,鐘原,周靜.基于Flink的分布式在線集成學習框架研究[J].計算機應用研究,2023,40(06):1784-1788.DOI:10.19734/j.issn.1001-3695.2022.09.0535.
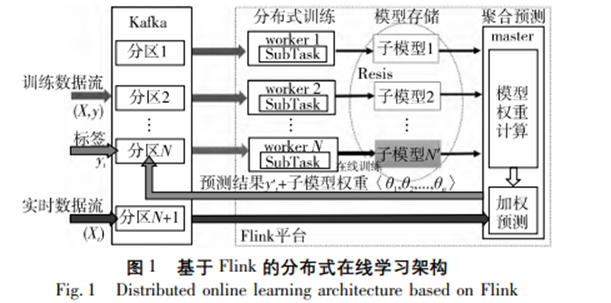
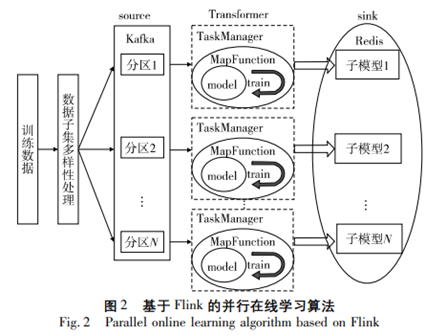
(1)本文設計的算法是在自己搭建的仿真環境下完成測試,對于是否能夠更有效地處理真實環境中規模更大、計算更復雜的數據,后續仍需要繼續研究。
(2)該算法只針對 Flink 集群,未來希望本文提出的 DSAWP 算法可以應用于其它的大數據計算引擎中,并取得性能提升。
(3)該算法要考慮實時監測和收集節點的資源性能指標數據,在提高集群性能時對集群的計算時延有一定的影響,所以下一步的研究就是對集群資源使用率設置約束閾值,找出平衡集群吞吐量和計算時延之間的參數,從而使得集群性能達到更優
5 基于Flink的分布式并行邏輯回歸算法的研究
[1]安超廣.基于Flink的分布式并行邏輯回歸算法的研究[J].長江信息通信,2023,36(04):65-67.
邏輯回歸
目前,機器學習中主要有兩種并行化方案,分別是模型并行化與數據并行化。模型并行化是由于模型太過于龐大,在一個計算機中難以放下,所以需要將模型拆分為多塊,分別放到不同的計算機中進行相應的計算任務。數據并行化則是在每個節點中都放置了完整的模型,讓每個節點使用不同的數據訓練模型[6]。數據并行的并行化方案適合于數據量大的情況。
主要是使用其 Sigmoid 函數,將計算結果映射到(0,1),其中結果大于 0.5 的可劃為第一類,結果小于 0.5 的部分可被劃為第二類。


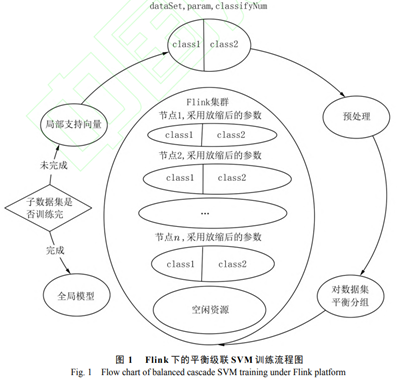
6 Flink平臺下的分布式平衡級聯支持向量機
[1]劉屹成,劉曉燕,嚴馨.Flink平臺下的分布式平衡級聯支持向量機[J/OL].云南大學學報(自然科學版):1-8[2023-08-02].http://kns.cnki.net/kcms/detail/53.1045.N.20230410.1007.004.html.
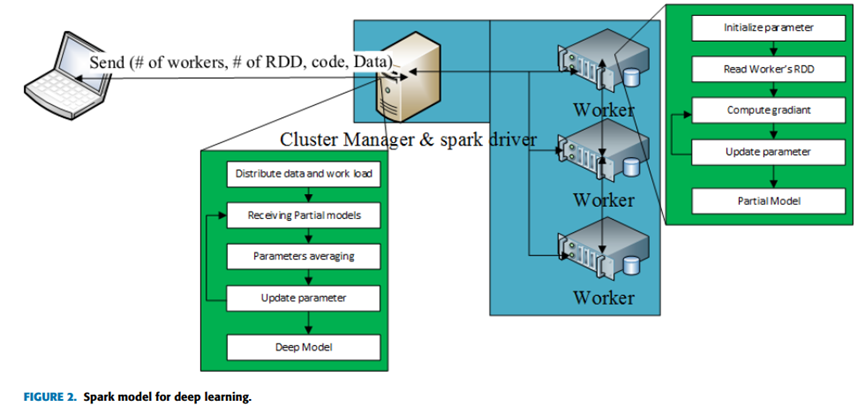
在訓練之前,需要對數據集進行平衡分組及統計樣本數量的預處理. 分塊后的子數據集中,各類樣本所占比例始終與原數據集相同. 由于 Flink 集群中的 TaskManager(類似于一臺機器,也被稱為 Worker)屬性需要在啟動前配置好,在啟動后基本無法更改,真正用于執行任務的 Task Slot(相當于 TaskManager 上的一個執行任務的容器)在默認情況下是根據配置平分 TaskManager 中的所有資源. 故此處需要采用動
態資源分配策略,對 TaskManager 中的資源進行細粒度管理,與默認的粗粒度資源管理的對比如圖 2所示. 在動態資源分配策略下,各節點所需最小資源集的計算方法為存儲樣本所需內存加上核函數矩陣所需內存,如在 LibSVM[16] 中,其計算方法如下:
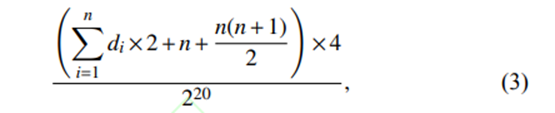
其中:n 為分配到各節點的樣本數量, di為各樣本的實際有效維度 (即取值不為 的維度). 4表示 float 類型的占用空間 , 2^20表示所需內存空間的單位為MB. 該方法可以根據樣本數量決定節點所需的實際內存大小,也可以根據節點的資源屬性,為不同規模的數據集采取相應的任務調度策略[17].算法工作需要提供 3 個參數:dataSet 代表需要訓練的數據集;classifyNum 指每層訓練時的子數據集個數;param 表示訓練所需的參數,如懲罰參數
7 Flink水位線動態調整策略
[1]呂鶴軒,黃山,艾力卡木·再比布拉等.Flink水位線動態調整策略[J].計算機工程與科學,2023,45(02):237-245.
衡量大數據的數據挖掘性能有2個最重要的任務指標:一是實時性,二是準確性。流數據從數據產生到消息隊列再通過數據源流入 Flink進行計算,這個過程中因為網絡傳輸速度不同,不同節點的計算性能不同等原因,流數據進入計算框架的先后順序和數據產生的事件時間順序會有局部亂序的現象。面對窗口作業的傳統水位線機制在不確定亂序程度的流數據情況下無法同時兼顧作業結果的實時性和準確性。針對這個問題,建立了流數據微簇模型。通過局部亂序度算法,根據流數據微簇的流數據事件時間局部亂序程度計算出可以代表當前時刻流數據的亂序度。設計了水位線動態調整策略,使水位線根據流數據的亂序程度動態調整大小。最后,在 ApacheFlink框架中對基于事件時間窗口的水位線動態調整策略進行了實現。實驗結果表明,彈性或不確定亂序流數據條件下,基于事件時間窗口的水位線動態調整策略可以有效地同時兼顧窗口作業的準確性和實時性
8 面向Flink的負載均衡任務調度算法的研究與實現
[1]李文佳,史嵐,季航旭等.面向Flink的負載均衡任務調度算法的研究與實現[J].計算機工程與科學,2022,44(07):1141-1151.
大數據計算引擎的發展歷程主要分為4個階段。第一代大數據計算引擎是谷歌于 2004 年提出的基于 MapReduce[1]的 Hadoop[2]計算引擎。Hadoop主要依靠把任務拆分成 map和reduce2個階段去處理,這種模式由于難以支持迭代計算,因此產生了第二代基于有向無 環 圖 DAG(Directed AcyclicGraph)[3]的 以Tez[4]和 Oozie為代表的計算引擎。雖然第二代計算引擎解決了 MapReduce中不支持迭代計算的問題,但是由于這種計算引擎只能處理離線任務,在線任務處理需求增加的驅動下,產生了第三代基于彈 性 分 布 式 數 據 集 RDD(Resilient Distributed Dataset)[5]的Spark[6]計算引擎。Spark既可以處理離線計算也可以處理實時計算,它是在 Tez的基礎上對Job作了更細粒度的拆分,但是其延遲較大,難以處理實時需求更高的連續流數據請求。因此,產生了現在主流的可以處理高實時性任務的第四代大數據計算引擎 Flink [7]。Flink對事件時間的支持、精確一次(Exactly-Once)的狀態一致性以及內部檢查點機制等特性,決定了其在大數據計算引擎上占據主流地位。
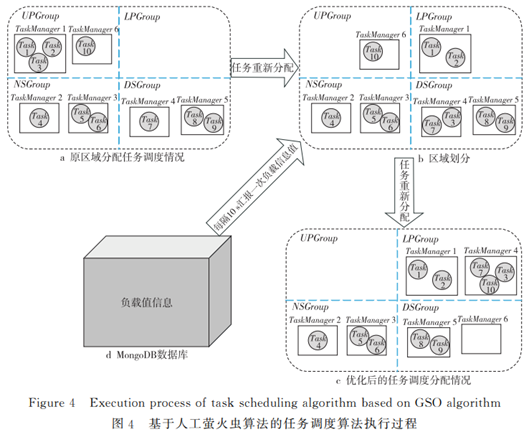
本文提出了基于資源反饋的負載均衡任務調度算法 RFTS(load balancing Task Scheduling algorithm based on Resource Feedback)。與傳統的負載均衡算法不同的是,RFTS算法綜合考慮了集群計算資源的實時負載情況以及處理任務的優先級和順序,更高效地完成任務與計算資源之間的分配,通過實時資源監控、區域劃分和基于人工螢火蟲優化 GSO(Glowworm Swarm Optimization)的任務調度算法3個模塊,把負載過重的機器中處于待隊列中的任務分配給負載較輕的機器,提高系統處理任務的執行效率和集群利用率。
9 面向云環境的Flink負載均衡策略
[1]徐浩桐,黃山,孫國璋等.面向云環境的Flink負載均衡策略[J].計算機工程與科學,2022,44(05):779-787.
結果表明,在相當高的吞吐量下,Storm 和 Flink 的延遲遠低于 Spark Streaming(其延遲與吞吐量成正比)。另一方面,Spark Streaming 能夠處理更高的最大吞吐量,但其性能對批處理持續時間設置非常敏感。
10 Network intrusion detection in big dataset using spark
Dahiya, Priyanka, and Devesh Kumar Srivastava. “Network intrusion detection in big dataset using spark.” Procedia computer science 132 (2018): 253-262.
11 Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018
Hagar, Abdulnaser A., and Bharti W. Gawali. “Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018.” Computational Intelligence and Neuroscience 2022 (2022).
12 Research of intrusion detection algorithm based on parallel SVM on spark
Wang, Hongbing, Youan Xiao, and Yihong Long. “Research of intrusion detection algorithm based on parallel SVM on spark.” 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC). IEEE, 2017.
SVM 是強大的分類和回歸工具。到目前為止,已經出現了一些SVM模型,例如順序最小優化(SMO)、libSVM、lightSVM等。然而,直接使用它們不適合處理大規模數據集。當訓練樣本規模變大時,SVM算法訓練所占用的內存和時間急劇增加[4]。此外,單一SVM算法無法有效處理大規模數據集。為了解決SVM處理大量數據不足的問題,目前的解析策略大致分為并行SVM算法[5]、[6]或采用分而治之的策略來縮小數據范圍[7]。
入侵檢測分析器的設計本質上是確定一個判別函數,以劃分輸入數據集D
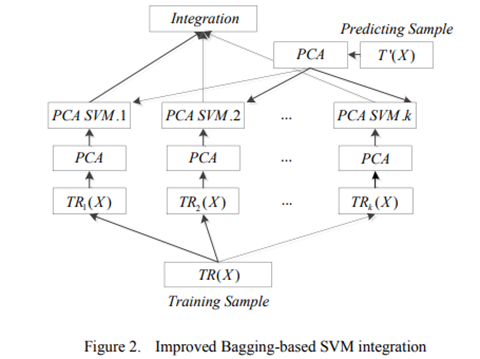
Bagging 整合策略 ???
改進的基于Bagging的SVM集成策略
對于分類問題,分類器的性能非常依賴于所研究的樣本,而樣本中的無用信息,如冗余、噪聲或不可靠信息,會削弱分類器的能力。在入侵檢測中,入侵行為信息往往只集中在某些特征上,如Dos和Probe類型的入侵主要與流量屬性相關,U2R和R2L主要與內容屬性相關。學習算法的冗余特征也會產生影響。隨著不相關特征的增加,學習問題不容易描述,分類精度會大大降低,學習算法的速度會受到影響。為了減少大量冗余信息的干擾,
在模型訓練開始之前,將待訓練的入侵數據上傳到HDFS分布式文件存儲系統。Spark集群的任務調度將數據集分為K塊。每個部分在執行器中創建一個新任務,并分配計算資源。然后在Spark集群上進行PCA數據處理和SVM并行訓練,直到訓練完成得到K個模型。每個模型用于預測待測試數據集,最后通過投票將預測結果合并。
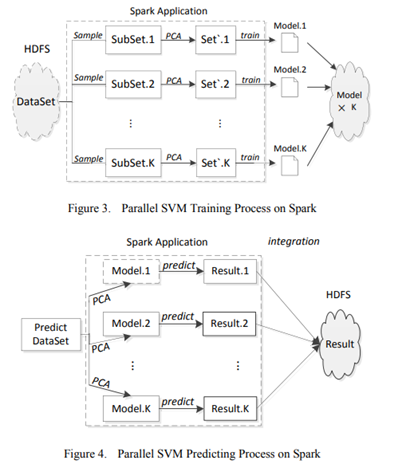
13 Development of a network intrusion detection system using Apache Hadoop and Spark
Kato, Keisuke, and Vitaly Klyuev. “Development of a network intrusion detection system using Apache Hadoop and Spark.” 2017 IEEE Conference on Dependable and Secure Computing. IEEE, 2017.
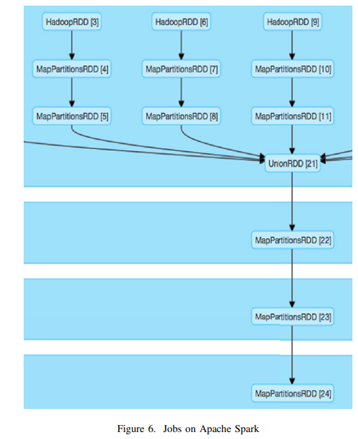
14 Implementing a deep learning model for intrusion detection on apache spark platform
Haggag, Mohamed, Mohsen M. Tantawy, and Magdy MS El-Soudani. “Implementing a deep learning model for intrusion detection on apache spark platform.” IEEE Access 8 (2020): 163660-163672.
NSL-KDD數據集中存在的攻擊是以下四種類型之一:
拒絕服務攻擊(DoS),這是一種通過消耗計算和內存資源來針對服務可用性的攻擊。
用戶對根攻擊 (U2R),這種攻擊首先以網絡上的合法用戶身份進行訪問,然后嘗試利用漏洞來獲取根訪問權限。
遠程到本地攻擊 (R2L),這是一種用戶以遠程用戶身份登錄,然后像本地用戶一樣嘗試檢測系統漏洞并利用權限的攻擊。
探測攻擊(Probe),這是一種嘗試收集有關計算機網絡的數據,以便在以后的攻擊中使用這些數據。
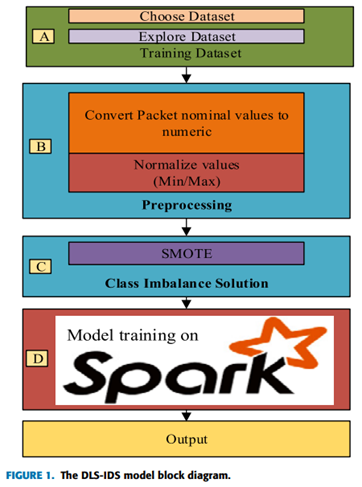
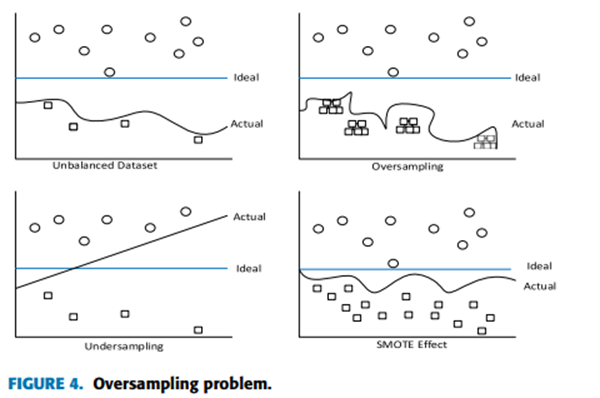
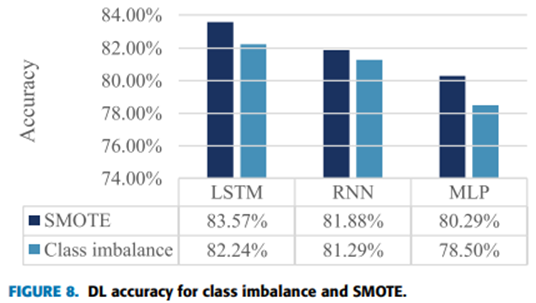
NSL-KDD 數據集存在類別不平衡分布的問題。一些研究人員使用過采樣,即復制少數類點,但這種方法的缺點是對這些點過度擬合。
其他人則使用欠采樣,這會從多數類中刪除一些點。這種方法的問題在于,一些被刪除的點對于代表類別可能至關重要。有一個混合解決方案,可以復制少數類點并刪除一些多數類點。該方法將增強模型,但會繼承兩個過程的問題。
引入了一種新技術[28],稱為合成少數過采樣技術(SMOTE)。該技術是過采樣和欠采樣的組合。盡管如此,過采樣是通過創建少數類的新點而不是重復來完成的,這減少了過擬合的影響,如圖4所示。
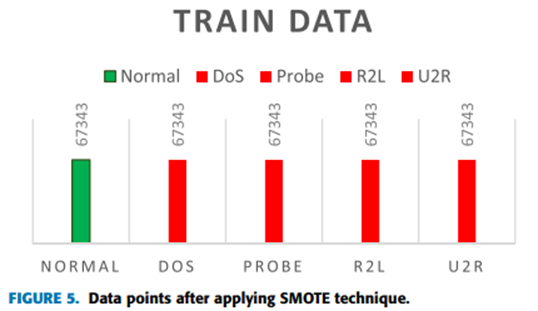
應用SMOTE后,所有類別(正常和攻擊)的NSL-KDD數據點相等,如圖5所示。
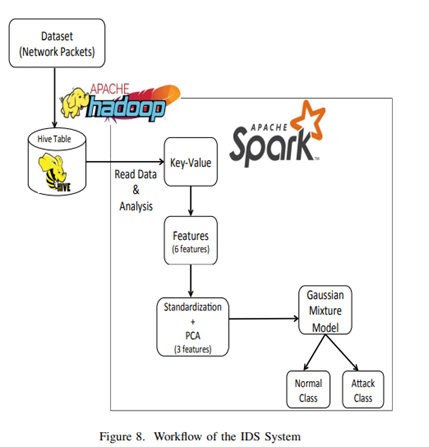
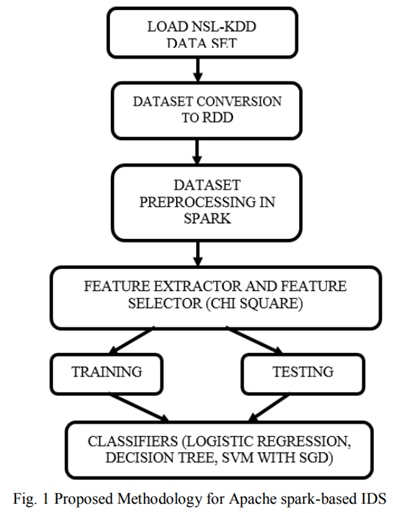
15 Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system
Saravanan, S. “Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system.” 2020 5th International Conference on Communication and Electronics Systems (ICCES). IEEE, 2020.
A. 數據集描述
B. 加載 NSL-KDD 數據集
實現階段首先將數據集加載為 RDD 格式,因為 RDD 是[15]的 Spark 基本架構,因此第一步將數據集加載到彈性分布式數據集中。
C. Spark 中的數據預處理
在此步驟中,用于去除不需要的數據、去除噪聲和去除均值的不同預處理步驟。
字符串索引器:通常,IDS 算法處理一種或多種原始輸入數據類型(例如 SVM 算法),并且還處理數據并將分類數據轉換為數據集中的數值數據。字符串索引器用于將分類數據轉換為數值數據,以實現更高的準確性。
編碼:編碼是一種將分類變量轉換為可用于通過機器學習算法進行更準確預測的形狀的機制
標準化:標準化是在機器學習中實現一致結果的重要技術。重新調整一個或多個屬性的方法需要數據標準化
D. 特征選擇
ChiSqSelector 是一種特征選擇方法,用于在數據集中的所有特征中選擇排名靠前的特征。與其他特征選擇算法相比,它工作高效且準確。它從數據集中存在的所有屬性中選擇最重要的特征。冗余和不相關的數據特征導致了網絡流量分類的問題。減少分類過程,防止分類準確,尤其是在處理高維大數據時。
–
–end–













)
搜索功能實現)




