Gradient-Based Learning Applied to Document Recognition
基于梯度的學習應用于文檔識別
摘要
使用反向傳播算法訓練的多層神經網絡構成了成功的基于梯度的學習技術的最佳示例。給定適當的網絡架構,基于梯度的學習算法可用于合成復雜的決策表面,該決策表面可以通過最少的預處理對高維模式(例如手寫字符)進行分類。本文回顧了應用于手寫字符識別的各種方法,并在標準手寫數字識別任務上對它們進行了比較。卷積神經網絡是專門為處理二維形狀的可變性而設計的,其性能優于所有其他技術。
現實生活中的文檔識別系統由多個模塊組成,包括字段提取、分割、識別和語言建模。一種稱為圖變換網絡(GTN)的新學習范式允許使用基于梯度的方法對此類多模塊系統進行全局訓練,以最大限度地減少整體性能指標。
描述了兩種在線手寫識別系統。實驗證明了全局訓練的優勢,圖轉換器網絡的靈活性。
還描述了用于讀取銀行支票的圖形轉換器網絡。它使用卷積神經網絡字符識別器與全局訓練技術相結合,以提供商業和個人支票的記錄準確性。它已進行商業部署,每天可讀取數百萬張支票。
關鍵詞|神經網絡、OCR、文檔識別、機器學習、基于梯度的學習、卷積神經網絡、圖變換網絡、有限狀態變換器。
命名法
GT 圖形轉換器。
GTN 圖變壓器網絡。
HMM 隱馬爾可夫模型。
HOS 啟發式過度分割。
K-NN K-最近鄰。
NN 神經網絡。
OCR 光學字符識別。
PCA 主成分分析。
RBF 徑向基函數。
RS-SVM 縮減集支持向量方法。
SDNN 空間位移神經網絡。
SVM支持向量法。
TDNN 時延神經網絡。
V-SVM 虛擬支持向量法
1、介紹
在過去的幾年中,機器學習技術,特別是應用于神經網絡時,在模式識別系統的設計中發揮著越來越重要的作用。事實上,可以說學習技術的可用性是最近模式識別應用(例如連續語音識別和手寫識別)取得成功的關鍵因素。
本文的主要信息是,通過更多地依賴自動學習,而不是手工設計的啟發式方法,可以構建更好的模式識別系統。機器學習和計算機技術的最新進展使這成為可能。使用字符識別作為案例研究,我們表明,手工制作的特征提取可以有利地被精心設計的直接在像素圖像上運行的學習機器所取代。
使用文檔理解作為案例研究,我們表明,通過手動集成單獨設計的模塊來構建識別系統的傳統方法可以被一種統一且原則良好的設計范式所取代,稱為圖變換網絡,該范式允許訓練所有模塊優化全局性能標準。
自模式識別早期以來,人們就知道自然數據(無論是語音、字形還是其他類型的模式)的可變性和豐富性,使得完全手工構建準確的識別系統幾乎不可能。因此,大多數模式識別系統都是使用自動學習技術和手工算法相結合來構建的。識別單個模式的常用方法是將系統分為兩個主要模塊,如圖 1 所示。
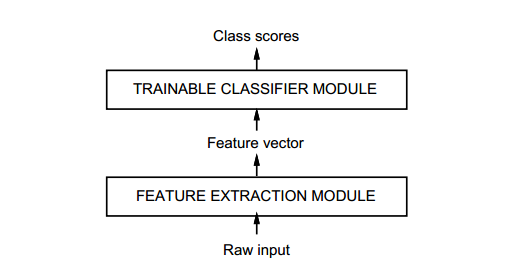
圖 1. 傳統模式識別由兩個模塊執行:固定特征提取器和可訓練分類器。
第一個模塊稱為特征提取器,它對輸入模式進行變換,以便它們可以用低維向量或短符號串表示,(a) 可以輕松匹配或比較,(b) 在變換方面相對不變,并且輸入模式的扭曲不會改變其本質。特征提取器包含大部分先驗知識,并且對于任務來說是相當特定的。它也是大多數設計工作的重點,因為它通常完全是手工制作的。
另一方面,分類器通常是通用的且可訓練的。這種方法的主要問題之一是識別精度很大程度上取決于設計者提出一組適當特征的能力。事實證明,這是一項艱巨的任務,不幸的是,每個新問題都必須重新完成。大量的模式識別文獻致力于針對特定任務來描述和比較相對不同功能集的優點。
從歷史上看,需要適當的特征提取器是因為分類器使用的學習技術僅限于具有易于分離的類的低維空間[1]。過去十年中,三個因素的結合改變了這一愿景。首先,具有快速算術單元的低成本機器的可用性允許更多地依賴暴力“數值”方法,而不是算法改進。其次,針對具有大市場和廣泛興趣的問題的大型數據庫的可用性,例如手寫識別,使設計人員能夠更多地依賴真實數據,而不是手工特征提取來構建識別系統。第三個也是非常重要的因素是強大的機器學習技術的可用性,這些技術可以處理高維輸入并可以生成復雜的數據。可以說,語音和手寫識別系統的準確性的最新進展在很大程度上可以歸因于對學習技術和大型訓練數據集的依賴增加。事實上,大部分現代商業 OCR 系統都使用某種形式的經過反向傳播訓練的多層神經網絡。
在本研究中,我們考慮手寫字符識別的任務(第一部分和第二部分),并比較幾種學習技術在手寫數字識別基準數據集上的性能(第三部分)。
雖然更多的自動學習是有益的,但如果沒有關于任務的最少量的先驗知識,任何學習技術都無法成功。對于多層神經網絡來說,整合知識的一個好方法是根據任務定制其架構。
第二節中介紹的卷積神經網絡 [2] 是專門神經網絡架構的一個示例,它通過使用局部連接模式并對權重施加約束來結合有關 2D 形狀不變性的知識。
第三節對幾種孤立手寫數字識別方法進行了比較。為了從單個字符的識別到文檔中單詞和句子的識別,
第四節介紹了組合多個訓練模塊以減少總體錯誤的想法。如果模塊操作有向圖,則最好使用多模塊系統識別可變長度對象(例如手寫文字)。這引出了第四節中介紹的可訓練圖變換網絡(GTN)的概念。
第五節描述了現在用于識別單詞或其他字符串的啟發式過度分割的經典方法。
第六節介紹了基于判別性和非判別性梯度的技術,用于在單詞級別訓練識別器,而不需要手動分割和標記。
第七節介紹了有前途的空間位移神經網絡方法,該方法通過掃描輸入上所有可能位置的識別器來消除分割啟發式的需要。
在第八節中,表明可訓練的圖變換網絡可以基于通用圖合成算法被表示為多個廣義轉換。還處理了語音識別中常用的 GTN 和隱馬爾可夫模型之間的連接。
第九部分描述了一個全球訓練的 GTN 系統,用于識別筆式計算機中輸入的手寫內容。這個問題被稱為“在線”手寫識別,因為機器必須在用戶書寫時立即產生反饋。該系統的核心是卷積神經網絡。結果清楚地證明了在單詞級別訓練識別器的優勢,而不是在預先分割的、手工標記的、孤立的字符上進行訓練。第 X 節描述了一個完整的基于 GTN 的系統,用于讀取手寫和機器打印的銀行支票。該系統的核心是稱為 LeNet-5 的卷積神經網絡該系統在 NCR Corporation 銀行業支票識別系統系列中投入商業使用。它每月在美國多家銀行讀取數百萬張支票。
A. 從??數據中學習
自動機器學習有多種方法,但近年來神經網絡社區流行的最成功的方法之一可以稱為“數值”或基于梯度的學習。學習機計算函數 Y p = F ( Zp ; W) 其中 Zp 是第 p 個輸入模式,W 表示系統中可調整參數的集合。
在模式識別設置中,輸出 Y p 可以解釋為模式 Zp 的已識別類標簽,或者解釋為與每個類別相關的分數或概率。損失函數 Ep = D(Dp ; F (W; Zp )),測量 Dp 、模式 Zp 的“正確”或期望輸出與系統產生的輸出之間的差異。
平均損失函數 Etrain(W) 是一組稱為訓練集 {(Z1 , D1 ) ,……(ZP , DP )}的標記示例的誤差 Ep 的平均值。在最簡單的設置中,學習問題在于找到使 Etrain(W) 最小化的 W 值。在實踐中,系統在訓練集上的性能并不重要。更相關的衡量標準是系統在實際應用領域的錯誤率。該性能是通過測量與訓練集(稱為測試集)不相交的一組樣本的準確性來估計的。許多理論和實驗工作 [3]、[4]、[5] 表明測試集 Etest 上的預期錯誤率與訓練集 Etrain 上的錯誤率之間的差距隨著訓練樣本數量的增加而減小,近似為
![]()
其中 P 是訓練樣本的數量,h 是機器“有效容量”或復雜性的度量 [6]、[7],是 0:5 到 1:0 之間的數字,k 是常數。當訓練樣本數量增加時,這個gap總是會減小,而且,隨著容量h的增加,Etrain會減小,因此,當容量h增加時,Etrain的減小和gap的增加之間存在一個trade-o,即實現最低泛化誤差 Etest 的容量 h 的最佳值。大多數學習算法嘗試最小化 Etrain 以及對差距的一些估計。其正式版本稱為結構風險最小化 [6]、[7] 和基于定義一系列容量遞增的學習機,對應于參數空間的一系列子集,使得每個子集都是前一個子集的超集。實際上,結構風險最小化是通過最小化 Etrain + H 來實現的(W),其中函數H(W)稱為正則化函數,是一個常數。選擇 H(W),使其對屬于參數空間高容量子集的參數 W 取較大值。最小化 H(W) 實際上限制了參數空間的可訪問子集的容量,從而控制最小化訓練誤差和最小化訓練誤差與測試誤差之間的預期差距之間的權衡。
B. 基于梯度的學習
相對于一組參數最小化函數的一般問題是計算機科學中許多問題的根源。基于梯度的學習利用了這樣一個事實:通常比離散(組合)函數更容易最小化相當平滑的連續函數。可以通過估計參數值的微小變化對損失函數的影響來最小化損失函數。這是通過損失函數相對于參數的梯度來衡量的。當梯度向量可以通過分析計算(而不是通過擾動進行數值計算)時,就可以設計出有效的學習算法。這是許多具有連續值參數的基于梯度的學習算法的基礎。在本文描述的過程中,參數集 W 是一個實值向量,相對于該向量 E(W) 是連續的,并且幾乎處處可微。這種設置中最簡單的最小化過程是梯度下降算法,其中 W 迭代調整如下:

在最簡單的情況下, 是一個標量常數。更復雜的過程使用變量 ,或將其替換為對角矩陣,或將其替換為牛頓或擬牛頓方法中的逆 Hessian 矩陣的估計。也可以使用共軛梯度法[8]。然而,附錄 B 表明,盡管文獻中有許多相反的說法,但這些二階方法對大型學習機的用處非常有限。
流行的最小化過程是隨機梯度算法,也稱為在線更新。它包括使用平均梯度的噪聲或近似版本來更新參數向量。在最常見的實例中,W 根據單個樣本進行更新:

通過這個過程,參數向量圍繞平均軌跡波動,但通常在具有冗余樣本的大型訓練集(例如在語音或字符識別中遇到的訓練集)上比常規梯度下降和二階方法收斂得更快。附錄 B 中解釋了其原因。自 20 世紀 60 年代以來,人們一直在理論上研究應用于學習的此類算法的特性 [9]、[10]、[11],但直到 80 年代中期才在重要任務上取得實際成功。
C. 梯度反向傳播
基于梯度的學習過程自 20 世紀 50 年代末以來一直在使用,但它們大多局限于線性系統 [1]。這種簡單的梯度下降技術對于復雜的機器學習任務的令人驚訝的有用性直到以下三個事件發生才被廣泛認識到。
第一個事件是認識到,盡管有相反的早期警告[12],但損失函數中局部最小值的存在在實踐中似乎并不是一個主要問題。當人們注意到局部最小值似乎并不是玻爾茲曼機等早期非線性梯度學習技術成功的主要障礙時,這一點就變得顯而易見了[13]、[14]。
第二個事件是 Rumelhart、Hinton 和 Williams [15] 以及其他人推廣了一種簡單而有效的程序,即反向傳播算法,用于計算由多層處理組成的非線性系統中的梯度。
第三個活動是演示反向傳播過程應用于具有 sigmoidal 單元的多層神經網絡可以解決復雜的學習任務。反向傳播的基本思想是通過從輸出到輸入的傳播可以有效地計算梯度。這個想法在六十年代初的控制理論文獻中有描述[16],但其在機器學習中的應用當時并未普遍實現。有趣的是,神經網絡學習背景下反向傳播的早期推導并未使用梯度,而是使用中間層單元的“虛擬目標”[17]、[18]或最小擾動參數[19]。拉格朗日形式主義控制理論文獻中使用的方法可能提供了導出反向傳播的最佳嚴格方法[20],并導出反向傳播對循環網絡的概括,和異構模塊網絡[22]。
第 I-E 節給出了通用多層系統的簡單推導。
對于多層神經網絡來說,局部極小值似乎不是問題,這一事實在某種程度上是一個理論上的謎團。據推測,如果網絡對于任務來說過大(實踐中通常是這種情況),參數空間中“額外維度”的存在會降低無法到達區域的風險。反向傳播是迄今為止使用最廣泛的神經網絡-網絡學習算法,可能是任何形式中使用最廣泛的學習算法。
D. 真實手寫識別系統中的學習
孤立的手寫字符識別在文獻中得到了廣泛的研究(參見[23]、[24]的評論),并且是神經網絡的早期成功應用之一[25]。第三節報告了識別單個手寫數字的比較實驗。
他們表明,使用基于梯度的學習訓練的神經網絡比在相同數據上測試的所有其他方法表現更好。最好的神經網絡稱為卷積網絡,旨在學習直接從像素圖像中提取相關特征(參見第二部分)。
然而,手寫識別中最困難的問題之一不僅是識別單個字符,還要將單詞或句子中的相鄰字符分開,這一過程稱為分段。執行此操作的技術已成為“標準”,稱為啟發式過度分割。它包括使用啟發式圖像處理技術在角色之間生成大量潛在的剪切,然后根據給定的分數選擇最佳剪切組合。在這樣的模型中,系統的準確性取決于啟發式生成的剪切質量,以及識別器區分正確分段字符與字符片段、多個字符或多個字符的能力。否則會錯誤地分割字符。訓練識別器來執行此任務提出了重大挑戰,因為創建錯誤分割字符的標記數據庫很困難。最簡單的解決方案包括通過分割器運行字符串圖像,然后手動標記所有的特征假設。不幸的是,這不僅是一項極其乏味且成本??高昂的任務,而且很難一致地進行標記。例如,分割后的 4 的右半部分應該標記為 1 還是非字符?分割后的 8 的右半部分應該標記為 3 嗎?
第五節中描述的第一個解決方案包括在整個字符串級別而不是字符級別訓練系統。基于梯度的學習的概念可以用于此目的。該系統經過訓練,可以最小化衡量錯誤答案概率的總體損失函數。第五節探討了確保損失函數可微的各種方法,因此適合使用基于梯度的學習方法。第五節介紹了使用有向無環圖(其弧帶有數字信息)作為表示替代假設的方式,并介紹了 GTN 的思想。
第七節中描述的第二種解決方案是完全消除分段。這個想法是將識別器掃過輸入圖像上的每個可能的位置,并依賴識別器的“字符定位”屬性,即它能夠正確識別輸入字段中居中的字符,即使存在除了它之外的其他字符,同時拒絕不包含中心字符的圖像[26],[27]。通過在輸入上掃描識別器獲得的識別器輸出序列然后被饋送到圖形變換器網絡,該網絡考慮語言約束并最終提取最可能的解釋。這個 GTN 有點類似于隱馬爾可夫模型 (HMM),這使得該方法讓人想起經典的語音識別 [28]、[29]。雖然這種技術在一般情況下相當昂貴,但卷積神經網絡的使用使其特別有吸引力,因為它可以顯著節省計算成本。
E. 全局可訓練系統
如前所述,大多數實用的模式識別系統都是由多個模塊組成的。例如,文檔識別系統由字段定位器(提取感興趣區域)、字段分割器(將輸入圖像切割為候選字符圖像)、識別器(對每個候選字符進行分類和評分)和上下文環境組成。后處理器,通常基于隨機語法,從識別器生成的假設中選擇最佳的語法正確答案。在大多數情況下,模塊間傳送的信息最好用帶有附加到弧線上的數字信息的圖形表示。例如,識別器模塊的輸出可以表示為非循環圖,其中每個弧包含候選字符的標簽和分數,并且其中每個路徑表示輸入字符串的替代解釋。通常,每個模塊都是在其上下文之外手動優化的,或者有時是經過訓練的。例如,字符識別器將在預分割字符的標記圖像上進行訓練。然后組裝完整的系統,并手動調整模塊參數的子集以最大化整體性能。最后一步極其乏味、耗時,而且幾乎肯定不是最理想的。
更好的選擇是以某種方式訓練整個系統,以最小化全局錯誤度量,例如文檔級別的字符錯誤分類的概率。理想情況下,我們希望找到關于系統中所有參數的全局損失函數的最小值。如果衡量性能的損失函數 E 可以相對于系統的可調參數 W 可微,我們就可以使用基于梯度的學習找到 E 的局部最小值。然而第一眼看去,系統的龐大規模和復雜性似乎使這個問題變得棘手。
為了確保全局損失函數 Ep (Zp ; W) 可微,整個系統被構建為可微模塊的前饋網絡。每個模塊實現的函數對于模塊的內部參數(例如,在字符識別模塊的情況下神經網絡字符識別器的權重)以及模塊的輸入而言,幾乎在任何地方都必須是連續且可微的。如果是這種情況,可以使用眾所周知的反向傳播過程的簡單概括來有效計算損失函數相對于系統中所有參數的梯度[22]。例如,讓我們考慮一個由級聯模塊構建的系統,每個模塊都實現一個函數 Xn = Fn(Wn; Xn1),其中 Xn 是表示模塊輸出的向量,Wn 是可調參數的向量模塊(W 的子集),Xn1 是模塊的輸入向量(以及前一個模塊的輸出向量)。第一個模塊的輸入 X0 是輸入模式 Zp 。如果 Ep 對 Xn 的偏導數已知,則可以使用后向遞推計算 Ep 對 Wn 和 Xn1 的偏導數

其中 ?F/ ?W (Wn, Xn-1) 是 F 相對于在點 (Wn, Xn-1) 處計算的 W 的雅可比行列式,?F/ ?X (Wn, Xn-1) 是 F 相對于 X 的雅可比行列式。向量函數的雅可比行列式是一個包含所有輸出相對于所有輸入的偏導數的矩陣。
第一個方程計算 Ep (W) 梯度的某些項,而第二個方程則生成向后遞歸,就像眾所周知的神經網絡反向傳播過程一樣。我們可以對訓練模式的梯度進行平均以獲得完整的梯度。
有趣的是,在許多情況下,不需要顯式計算雅可比矩陣。上面的公式使用雅可比行列式與偏導數向量的乘積,并且直接計算該乘積通常更容易,而無需預先計算雅可比行列式。與普通的多層神經網絡類比,除了最后一個模塊之外的所有模塊都稱為隱藏層,因為它們的輸出無法從外部觀察到。
在比上述模塊的簡單級聯更復雜的情況下,偏導數符號變得有些模糊和尷尬。在更一般的情況下,可以使用拉格朗日函數 [20]、[21]、[22] 完成完全嚴格的推導。
傳統的多層神經網絡是上述網絡的特例,其中狀態信息 Xn 用固定大小的向量表示,并且其中的模塊是矩陣乘法(權重)和分量式 sigmoid 函數(神經元)的交替層。然而,如前所述,復雜識別系統中的狀態信息最好由帶有附加到弧上的數字信息的圖形來表示。在這種情況下,每個模塊(稱為圖形轉換器)將一個或多個圖形作為輸入,并生成一個圖形作為輸出。此類模塊的網絡稱為圖轉換器網絡(GTN)。
第四、六和八節發展了 GTN 的概念,并表明基于梯度的學習可用于訓練所有模塊中的所有參數,以最小化全局損失函數。當狀態信息由本質上離散的對象(例如圖形)表示時,可以計算梯度,這似乎是自相矛盾的,但這種困難是可以克服的,如稍后所示。
二.用于孤立字符識別的卷積神經網絡
通過梯度下降訓練的多層網絡能夠從大量示例中學習復雜、高維、非線性映射,這使得它們成為圖像識別任務的明顯候選者。在傳統的模式識別模型中,手工設計的特征提取器從輸入中收集相關信息并消除不相關的變異性。然后,可訓練的分類器將所得特征向量分類。
在該方案中,標準的、全連接的多層網絡可以用作分類器。一個可能更有趣的方案是盡可能依賴特征提取器本身的學習。在字符識別的情況下,網絡可以輸入幾乎原始的輸入(例如尺寸標準化圖像)。雖然這可以通過普通的全連接前饋網絡來完成,并在字符識別等任務中取得一些成功,但也存在問題。
首先,典型的圖像很大,通常具有數百個變量(像素)。一個完全連接的第一層,比如說第一層有一百個隱藏單元,已經包含了數萬個權重。如此大量的參數增加了系統的容量,因此需要更大的訓練集。此外,存儲如此多權重的存儲器要求可能排除某些硬件實現。但是,用于圖像或語音應用的非結構化網絡的主要缺陷是它們在翻譯或輸入的局部扭曲方面沒有內置的不變性。
在發送到神經網絡的固定大小輸入層之前,字符圖像或其他 2D 或 1D 信號必須進行近似大小歸一化并在輸入字段中居中。不幸的是,這樣的預處理不可能是完美的:手寫體通常在單詞級別進行標準化,這可能會導致單個字符的大小、傾斜和位置變化。這與書寫風格的變化相結合,將導致輸入對象中顯著特征的位置發生變化。原則上,足夠規模的全連接網絡可以學習產生相對于此類變化不變的輸出。然而,學習這樣的任務可能會導致多個具有相似權重模式的單元位于輸入中的不同位置,以便檢測它們出現在輸入中的任何地方的獨特特征。學習這些權重配置需要大量的訓練實例來覆蓋可能的變化空間。在如下所述的卷積網絡中,通過強制跨空間復制權重配置來自動獲得平移不變性。
其次,全連接架構的缺陷在于完全忽略了輸入的拓撲。輸入變量可以以任何(固定)順序呈現,而不會影響訓練的結果。相反,圖像(或語音的時頻表示)具有很強的二維局部結構:空間或時間上鄰近的變量(或像素)高度相關。局部相關性是在識別空間或時間對象之前提取和組合局部特征的眾所周知的優勢的原因,因為相鄰變量的配置可以分為少量類別(例如邊緣、角點......) 。卷積網絡通過將隱藏單元的感受野限制為局部來強制提取局部特征。
A. 卷積網絡
卷積網絡結合了三種架構思想,以確保一定程度的移位、尺度和失真不變性:局部感受野、共享權重(或權重復制)以及空間或時間子采樣。
圖 2 顯示了一個用于識別字符的典型卷積網絡,稱為 LeNet-5。輸入平面接收近似大小歸一化且居中的字符圖像。層中的每個單元接收來自位于前一層的小鄰域中的一組單元的輸入。將輸入單元連接到局部感受域的想法可以追溯到 60 年代初的感知器,幾乎與 Hubel 和 Wiesel 在貓的視覺系統中發現局部敏感、方向選擇性神經元同時[30]。局部連接已在視覺學習的神經模型中多次使用[31]、[32]、[18]、[33]、[34]、[2]。通過局部感受野,神經元可以提取基本的視覺特征,例如定向邊緣、端點、角(或其他信號中的類似特征,例如語音頻譜圖)。然后,后續層將這些特征組合起來,以檢測更高階的特征。如前所述,輸入的扭曲或偏移可能會導致顯著特征的位置發生變化。此外,對圖像的一部分有用的基本特征檢測器可能對整個圖像有用。可以通過強制一組單元(其感受野位于圖像上的不同位置)具有相同的權重向量來應用這一知識[32]、[15]、[34]。層中的單元按平面組織,其中所有單元共享相同的權重集。該平面中單元的輸出集稱為特征圖。特征圖中的單元都被限制對圖像的不同部分執行相同的操作。
一個完整的卷積層由多個特征圖(具有不同的權重向量)組成,因此可以在每個位置提取多個特征。一個具體的例子是 LeNet-5 的第一層,如圖 2 所示。

圖 2.LeNet-5(一種卷積神經網絡)的架構??,此處用于數字識別。每個平面都是一個特征圖,即一組權重被限制為相同的單元。
LeNet-5的第一個隱藏層中的單元被組織在6個平面中,每個平面都是一個特征圖。特征圖中的一個單元有 25 個輸入,連接到輸入中的 5 x 5 區域,稱為單元的感受野。每個單元有 25 個輸入,因此有 25 個可訓練系數加上一個可訓練偏差。特征圖中連續單元的感受野以前一層中相應的連續單元為中心。因此,相鄰單元的感受野重疊。例如,在 LeNet-5 的第一個隱藏層中,水平連續單元的感受域重疊 4 列和 5 行。如前所述,特征圖中的所有單元共享相同的 25 個權重集和相同的偏差,因此它們在輸入的所有可能位置檢測到相同的特征。該層中的其他特征圖使用不同的權重和偏差集,從而提取不同類型的局部特征。在 LeNet-5 的情況下,在每個輸入位置,六個單元在六個特征圖中相同位置提取六種不同類型的特征。特征圖的順序實現將使用具有局部感受野的單個單元掃描輸入圖像,并將該單元的狀態存儲在特征圖中的相應位置。
此操作相當于一個卷積,后跟一個加性偏差和擠壓函數,因此稱為卷積網絡。卷積的內核是特征圖中的單元使用的連接權重的集合。卷積層的一個有趣的特性是,如果輸入圖像發生移動,特征圖輸出將移動相同的量,但否則將保持不變。這一特性是卷積網絡對輸入的偏移和扭曲的魯棒性的基礎。
一旦檢測到某個特征,其確切位置就變得不那么重要了。只有其相對于其他特征的大致位置才是相關的。例如,一旦我們知道輸入圖像包含左上區域中的大致水平線段的端點、右上區域中的角點以及圖像下部的大致垂直線段的端點,我們可以告訴輸入圖像是 7。這些特征中的每一個的精確位置不僅與識別模式無關,而且還可能有害,因為位置可能會因字符的不同實例而異。降低特征圖中獨特特征的位置編碼精度的一個簡單方法是降低特征圖的空間分辨率。這可以通過所謂的子采樣層來實現,該子采樣層執行局部平均和子采樣,降低特征圖的分辨率,并降低輸出對移位和失真的敏感性。
LeNet5的第二個隱藏層是子采樣層。該層包含六個特征圖,每個特征圖對應前一層中的每個特征圖。每個單元的感受野是前一層對應特征圖中的 2 x 2 區域。每個單元計算其四個輸入的平均值,將其乘以可訓練系數,添加可訓練偏差,并將結果傳遞給 sigmoid 函數。連續的單元具有不重疊的連續感受野。因此,子采樣層特征圖的行數和列數只有一半作為前一層的特征圖。可訓練系數和偏差控制 S 形非線性的影響。如果系數很小,則該單元以準線性模式運行,并且子采樣層僅模糊輸入。如果系數很大,則子采樣單元可以被視為執行“噪聲或”或“噪聲與”函數,具體取決于偏差的值。連續的卷積層和子采樣通常是交替的,從而形成“雙金字塔”:在每一層,特征圖的數量隨著空間分辨率的降低而增加。
圖2中第三個隱藏層中的每個單元可以具有來自前一層中的多個特征圖的輸入連接。卷積/子采樣組合受到 Hubel 和 Wiesel 的“簡單”和“復雜”單元概念的啟發,在福島的 Neocognitron [32] 中實現,盡管沒有全局監督學習當時可以使用諸如反向傳播之類的過程。通過逐漸增加表示的豐富度(特征圖的數量)來補償空間分辨率的逐漸降低,可以實現輸入的幾何變換的很大程度的不變性。
由于所有權重都是通過反向傳播學習的,因此卷積網絡可以被視為合成自己的特征提取器。權值共享技術有一個有趣的副作用,即減少自由參數的數量,從而減少機器的“容量”并減少測試誤差和訓練誤差之間的差距[34]。圖2中的網絡包含340,908個連接,但由于權重共享,只有 60,000 個可訓練的自由參數。
固定大小的卷積網絡已應用于許多應用,包括手寫識別[35]、[36]、機器打印字符識別[37]、在線手寫識別[38]和人臉識別[39]。沿單個時間維度共享權重的固定大小的卷積網絡稱為時延神經網絡 (TDNN)。 TDNN 已用于音素識別(無子采樣)[40]、[41]、口語單詞識別(有子采樣)[42]、[43]、孤立手寫字符的在線識別 [44]、和簽名驗證[45]。
B.LeNet-5
本節更詳細地描述實驗中使用的卷積神經網絡 LeNet-5 的架構。 LeNet-5由7層組成,不包括輸入,所有層都包含可訓練的參數(權重)。
輸入是 32x32 像素圖像。這比數據庫中的最大字符(最多 20x20 像素,以 28x28 字段為中心)大得多。原因是希望潛在的獨特特征(例如筆畫端點或角)可以出現在最高級別特征檢測器的感受野的中心。在 LeNet-5 中,最后一個卷積層(C3,見下文)的感受野中心集在 32x32 輸入的中心形成一個 20x20 的區域。輸入像素的值被歸一化,使得背景水平(白色)對應于值-0.1,前景(黑色)對應于1.175。這使得平均輸入大致為 0,方差大致為 1,從而加速了學習 [46]。
下面,卷積層標記為 Cx,子采樣層標記為 Sx,全連接層標記為 Fx,其中 x 是層索引。
C1 層是一個具有 6 個特征圖的卷積層。每個特征圖中的每個單元都連接到輸入中的 5x5 鄰域。特征圖的大小為 28x28,這可以防止輸入的連接超出邊界。 C1 包含 156 個可訓練參數和 122,304 個連接。
S2層是一個子采樣層,有6個大小為14x14的特征圖。每個特征圖中的每個單元都連接到 C1 中相應特征圖中的 2x2 鄰域。S2 中一個單元的四個輸入相加,然后乘以可訓練系數,并添加到可訓練偏差。
結果通過 sigmoidal 函數傳遞。 2x2 感受域不重疊,因此 S2 中的特征圖的行數和列數是 C1 中特征圖的一半。 S2 層有 12 個可訓練參數和 5,880 個連接。
C3 層是一個具有 16 個特征圖的卷積層。每個特征圖中的每個單元都連接到 S2 特征圖子集中相同位置的多個 5x5 鄰域。表 I 顯示了 S2 特征圖集由每個 C3 特征圖組合。

表I 每一列指示S2中的哪個特征圖由C3的特定特征圖中的單元組合。
為什么不將每個 S2 特征圖連接到每個 C3 特征圖?原因是雙重的。首先,非完整連接方案將連接數保持在合理范圍內。
更重要的是,它迫使網絡對稱性被打破。不同的特征圖被迫提取不同的(希望是互補的)特征,因為它們獲得不同的輸入集。表I中的連接方案背后的基本原理如下。前六個 C3 特征圖從 S2 中三個特征圖的每個連續子集獲取輸入。接下來的六個從四個連續子集中獲取輸入。接下來的三個從四個不連續的子集中獲取輸入。最后一個從所有 S2 特征圖中獲取輸入。 C3 層有 1,516 個可訓練參數和 151,600 個連接。
S4 層是子采樣層,具有 16 個大小為 5x5 的特征圖。每個特征圖中的每個單元都連接到 C3 中相應特征圖中的 2x2 鄰域,其方式與 C1 和 S2 類似。 S4 層有 32 個可訓練參數和 2,000 個連接。
C5 層是一個具有 120 個特征圖的卷積層。
每個單元都連接到 S4 的所有 16 個特征圖上的 5x5 鄰域。這里,因為S4的大小也是5x5,所以C5的特征圖的大小是1x1:這相當于S4和C5之間的全連接。 C5 被標記為卷積層,而不是全連接層,因為如果 LeNet-5 輸入變大而其他一切保持不變,則特征圖尺寸將大于 1x1。第七節描述了動態增加卷積網絡大小的過程。 C5 層有 48,120 個可訓練連接。
F6層包含84個單元(這個數字的原因來自于輸出層的設計,如下所述)并且完全連接到C5。它有 10,164 個可訓練參數。
與經典神經網絡一樣,直到 F6 的層中的單元計算其輸入向量和權重向量之間的點積,并添加偏差。該加權和(對于單元 i 表示為 ai)然后通過 sigmoid 壓縮函數以產生單元 i 的狀態,由 xi 表示:
![]()
擠壓函數是縮放的雙曲正切:
![]()
其中 A 是函數的幅度,S 確定其在原點處的斜率。函數 f 是奇數,在 +A 和 A 處具有水平漸近線。常數 A 選擇為 1:7159。附錄 A 給出了選擇擠壓函數的基本原理。
最后,輸出層由歐幾里得徑向基函數單元 (RBF) 組成,每個類別一個,每個單元有 84 個輸入。每個 RBF 單元 yi 的輸出計算如下:
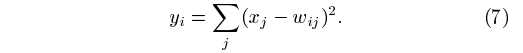
換句話說,每個輸出 RBF 單元計算其輸入向量與其參數向量之間的歐幾里德距離。距離參數向量的輸入越遠,RBF 輸出就越大。特定 RBF 的輸出可以解釋為測量輸入模式和與 RBF 相關的類模型之間的 t 的懲罰項。用概率術語來說,RBF 輸出可以解釋為 F6 層配置空間中高斯分布的非歸一化負對數似然。給定一個輸入模式,損失函數的設計應使 F6 的配置盡可能接近對應于模式所需類別的 RBF 參數向量。
這些單元的參數向量是手動選擇的并保持固定(至少最初是這樣)。這些參數向量的分量被設置為-1或+1。雖然它們可以以 -1 和 +1 的相同概率隨機選擇,甚至可以按照[47]的建議選擇形成糾錯碼,但它們被設計為表示在7x12 位圖(因此數字為 84)。這種表示對于識別孤立的數字并不是特別有用,但是對于識別從完整的可打印 ASCII 集中獲取的字符串非常有用。基本原理是,相似且容易混淆的字符(例如大寫 O、小寫 O 和零,或小寫 l、數字 1、方括號和大寫 I)將具有相似的輸出代碼。如果系統與可以糾正此類混淆的語言后處理器結合使用,這將特別有用。由于易混淆類的代碼相似,因此模糊字符的相應 RBF 的輸出將相似,并且后處理器將能夠選擇適當的解釋。圖 3 給出了完整 ASCII 集的輸出代碼

圖 3. 用于識別完整 ASCII 集的輸出 RBF 的初始參數。
使用這種分布式代碼而不是更常見的 \1 of N" 代碼(也稱為位置代碼或祖母單元代碼)作為輸出的另一個原因是,當類的數量為大于幾十個。原因是非分布式代碼中的輸出單元大多數時候必須是 o。這很難用 sigmoid 單元實現。還有一個原因是分類器經常用于不僅可以識別字符,還可以拒絕非字符。具有分布式代碼的 RBF 更適合此目的,因為與 sigmoid 不同,在這種情況下,它們在輸入空間的一個明確限定的區域內被激活,而非典型模式更有可能落在這個區域之外。
RBF 的參數向量起到 F6 層目標向量的作用。值得指出的是,這些向量的分量為 +1 或 -1,完全在 F6 的 sigmoid 范圍內,因此可以防止這些 sigmoid 飽和。事實上,+1 和 -1 是 S 型曲線的最大曲率點。這迫使 F6 裝置在最大非線性范圍內運行。必須避免 sigmoid 的飽和,因為眾所周知,它會導致損失函數收斂緩慢和病態。
C. 損失函數
可與上述網絡一起使用的最簡單的輸出損失函數是最大似然估計準則(MLE),在我們的例子中相當于最小均方誤差(MSE)。一組訓練樣本的標準很簡單:

其中 yDp 是第 Dp 個 RBF 單元的輸出,即對應于輸入模式 Zp 的正確類別的輸出。雖然此成本函數適用于大多數情況,但它缺乏三個重要屬性。首先,如果我們允許 RBF 的參數進行調整,E(W) 就會有一個微不足道但完全不可接受的解決方案。在該解決方案中,所有 RBF 參數向量都相等,并且 F6 的狀態是恒定的并且等于該參數向量。在這種情況下,網絡會愉快地忽略輸入,并且所有 RBF 輸出都等于 0。如果不允許 RBF 權重自適應,這種崩潰現象就不會發生。第二個問題是班級之間沒有競爭。這種競爭可以通過使用更具辨別力的訓練標準來獲得,稱為 MAP(最大后驗)標準,類似于有時用于訓練 HMM 的最大互信息標準 [48]、[49]、[50]。它對應于最大化正確類 Dp 的后驗概率(或最小化正確類概率的對數),假設輸入圖像可以來自其中一個類或來自背景“垃圾”類標簽。的懲罰,這意味著除了像MSE標準一樣壓低正確類別的懲罰之外,該標準還拉高了錯誤類別的懲罰:
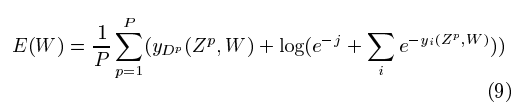
第二項的否定起著“競爭”的作用。
它必然小于(或等于)第一項,因此該損失函數為正。常數 j 是正值,可以防止已經很大的類別的懲罰被進一步推高。該垃圾類標簽的后驗概率將是 𝑒?𝑗?和 𝑖𝑒𝑦𝑖(𝑍𝑃,?𝑊)?的比率。當學習 RBF 參數時,這種判別標準可以防止前面提到的“崩潰效應”,因為它使 RBF 中心彼此分開。在第六節中,我們為學習對多個對象進行分類的系統提出了該標準的推廣輸入(例如,單詞或文檔中的字符)。
計算損失函數相對于卷積網絡所有層中所有權重的梯度是通過反向傳播完成的。必須稍微修改標準算法以考慮權重共享。實現它的一種簡單方法是首先計算損失函數相對于每個連接的偏導數,就好像網絡是沒有權重共享的傳統多層網絡一樣。然后將共享相同參數的所有連接的偏導數相加,以形成相對于該參數的導數。
如此大型的架構可以非常有效地進行訓練,但這樣做需要使用附錄中描述的一些技術。附錄的 A 節描述了諸如所使用的特定 sigmoid 和權重初始化等細節。 B 和 C 部分描述了所使用的最小化過程,它是 Levenberg-Marquardt 過程的對角線近似的隨機版本。
三.結果及與其他方法的比較
雖然識別單個數字只是設計實用識別系統所涉及的眾多問題之一,但它是比較形狀識別方法的絕佳基準。盡管許多現有方法結合了手工制作的特征提取器和可訓練的分類器,但本研究集中于直接對尺寸歸一化圖像進行操作的自適應方法。
A. 數據庫: 修改的NIST 集
用于訓練和測試本文中描述的系統的數據庫是根據包含手寫數字二進制圖像的 NIST 特殊數據庫 3 和特殊數據庫 1 構建的。 NIST 最初指定 SD-3 作為訓練集,SD-1 作為測試集。然而,SD-3 比 SD1 更清晰、更容易識別。原因在于SD-3是在人口普查局的雇員中收集的,而SD-1則是在高中生中收集的。從學習實驗中得出合理的結論要求結果獨立于完整樣本集中訓練集和測試的選擇。因此有必要通過混合 NIST 的數據集來建立一個新的數據庫。
SD-1 包含由 500 位不同作家撰寫的 58,527 幅數字圖像。與 SD-3 不同的是,SD-3 中每個寫入器的數據塊按順序出現,而 SD-1 中的數據是加擾的。 SD-1 的作者身份是可用的,我們使用此信息來解讀作者。然后,我們將 SD-1 一分為二:前 250 位作家寫的字符進入我們的新訓練集。其余 250 位作家被放入我們的測試集中。因此,我們有兩組,每組有近 30,000 個示例。新的訓練集使用 SD-3 中的足夠示例完成,從模式 # 0 開始,形成一整套 60,000 個訓練模式。
同樣,新的測試集是用從模式 # 35,000 開始的 SD-3 示例完成的,以形成具有 60,000 個測試模式的完整集。在此描述的實驗中,我們僅使用了 10,000 個測試圖像的子集(5,000 個來自 SD-1 和 5,000 個來自 SD-3),但我們使用了完整的 60,000 個訓練樣本。生成的數據庫稱為 Modi ed NIST 或 MNIST 數據集。
原始黑白(雙層)圖像的尺寸在 20x20 像素框中標準化為 t,同時保留其縱橫比。由于歸一化算法使用的抗鋸齒(圖像插值)技術,生成的圖像包含灰度級。使用了三個版本的數據庫。在第一個版本中,通過計算像素的質心并平移圖像以將該點定位在 28x28 區域的中心,圖像在 28x28 圖像中居中。在某些情況下,這個 28x28 字段會擴展到帶有背景像素的 32x32。該版本的數據庫將被稱為常規數據庫。
在數據庫的第二個版本中,角色圖像被去除傾斜并裁剪為 20x20 像素圖像。去傾斜計算像素的二階慣性矩(將前景像素計為 1,將背景像素計為 0),并通過水平移動線條以使主軸垂直來剪切圖像。該版本的數據庫將被稱為 deslanted 數據庫。在一些早期實驗中使用的數據庫的第三個版本中,圖像被縮小到 16x16 像素。常規數據庫(60,000 個訓練示例、10,000 個測試示例(大小標準化為 20x20,并以 28x28 字段中的質心為中心))可從 error 獲取。
圖 4 顯示了從測試集中隨機選取的示例。

圖 4 來自 MNIST 數據庫的大小歸一化示例。
B. 結果
LeNet-5 的多個版本是在常規 MNIST 數據庫上進行訓練的。每個會話對整個訓練數據進行 20 次迭代。全局學習率的值(參見附錄 C 中的公式 21 了解定義)使用以下計劃減小:前兩遍為 0.0005,接下來的3個為 0.0002,接下來的 3 個為 0.0001,接下來的 4 個為 0.00005,其后為 0.00001。在每次迭代之前,如附錄 C 中所述,對 500 個樣本重新評估對角線 Hessian 近似,并在整個迭代期間保持固定。參數設置為0.02。在第一遍期間,所得到的有效學習率在參數集上大約在 7 105 到 0:016 之間變化。經過大約 10 次訓練集后,測試錯誤率穩定在 0.95%。經過 19 遍后,訓練集上的錯誤率達到 0.35%。許多作者報告說,在針對各種任務訓練神經網絡或其他自適應算法時,觀察到了過度訓練的常見現象。當過度訓練發生時,訓練誤差隨著時間的推移不斷減小,但測試誤差會經歷一個最小值,并在一定次數的迭代后開始增大。雖然這種現象很常見,但在我們的案例中并未觀察到,如圖 5 中的學習曲線所示。一個可能的原因是學習率保持相對較大。這樣做的結果是權重永遠不會穩定在局部最小值,而是保持隨機振蕩。因為那些波動時,平均成本將在更廣泛的最低限度內降低。

圖 5.LeNet-5 的訓練和測試誤差作為通過 60,000 個模式訓練集(無失真)的次數的函數。平均訓練誤差是在 -y 隨著訓練的進行。這解釋了為什么訓練誤差似乎大于測試誤差。經過 10 到 12 次訓練集后即可收斂。
因此,隨機梯度將具有與有利于更廣泛最小值的正則化項類似的效果。較寬的最小值對應于參數分布熵較大的解,這有利于泛化誤差。
在通過使用 15,000、30,000 和 60,000 個示例訓練網絡來測量訓練集大小的影響。由此產生的訓練誤差和測試誤差如圖 6 所示。很明顯,即使使用 LeNet-5 等專門的架構,更多的訓練數據也會提高準確性。

圖 6. 使用不同大小的訓練集實現的 LeNet-5 的訓練和測試誤差。該圖表明更大的訓練集可以提高 LeNet-5 的性能。空心方塊顯示使用隨機失真人工生成更多訓練模式時的測試誤差。測試圖案不變形
為了驗證這個假設,我們通過隨機扭曲原始訓練圖像來人工生成更多的訓練樣本。將增加的訓練集組成60,000個原始圖案加上540,000個帶有隨機選擇的扭曲參數的扭曲圖案實例。扭曲是以下平面變換的組合:水平和垂直平移、縮放、擠壓(同時水平壓縮和垂直伸長,或相反)以及水平剪切。圖 7 顯示了用于訓練的扭曲模式的示例。當使用扭曲數據進行訓練時,測試錯誤率下降至 0.8%(未變形時為 0.95%)。使用與沒有變形相同的訓練參數。訓練課程的總時長保持不變(20 次,每次 60,000 個模式)。有趣的是,在這 20 次傳遞過程中,網絡實際上只看到每個單獨的樣本兩次。

圖 7.十種訓練模式的扭曲示例。
圖 8 顯示了所有 82 個錯誤分類的測試示例。其中一些例子確實含糊不清,盡管它們是用代表性不足的風格編寫的,但是有幾個人類可以完全識別。這表明隨著更多的訓練數據,預計會有進一步的改進。

圖 8. LeNet-5 錯誤分類的 82 個測試模式。每張圖片下方都顯示了正確答案(左)和網絡答案(右)。這些錯誤主要是由真正不明確的模式引起的,或者是由訓練集中代表性不足的風格編寫的數字引起的。
C.與其他分類器的比較為了進行比較
在同一數據庫上對各種其他可訓練分類器進行了訓練和測試。這些結果的早期子集在[51]中提出。各種方法的測試集的錯誤率如圖 9 所示。
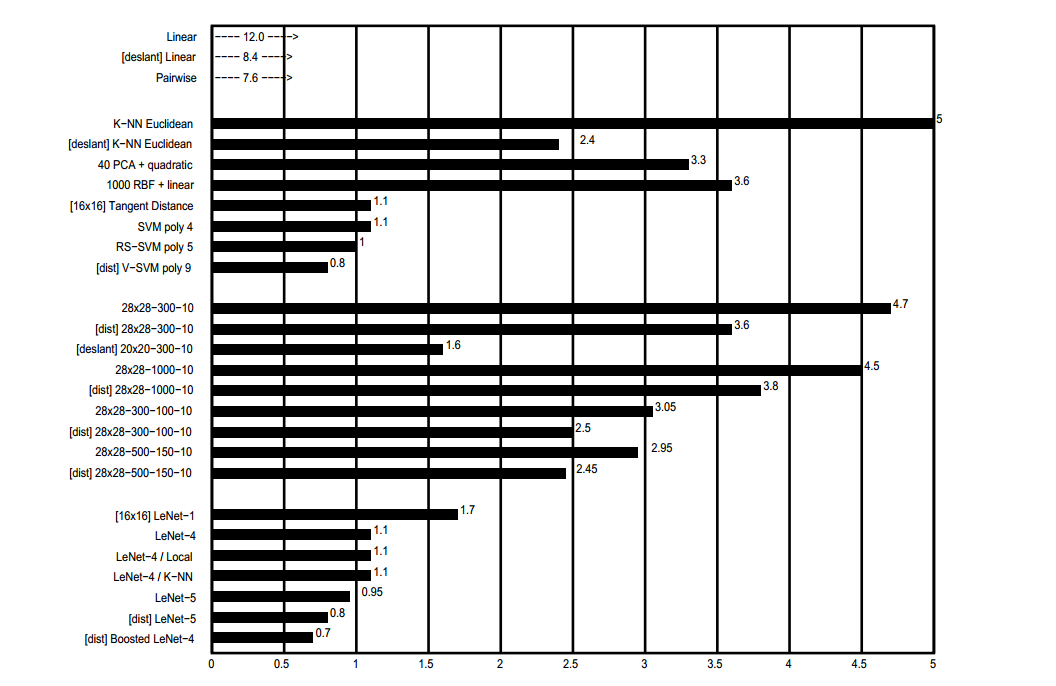
圖 9. 各種分類方法的測試集錯誤率 (%)。 [deslant] 表示分類器是在數據庫的 deslanted 版本上進行訓練和測試的。 [dist] 表示訓練集增加了人為扭曲的示例。 [16x16]表示系統使用16x16像素的圖像。所報錯誤率的不確定性約為0.1%。
C.1 線性分類器和成對線性分類器
人們可能考慮的最簡單的分類器是線性分類器。每個輸入像素值對每個輸出單元的加權和有貢獻。總和最大的輸出單元(包括偏置常數的貢獻)。表示輸入字符的類別。在常規數據上,錯誤率為12%。該網絡有 7850 個免費參數。在去斜圖像上,測試錯誤率為8.4%。網絡有4010個自由參數。線性分類器的缺陷已有詳細記錄 [1],將其包含在這里只是為了形成更復雜的分類器的比較基礎。 sigmoid 單元、線性單元、梯度下降學習和直接求解線性系統學習的各種組合給出了相似的結果。
測試了基本線性分類器的簡單改進[52]。這個想法是訓練單層網絡的每個單元以將每個類與其他類分開。在我們的例子中,該層包含 45 個單元,標記為 0/1、0/2、...0/9、1/2...8/9。單元 i=j 被訓練為在 i 類模式上產生 +1,在 j 類模式上產生 -1,并且不接受其他模式的訓練。對于所有 x 和 y,第 i 類的最終分數是所有標記為 i=x 的單元的輸出總和減去所有標記為 y=i 的單元的輸出總和。常規測試集的錯誤率為 7.6%。
C.2 基線最近鄰分類器
另一個簡單的分類器是 K 最近鄰分類器,在輸入圖像之間具有歐幾里得距離度量。該分類器的優點是不需要訓練時間,也不需要設計者動腦筋。
然而,內存要求和識別時間都很大:完整的 60,000 個 20 x 20 像素訓練圖像(每個像素 1 字節大約 24 兆字節)必須在運行時可用。可以設計出更緊湊的表示形式,同時錯誤率略有增加。在常規測試集上,錯誤率為 5.0%。在去傾斜數據上,錯誤率為 2.4%,k = 3。自然地,現實的歐幾里得距離最近鄰系統將在特征向量上運行,而不是直接在像素上運行,但由于本研究中提出的所有其他系統直接對像素進行操作,此結果對于基線比較很有用。
C.3 主成分分析(PCA)和多項式分類器
繼[53]、[54]之后,構建了一個預處理階段,用于計算輸入模式在訓練向量集的 40 個主成分上的投影。為了計算主成分,首先計算每個輸入成分的平均值并從訓練向量中減去。然后使用奇異值分解計算所得向量的協方差矩陣并對其進行對角化。 40維特征向量被用作二階多項式分類器的輸入。這個分類器可以看作是一個具有821個輸入的線性分類器,前面是一個計算輸入變量對的所有乘積的模塊。常規測試集的誤差為 3.3%。
C.4 徑向基函數網絡
繼[55]之后,構建了 RBF 網絡。第一層由 1,000 個具有 28x28 輸入的高斯 RBF 單元組成,第二層是一個簡單的 1000 個輸入/10 個輸出的線性分類器。 RBF 單元分為 10 組,每組 100 個。使用自適應 K 均值算法對每組單元進行 10 個類之一的所有訓練示例的訓練。使用正則化偽逆方法計算第二層權重。常規測試集的錯誤率為 3.6%
C.5 單隱層全連接多層神經網絡
我們測試的另一個分類器是一個完全連接的多層神經網絡,具有兩層權重(一個隱藏層),使用附錄 C 中描述的反向傳播版本進行訓練。網絡的常規測試集誤差為 4.7%具有 300 個隱藏單元的網絡,具有 1000 個隱藏單元的網絡為 4.5%。使用人工扭曲生成更多訓練數據僅帶來邊際改進:300 個隱藏單元提高 3.6%,1000 個隱藏單元提高 3.8%。當使用去傾斜圖像時,對于具有 300 個隱藏單元的網絡,測試誤差躍升至 1.6%。
具有如此大量自由參數的網絡能夠實現相當低的測試錯誤仍然是一個謎。我們推測多層網絡中梯度下降學習的動力學具有“自正則化”效應。由于權重空間的原點是一個幾乎在每個方向上都有吸引力的鞍點,因此權重在最初的幾個時期總是會縮小(最近的理論分析似乎證實了這一點[56])。小權重導致 sigmoid 在準線性區域運行,使得網絡本質上相當于一個低容量的單層網絡。隨著學習的進行,權重增長,逐漸增加網絡的有效容量。這似乎是 Vapnik 的“結構風險最小化”原則的近乎完美(如果是偶然的)實施[6]。絕對需要對這些現象有更好的理論理解和更多的經驗證據。
C.6 二隱層全連接多層神經網絡
為了查看該架構的效果,訓練了幾個兩隱藏層的多層神經網絡。理論結果表明任何函數都可以用單隱層神經網絡來逼近[57]。然而,一些作者觀察到,兩個隱藏層架構有時在實際情況下會產生更好的性能。這里也觀察到了這種現象。 28x28-300-100-10 網絡的測試錯誤率為 3.05%,比使用稍多的權重和連接獲得的單隱藏層網絡要好得多。
將網絡大小增加到 28x28-1000-150-10 僅略微改善了錯誤率:2.95%。使用扭曲模式進行訓練在一定程度上提高了性能:28x28-300-100-10 網絡的錯誤率為 2.50%,28x28-1000-150-10 網絡的錯誤率為 2.45%。
C.7 小型卷積網絡:LeNet-1
卷積網絡試圖解決無法學習訓練集的小型網絡和似乎過度參數化的大型網絡之間的困境。 LeNet-1 是卷積網絡架構的早期實施例,出于比較目的而包含在此處。圖像被下采樣到 16x16 像素并位于 28x28 輸入層的中心。盡管評估 LeNet-1 需要大約 100,000 個乘法/加法步驟,但其卷積性質使自由參數的數量僅約為 2600 個。LeNet1 架構是使用我們自己版本的 USPS(美國郵政服務郵政編碼)數據庫開發的,并且其大小經過調整以匹配可用數據[35]。 LeNet-1 取得了 1.7% 的測試誤差。具有如此少量參數的網絡可以獲得如此好的錯誤率,這一事實表明該架構適合該任務。
C.8 LeNet-4
LeNet-1 的實驗清楚地表明,需要更大的卷積網絡才能充分利用大尺寸的訓練集。 LeNet-4和后來的LeNet5就是為了解決這個問題而設計的。除了架構細節之外,LeNet-4 與 LeNet-5 非常相似。它包含 4 個第一層特征圖,后面是與每個第一層特征圖成對連接的 8 個子采樣圖,然后是 16 個特征圖,后面是 16 個子采樣圖,后面是一個有 120 個單元的全連接層,最后是輸出層(10 個單位)。 LeNet-4包含約260,000個連接,并具有約17,000個自由參數。測試誤差為1.1%。在一系列實驗中,我們用歐幾里德最近鄰分類器替換了 LeNet-4 的最后一層,并用 Bottou 和 Vapnik [58] 的“局部學習”方法替換,其中每次都重新訓練局部線性分類器顯示了新的測試模式。盡管這些方法確實提高了拒絕性能,但它們都沒有提高原始錯誤率。
C.9 增強的 LeNet-4
根據 R. Schapire [59] 的理論工作,Drucker 等人 [60] 開發了組合多個分類器的“boosting”方法。組合了三個 LeNet-4:第一個以通常的方式進行訓練。第二個以常規方式進行訓練在第一個網絡過濾的模式上,以便第二個機器看到混合的模式,第一個網絡有 50% 是正確的,而 50% 是錯誤的。最后,第三個網絡接受新模式的訓練第一個和第二個網絡不一致。在測試時,將三個網絡的輸出簡單相加。由于LeNet-4的錯誤率非常低,因此需要使用人工扭曲的圖像(與LeNet-5一樣) )以獲得足夠的樣本來訓練第二個和第三個網絡。測試錯誤率為 0.7%,是我們所有分類器中最好的。乍一看,Boosting 的成本似乎是單個網絡的三倍。事實上,當第一個網絡產生高置信度答案時,其他網絡不會被調用。平均計算成本約為單個網絡的1.75倍。
C.10 切線距離分類器(TDC)
切線距離分類器(TDC)是一種最近鄰方法,其中距離函數對輸入圖像的小變形和平移不敏感[61]。如果我們將圖像視為高維像素空間中的一個點(其中維數等于像素數),那么字符的不斷演變的失真會在像素空間中描繪出一條曲線。總而言之,所有這些扭曲定義了像素空間中的低維流形。對于小畸變,在原始圖像附近,可以用一個平面(稱為切平面)來近似該流形。字符圖像“接近度”的一個很好的衡量標準是它們的切平面之間的距離,其中用于生成平面的扭曲集包括平移、縮放、傾斜、擠壓、旋轉和線粗細變化。使用 16x16 像素圖像實現了 1.1% 的測試錯誤率。在多個分辨率下使用簡單歐幾里得距離的預過濾技術可以減少必要的切線距離計算的數量。
C.11 支持向量機(SVM)
多項式分類器是經過充分研究的用于生成復雜決策面的方法。不幸的是,它們對于高維問題不切實際,因為乘積項的數量令人望而卻步。支持向量技術是一種在高維空間中表示復雜表面(包括多項式和許多其他類型的表面)的極其經濟的方法[6]。
決策面的一個特別有趣的子集是與乘積項的高維空間中距兩類凸包最大距離的超平面相對應的子集。 Boser、Guyon 和 Vapnik [62] 意識到,這個“最大邊距”集中的任何 k 次多項式都可以通過首先計算輸入圖像與訓練樣本子集(稱為“支持向量”)的點積來計算。 ),將結果進行 k 次方,然后將所得數字進行線性組合。找到支持向量和系數相當于解決具有線性不等式約束的高維二次最小化問題。為了進行比較,我們在此納入了 Burges 和 Scholkopf 在[63]中報告的結果。使用常規 SVM,他們在常規測試集上的錯誤率為 1.4%。 Cortes 和 Vapnik 報告稱,使用略有不同的技術,在相同數據上使用 SVM 的錯誤率為 1.1%。該技術的計算成本非常高:每次識別大約需要 1400 萬次乘加運算。使用 Sch olkopf 的虛擬支持向量技術 (V-SVM),獲得了 1.0% 的誤差。最近,Sch olkopf(個人通訊)使用 V-SVM 的修改版本已達到 0.8%。不幸的是,V-SVM 非常昂貴:大約是普通 SVM 的兩倍。為了緩解這個問題,Burges 提出了縮減集支持向量技術(RS-SVM),該技術在常規測試集上達到了 1.1% [63],每次識別的計算成本僅為 650,000 次乘加,即僅比 LeNet-5 貴約 60 %。
D、討論
圖 9 至圖 12 顯示了分類器性能的摘要。圖 9 顯示了分類器在 10,000 個示例測試集上的原始錯誤率。 Boosted LeNet-4 表現最好,得分為 0.7%,緊隨其后的是 LeNet-5,得分為 0.8%。

圖 10. 拒絕性能:某些系統必須拒絕才能實現 0.5% 錯誤的測試模式的百分比。
圖 10 顯示了測試集中必須拒絕的模式數量,以達到某些方法的 0.5% 錯誤率。當相應輸出的值小于預定閾值時,模式被拒絕。
在許多應用中,拒絕性能比原始錯誤率更重要。用于決定拒絕某個模式的分數是前兩個類別的分數之間的差異。同樣,Boosted LeNet-4 具有最佳性能。盡管準確度是相同的,原始 LeNet-4 的增強版本比原始 LeNet-4 表現更好。

圖 11. 從尺寸歸一化圖像開始識別單個字符的乘法累加運算的數量。
圖 11 顯示了每種方法識別單個尺寸歸一化圖像所需的乘法累加運算的數量。預計神經網絡的要求比基于記憶的方法要低得多。卷積神經網絡特別適合硬件實現,因為它們的結構規則且權重內存要求低。 LeNet-5 前身的單芯片混合模擬數字實現已被證明能夠以超過每秒 1000 個字符的速度運行 [64]。然而,主流計算機技術的快速進步使得這些外來技術很快就過時了。由于內存需求和計算需求巨大,基于內存的技術的經濟有效的實現更加難以捉摸。
還測量了訓練時間。 K 最近鄰和 TDC 的訓練時間基本上為零。雖然單層網絡、成對網絡和 PCA+二次網絡可以在不到一個小時的時間內完成訓練,但多層網絡的訓練時間預計要長得多,但只需要 10 到 20 次通過訓練集。這相當于使用單個 200MHz R10000 處理器在 Silicon Graphics Origin 2000 服務器上訓練 LeNet-5 需要 2 到 3 天的 CPU 時間。需要注意的是,雖然訓練時間與設計者有一定關系,但系統的最終用戶卻沒有多大興趣。考慮到在現有技術和以大量訓練時間為代價帶來邊際精度提高的新技術之間進行選擇,任何最終用戶都會選擇后者。
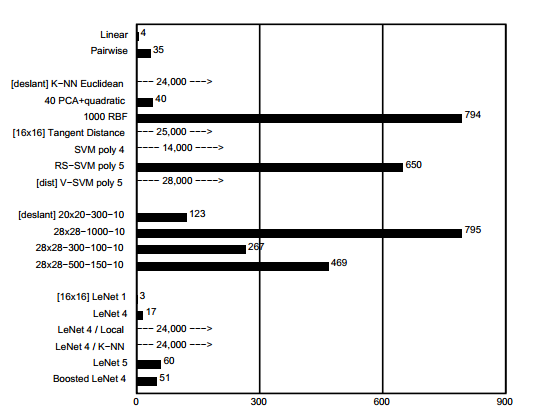
圖 12. 每種方法的內存需求(以變量數量衡量)。大多數方法只需要每個變量一個字節即可獲得足夠的性能。
圖 12 顯示了內存需求,以及根據需要存儲的變量數量衡量的各種分類器的自由參數數量。大多數方法只需要每個變量大約一個字節即可獲得足夠的性能。然而,NearestNeighbor 方法可能需要每像素 4 位來存儲模板圖像。毫不奇怪,神經網絡比基于內存的方法需要更少的內存。總體性能取決于許多因素,包括準確性、運行時間和內存要求。
隨著計算機技術的進步,更大容量的識別器變得可行。更大的識別器反過來需要更大的訓練集。 LeNet-1 適合 1989 年的可用技術,就像 LeNet-5 適合現在一樣。
1989 年,像 LeNet-5 這樣復雜的識別器需要數周的訓練,并且數據量超出了可用數據,因此甚至沒有被考慮。在相當長的一段時間里,LeNet-1 被認為是最先進的。開發了局部學習分類器、最佳邊緣分類器和切線距離分類器來改進 LeNet-1,并且他們在這方面取得了成功。然而,他們反過來又促使人們尋求改進的神經網絡架構。這種搜索部分是通過對各種學習機器的能力的估計來指導的,這些能力是根據訓練和測試誤差的測量結果得出的,作為訓練樣本數量的函數。我們發現需要更多的容量。通過一系列架構上的實驗,結合識別錯誤的特征分析,精心設計了LeNet-4和LeNet-5。
我們發現提升可以顯著提高準確性,并且內存和計算費用的損失相對較小。此外,失真模型可用于增加數據集的有效大小,而實際上不需要收集更多數據。
支持向量機具有出色的準確性,這是最引人注目的,因為與其他高性能分類器不同,它不包含有關問題的先驗知識。事實上,如果圖像像素用固定映射進行排列并丟失其圖像結構,則該分類器也能起到同樣的作用。然而,要達到與卷積神經網絡相當的性能水平,只能在內存和計算要求方面付出相當大的代價。簡化集 SVM 要求在卷積網絡的兩倍以內,并且錯誤率非常接近。由于該技術相對較新,因此預計這些結果會有所改善。
當有大量數據可用時,許多方法都可以獲得相當高的準確性。與基于內存的技術相比,神經網絡方法運行速度更快,所需空間也少得多。隨著訓練數據庫規模的不斷增大,神經網絡的優勢將變得更加引人注目。
E. 不變性和抗噪性
卷積網絡特別適合識別或拒絕大小、位置和方向變化很大的形狀,例如現實世界字符串識別系統中啟發式分段器通常生成的形狀。
在上述實驗中,抗噪性和失真不變性的重要性并不明顯。大多數實際應用中的情況是完全不同的。在識別之前,通常必須將字符從其上下文中分割出來。分割算法很少是完美的,并且經常在字符圖像中留下無關的標記(噪聲、下劃線、相鄰字符),或者有時過多地剪切字符并產生不完整的字符。這些圖像無法可靠地進行尺寸標準化和居中。規范化不完整的字符可能非常危險。例如,放大的雜散標記可能看起來像真正的 1。因此,許多系統已采取在字段或單詞級別對圖像進行標準化的方法。在我們的例子中,檢測整個區域的上下輪廓(支票中的金額)并用于將圖像標準化為固定高度。雖然這保證了雜散標記不會被放大成看起來像字符的圖像,但這也會在分割后造成字符大小和垂直位置的廣泛變化。因此,最好使用對此類變化具有魯棒性的識別器。圖 13 顯示了 LeNet-5 正確識別的幾個扭曲字符的示例。據估計,對于高達約2倍的比例變化、正負約一半字符高度的垂直移位變化以及高達正負30度的旋轉,會發生準確的識別。
雖然復雜形狀的完全不變性識別仍然是一個難以實現的目標,但卷積網絡似乎為幾何扭曲的不變性或魯棒性問題提供了部分答案。
圖 13 包括 LeNet5 在極其嘈雜的條件下的魯棒性示例。處理這些圖像會給許多方法帶來難以克服的分割和特征提取問題,但 LeNet-5 似乎能夠從這些雜亂的圖像中穩健地提取顯著特征。此處所示網絡使用的訓練集是添加了椒鹽噪聲的 MNIST 訓練集。每個像素以 0.1 的概率隨機反轉。有關 LeNet-5 實際應用的更多示例,請訪問互聯網:http://www.research.att.com/~yann/ocr。







)




連接云服務器 HomeAssistant + MQTT 物聯網平臺)






