鞏固基礎,砥礪前行 。
只有不斷重復,才能做到超越自己。
能堅持把簡單的事情做到極致,也是不容易的。
mysql怎么優化 : MySQL的優化可以從以下幾個方面入手:
- 數據庫設計優化:合理設計表結構,選擇合適的數據類型,規范化表結構,避免冗余數據等。
- 索引優化:為經常查詢的列添加索引,合理選擇索引類型,避免使用過多的索引。
- SQL語句優化:避免使用SELECT *,使用JOIN代替子查詢,盡量避免使用LIKE和%等模糊查詢,使用EXPLAIN查看SQL語句執行計劃。
- 緩存優化:使用緩存來減少對數據庫的訪問次數,如使用Redis緩存熱門數據。
- 硬件優化:增加內存、優化磁盤I/O等,提高服務器的性能。
- 代碼優化:優化應用程序代碼,減少不必要的數據庫操作,避免頻繁的連接和關閉數據庫。
- 定期維護:定期備份數據、優化表、清理日志等,保持數據庫的穩定性和高效性。
數據庫怎么調優 : 數據庫調優是指通過優化數據庫的性能,提高其響應速度和處理能力,從而提高系統的整體性能和穩定性。以下是一些常見的數據庫調優方法:
1.優化查詢語句:盡量避免使用SELECT *等大量數據的查詢語句,使用索引查詢,避免JOIN查詢等。
2.優化索引:合理設計數據庫索引,刪除不必要的索引,使用覆蓋索引等。
3.優化表結構:合理設計表結構,避免使用大量的NULL值,避免使用過多的TEXT、BLOB類型的數據。
4.優化緩存:增加緩存大小,調整緩存策略,避免頻繁的I/O操作。
5.優化參數設置:根據實際情況調整數據庫的參數設置,如緩沖池大小、連接數、查詢緩存等。
6.優化存儲引擎:選擇合適的存儲引擎,如MyISAM、InnoDB等。
7.分區和分表:對于大型數據庫,可以根據數據的特點進行分區和分表,提高查詢效率和可維護性。
8.定期維護:定期進行數據庫的備份、清理和優化,避免數據紊亂和性能下降。
總之,數據庫調優需要根據具體情況進行定制化的優化方案,綜合考慮數據庫的硬件環境、軟件配置、應用需求等因素。
Mysql慢查詢該如何優化?
1.檢查是否走了索引,如果沒有則優化SQL利用索引
2.檢查所利用的索引,是否是最優索引
3.檢查所查字段是否都是必須的,是否查詢了過多字段,查出了多余數據
4.檢查表中數據是否過多,是否應該進行分庫分表了
5.檢查數據庫實例所在機器的性能配置,是否太低,是否可以適當增加資源
Mysql鎖有哪些,如何理解
按鎖粒度分類:
1.行鎖:鎖某行數據,鎖粒度最小,并發度高
2.表鎖:鎖整張表,鎖粒度最大,并發度低
3.間隙鎖:鎖的是一個區間
還可以分為:
1.共享鎖:也就是讀鎖,一個事務給某行數據加了讀鎖,其他事務也可以讀,但是不能寫
2.排它鎖:也就是寫鎖,一個事務給某行數據加了寫鎖,其他事務不能讀,也不能寫
還可以分為:
1.樂觀鎖:并不會真正的去鎖某行記錄,而是通過一個版本號來實現的
2.悲觀鎖:上面所的行鎖、表鎖等都是悲觀鎖
在事務的隔離級別實現中,就需要利用所來解決幻讀
鎖的類型有哪些
基于鎖的屬性分類:共享鎖、排他鎖。
基于鎖的粒度分類:行級鎖(INNODB)、表級鎖(INNODB、MYISAM)、頁級鎖(BDB引擎)、記錄鎖、間隙鎖、臨鍵
鎖。
基于鎖的狀態分類:意向共享鎖、意向排它鎖。
,共享鎖(Share Lock)
共享鎖又稱讀鎖,簡稱S鎖;當一個事務為數據加上讀鎖之后,其他事務只能對該數據加讀鎖,而不能對數據加寫鎖,直到所有的讀鎖釋放之后其他事務才能對其進行加持寫鎖。共享鎖的特性主要是為了支持并發的讀取數據,讀取數據的時候不支持修改,避免出現重復讀的問題。
排他鎖(exclusive Lock)
排他鎖又稱寫鎖,簡稱X鎖;當一個事務為數據加上寫鎖時,其他請求將不能再為數據加任何鎖,直到該鎖釋放之后,其他事務才能對數據進行加鎖。排他鎖的目的是在數據修改時候,不允許其他人同時修改,也不允許其他人讀取。避免了出現臟數據和臟讀的問題。
表鎖
表鎖是指上鎖的時候鎖住的是整個表,當下一個事務訪問該表的時候,必須等前一個事務釋放了鎖才能進行對表進行
訪問;
特點:
粒度大,加鎖簡單,容易沖突;
行鎖
行鎖是指上鎖的時候鎖住的是表的某一行或多行記錄,其他事務訪問同一張表時,只有被鎖住的記錄不能訪問,其他
的記錄可正常訪問;
特點:粒度小,加鎖比表鎖麻煩,不容易沖突,相比表鎖支持的并發要高;
記錄鎖(Record Lock)
記錄鎖也屬于行鎖中的一種,只不過記錄鎖的范圍只是表中的某一條記錄,記錄鎖是說事務在加鎖后鎖住的只是表的
某一條記錄。
精準條件命中,并且命中的條件字段是唯一索引
加了記錄鎖之后數據可以避免數據在查詢的時候被修改的重復讀問題,也避免了在修改的事務未提交前被其他事務讀
取的臟讀問題。
頁鎖
頁級鎖是MySQL中鎖定粒度介于行級鎖和表級鎖中間的一種鎖。表級鎖速度快,但沖突多,行級沖突少,但速度慢。
所以取了折衷的頁級,一次鎖定相鄰的一組記錄。
特點:開銷和加鎖時間界于表鎖和行鎖之間;會出現死鎖;鎖定粒度界于表鎖和行鎖之間,并發度一般
間隙鎖((Gap Lock)
屬于行鎖中的一種,間隙鎖是在事務加鎖后其鎖住的是表記錄的某一個區間,當表的相鄰ID之間出現空隙則會形成一
個區間,遵循左開右閉原則。
范圍查詢并且查詢未命中記錄,查詢條件必須命中索引、間隙鎖只會出現在REPEATABLE_READ(重復讀)的事務級別
中。
觸發條件:防止幻讀問題,事務并發的時候,如果沒有間隙鎖,就會發生如下圖的問題,在同一個事務里,A事務的兩次查詢出的結果會不一樣。
比如表里面的數據ID為1,4,5,7,10,那么會形成以下幾個間隙區間,-n-1區間,1-4區間,7-10區間,10-n區
間(一n代表負無窮大,n代表正無窮大)
臨建鎖(Next-Key Lock)
也屬于行鎖的一種,并且它是INNODB的行鎖默認算法,總結來說它就是記錄鎖和間隙鎖的組合,臨鍵鎖會把查詢出來
的記錄鎖住,同時也會把該范圍查詢內的所有間隙空間也會鎖住,再之它會把相鄰的下一個區間也會鎖住
觸發條件:范圍查詢并命中,查詢命中了索引。結合記錄鎖和問隙鎖的特性,臨鍵鎖避免了在范圍查詢時出現臟讀、重復讀、幻讀問題。加了臨鍵鎖之后,在范圍區間內數據不允許被修改和插入。
如果當事務A加鎖成功之后就設置一個狀態告訴后面的人,已經有人對表里的行加了一個排他鎖了,你們不能對整個表加共享鎖或排它鎖了,那么后面需要對整個表加鎖的人只需要獲取這個狀態就知道自己是不是可以對表加鎖,避免了對整個索引樹的每個節點掃描是否加鎖,而這個狀態就是意向鎖。
意向共享鎖
當一個事務試圖對整個表進行加共享鎖之前,首先需要獲得這個表的意向共享鎖。
意向排他鎖
當一個事務試圖對整個表進行加排它鎖之前,首先需要獲得這個表的意向排它鎖。
B樹和B+樹的區別,為什么Mysql使用B+樹
B樹的特點:
1.節點排序
2.一個節點了可以存多個元素,多個元素也排序了
B+樹的特點:1.擁有B樹的特點2.葉子節點之間有指針
3.非葉子節點上的元素在葉子節點上都冗余了,也就是葉子節點中存儲了所有的元素,并且排好順序
B樹和B+樹的區別,為什么Mysql使用B+樹
B樹的特點:
1.節點排序
2.一個節點了可以存多個元素,多個元素也排序了
B+樹的特點:1.擁有B樹的特點2.葉子節點之間有指針
3.非葉子節點上的元素在葉子節點上都冗余了,也就是葉子節點中存儲了所有的元素,并且排好順序
Mysql索引使用的是B+樹,因為索引是用來加快查詢的,而B+樹通過對數據進行排序所以是可以提高查詢速度的,然后通過一個節點中可以存儲多個元素,從而可以使得B+樹的高度不會太高,在Mysql中一個Innodb頁就是一個B+樹節點,一個Innodb頁默認16kb,所以一般情況下一顆兩層的B+樹可以存2000萬行左右的數據,然后通過利用B+樹葉子節點存儲了所有數據并且進行了排序,并且葉子節點之間有指針,可以很好的支持全表掃描,范圍查找等SQL語句。
mysql聚簇和非聚簇索引的區別
都是B+樹的數據結構
聚簇索引:將數據存儲與索引放到了一塊、并且是按照一定的順序組織的,找到索引也就找到了數據,數據的物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那么對應的數據一定也是相鄰地存放在磁盤上的非聚簇索引:葉子節點不存儲數據、存儲的是數據行地址,也就是說根據索引查找到數據行的位置再取磁盤查找數據,這個就有點類似一本樹的目錄,比如我們要找第三章第一節,那我們先在這個目錄里面找,找到對應的頁碼后再去對應的頁碼看文章。
優勢:
1、查詢通過聚簇索引可以直接獲取數據,相比非聚簇索引需要第二次查詢(非覆蓋索引的情況下)效率要高
2、聚簇索引對于范圍查詢的效率很高,因為其數據是按照大小排列的
3、聚簇索引適合用在排序的場合,非聚簇索引不適合
劣勢:
1、維護索引很昂貴,特別是插入新行或者主鍵被更新導至要分頁(page sp1it)的時候。建議在大量插入新行后,選在負載較低的時間段,通過OPTIMIZE TABLE優化表,因為必須被移動的行數據可能造成碎片。使用獨享表空間可以弱化碎片
2、表因為使用UUId(隨機ID)作為主鍵,使數據存儲稀疏,這就會出現聚族索引有可能有比全表掃面更慢,所以建
議使用int的auto_increment作為主鍵
3、如果主鍵比較大的話,那輔助索引將會變的更大,因為輔助索引的葉子存儲的是主鍵值;過長的主鍵值,會導致非
葉子節點占用占用更多的物理空間
InnoDB中一定有主鍵,主鍵一定是聚簇索引,不手動設置、則會使用unique索引,沒有unique索引,則會使用
數據庫內部的一個行的隱藏id來當作主鍵索引。在聚簇索引之上創建的索引稱之為輔助索引,輔助索引訪問數據總是需要二次查找,非聚簇索引都是輔助索引,像復合索引、前綴索引、唯一索引,輔助索引葉子節點存儲的不再是行的物理位置,而是主鍵值
MyISM使用的是非聚簇索引,沒有聚簇索引,非聚簇索引的兩棵B+樹看上去沒什么不同,節點的結構完全一致只是存儲的內容不同而已,主鍵索引B+樹的節點存儲了主鍵,輔助鍵索引B+樹存儲了輔助鍵。表數據存儲在獨立的地方,這兩顆B+樹的葉子節點都使用一個地址指向真正的表數據,對于表數據來說,這兩個鍵沒有任何差別。由于索引樹是獨立的,通過輔助鍵檢索無需訪問主鍵的索引樹。
如果涉及到大數據量的排序、全表掃描、count之類的操作的話,還是MyISAM占優勢些,因為索引所占空間小,
這些操作是需要在內存中完成的。
聚簇索引與非聚集索引的特點是什么?
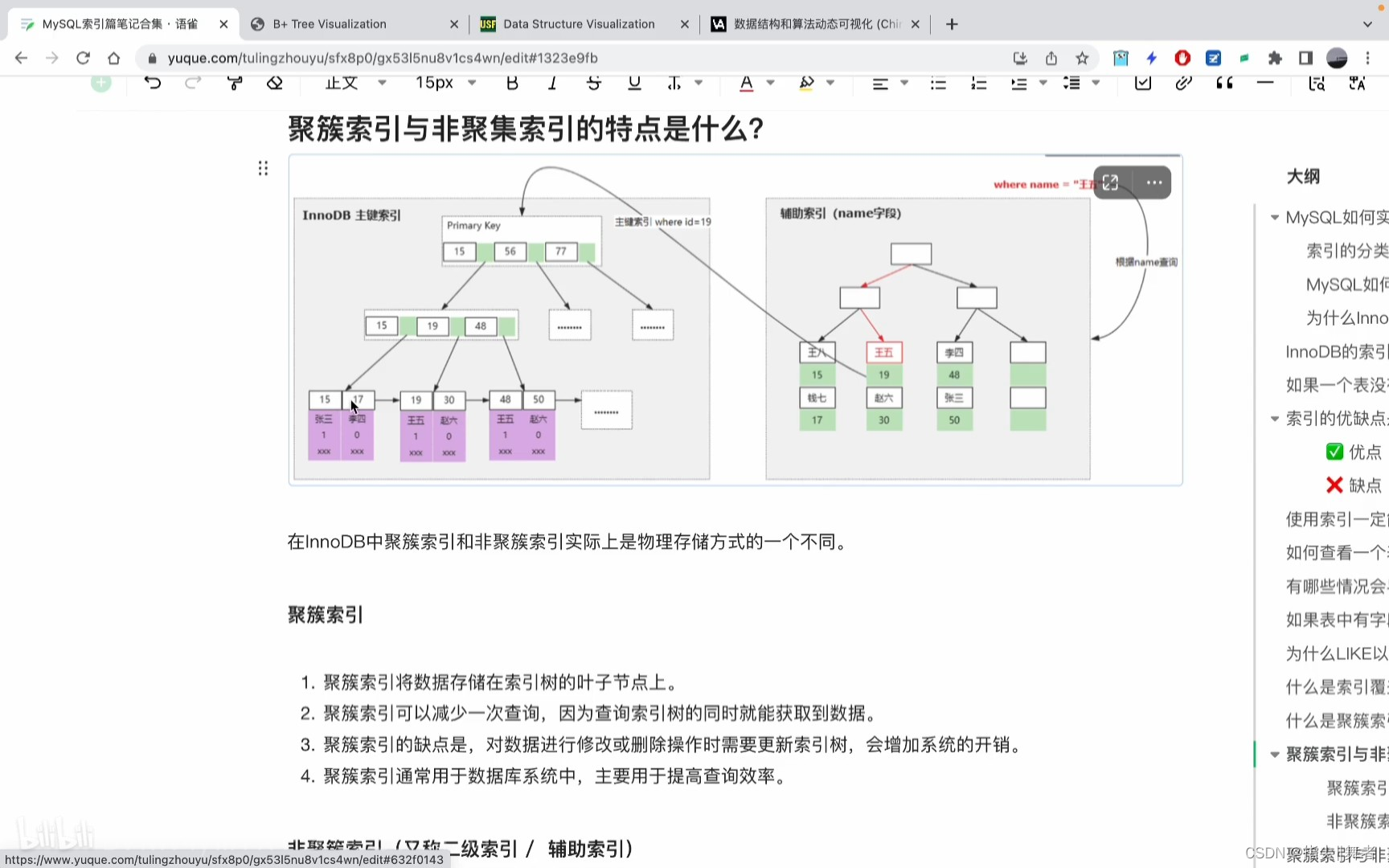
在InnoDB中聚簇索引和非聚簇索引實際上是物理存儲方式的一個不同。
聚簇索引
1.聚簇索引將數據存儲在索引樹的葉子節點上。
2.聚簇索引可以減少一次查詢,因為查詢索引樹的同時就能獲取到數據。
3.聚簇索引的缺點是,對數據進行修改或刪除操作時需要更新索引樹,會增加系統的開銷。
4.聚簇索引通常用于數據庫系統中,主要用于提高查詢效率。
非聚簇索引(又稱二級索引/輔助索引)
1.非聚簇索引不將數據存儲在索引樹的葉子節點上,而是存儲在數據頁中。
2.非聚簇索引在查詢數據時需要兩次查詢,一次查詢索引樹,獲取數據頁的地址,再通過數據頁的地址查詢數據(通常情況下來說是的,但如果索引覆蓋的話實際上是不用回表的)
3.非聚簇索引的優點是,對數據進行修改或刪除操作時不需要更新索引樹,減少了系統的開銷。
4.非聚簇索引通常用于數據庫系統中,主要用于提高數據更新和刪除操作的效率。
什么是Hash索引?
哈希索引(hash index)基于哈希表實現。哈希索引通過Hash算法將數據庫的索引列數據轉換成定長的哈希碼作
為key,將這條數據的行的地址作為value一并存入Hash表的對應位置。
在MySQL中,只有Memeory引擎顯式的支持哈希索引,這也是Memory引擎表的默認索引結構,Memeory同時也支持B-Tree索引。并且,Memory引擎支持非唯一哈希索引,如果多個列的哈希值相同(或者發生了Hash碰撞),索引會在對應Hash鍵下以鏈表形式存儲多個記錄地址。
::哈希索引還有如下特點:
哈希索引不支持部分索引列的匹配查找,因為哈希索引始終是使用索引列的全部內容來計算哈希值的。例
如,在數據列(A,B)上建立哈希索引,如果查詢只有數據列A,則無法使用該索引。
哈希索引具有哈希表的特性,因此只有精確匹配所有列的查詢對于哈希索引才有效,比如=、<>、IN(,因為
數據的存儲是無序的),且無法使用任何范圍查詢。
因為數據的存儲是無序的,哈希索引還無法用于排序。
對于精確查詢,則哈希索引效率很高,時間復雜度為O(1),除非有很多哈希沖突(不同的索引列有相同的哈希值),如果發生哈希沖突,則存儲引擎必須遍歷鏈表中的所有數據指針,逐行比較,直到找到所有符合條件的行。哈希沖突越多,代價就越大!
InnoDB到底支不支持哈希索引?
對于InnoDB的哈希索引,確切的應該這么說:
?InnoDB用戶無法手動創建哈希索引,這一層上說,InnoDB確實不支持哈希索引;
InnoDB會自調優(self-tuning),如果判定建立自適應哈希索引(Adaptive HashIndex,AHI),能夠提升查詢
效率,InnoDB自己會建立相關哈希索引,這一層上說,InnoDB又是支持哈希索引的;
那什么是自適應哈希索引(Adaptive Hash Index,AHI)呢?
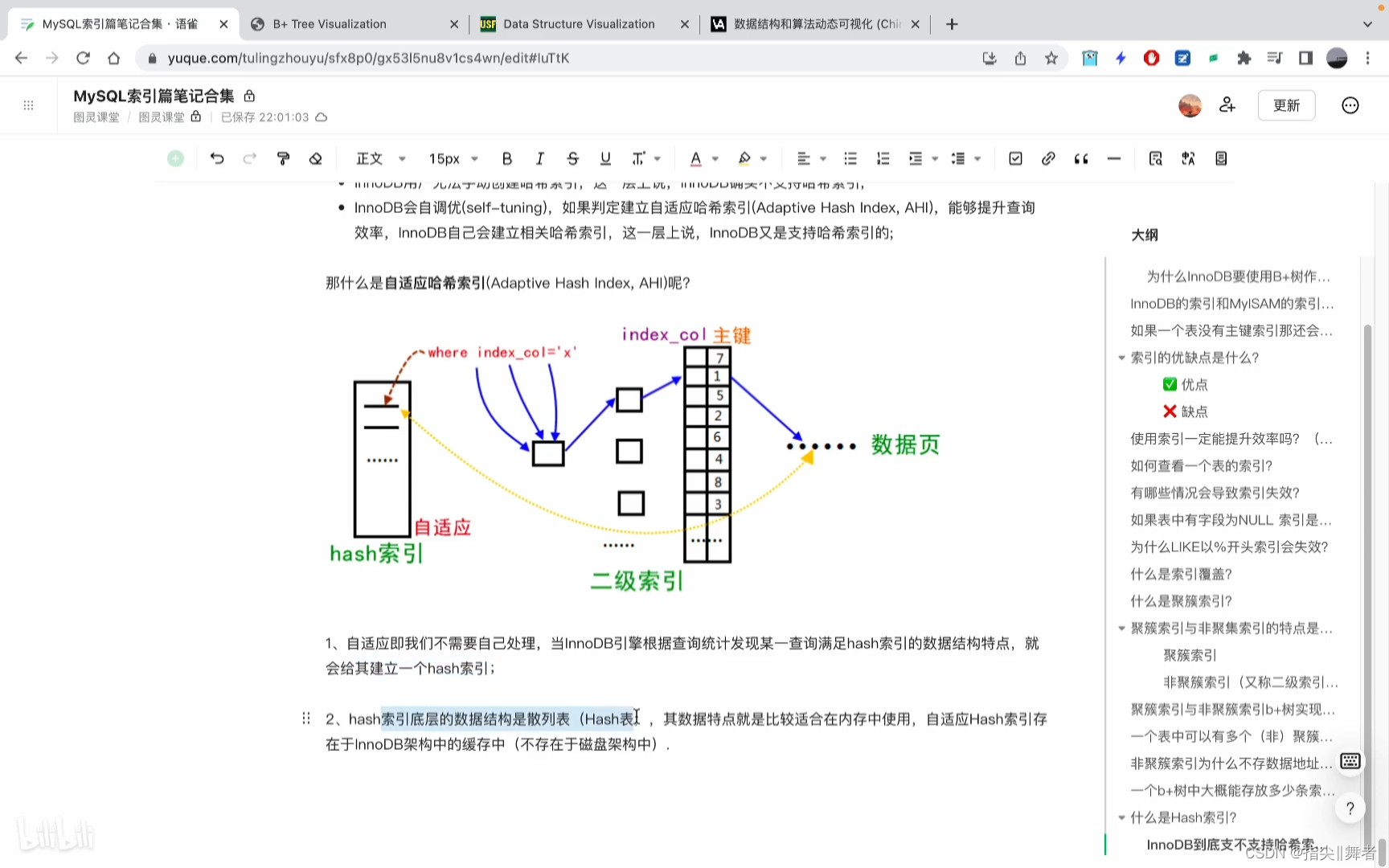
1、自適應即我們不需要自己處理,當InnoDB引擎根據查詢統計發現某一查詢滿足hash索引的數據結構特點,就
會給其建立一個hash索引;
2、hash索引底層的數據結構是散列表(Hash表,其數據特點就是比較適合在內存中使用,自適應Hash索引存
在于InnoDB架構中的緩存中(不存在于磁盤架構中)
什么是唯一索引?
講起來非常簡單,其實和“普通索引"類似,不同的就是:索引列的值必須唯一,但允許有空值。可以是單列
唯一索引,也可以是聯合唯一索引。
最大的所用就是確保寫入數據庫的數據是唯一值
什么時候應該使用唯一索引呢?
我們前面講了唯一索引最大的好處就是能保證唯一性。看似沒什么太大的價值,可能就會有同學說,我業務層做一個重復檢查不就好了。問題就在這個地方,“業務是無法確保唯一性的”,除非你說你的代碼沒有BUG。很多時候業務場景需要保證唯一性,如果不在數據庫加限制的話,總有一天會出現臟數據。
那又有同學就說了,既然你不想重復你可以使用主鍵索引。這個回答也很有意思。
我們確實可以通過主鍵索引來保證唯一,但是,如果你的數據不能保證有序插入。比如說身份證字段,
你如果用身份證字段作為主鍵的話,會導致查詢效率降低。
唯一索引還有一個好處就是可以為空,真實的業務場景肯定是可以保證身份證為空的,如果沒有綁定身
份證就不讓注冊好像也有點說不過去。
聚簇索引的原理就不在這里細講了,會有一個單獨的章節來介紹。
唯一索引是否會影響性能呢?
我找們通過和普通索引來做一個對比,有查詢和插入兩個場懸
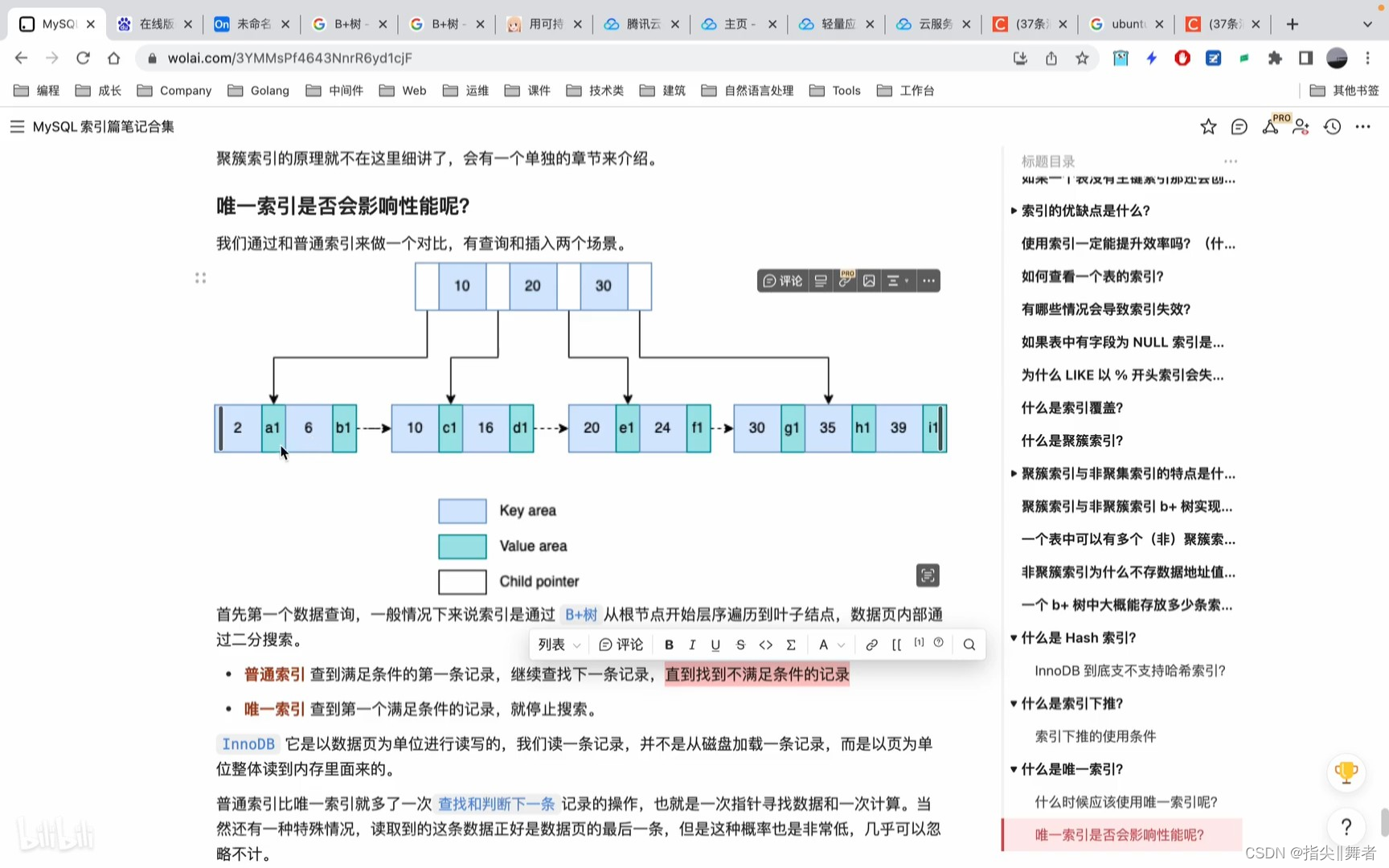
首先第一個數據查詢,一般情況下來說索引是通過 B+樹 從根節點開始層序遍歷到葉子結點,數據頁內部通過二分檢索
普通索引查到滿足條件的第一條記錄,繼續查找下一條記錄,直到找到不滿足條件的記錄
唯一索引 查到第一個滿足條件的記錄,就停止搜索。
InnoDB它是以數據頁為單位進行讀寫的,我們讀一條記錄,并不是從磁盤加載一條記錄,而是以頁為單
普通索引比唯一索引就多了一次 查找和判斷下一條 記錄的操作,也就是一次指針尋找數據和一次計算。當然還有一種特殊情況,讀取到的這條數據正好是數據頁的最后一條,但是這種概率也是非常低,幾乎可以忽略不計。
整體看下來看上去性能差距并不大對吧.
來看第二個更新的性能,我們按照上面圖上的例子在 2 和6 之間插入一個 3.
在內存中
普通索引找到2和6之間的位置→插入值→
·唯一索引找到衛和6之間的位置→當判斷有沒有沖突→插入值→結束
不在內存中
普通索引 將更新記錄在 change buffer→結束
?唯一索引 將數據頁讀入內存→當判斷到沒有沖突→插入值→結束
數據讀取到內存涉及了隨機|O訪問,這是在數據庫里面成本最高的操作之一,
而change buffer就可以減少這種隨機磁盤訪問,所以性能提示比較明顯。所以在這一塊來說,如果兩者在業務場景下都能滿足時可以優先考慮使用普通索引。
什么是聯合索引,組合索引,復合索引?
我們在索引回顧的時候和大家對索引做了一個分類對吧,按照字段個數來分的話,就分為了單列索引和組合
索引對吧。那么他們之間的特點是什么呢?我們來看
,單列索引 一個索引只包含了一個列,一個表里面可以有多個單加要2,但早這不叫組各思己
?組合索引(聯合索引&復合索引)一個索引包含多個列。
看上去感覺這組合索引并沒有太大作用是吧,我一個列已經有一個索引了,我還要這組合索引干嘛?
真相往往不那么簡單,首先我們得承認我們的業務千變萬化,我們的查詢語句條件肯定是非常多的。
高效率如果說只有單列索引,那就會涉及多次二級索引樹查找,再加上回表,性能相對于聯合索引來說
是比較低的。
減少開銷 我們要記得創建索引是存在空間開銷的,對于大數據量的表,使用聯合索引會降低空間開銷。
索引覆蓋 如果組合索引索引值已經滿足了我們的查詢條件,那么就不會進行回表,直接返回。
但是我們按照我們的查詢條件去創建一個聯合索引的話,就避免了上面的問題
那么聯合索引是怎么工作的
呢?
這里涉及到了一個重點,叫做 最左前綴,簡單理解就是只會從最左邊開始組合,組合索引的第一個字段必須出現在查詢組句中,還不能跳躍,只有這樣才能讓索引生效,比如說我查詢條件里面有組合索引里面的第二個字段,那么也是不會走組合索引的。舉個例子
SQL
// 假設給username,age創建了組合索引
// 這兩種情況是會走索引的
select * from user where username ='張三
select * from user where username
// 這種是不會走索引的
select * from user where age =18
select * from user where city
'北京
and age=18
and age
18
復合索引創建時字段順序不一樣使用效果一樣嗎?
SQL
// 特殊情況,這種也是會走索引的,雖然我的age在前面,username在后面。
// 剛剛不是手最左前綴匹配嗎,為什么放到第二位也可以呢?
// 雖說順序不一致,但是在SQL執行過程中,根據查詢條件命中索引,//無論我username在不在前面,都會按照username去進行索引查找。select * from user where age = 18 and username =
‘張三
mysql索引的數據結構,各自優劣
索引的數據結構和具體存儲引擎的實現有關,在MySQL中使用較多的索引有Hash索引,B+樹索引等,InnoDB存儲引擎的默認索引實現為:B+樹索引。對于哈希索引來說,底層的數據結構就是哈希表,因此在絕大多數需求為單條記錄查詢的時候,可以選擇哈希索引,查詢性能最快;其余大部分場景,建議選擇BTree索引。
B+樹:
B+樹是一個平衡的多叉樹,從根節點到每個葉子節點的高度差值不超過1,而且同層級的節點間有指針相互鏈接。在B+樹上的常規檢索,從根節點到葉子節點的搜索效率基本相當,不會出現大幅波動,而且基于索引的順序掃描時,也可以利用雙向指針快速左右移動,效率非常高。因此,B+樹索引被廣泛應用于數據庫、文件系統等場景。
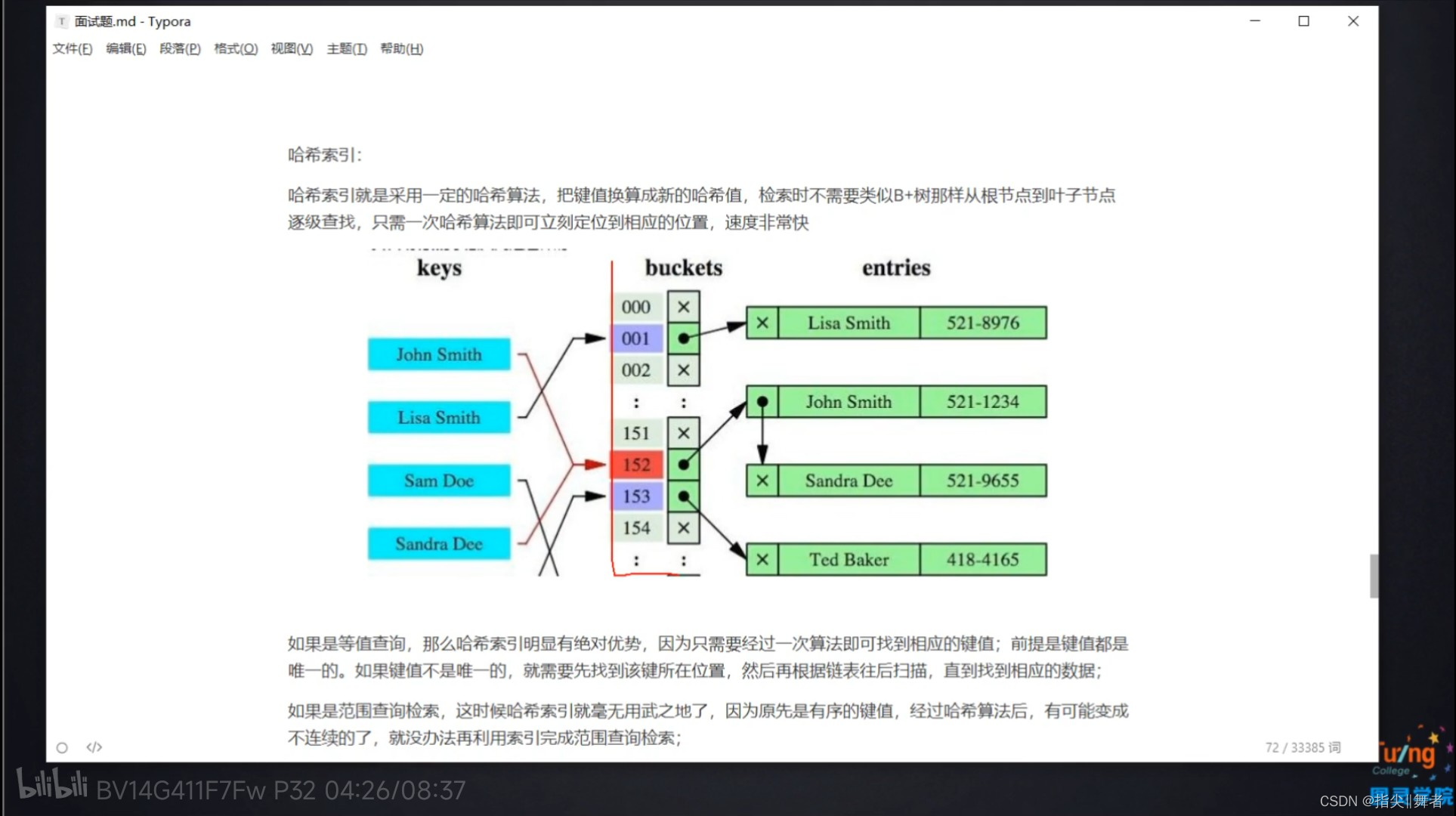
哈希索引:
哈希索引就是采用一定的哈希算法,把鍵值換算成新的哈希值,檢索時不需要類似B+樹那樣從根節點到葉子節點
逐級查找,只需一次哈希算法即可立刻定位到相應的位置,速度非常快
如果是等值查詢,那么哈希索引明顯有絕對優勢,因為只需要經過一次算法即可找到相應的鍵值;前提是鍵值都是
唯一的。如果鍵值不是唯一的,就需要先找到該鍵所在位置,然后再根據鏈表往后掃描,直到找到相應的數據;
如果是范圍查詢檢索,這時候哈希索引就毫無用武之地了,因為原先是有序的鍵值,經過哈希算法后,有可能變成
不連續的了,就沒辦法再利用索引完成范圍查詢檢索;
哈希素引也沒辦法利用索引完成排序,以及likexxx%這樣的部分模糊查詢(這種部分模糊查詢,其實本質上也是
范圍查詢);
哈希索引也不支持多列聯合索引的最左匹配規則;
B+樹索引的關鍵字檢索效率比較平均,不像B樹那樣波動幅度大,在有大量重復鍵值情況下,哈希索引的效率也是
極低的,因為存在哈希碰撞問題。
Innodb是如何實現事務的
Innodb通過Buffer Pool,LogBuffer,Redo Log,Undo Log來實現事務,以一個update語句為例:1.Innodb在收到一個update語句后,會先根據條件找到數據所在的頁,并將該頁緩存在Buffer Pool中2.執行update語句,修改Buffer Pool中的數據,也就是內存中的數據
3.針xupdate語句生成一個RedoLog對象,并存入LogBuffer中
4.針對update語句生成undolog日志,用于事務回滾
5.如果事務提交,那么則把RedoLog對象進行持久化,后續還有其他機制將Buffer Pool中所修改的數據頁持久化到磁盤中
6.如果事務回滾,則利用undolog日志進行回滾
mysql left join中on后加條件判斷和where中加條件的區別
left join中關于where和on條件的幾個知識點:
1.多表left join是會生成一張臨時表,并返回給用戶
2.where條件是針對最后生成的這張臨時表進行過濾,過濾掉不符合where條件的記錄,是真正的不符合就過濾掉。
3.on條件是對left join的右表進行條件過濾,但依然返回左表的所有行,右表中沒有的補為NULL
4.on條件中如果有對左表的限制條件,無論條件真假,依然返回左表的所有行,但是會影響右表的匹配值。也就是說on中左表的限制條件只影響右表的匹配內容,不影響返回行數。
結論:
1.where條件中對左表限制,不能放到on后面
2.where條件中對右表限制,放到on后面,會有數據行數差異,比原來行數要多
ACID靠什么保證的?
A原子性由undo log日志保證,它記錄了需要回滾的日志信息,事務回滾時撤銷已經執行成功的sql
C一致性由其他三大特性保證、程序代碼要保證業務上的一致性
|隔離性由MVCC來保證
D持久性由內存+redo log來保證,mysql修改數據同時在內存和redolog記錄這次操作,宕機的時候可以從redo
log恢復
InnoDB redo 1og 寫盤,InnoDB 事務進入prepare狀態。
如果前面 prepare 成功,bin1og 寫盤,再繼續將事務日志持久化到bin1og,如果持久化成功,那么 InnoDB 事務
則進入 commit 狀態(在 redo 1og 里面寫一個 commit 記錄)
redolog的刷盤會在系統空閑時進行
MySQL的索引結構是什么樣的?聚簇索引和非聚簇索引又是什么?
二叉樹-》 AVL樹-》 紅黑樹-》 B-樹-》 B+樹
二叉樹:每個節點最多只有兩個子節點,左邊的子節點都比當前節點小,右邊的子節點都比當前節點大。
AVL樹: 樹中任意節點的兩個子樹的高度差最大為1
紅黑樹:1、每個節點都是紅色或者黑色。2 根節點是黑色。3 每個葉子節點都是黑色的空節點。4 紅色節點的父子節點都必
須是褐色。5 從任一節點到其每個葉子節點的所有路徑都包含相同的黑色節點。
B-樹:1、B-樹的每個非葉子節點的子節點個數都不會超過D(這個D就是B-樹的階)2、所有的葉子節點都在同一層。3.所有
節點關鍵字都是按照遞增順序排列。
B+樹: 1、非葉子節點不存儲數據,只進行數據索引。2、所有數據都存儲在葉子節點當中。3、每個葉子節點都存有相鄰葉
子節點的指針。4、葉子節點按照本身關鍵字從小到大排序。
聚簇索引就是數據和索引是在一起的。
MylSAM使用的是非聚簇索引,樹的子節點上的data不是數據本身,而是數據存放的地址。InnoDB采用的是聚簇索引,樹的
葉子節點上的data就是數據本身。
聚簇索引的數據物理存放順序和索引順序是一致的,所以一個表當中只能有一個聚簇索引,而非聚簇索引可以有多個。
InnoDB中,如果表定義了PK,那PK就是聚簇索引
如果沒有PK,就會找第一個非空的unique列作為聚簇索引。否則,
InnoDB會創建一個隱藏的row-i作為聚簇索引。
MySQL的覆蓋索引和回表
如果只需要在一顆索引樹上就可以獲取SQL所需要的所有列,就不需要再回表查詢,這樣查詢速度就可以更快。
實現索引覆蓋最簡單的方式就是將要查詢的字段,全部建立到聯合索引當中。
user (PK id, name ,sex)
select count(name) from user;->在name字段上建立一個索引。
select id,name ,sex from user; ->將name上的索引升級成為(name,sex)的聯合索引。
MySQL有哪幾種數據存儲引擎?有什么區別?
MySQL中通過show ENGINES指令可以看到所有支持的數據庫存儲引擎。 最為常用的就是MyISAM和InnoDB兩種。
MyISAM和InnDB的區別:
1、存儲文件。 MylSAM每個表有兩個文件。 MYD和MYISAM文件。 MYD是數據文件。 MYI是索引文件。而InnDB每個表
只有一個文件,idb。
2、LnnoDB支持事務,支持行級鎖,支持外鍵。
3、InnoDB支持XA事務
4、InnoDB支持savePoints
MySQL 基礎復習 三種存儲引擎的特點
1.create database aa;
2.show create database aa\G;
3.drop database aa; 刪除數據庫,mysql是不會有提示的,而且不能回復
4.show engines; sopport 表示該數據引擎是否能使用,yes表示可以,no表示不能,default表示該引擎是當前的默認引擎。
5.mysql數據庫引擎介紹:
5.1 InnoDB:
它是事務型數據庫的首選引擎,支持事務安全表(提供了提交、回滾、奔潰的恢復能力),支持行鎖和外鍵。
在mysql5.5之后,他就是mysql的默認數據庫引擎。 InnoDB 鎖定在行級 并且 也在select語句中提供了一個類似oracle的非鎖定讀。
InnoDB能夠處理大數據量的數據。
InnoDB存儲引擎完全和mysql服務器整合,InnoDB為在主內存中緩存數據和索引而維護他自己的緩存池。
InnoDB中的表和縮影存儲在一個邏輯空間中,表中可以包含多個數據文件或者原始磁盤分區。 這一點和 MyISAM不同,MyISAM單個表中存放在分離的文件中。
InnoDB表可設置任何尺寸。
InnoDB支持外鍵完整性約束。存儲表中的數據時,按照表中的住建順序存放,如果沒有主鍵,他會為每行數據創建一個6B的rowId,以此作為行記錄的主鍵。
InnoDB用在需要高性能的大型數據庫的地方。
InnoDB不會創建目錄,MySQL 在她的數據目錄下創建一個可以動態擴容的 名為ibdata1的 大小為10M的數據文件,創建兩個5M的數據庫日志文件,ib_logfile0和ib_logfile01.
5.2 MyISAM
MyISAM具有較高的查詢、插入速度。不支持事務,它是mysql5.5之前的版本默認的數據庫。
支持大文件在支持大文件的系統上被支持。
當insert update delete 混合使用時,動態尺寸的行產生更少的碎片。
單表最大索引數是64,可以通過編譯改變.每個索引最大的列是16列
最大的鍵長是100B ,可以通過編譯改變,
blob和text 列可以被索引
null值可以出現在索引中
所有的鍵值以高字節優先被存儲以允許一個更高的索引壓縮
表中的自增長列的內部處理,insert 和 update 操作自動更新這一列,這使得自增長(auto_increment)列更快。在序列頂的值悲傷出后就不再使用了
可以把數據文件和索引文件放在不同的位置
每個字符列可以有不同的字符集
有varchar的表可以固定或者動態記錄長度
varchar 和 char 列可以多達64K
使用MyISAM創建數據庫,產生三個文件,文件名以表名開始,.frm 文件存儲表定義 、.myd 文件存儲數據 、.myi存儲索引
5.3 memory
它把表中的數據存放在內存中
memory表中可以有32個索引、每個索引可以有16列,以及500B的最大鍵長度
支持存儲hash和bree索引
可以在memory表中有非唯一鍵
不支持blob和text
支持自增長列和對包含null值列的索引
memory表在所有客戶端之間共享
MySQL 數據表基本操作
?
1.在創建表的時候定義主鍵
create table aa{
id int(10) primary key auto_incremnt,
name varchar(10)
};
指定索引從哪里開始:alter table aa AUTO_INCREMENT=123456
2.定義完列之后申明主鍵
create table aa{
id int(10) ,
name varchar(10),
primary key(id)
};
- 追加
alter table aa add primary key(id);
-
一堆約束 外鍵約束 非空約束 唯一性約束
-
顯示表字段以及類型 desc aa
-
顯示建表語句 show create table aa\G
7.修改表名 alter table aa rename bb
- 修改字段類型 alter table aa modify name varchar(100)
9.修改列名 alter table aa change name newname varchar(10)
10 添加列 alter table aa add sex char(1) [first | after columnlname]
11 添加約束:alter table aa add nickname varchar(30) not null
12 刪除字段:alter table aa drop nickname
13 修改字段的位置:alter table aa modify name varchar(10) first | alter name
14 更改數據庫引擎:alter table aa engine = MyISAM
15 刪除表的外鍵:alter table aa drop foreign key name
16 drop table if exist aa
17 刪除有關聯的表:首先刪除關聯關系,然后在刪除對應的表:alter table aa drop foreign key fk_name; drop table aa;
MySQL 數據類型
?
MySQL 支持多種數據類型,主要有 數值類型、日期/時間、字符串等
數值類型:整數類型:tinyint(1)、smallint(2)、mediumint(3)、int(4)、bigint(8);浮點數據類型有:float(4)、double(8) ;指定小數類型:decimal(M,D) M+2個字節。無論是定點還是浮點,如果用戶指定的精度超出精度范圍,則會四舍五入進行處理。
時間日期類型:year(YYYY)、time(HH:MM:SS)、date(YYYY-MM-DD)、datetime(YYYY-MM-DD HH:MM:SS)、timestamp(YYYY-MM-DD HH:MM:SS)
字符串類型:char、varchar、binary、varbinary、blob、text、enum、set。字符串類型分為文本類型和二進制類型。
float(5,1)–>float(5.12) = 5.1
double(5,1)->double(5.15) = 5.2
decimal(5,1)->decimal(5.123) = 5.1
InnoDB的索引和MyISAM的索引有什么區別?
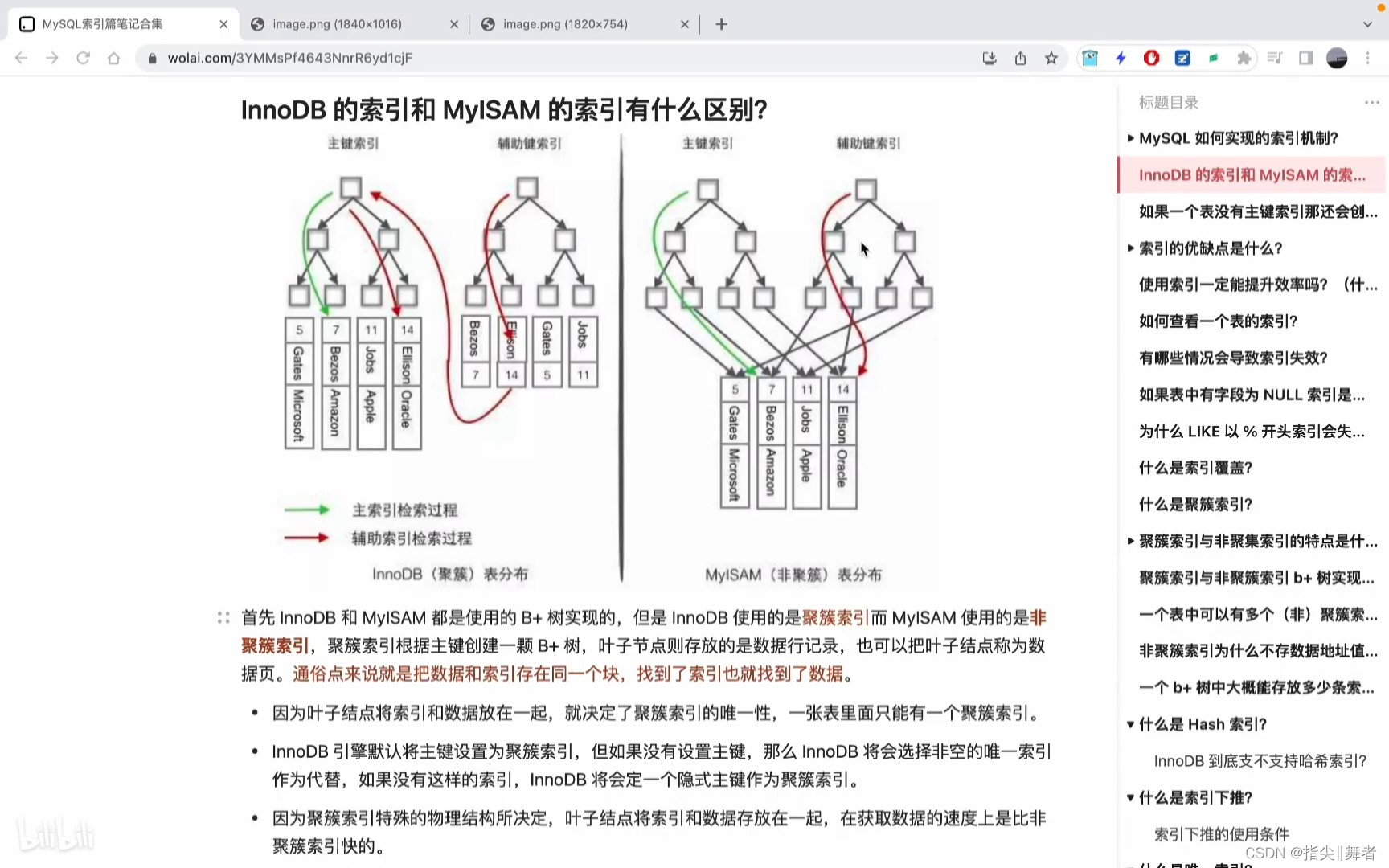
首先InnoDB和MyISAM都是使用的B+樹實現的,但是InnoDB使用的是聚簇索引而MyISAM使用的是非聚簇索引,聚簇索引根據主鍵創建一顆B+樹,葉子節點則存放的是數據行記錄,也可以把葉子結點稱為數據頁。通俗點來說就是把數據和索引存在同一個塊,找到了索引也就找到了數據。
·因為葉子結點將索引和數據放在一起,就決定了聚簇索引的唯一性,一張表里面只能有一個聚簇索引。InnoDB引擎默認將主鍵設置為聚簇索引,但如果沒有設置主鍵,那么InnoDB將會選擇非空的唯一索引作為代替,如果沒有這樣的索引,InnoDB將會定一個隱式主鍵作為聚簇索引。
因為聚簇索引特殊的物理結構所決定,葉子結點將索引和數據存放在一起,在獲取數據的速度上是比非
聚簇索引快的。
聚簇索引數據的存儲是有序的,在進行排序查找和范圍查找的速度也是非常快的。
A也正因為有序性,在數據插入時按照主鍵的順序插入是最快的,否則就會出現頁分裂等問題,嚴重
影響性能。對于InnoDB我們一般采用自增作為主鍵ID。
第二個問題主鍵最好不要進行更新,修改主鍵的代價非常大,為了保持有序性會導致更新的行移動,一
般來說我們通常設置為主鍵不可更新。
在這部分只介紹InnoDB和MyISAM主鍵索引的不同?輔助索引后面在說
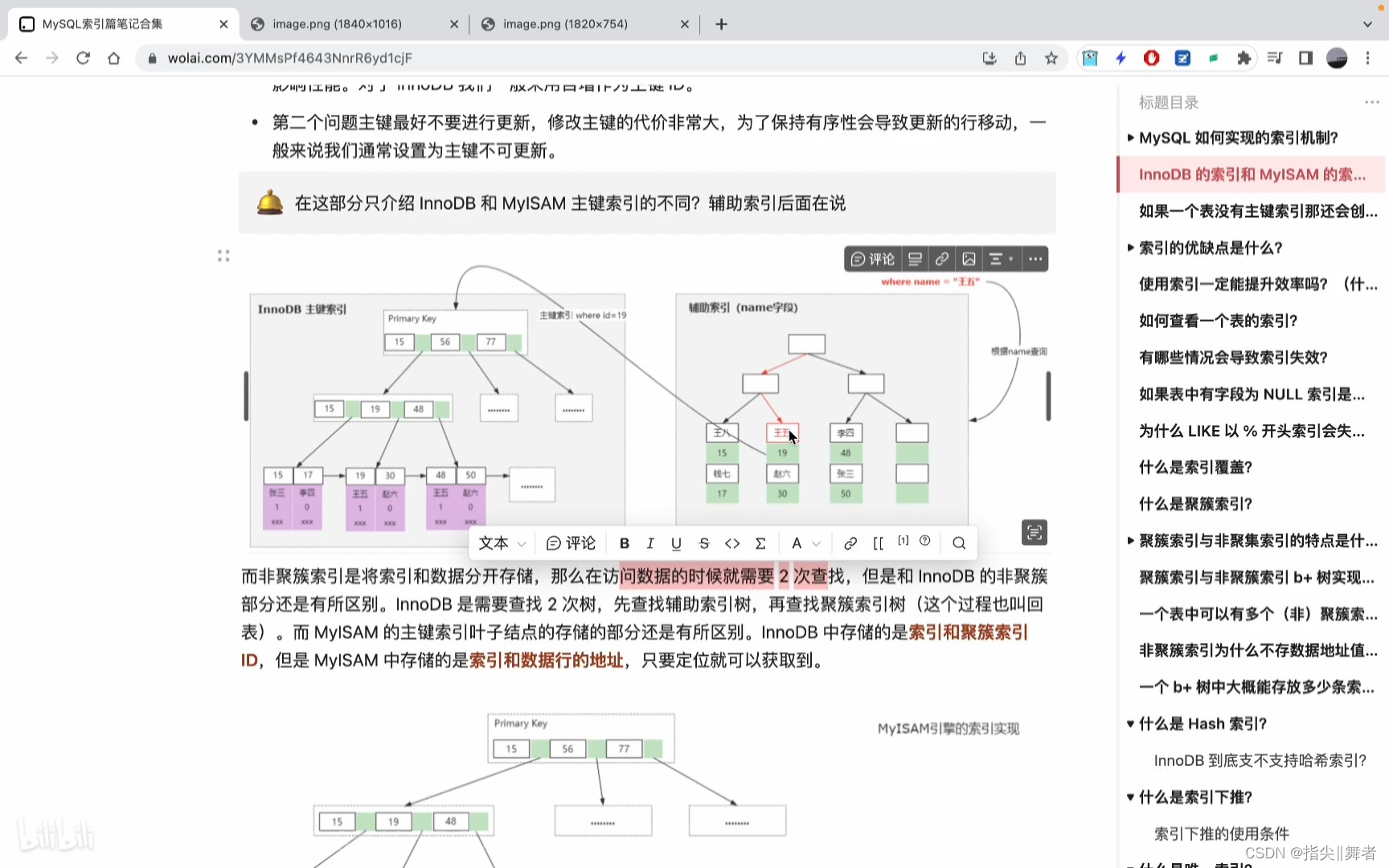
而非聚簇索引是將索引和數據分開存儲,那么在訪問數據的時候就需要2次查找,但是和InnoDB的非聚簇部分還是有所區別。InnoDB是需要查找2次樹,先查找輔助索引樹,再查找聚簇索引樹(這個過程也叫回表)。而MyISAM的主鍵索引葉子結點的存儲的部分還是有所區別。InnoDB中存儲的是索引和聚簇索引ID,但是MyISAM中存儲的是索引和數據行的地址,只要定位就可以獲取到
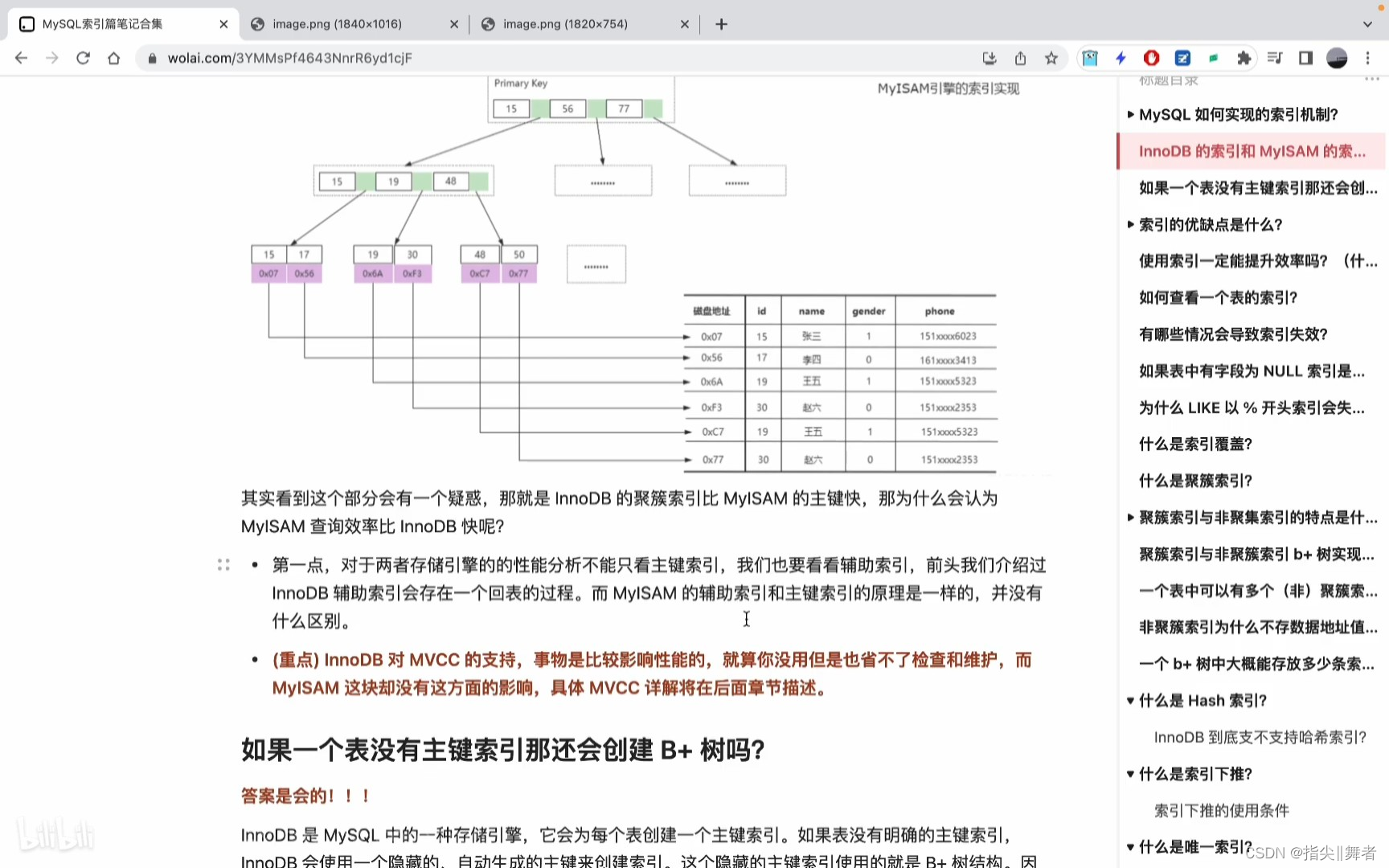
其實看到這個部分會有一個疑惑,那就是InnoDB的聚簇索引比MyISAM的主鍵快,那為什么會認為
MyISAM查詢效率比InnoDB快呢?
第一點,對于兩者存儲引擎的的性能分析不能只看主鍵索引,我們也要看看輔助索引,前頭我們介紹過InnoDB輔助索引會存在一個回表的過程。而MyISAM的輔助索引和主鍵索引的原理是一樣的,并沒有什么區別。
(重點)InnoDB對MVCC的支持,事物是比較影響性能的,就算你沒用但是也省不了檢查和維護,而
MyISAM 這塊卻沒有這方面的影響,具體MVCC詳解將在后面章節描述。
如果一個表沒有主鍵索引那還會創建B+樹嗎?
答案是會的!!!
InnoDB是MySQL中的一種存儲引擎,它會為每個表創建一個主鍵索引。如果表沒有明確的主鍵索引,
InnoDB 會使用一個隱藏的,自動生成的主鍵來創建索引。
這個隱藏的主鍵索引使用的就是 B+ 樹結構。
索引的優缺點是什么?
?需要占用物理空間,建立的索引越多需要的空間越大
創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加
會降低表的增刪改的效率,因為每次增刪改索引需要進行動態維護,導致時間變長
::使用索引一定能提升效率嗎?
(什么時候適合創建索引,什么時候不適
合創建索引?)
答案是不一定,任何事物我們都應該辯證的看,知道其運行邏輯從而利用其優點,盡量避開它的缺點。在上
面我們已經和大家介紹了過了索引帶來的優缺點,那接下來就和大家分享幾個建索引的提示。
對于查詢中使用的少的字段盡量不要創建索引,創建索引是有成本的,空間占用、創建和維護成本、增
刪改效率降低。
對于數據密度小的列也不建議創建索引,因為InnoDB中索引的B+樹所決定的,你能帶來的效率提升非常有限。(但是也有例外,舉個例子枚舉值(1,2,3),頭兩個占比百分之1%,第三個占比99%,并且頭兩個搜索占比比第三個高很多,那么是可以建議加索引的)。InnoDB的輔助索引是存在回表的,如果數據密度過小,那么性能可能還不如全表掃。像上面這種場景具有特殊性,也說明一個道理,在大多數場景下建議可能適用,但是也有不適用的時候,我們不要把這種建議當作鐵律。
MySQL 索引
聲明:寫這個玩意,僅僅是為了復習看看。僅此而已。
索引,老生常談。就是為了快,用空間換時間的。
索引是在存儲引擎中實現的,每種存儲引擎的所應都不一定相同,并且每種存儲引擎也不一定支持所有的索引類型。mysql中的縮影的存儲類型有兩種btree和hash。myisam和innodb只支持btree。memory和heap可以支持btree和innodb。每個表都支持至少16個索引,每個表索引長度最少256字節。
索引的優點:
1、通過創建唯一索引,可以保證數據庫中的每條記錄的唯一性
2、可以加快查詢速度
3、在實現數據的參考完整性方面,可以加快表之間的連接
4、在使用分組和排序是,可以顯著減少查詢中分組和排序的時間
索引的缺點:
1、創建和維護縮影需要耗費時間,并且隨著數據量的增加所耗費的時間也會增加
2、索引需要占用存儲空間,物理空間,如果有大量的縮影,索引文件可能比數據文件更快達到最大尺寸
3、對表進行crud操作時,索引需要動態的移動,這樣減低了數據的維護速度
索引的分類:
1、普通索引和唯一索引
2、單列索引和組合索引
3、全文索引
全文索引可以在char、varchar、text類型上創建,mysql上只有myisam引擎可以創建全文索引
4、空間索引
mysql上只有myisam引擎可以創建空間索引
索引的設計原則
索引設計不合理或者缺少索引都會對數據庫和應用程序的性能造成障礙。高效的索引對千獲得良好的性能非常重要。設計索引時,應該考慮以下準則:
- 索引 并非越多越好, 一個表中如有大量的索引, 不僅占用磁盤空間, 而且會影響
INSERT 、DELETE、UPDATE 等語句的性能,因 為當表中的數據更改的同 時,索引也 會進行調整和更新。 - 避免對經常更新的表進行過多的索引 , 并且索引中的列盡可能少。而對經常用 千查詢的字段應該創建索引,但要避免添加不必要的字段。
- 數據量小的表最好不要使用索引, 由千數據較少, 查詢花費的時間可能比遍歷索引的時間還要短,索引可能不會產生優化效果。
- 在條件表達式中經常用到的不同值較多的列上建立索引, 在不同值很少的列上不要建立索引。比如在學生表的“性別”字段上只有“男”與“女”兩個不同值,因此就無須建立 索引。如果建立索引不但不會提高查詢效率,反而會嚴重降低數據更新速度。
- 當唯一性是某種數據本身的特征時,指 定唯一索引。使用唯一索引需能確保定義的列的數據完整性,以提高查詢速度。
- 在頻繁進行排序或分組(即進行group by 或 order by 操作)的列上建立索引,如 果待排序的列有多個,可以在這些列上建立組合索引
mysql建立索引時中的length什么用
如果是CHAR,VARCHAR類型,length可以小于字段實際長度;如果是BLOB和TEXT類型,必須指定 length.
參考MySQL手冊 13.1.4. CREATE INDEX語法
對于CHAR和VARCHAR列,只用一列的一部分就可創建索引。創建索引時,使用col_name(length)語法,對前綴編制索引。前綴包括每列值的前length個字符。BLOB和TEXT列也可以編制索引,但是必須給出前綴長度。
此處展示的語句用于創建一個索引,索引使用列名稱的前10個字符。
CREATE INDEX part_of_name ON customer (name(10));
因為多數名稱的前10個字符通常不同,所以此索引不會比使用列的全名創建的索引速度慢很多。另外,使用列的一部分創建索引可以使索引文件大大減小,從而節省了大量的磁盤空間,有可能提高INSERT操作的速度
創建索引
MySQL 支持多種方法在單個或多個列上創建索引:
- 在創建表的定義語句CREATE TABLE中指定索引列
- 使用 ALTER TABLE 語句在存在的表上創建索引
- 使用 CREATE INDEX語句在已存在的表 上添加索引
-- 建表的時候指定索引
CREATE TABLE aa(
ID INT NOT NULL,
info VARCHAR(255) NULL,
comment VARCHAR (255) NULL,
year_publication YEAR NOT NULL,
INDEX(year_publication)
)
--創建唯一索引
UNION INDEX(year_publication)
--創建全文索引
FULLTEXT INDEX FullTxtidx (info)顯示索引
SHOW INDEX FROM TABLE_NAME;
Table: book Non_unique: 1
Key_nam : year_publication
Seq_in_index: 1
Column_name: year_publication
Collation: A
Cardinality : 0
Sub_part: NULL
Packed: NULL Null:
Index_type: BTREE
Comment:
Index comment:
其中各個主要參數的含義為:
- Table 表示創建索引的表。
- Non_ unique 表示索引非唯一, l 代表是非唯一索引, 0 代表唯一索引。
- Key_ name 表示索引的名稱。
- Seq_in_index 表示該字段在索引中的位置,單列索引該值為 I, 組合索引為每個字段在索引定義中的順序。
- Column_name 表示定義索引的列字段。
- Sub_part 表示索引的長度。
- Null 表示該字段是否能為空值。
- Index_type 表示索引類型
在已經存在的表上創建索引
ALTER TABLE TABLE_NAME ADD INDEX INDEX_NAME(CLOUMN(INDEX_LENGTH))
create index
CREATE INDEX INDEX_NAME(CLOUMN(INDEX_LENGTH))
刪除索引
有兩種方式
1. ALTER TABLE TABLE_NAME DROP INDEX INDEX_NAME;2. DROP INDEX INDEX_NAME ON TABLE_NAME;
MySQL 函數
?
數字函數、字符串函數、時間日期函數、條件函數、系統函數、加密函數、其他特殊函數
數字函數
- abs() 絕對值
2.pi() 圓周率
-
mod(x,y) 余數、sprt()
-
獲取整數函數:ceil() ceiling() floor()
ceil(-3.35) = -3
ceilIng(3.35) = 4
floor(-3.35) = -4
floor(3.35) = 3
-
隨機數函數 rand()[0,1] rand(X)
-
四舍五入:round() round(x,y) y表示小數點后保留幾位 truncate()
-
符號函數:sign(x)
sign(-21) = -1
sign(0) = 0
sign(21) = 1
8. 冪運算:pow() power() exp()
- 對數:log() log10()
字符串函數
1.char_length() 字符個數
2.length() 字節長度
- concat() 如果是有null,則為null;concat_ws() 會忽略null
concat_ws(‘-’,1,1) = 1-1
concat_ws(‘-’,1,null) = 1-
4.字符串替換: insert(s1,x,len,sr) 索引是從1開始
- lower() upper()
6.獲取指定長度的字符串:left(s,len)、right(s,len)
-
填充 lpad(s1,len.s2) rpad()
-
刪除空格 trim ltrin rtrim
-
刪除指定字符串 trim(s2 from string)
-
重復生成字符串repeat(s,n)
11, 空格函數:space(n) ;替換replace(s,s1,s2)
12.字符串大小比較:strcmp(s1,s2) 返回 -1,0,1
13.匹配字符串位置:locate(str,s) 返回索引位置,索引從0開始;positoin(str1 in str);instr(str,str1)
-
reverse()
-
返回指定位置的字符串函數:elt()
elt(1,1,b,c) = a
elt(3,a,b) = null
16 返回指定字符串位置的函數:field()
field(s,s1,s2)
field(‘hi’,a,b,‘hi’) = 3
field(‘hi’,‘hihi’,‘hh’) = 0
17 返回字符串位置的函數:find_in_set(s1,s2) s1 在s2中出現的索引位置
18 獲取字符串函數:make_set
時間日期
1.curdate() cur_date() curdate()+0
2.curtime() cur_time() curtime()+0
3.current_timestamp() localdate() now() sysdate()
- nuix 時間戳函數 unix_timestamp()
5.uct_date() 世界標準時間
6.month() monthname()
7.dayname() dayofweek() 注意:1表示周日 7表示周6 weekday() 表示工作日索引。0表示周一
8.week(date) 查詢日期是一年中的第幾周 ,week(date,modle):modle 表示一周的第一天是周幾,默認是0,0標識 一周第一天是周日 ;weekofyear(date) 查詢日期是一年中的第幾周
9.dayofyear(date) 、dayofmonth(date) 時間在一年、一月中的第幾天
- year() 、quartrt()、minute()、second()
11.extract(type from date) :type可以為 year 、year_month、year_minute
12 時間和秒轉換:time_to_sec() sec_to_time()
13 計算時間和日期的函數:
date_add()、adddate() :時間加法操作:date_add(date,interval 數量 單位) 單位可以是 年月日時分秒
date_sub()、subdate():時間減法操作:date_add(date,interval 數量 單位) 單位可以是 年月日時分秒
addtime(date,express) :addtime(‘2020-01-01 11:00:00’ ,‘1:00:00’) 加了一個小時 ;subtime() 同理 addtime(‘2020-01-01 12:00’,‘24:00’)
date_diff(d1,d2) : 返回天數
- 時間日期格式化 date_format() DATE_FORMAT(NOW(),‘%Y-%m-%d %H:%i:%s’)
條件判斷函數
- ifnull(a,b,c) 三目表達式
2.ifnull(a,b)
- case when
系統信息函數
select version()
select connection_id()
show processlist
select database() ,schema()
select user(),current_user(),system_user(),session_user()
select charset(‘123’) 獲取字符集
select last_insert_id()
加密函數、
password()
md5()
encode(str,pwd_str)
decode(str,pwd_str)
其他函數
cast() convert()
索引
是一個單獨的、存儲在磁盤上的數據庫結構,它 們包含著對數據表里所有記錄的引用指針
MySQL 中索引的存儲類型有兩種: BTREE 和 HASH, 具體和表的存儲引擎相關;
MyISAM 和InnoDB 存儲引擎只支持BTREE 索引; MEMORY/HEAP 存儲引擎可以支持 HASH
和 BTREE 索引。
索引的優點主要有以下幾條:
通過創建唯一索引, 可以保證數據庫表中每一行數據的唯一性。
可以大大加快數據的查詢速度, 這也是創建索引的最主要的原因。
在實現數據的參考完整性方面, 可以加速表和表之間的連接。
在使用分組和排序子句進行數據查詢時, 也可以顯著減少查詢中分組和排序的時間。
增加索引也有許多不利,主要表現在如下幾個方面:
創建索引和維護索引要耗費時間, 并且隨著數據量的增加所耗費的時間也會增加。
索引需要占磁盤空間, 除了數據表占數據空間之外, 每一個索引還要占一定的物理空間,如果有大量的索引,索引文件可能比數據文件更快達到最大文件尺寸。
當對表中的數據進行增加、刪除和修改的時候, 索引也要動態地維護, 這樣就降低了數據的維護速度。
索引的優缺點是什么?
數據是存儲在磁盤上的,操作系統讀取磁盤的最小單位是塊,如果沒有索引,會加載所有的數據到內存,依次進
行檢索,加載的總數據會很多,磁盤10多。
如果有了索引,會以某個列為key創建索引,MySQL采用B+樹結構存儲,一方面加載的數據只有某個列和主鍵
ID,另一方便采用了多叉平衡樹,定位到指定某個列的值會很快,根據關聯的ID可以快速定位到對應行的數據,
所以檢索的速度會很快,因為加載的總數據很少,磁盤10少。
可見,索引可以大大減少檢索數據的范圍、減少磁盤1O,使查詢速度很快,因為磁盤10是很慢的,是由它的硬件
結構決定的。
優點
索引能夠提高數據檢索的效率,降低數據庫的IO成本。
,通過創建唯一性索引,可以保證數據庫表中每一行數據的唯一性,創建唯一索引在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間加速兩個表之間的連接,一般是在外鍵上創建索引
×缺點
需要占用物理空間,建立的索引越多需要的空間越大
創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加
會降低表的增刪改的效率,因為每次增刪改索引需要進行動態維護,導致時間變長
索引的分類
索引的分類
按「數據結構」分類:B+tree索引、Hash索引、Full-text索引。
按「物理存儲」分類:聚簇索引(主鍵索引)、二級索引(輔助索引)按「字段特性」分類:主鍵索引、唯一索引、普通索引、前綴索引。按「字段個數」分類:單列索引、聯合索引。
1.普通索引和唯—索引
2.單列索引和組合索引
3.全文索引
4.空間索引刪除線格式
索引的設計原則
索引并非越多越好
避免對經常更新的表進行過多的索引
數據量小的表最好不要使用索引
在條件表達式中經常用到的不同值較多的列上建立索引, 在不同值很少的列上不要建立索引
當唯一性是某種數據本身的特征時,指定唯一索引。使用唯一索引需能確保定義的列的數據完整性,以提高查詢速度
在頻繁進行排序或分組(即進行group by 或 order by 操作)的列上建立索引
create index index_1 on by_his_user(USER_NAME);
EXPLA 語句輸出結果的各個行解釋如下:
(1)select_type 行指定所使用的SELECT查詢類型,這里值為SIMPLE, 表示簡單的SELECT,
不使用UNION 或子查詢。其他可能的取值有: PRIMARY、UNION、SUBQUERY 等。
(2)table 行指定數據庫讀取的數據表的名字, 它們按被讀取的先后順序排列。
(3)type 行指定了本數據表與其他數據表之間的 關聯關系, 可能的取值有 system、const、
eq_ref、 ref、 range、 index 和 All。
(4)possible_keys 行給出了 MySQL 在搜索數據記錄時可選用的各個索引。
(5)key 行是 MySQL 實際選用的索引。
(6)key—len 行給出索引 按字節計算的長度, ke y_len 數值越小, 表示越快。
(7)ref 行給出了關聯關系中另 一個數據表里的數據列的名字。
(8)rows 行是 MySQL 在執行這個查詢時預計會從這個數據表里讀出的數據行的個數。
extra 行提供了與關聯操作有關的信息
性能下降SQL慢,執行時間長,等待時間長:
查詢語句寫的爛
索引失效???
關聯查詢太多join
服務器調優及各個參數設置
join
left join
right join
inner join
left join on where b.XXX is null
right join on where a.XXX is null
full outer join
full outer join where a.XXX is null or b.XXX is null
數據庫遷移
數據庫遷移就是把數據從一個系統移動到另一個系統上
相同版本的 MySQL 數據庫之間的遷移
主版本號 相同的 MySQL 數據庫之間進行數據庫移動
eg:將www.abc.com 主機上的 MySQL 數據庫全部遷移到 www.bcd.com 主機上。在
www.abc.com 主機上執行的命令如下
mysqldump -h www.abc.com -uroot -ppassword dbname |
mysql -h www.bcd.com -uroot -ppassword
MySQLdump 導入的數據直接通過管道符 " I " 傳給 MySQL 命令導入的主機
www.bcd.com 數據庫中, dboame 為需要遷移的數據庫名稱, 如果要遷移全部的數據庫 , 可使用參數–all-databases
不同版本的 MySQL 數據庫之間的遷移
將舊版本數據庫中的數據備份出來,然后導入到新版本的數據庫中
不同數據庫之間的遷移
可以使用naviat Premium工具進行不同數據庫之間數據的遷移
數據恢復
可以使用命令進行恢復
直接復制到數據庫目錄
如果數據庫通過復制數據庫文件備份,可以直接復制備份的文件到 MySQL 數據目錄下實現恢復。
通過這種方式恢復時,必須保存備份數據的數據庫和待恢復的數據庫服務器的主版本號相同。而且這種方式只對 MyISAM 引擎的表有效,對于 InnoDB 引擎的表不可用。
執行恢復以前關閉MySQL服務,將備份的文件或目錄覆蓋 MySQL 的 data 目錄,啟動MySQL 服務。對于 Linux/Unix 操作系統來說, 復制完文件需要將文件的用戶和組更改為
MySQL 運行的用戶 和組,通 常用戶是 MySQL, 組也是 MySQ
mysql執行計劃怎么看
執行計劃就是sql的執行查詢的順序,以及如何使用索引查詢,返回的結果集的行數
EXPLAIN SELECT * from A where X=? and Y=?
id I select_type I table I partitions | type
filtered I Extra
1。id:是一個有順序的編號,是查詢的順序號,有幾個select 就顯示幾行。id的順序是按 select 出現的順序增
長的。id列的值越大執行優先級越高越先執行,id列的值相同則從上往下執行,id列的值為NULL最后執行。
2。selectType 表示查詢中每個select子句的類型
SIMPLE:表示此查詢不包含 UNION查詢或子查詢
?PRIMARY:表示此查詢是最外層的查詢(包含子查詢)
SUBQUERY:子查詢中的第一個SELECT
UNION:表示此查詢是UNION的第二或隨后的查詢
? DEPENDENT UNION:UNION中的第二個或后面的查詢語句,取決于外面的查詢
? UNION RESULT,UNION的結果
DEPENDENT SUBQUERY:子查詢中的第一個SELECT,取決于外面的查詢.即子查詢依賴于外層查詢的結果.
DERIVED:衍生,表示導出表的SELECT(FROM子句的子查詢)
3.table:表示該語句查詢的表
4.type:優化sql的重要字段,也是我們判斷sql性能和優化程度重要指標。
mysql執行計劃怎么看
執行計劃就是sql的執行查詢的順序,以及如何使用索引查詢,返回的結果集的行數
EXPLAIN SELECT * from A where X=? and Y=?
id I select_type I table I partitions I type
I possible_keys | key
filtered | Extra
1。id:是一個有順序的編號,是查詢的順序號,有幾個select 就顯示幾行。id的順序是按 select 出現的順序增
長的。id列的值越大執行優先級越高越先執行,id列的值相同則從上往下執行,id列的值為NULL最后執行。
2。selectType 表示查詢中每個select子句的類型
SIMPLE:表示此查詢不包含UNION查詢或子查詢
?PRIMARY:表示此查詢是最外層的查詢(包含子查詢)
? SUBQUERY:子查詢中的第一個SELECT
UNION:表示此查詢是 UNION的第二或隨后的查詢
? DEPENDENT UNION:UNION中的第二個或后面的查詢語句,取決于外面的查詢
? UNION RESULT,UNION的結果
DEPENDENT SUBQUERY:子查詢中的第一個SELECT,取決于外面的查詢.即子查詢依賴于外層查詢的結果.
DERIVED:衍生,表示導出表的SELECT(FROM子句的子查詢)
3.table:表示該語句查詢的表
4.type:優化sql的重要字段,也是我們判斷sql性能和優化程度重要指標。他的取值類型范圍
const:
|通過索引一次命中,匹配一行數據
Lsystem:)
表中只有一行記錄,相當于系統表;
eq_ref:唯一性索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配
ref:非唯一性索引掃描,返回匹配某個值的所有
?range:只檢索給定范圍的行,使用一個索引來選擇行,一般用于between、
index:只遍歷索引樹;
ALL:表示全表掃描,這個類型的查詢是性能最差的查詢之一。 那么基本就是隨著表的數量增多,執行效率越
慢。
執行效率:
ALL <index <range< ref<eq_ref<const<system。最好是避免ALL和index
5.possible_keys:它表示Mysql在執行該sql語句的時候,可能用到的索引信息,僅僅是可能,實際不一定會用
到。
6.key:此字段是 mysql在當前查詢時所真正使用到的索引。他是possible_keys的子集
MySQL 執行計劃 explain
Explain:使用EXPLAIN關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的,能查看哪些索引被使用,表的執行順序。
explain select* from book where year_publication=l990 \Gid: 1
select_type: SIMPLE
table : book
type: ref
possible_keys: year_publication
key: year_publication
key_len: 1
ref: const
rows: l
Extra:
explain 語句輸出結果的各個行解釋如下:
- select_type 行指定所使用的SELECT查詢類型,這里值為SIMPLE, 表示簡單的SELECT, 不使用UNION 或子查詢。其他可能的取值有: PRIMARY、UNION、SUBQUERY 等。
- table 行指定數據庫讀取的數據表的名字, 它們按被讀取的先后順序排列。
- type 行指定了本數據表與其他數據表之間的 關聯關系, 可能的取值有 system、const、eq_ref、 ref、 range、 index 和 All。
- possible_keys 行給出了 MySQL 在搜索數據記錄時可選用的各個索引。
- key 行是 MySQL 實際選用的索引。
- key—len 行給出索引 按字節計算的長度, key_len 數值越小,表示越快。
- ref 行給出了關聯關系中另 一個數據表里的數據列的名字。
- rows 行是 MySQL 在執行這個查詢時預計會從這個數據表里讀出的數據行的個數。
- extra 行提供了與關聯操作有關的信息
id
三種情況:
id相同,執行順序由上至下
id不同,如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行
id相同不同,同時存在
select_type
表示查詢中每個select子句的類型
(1) SIMPLE(簡單SELECT,不使用UNION或子查詢等)
(2) PRIMARY(子查詢中最外層查詢,查詢中若包含任何復雜的子部分,最外層的select被標記為PRIMARY)
(3) UNION(UNION中的第二個或后面的SELECT語句)
(4) DEPENDENT UNION(UNION中的第二個或后面的SELECT語句,取決于外面的查詢)
(5) UNION RESULT(UNION的結果,union語句中第二個select開始后面所有select)
(6) SUBQUERY(子查詢中的第一個SELECT,結果不依賴于外部查詢)
(7) DEPENDENT SUBQUERY(子查詢中的第一個SELECT,依賴于外部查詢)
(8) DERIVED(派生表的SELECT, FROM子句的子查詢)
(9) UNCACHEABLE SUBQUERY(一個子查詢的結果不能被緩存,必須重新評估外鏈接的第一行)
table
顯示表名稱或者別名
type
對表訪問方式,表示MySQL在表中找到所需行的方式,又稱“訪問類型”。
常用的類型有: ALL、index、range、 ref、eq_ref、const、system、NULL(從左到右,性能從差到好)
ALL:Full Table Scan, MySQL將遍歷全表以找到匹配的行
index: Full Index Scan,index與ALL區別為index類型只遍歷索引樹
range:只檢索給定范圍的行,使用一個索引來選擇行
ref: 表示上述表的連接匹配條件,即哪些列或常量被用于查找索引列上的值
eq_ref: 類似ref,區別就在使用的索引是唯一索引,對于每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用primary key或者 unique key作為關聯條件
const、system: 當MySQL對查詢某部分進行優化,并轉換為一個常量時,使用這些類型訪問。如將主鍵置于where列表中,MySQL就能將該查詢轉換為一個常量,system是const類型的特例,當查詢的表只有一行的情況下,使用system
NULL: MySQL在優化過程中分解語句,執行時甚至不用訪問表或索引,例如從一個索引列里選取最小值可以通過單獨索引查找完成
possible_keys
指出MySQL能使用哪個索引在表中找到記錄,查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢使用(該查詢可以利用的索引,如果沒有任何索引顯示 null)
Key
key列顯示MySQL實際決定使用的鍵(索引),必然包含在possible_keys中
如果沒有選擇索引,鍵是NULL。要想強制MySQL使用或忽視possible_keys列中的索引,在查詢中使用FORCE INDEX、USE INDEX或者IGNORE INDEX
key_len
表示索引中使用的字節數,可通過該列計算查詢中使用的索引的長度(key_len顯示的值為索引字段的最大可能長度,并非實際使用長度,即key_len是根據表定義計算而得,不是通過表內檢索出的)
ref
列與索引的比較,表示上述表的連接匹配條件,即哪些列或常量被用于查找索引列上的值
rows
估算出結果集行數
Extra
該列包含MySQL解決查詢的詳細信息,有以下幾種情況:
Using where:不用讀取表中所有信息,僅通過索引就可以獲取所需數據,這發生在對表的全部的請求列都是同一個索引的部分的時候,表示mysql服務器將在存儲引擎檢索行后再進行過濾
Using temporary:表示MySQL需要使用臨時表來存儲結果集,常見于排序和分組查詢,常見 group by ; order by
Using filesort:當Query中包含 order by 操作,而且無法利用索引完成的排序操作稱為“文件排序”
– 測試Extra的filesort
explain select * from emp order by name;
Using join buffer:改值強調了在獲取連接條件時沒有使用索引,并且需要連接緩沖區來存儲中間結果。如果出現了這個值,那應該注意,根據查詢的具體情況可能需要添加索引來改進能。
Impossible where:這個值強調了where語句會導致沒有符合條件的行(通過收集統計信息不可能存在結果)。
Select tables optimized away:這個值意味著僅通過使用索引,優化器可能僅從聚合函數結果中返回一行
No tables used:Query語句中使用from dual 或不含任何from子句
mysql 備份恢復命令
數據備份
1.備份某個數據庫中的一張表
mysqldump -uroot -p 數據庫名稱 表名 >aa.sqleg:mysqldump -uroot -p course student >aa.sql
2.備份某個數據庫
命令:mysqldump -uroot -p 數據庫名稱 >aa.sqleg:mysqldump -uroot -p course >aa.sql
3.備份整個數據庫
命令:mysqldump -uroot -p >aa.sqleg:mysqldump -uroot -p --all-databases >aa.sql
4.僅導出表結構不導出數據 --no-data
命令:mysqldump -uroot -p --no-data [數據庫名稱] >aa.sqleg:mysqldump -uroot -p --no-data [springbootv2][--all-databases] >aa.sql
5.僅導出表結構不導出數據 --no-create-info
命令:mysqldump -uroot -p --no-create-info [數據庫名稱] >aa.sqleg:mysqldump -uroot -p --no-create-info [springbootv2][--all-databases] >aa.sql
6.導出course庫中的存儲過程和觸發器 --routines --triggers [–測試未通過]
命令:mysqldump -uroot -p --routines --triggers [數據庫名稱] >aa.sqleg:mysqldump -uroot -p --routines --triggers [springbootv2][--all-databases] >aa.sql
數據恢復
有兩種恢復方式 登錄/不登錄
1.不登錄
命令:mysql -uroot -p <備份文件.sqleg:mysql -uroot -p <test.sql
2.登錄
命令:mysql> source 備份文件.sqleg: mysql> source test.sql
數據庫 中的事務
事務是由一組SQL語句組成的邏輯處理單元,事務具有以下4個屬性,通常簡稱為事務的ACID屬性。
l 原子性(Atomicity):事務是一個原子操作單元,其對數據的修改,要么全都執行,要么全都不執行。
l 一致性(Consistent):在事務開始和完成時,數據都必須保持一致狀態。
這意味著所有相關的數據規則都必須應用于事務的修改,以保持數據的完整性;
事務結束時,所有的內部數據結構(如B樹索引或雙向鏈表)也都必須是正確的。
l 隔離性(Isolation):數據庫系統提供一定的隔離機制,保證事務在不受外部并發操作影響的“獨立”環境執行。
這意味著事務處理過程中的中間狀態對外部是不可見的,反之亦然。
l 持久性(Durable):事務完成之后,它對于數據的修改是永久性的,即使出現系統故障也能夠保持。
并發事務處理帶來的問題:
更新丟失(Lost Update)
當兩個或多個事務選擇同一行,然后基于最初選定的值更新該行時,由于每個事務都不知道其他事務的存在,
就會發生丟失更新問題--最后的更新覆蓋了由其他事務所做的更新。
例如,兩個程序員修改同一java文件。每程序員獨立地更改其副本,然后保存更改后的副本,這樣就覆蓋了原始文檔。
最后保存其更改副本的編輯人員覆蓋前一個程序員所做的更改。如果在一個程序員完成并提交事務之前,
另一個程序員不能訪問同一文件,則可避免此問題。
臟讀(Dirty Reads)
一個事務正在對一條記錄做修改,在這個事務完成并提交前,這條記錄的數據就處于不一致狀態;這時,
另一個事務也來讀取同一條記錄,如果不加控制,第二個事務讀取了這些“臟”數據,并據此做進一步的處理,
就會產生未提交的數據依賴關系。這種現象被形象地叫做”臟讀”。
一句話:事務A讀取到了事務B已修改但尚未提交的的數據,還在這個數據基礎上做了操作。此時,如果B事務回滾,A讀取
的數據無效,不符合一致性要求。
不可重復讀(Non-Repeatable Reads)
一個事務在讀取某些數據后的某個時間,再次讀取以前讀過的數據,卻發現其讀出的數據已經發生了改變、或某些記錄已經被刪除了!
這種現象就叫做“不可重復讀”。
一句話:事務A讀取到了事務B已經提交的修改數據,不符合隔離性
幻讀(Phantom Reads)
一個事務按相同的查詢條件重新讀取以前檢索過的數據,卻發現其他事務插入了滿足其查詢條件的新數據,這種現象就稱為“幻讀”。
一句話:事務A讀取到了事務B體提交的新增數據,不符合隔離性。
多說一句:幻讀和臟讀有點類似,
臟讀是事務B里面修改了數據,
幻讀是事務B里面新增了數據。
事務隔離級別
臟讀”、“不可重復讀”和“幻讀”,其實都是數據庫讀一致性問題,必須由數據庫提供一定的事務隔離機制來解決。
數據庫的事務隔離越嚴格,并發副作用越小,但付出的代價也就越大,因為事務隔離實質上就是使事務在
一定程度上 “串行化”進行,這顯然與“并發”是矛盾的。同時,不同的應用對讀一致性和事務隔離程度的
要求也是不同的,比如許多應用對“不可重復讀”和“幻讀”并不敏感,可能更關心數據并發訪問的能力。
mysql主從同步原理
mysql主從同步的過程:
Mysql的主從復制中主要有三個線程:master(binloa dump thread)、slave
thread),Master—條線程和Slave中的兩條線程。
·主節點binlog,主從復制的基礎是主庫記錄數據庫的所有變更記錄到binlog。binlog是數據庫服務器啟動的
那一刻起,保存所有修改數據庫結構或內容的一個文件。
主節點log dump線程,當binlog有變動時,log dump 線程讀取其內容并發送給從節點。
從節點1/O線程接收binlog內容,并將其寫入到relaylog文件中。
·從節點的SQL線程讀取relay log文件內容對數據更新進行重放,最終保證主從數據庫的一致性。
注:主從節點使用binglog文件+position偏移量來定位主從同步的位置,從節點會保存其已接收到的偏移量
如果從節點發生宕機重啟,則會自動從 position的位置發起同步。
由于mysql默認的復制方式是異步的,主庫把日志發送給從庫后不關心從庫是否已經處理,這樣會產生一個問題就
是假設主庫掛了,從庫處理失敗了,這時候從庫升為主庫后,日志就丟失了。由此產生兩個概念。
全同步復制
主庫寫入binlog后強制同步日志到從庫,所有的從庫都執行完成后才返回給客戶端,但是很顯然這個方式的話性能
會受到嚴重影響。
半同步復制
和全同步不同的是,半同步復制的邏輯是這樣,從庫寫入日志成功后返回ACK確認給主庫,主庫收到至少一個從庫
的確認就認為寫操作完成。
Mysql數據庫中,什么情況下設置了索引但無法使用?
1.沒有符合最左前綴原則
2.字段進行了隱私數據類型轉化
3.走索引沒有全表掃描效率高
存儲拆分后如何解決唯一主鍵問題
UUID:簡單、性能好,沒有順序,沒有業務含義,存在泄漏mac地址的風險
數據庫主鍵:實現簡單,單調遞增,具有一定的業務可讀性,強依賴db、存在性能瓶頸,存在暴露業務信息的風
險
redis,mongodb,zk等中間件:增加了系統的復雜度和穩定性
雪花算法
海量數據下,如何快速查找一條記錄?
1、使用布隆過濾器,快速過濾不存在的記錄。
使用Redis的bitmap結構來實現布隆過濾器。
2、在Redis中建立數據緩存。-將我們對Redis使用場景的理解盡量表達出來。
以普通字符串的形式來存儲,(serld->user.json)。以一個hash來存儲一條記錄(userld key->username field->,userAge->)。以一個整的hash來存儲所有的數據,Userlnfo->field就用userld,value就用user.json。一個hash最多能支持2^32-1(40多個億)個鍵值對。
緩存擊穿:對不存在的數據也建立key。這些key都是經過布隆過濾器過濾的,所以一般不會太多.
緩存過期:將熱點數據設置成永不過期,定期重建緩存。 使用分布式鎖重建緩存。
3、查詢優化。
按槽位分配數據,
自己實現槽位計算,找到記錄應該分配在哪臺機器上,然后直接去目標機器上找。
簡述MyISAM和InnoDB的區別
MyISAM:
不支持事務
支持表級鎖,
存儲表的總行數;
一個MYISAM表有三個文件:索引文件、表結構文件、數據文件;
采用非聚集索引,索引文件的數據域存儲指向數據文件的指針。輔索引與主索引基本一致,但是輔索引不用保證唯
一性。
InnoDb:
支持ACID的事務,支持事務的四種隔離級別;
支持行級鎖及外鍵約束:因此可以支持寫并發;
不存儲總行數;
一個InnoDb引擎存儲在一個文件空間(共享表空間,表大小不受操作系統控制,一個表可能分布在多個文件里),也有可能為多個(設置為獨立表空,表大小受操作系統文件大小限制,一般為2G),受操作系統文件大小的限制;
主鍵索引采用聚集索引(索引的數據域存儲數據文件本身),輔索引的數據域存儲主鍵的值;因此從輔索引查找數據,需要先通過輔索引找到主鍵值,再訪問輔索引;最好使用自增主鍵,防止插入數據時,為維持B+樹結構,文件的大調整。
簡述mysql中索引類型及對數據庫的性能的影響
普通索引:允許被索引的數據列包含重復的值。
唯一索引:可以保證數據記錄的唯一性。
主鍵:是一種特殊的唯一索引,在一張表中只能定義一個主鍵索引,主鍵用于唯一標識一條記錄,使用關鍵字
PRIMARYKEY來創建。
聯合索引:索引可以覆蓋多個數據列,如像INDEx(olumnA,columnB)引。
全文索引:通過建立倒排索引,可以極大的提升檢索效率,解決判斷字段是否包含的問題,是目前搜索引擎使用的一
種關鍵技術。可以通過ALTER TABLE table_name ADDFULLTEXT(column);創建全文索引
索引可以極大的提高數據的查詢速度。
通過使用索引,可以在查詢的過程中,使用優化隱藏器,提高系統的性能。
但是會降低插入、刪除、更新表的速度,因為在執行這些寫操作時,還要操作索引文件
索引需要占物理空間,除了數據表占數據空間之外,每一個索引還要占一定的物理空間,如果要建立聚簇索引,那
么需要的空間就會更大,如果非聚集索引很多,一旦聚集索引改變,那么所有非聚集索引都會跟著變。
強平衡二叉樹和弱平衡二叉樹有什么區別
強平衡二叉樹AVL樹,弱平衡二叉樹就是我們說的紅黑樹。
1.AVL樹比紅黑樹對于平衡的程度更加嚴格,在相同節點的情況下,AVL樹的高度低于紅黑樹
2.紅黑樹中增加了一個節點顏色的概念
3.AVL樹的旋轉操作比紅黑樹的旋轉操作更耗時
B樹和B+樹的區別,為什么Mysql使用B+樹
B樹的特點:
1.節點排序
2.一個節點了可以存多個元素,多個元素也排序了
B+樹的特點:1.擁有B樹的特點2.葉子節點之間有指針
3.非葉子節點上的元素在葉子節點上都冗余了,也就是葉子節點中存儲了所有的元素,并且排好順序
Mysql索引使用的是B+樹,因為索引是用來加快查詢的,而B+樹通過對數據進行排序所以是可以提高查詢速度的,然后通過一個節點中可以存儲多個元素,從而可以使得B+樹的高度不會太高,在Mysql中一個Innodb頁就是一個B+樹節點,一個Innodb頁默認16kb,所以一般情況下一顆兩層的B+樹可以存2000萬行左右的數據,然后通過利用B+樹葉子節點存儲了所有數據并且進行了排序,并且葉子節點之間有指針,可以很好的支持全表掃描,范圍查找等SQL語句。
事務的基本特性和隔離級別有哪些?
事務:表示多個數據操作組成一個完整的事務單元,這個事務內的所有數據操作要么同時成功,要么同時失敗。
事務的特性:ACID
1、原子性:事務是不可分割的,要么完全成功,要么完全失敗。
2、一致性:事務無論是完成還是失敗,都必須保持事務內操作的一致性。當失敗時,都要對前面的操作進行回滾,不管中途
是否成功。
3、隔離性:當多個事務操作一個數據的時候,為防止數據損壞,需要將每個事務進行隔離,互相不干擾。
4、持久性:事務開始就不會終止。他的結果不受其他外在因素的影響。
事務的隔離級別:SHOW VARIABLES like’transaction%’
設置隔離級別:set transaction level xxx 設置下次事務的隔離級別。
set session transaction level xxx 設置當前會話的事務隔離級別
set global transaction level xxx 設置全局事務隔離級別
MySQL當中有五種隔離級別
NONE:不使用事務。
READ UNCOMMITED:
READ COMMITED:防止臟讀,最常用的隔離級別
REPEATABLE READ:防止臟讀和不可重復讀。MYSQL默認
SERIALIZABLE:事務串行,可以防止臟讀、幻讀,不可重復度
如何實現分庫分表
將原本存儲于單個數據庫上的數據拆分到多個數據庫,把原來存儲在單張數據表的數據拆分到多張數據表中,實現
數據切分,從而提升數據庫操作性能。分庫分表的實現可以分為兩種方式:垂直切分和水平切分。
水平:將數據分散到多張表,涉及分區鍵,
。分庫:每個庫結構一樣,數據不一樣,沒有交集。庫多了可以緩解io和cpu壓力
”分表:每個表結構一樣,數據不一樣,沒有交集。表數量減少可以提高sq|執行效率、減輕cpu壓力
垂直:將字段拆分為多張表,需要一定的重構
·分庫:每個庫結構、數據都不一樣,所有庫的并集為全量數據
、分表:每個表結構、數據不一樣,至少有一列交集,用于關聯數據,所有表的并集為全量數據
什么是MVCC
多版本并發控制:讀取數據時通過一種類似快照的方式將數據保存下來,這樣讀鎖就和寫鎖不沖突了,不同的事務
session會看到自己特定版本的數據,版本鏈
MVCC只在 READ COMMITTED和 REPEATABLE READ兩個隔離級別下工作。其他兩個隔離級別夠和MVCC不兼容,因為READ UNCOMMITTED總是讀取最新的數據行,而不是符合當前事務版本的數據行。而SERIALIZABLE則會對所有讀取的行都加鎖。
聚簇索引記錄中有兩個必要的隱藏列:
trx_id:用來存儲每次對某條聚簇索引記錄進行修改的時候的事務id。
roll_pointer:每次對哪條聚簇索引記錄有修改的時候,都會把老版本寫入undo日志中。這個roll_pointer就是存了一個指針,它指向這條聚簇索引記錄的上一個版本的位置,通過它來獲得上一個版本的記錄信息。(注意插入操作的undo日志沒有這個屬性,因為它沒有老版本)
已提交讀和可重復讀的區別就在于它們生成ReadView的策略不同。
開始事務時創建readview,readView維護當前活動的事務id,即未提交的事務id,排序生成一個數組
訪問數據,獲取數據中的事務id(獲取的是事務id最大的記錄),對比readview:
如果在readview的左邊(比readview都小),可以訪問(在左邊意味著該事務已經提交)
如果在readview的右邊(比readview都大)或者就在readview中,不可以訪問,獲取roll_pointer,取上一版本
重新對比(在右邊意味著,該事務在readview生成之后出現,在readview中意味著該事務還未提交)
已提交讀隔離級別下的事務在每次查詢的開始都會生成一個獨立的ReadView,而可重復讀隔離級別則在第一次讀的
時候生成一個ReadView,之后的讀都復用之前的ReadView。
這就是MysqI的MVCC,通過版本鏈,實現多版本,可并發讀-寫,寫-讀。通過ReadView生成策略的不同實現不同的
隔離級別。
什么是臟讀、幻讀、不可重復讀?要怎么處理?
這些問題都是MySQL進行事務并發控制時經常遇到的問題。
臟讀:在事務進行過程中,讀到了其他事務未提交的數據。
不可重復讀:在一個事務過程中,多次查詢的結果不一致。
幻讀:在一個事務過程中,用同樣的操作查詢數據,得到的記錄數不相同。
處理的方式有很多種:加鎖、康務隔離、MVCC
加鎖:
1、臟讀:在修改時加排他鎖,直到事務提交才釋放。讀取時加共享鎖,讀完釋放鎖。
2、不可重復讀:讀數據時加共享鎖,寫數據時加排他鎖。
3、幻讀:加范圍鎖。
事務的基本特性和隔離級別
事務基本特性ACID分別是:
原子性指的是一個事務中的操作要么全部成功,要么全部失敗。
一致性指的是數據庫總是從一個一致性的狀態轉換到另外一個一致性的狀態。比如A轉賬給B100塊錢,假設A只有90塊,支付之前我們數據庫里的數據都是符合約束的,但是如果事務執行成功了,我們的數據庫數據就破壞約束了,因此事務不能成功,這里我們說事務提供了一致性的保證
隔離性指的是一個事務的修改在最終提交前,對其他事務是不可見的。
持久性指的是一旦事務提交,所做的修改就會永久保存到數據庫中。
隔離性有4個隔離級別,分別是:
read uncommit 讀未提交,可能會讀到其他事務未提交的數據,也叫做臟讀。
用戶本來應該讀取到id=1的用戶age應該是10,結果讀取到了其他事務還沒有提交的事務,結果讀取結果
age=20,這就是臟讀。
read commit 讀已提交,兩次讀取結果不一致,叫做不可重復讀。
不可重復讀解決了臟讀的問題,他只會讀取已經提交的事務。
用戶開啟事務讀取id=1用戶,查詢到age=10,再次讀取發現結果=20,在同一個事務里同一個查詢讀取到不同的結果叫做不可重復讀。
repeatable read 可重復復讀,這是mysql的默認級別,就是每次讀取結果都一樣,但是有可能產生幻讀。
serializable串行,一般是不會使用的,他會給每一行讀取的數據加鎖,會導致大量超時和鎖競爭的問題
索引的基本原理
索引用來快速地尋找那些具有特定值的記錄。如果沒有索引,一般來說執行查詢時遍歷整張表。
索引的原理:就是把無序的數據變成有序的查詢
1.把創建了索引的列的內容進行排序
2.對排序結果生成倒排表
3.在倒排表內容上拼上數據地址鏈
4.在查詢的時候,先拿到倒排表內容,再取出數據地址鏈,從而拿到具體數據
索引設計的原則?
查詢更快、占用空間更小
1.適合索引的列是出現在where子句中的列,或者連接子句中指定的列
2.基數較小的表,索引效果較差,沒有必要在此列建立索引
3.使用短索引,如果對長字符串列進行索引,應該指定一個前綴長度,這樣能夠節省大量索引空間,如果搜索詞
超過索引前綴長度,則使用索引排除不匹配的行,然后檢查其余行是否可能匹配。
4.不要過度索引。索引需要額外的磁盤空間,并降低寫操作的性能。在修改表內容的時候,索引會進行更新甚至
重構,索引列越多,這個時間就會越長。所以只保持需要的索引有利于查詢即可。
5.定義有外鍵的數據列一定要建立索引。
6.更新頻繁字段不適合創建索引
7.若是不能有效區分數據的列不適合做索引列(如性別,男女未知,最多也就三種,區分度實在太低)
8.盡量的擴展索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那么只需要修改原來的索
引即可。
9.對于那些查詢中很少涉及的列,重復值比較多的列不要建立索引。
10.對于定義為text、image和bit的數據類型的列不要建立索引。
索引覆蓋是什么
索引覆蓋就是一個SQL在執行時,可以利用索引來快速查找,并且此SQL所要查詢的字段在當前索引對應的字段中都包含了,那么
就表示此SQL走完索引后不用回表了,所需要的字段都在當前索引的葉子節點上存在,可以直接作為結果返回了
最左前綴原則是什么
當一個SQL想要利用索引是,就一定要提供該索引所對應的字段中最左邊的字段,也就是排在最前面的字段,比如針對a,b,c三個字段建立了一個聯合索引,那么在寫一個sql時就一定要提供a字段的條件,這樣才能用到聯合索引,這是由于在建立a,b,c三個字段的聯合索引時,底層的B+樹是按照a,bc三個字段從左往右去比較大小進行排序的,所以如果想要利用B+樹進行快速查找也得符合這個規則
談談如何對MySQL進行分庫分表?多大數據量需要進行分庫分表?分庫分表的方式和分片策略由哪些?分庫分表后,SQL語句的執行流程是怎樣的?
什么是分庫分表? 就是當表中的數據量過大時,整個查詢效率就會降低得非常明顯。這時為了提升查詢效率,就要將一個表
中的數據分散到多個數據庫的多個表當中。
分庫分表最常用的組件:
Mycatl ShardingSphere
數據分片的方式有垂直分片和水平分片。垂直分片就是從業務角度將不同的表拆分到不同的庫中,能夠解決數據庫數據文件過大的問題,但是不能從根本上解決查詢問題。水平分片就是從數據角度將一個表中的數據拆分到不同的庫或表中,這樣可以從根本上解決數據量過大造成的查詢效率低的問題。
有非常多的分片策略,比如 取模、按時間、按枚舉值。。。。
阿里提供的開發手冊當中,建議:一個表的數據量超過500W或者數據文件超過2G,就要考慮分庫分表了。
分庫分表后的執行流程:
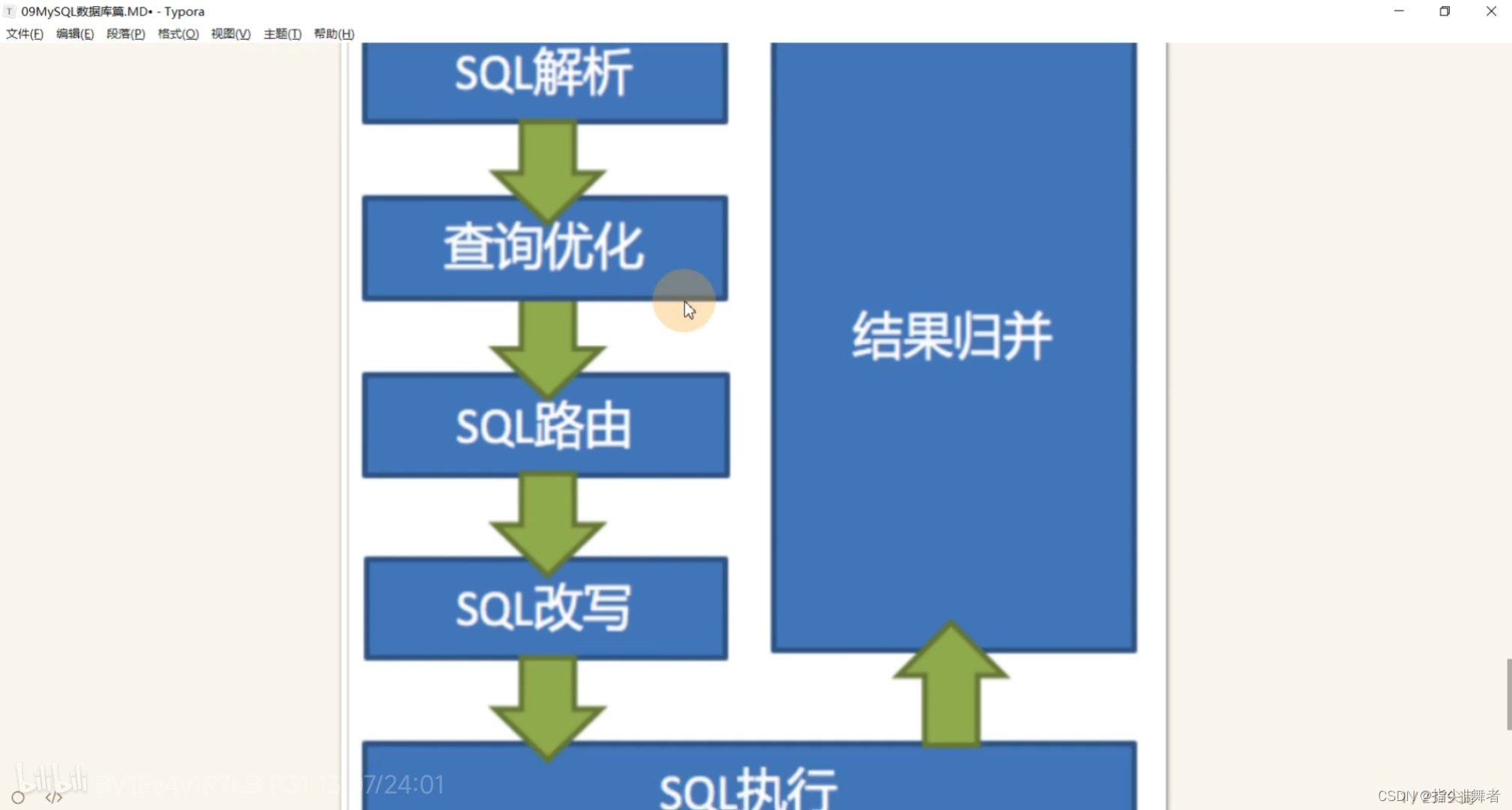
一個user表,按照userid進行了分片,然后我需要按照sex字段去查,這要怎么查?強制指定只查一個數據庫,要怎么做?查
詢結果按照userid來排序,要怎么排?
分庫分表的問題:跨庫查詢,跨庫排序,分布式事務,公共表,主鍵重復……
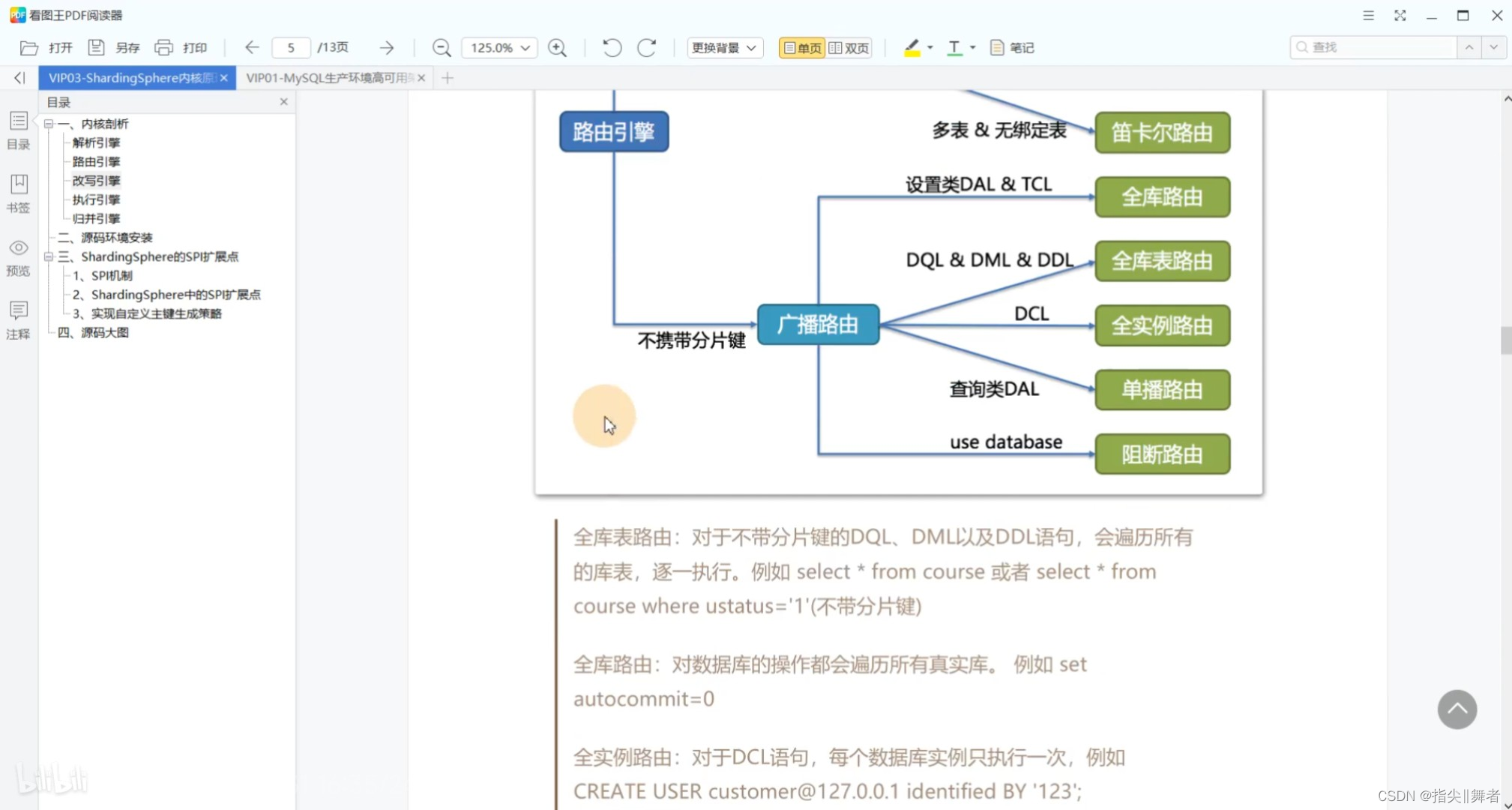
全庫表路由:對于不帶分片鍵的DQL、DML以及DDL語句,會遍歷所有的庫表,逐一執行。例如selectfrom course 或者selectfrom course where ustatus=‘1(不帶分片鍵)
全庫路由:對數據庫的操作都會遍歷所有真實庫。例如set
autocommit=0
全實例路由:對于DCL語句,每個數據庫實例只執行一次,例如
CREATE USER customer@127.0.0.1 identified BY’123’;
關心過業務系統里面的sql耗時嗎?統計過慢查詢嗎?對慢查詢都
怎么優化過?
在業務系統中,除了使用主鍵進行的查詢,其他的都會在測試庫上測試其耗時,慢查詢的統計主要由運維在做,會
定期將業務中的慢查詢反饋給我們。
慢查詢的優化首先要搞明白慢的原因是什么?是查詢條件沒有命中索引?是load了不需要的數據列?還是數據量
太大?
所以優化也是針對這三個方向來的,
首先分析語句,看看是否load了額外的數據,可能是查詢了多余的行并且拋棄掉了,可能是加載了許多結果中
并不需要的列,對語句進行分析以及重寫。
分析語句的執行計劃,然后獲得其使用索引的情況,之后修改語句或者修改索引,使得語句可以盡可能的命中
索引。
如果對語句的優化已經無法進行,可以考慮表中的數據量是否太大,如果是的話可以進行橫向或者縱向的分
表。
SQL優化有哪些著手點?組合索引的最左前綴原則的含義?
首先講第一個問題:
SQL優化,既然是優化,那么首先得要定位問題才能對癥下藥,開啟慢查詢日志監控,找出系統中比較慢的SQL。這就減少了篩查范圍,然后逐條進行執行計劃分析。沒建索引的建索引,建了索引的看看索引是不是失效了,然后排查為什么索引失效?這些問題排查完了之后,可能因為表數據量過大,那就要考慮是不是要拆表,進行分表。|
常用優化建議:
1.優化查詢的選擇、連接和排序操作。
2.優化查詢中使用的索引,包括創建新索引、刪除無用索引、調整索引的順序等。
3.優化查詢中使用的表連接方式,包括內連接、外連接、自連接等。
4.優化查詢中使用的子查詢,包括對子查詢進行優化、使用連接代替子查詢等。
5.優化查詢中使用的聚合函數,包括使用索引進行優化、使用分組連接代替聚合函數等。
第二個問題:
組合索引的最左前綴原則指的是,在創建組合索引時,應該將最常用于篩選數據的列放在索引的最左側,這樣可以使索引更有效地幫助查詢優
化。
例如,如果有一張表中包含三個字段:A、B和C,并且頻繁使用A和B 這兩個字段進行篩選數據,則應該將 A和B 作為組合索引的最左前
綴,而不是C。
這樣,在使用組合索引進行查詢時,數據庫系統就可以使用索引進行快速篩選,而不必掃描整張表。這有助于提高查詢的效率。
最左前綴原則對于組合索引的創建非常重要,因為它可以幫助數據庫系統更有效地使用索引。如果不遵循最左前綴原則,則組合索引可能會變
得無用,甚至阻礙查詢的優化。
分庫分表之后,id主鍵如何處理?
其實這是分庫分表之后你必然要面對的一個問題,就是 id昨生成?因為要是分成多個表之后,每個表都是從 1開始累加,那肯定不對啊,需要
一個全局唯一的id來支持。所以這都是你實際生產環境中必須考慮的問題。
數據庫自增長 ID
這個就是說你的系統里每次得到一個id,都是往一個庫的一個表里插入一條沒什么業務含義的數據,然后獲取一個數據庫自增的一個id。拿到
這個id之后再往對應的分庫分表里去寫入。
優點:非常簡單,有序遞增,方便分頁和排序。
缺點:分庫分表后,同一數據表的自增ID容易重復,無法直接使用(可以設置步長,但局限性很明顯);性能吞吐量整個較低,如果設計一個
單獨的數據庫來實現 分布式應用的數據唯一性,即使使用預生成方案,也會因為事務鎖的問題,高并發場景容易出現單點瓶頸。
適用場景:單數據庫實例的表ID(包含主從同步場景),部分按天計數的流水號等;分庫分表場景、全系統唯一性ID場景不適用。
Redis生成ID
通過Redis的INCR/INCRBY自增原子操作命令,能保證生成的1D肯定是唯一有序的,本質上實現方式與數據庫一致。
優點:整體吞吐量比數據庫要高。
缺點:Redis 實例或集群宕機后,找回最新的ID值比較麻煩。
適用場景:比較適合計數場景,如用戶訪問量,訂單流水號(日期+流水號)等
UUID、GUID生成ID
優點:性能非常高,本地生成,沒有網絡消耗;
缺點:UUID太長了、占用空間大,作為主鍵性能太差了;
由于UUID不具有有序性,會導致B+樹索引在寫的時候有過多的隨機寫操作
適合的場景:如果你是要隨機生成個什么文件名、編號之類的,你可以用UUID,但是作為主鍵不建議用UUID的。
snowflake(雪花)算法
snowflake 算法來源于Twitter,使用scala語言實現,snowflake算法的特性是有序、唯一,并且要求高性能,低延遲(每臺機器每秒至少生
成10k條數據,并且響應時間在2ms以內),要在分布式環境(多集群,跨機房)下使用,因此 snowflake算法得到的ID是分段組成的:
與指定日期的時間差(毫秒級),41位,夠用69年
集群1D+機器ID,10位,最多支持1024臺機器
序列,12位,每臺機器每毫秒內最多產生4096個序列號
雪花算法核心思想是:分布式ID固定是一個long型的數字,一個long型占8個字節,也就是64個bit
1bit:符號位,固定是0,表示全部|D都是正整數
41bit:表示的是時間戳,單位是毫秒。41 bits可以表示的數字多達241-1,也就是可以標識241-1個毫秒值,換算成年就是表示
69年的時間。
10bit:機器ID,有異地部署,多集群的也可以配置,需要線下規劃好各地機房,各集群,各實例ID的編號
12bit:序列ID,用來記錄同一個毫秒內產生的不同id,12 bits 可以代表的最大正整數是2^12-1=4096,也就是說可以用這個12 bits
代表的數字來區分同一個毫秒內的4096個不同的id。
優點:
毫秒數在高位,自增序列在低位,整個ID都是趨勢遞增的。
不依賴數據庫等第三方系統,以服務的方式部署,穩定性更高,生成ID的性能也是非常高的。
可以根據自身業務特性分配bit位,非常靈活。
缺點:
強依賴機器時鐘,如果機器上時鐘回撥,會導致發號重復或者服務會處于不可用狀態。
IP地址如何在數據庫中存儲?
在MySQL中,當存儲IPv4地址時,應該使用32位的無符號整數(UNSIGNEDINT)來存儲IP地址,而不是使用字符串,用UNSIGNED INT
類型存儲IP地址是一個4字節長的整數。
如果是字符串存儲|P地址,在正常格式下,最小長度為7個字符(0.0.0.0),最大長度為15個(255.255.255.255),因此,我們通常會使用varchar(15)來存儲。同時為了讓數據庫準確跟蹤列中有多少數據,數據庫會添加額外的1字節來存儲字符串的長度。這使得以字符串表示的IP的實際數據存儲成本需要16字節。
這意味著如果將每個IP地址存儲為字符串的話,每行需要多耗費大約10個字節的額外資源。
如果你說磁盤夠使不是事兒,那我得告訴你,這個不僅會使數據文件消耗更多的磁盤,如果該字段加了索引,也會同比例擴大索引文件的大小,緩存數據需要使用更多內存來緩存數據或索引,從而可能將其他更有價值的內容推出緩存區。執行SQL對該字段進行CRUD時,也會消耗更多的CPU資源。
MySQL中有內置的函數,來對IP和數值進行相互轉換。
INET_ATON()
將IP轉換成整數。
算法:第一位乘256三次方+第二位乘256二次方+第三位乘256一次方+第四位乘256零次方
? INET_NTOA()
將數字反向轉換成IP
SELECT INET_ATON(‘127.0.0.1’);
Java
INET_ATON(‘127.0.0.1’)|
2130706433
1 row in set (0.00 sec)
SELECT INET_NTOA(‘2130706433’);
INET_NTOA(‘2130706433’)|
127.0.0.1
1 row in set
(0.02 sec)
如果是 IPv6地址的話,可以使用函數INET6_ATON()和 INET6_NTOA()來轉化:
Mysql> SELECT HEX(INET6_ATON(‘1030::C9B4:FF12:48AA:1A2B’))
Java
| HEX(INET6_ATON(‘1030::C9B4:FF12:48AA:1A2B’))|
| 1030000000000000C9B4FF1248AA1A2B
1 row in set
mysql> SELECT INET6_NTOA(UNHEX('1030000000000000C9B4FF1248AA1A2B
| INET6_NTOA(UNHEX(‘1030000000000000C9B4FF1248AA1A2B’))
| 1030::c9b4:ff12:48aa:1a2b
1 row in set
然后將數據庫定義為varbinary 類型,分配 128bits空間(因為ipv6采用的是128bits,16個字節)
間。;或者定義為char 類型,分配 32bits空
如何實現MySQL的讀寫分離?
其實很簡單,就是基于主從復制架構,簡單來說,就搞一個主庫,掛多個從庫,然后我們就單單只是寫主庫,然后主庫會自動把數據給同步到從庫上去。
MySQL主從復制原理的是啥?
主庫將變更寫入binlog日志,然后從庫連接到主庫之后,從庫有一個1O線程,將主庫的binlog日志拷貝到自己本地,寫入一個relay 中繼日志中。接著從庫中有一個SQL線程會從中繼日志讀取binlog,然后執行binlog日志中的內容,也就是在自己本地再次執行一遍SQL,這樣就可以保證自己跟主庫的數據是一樣的。
這里有一個非常重要的一點,就是從庫同步主庫數據的過程是串行化的,也就是說主庫上并行的操作,在從庫上會串行執行。所以這就是一個非常重要的點了,由于從庫從主庫拷貝日志以及串行執行SQL的特點,在高并發場景下,從庫的數據一定會比主庫慢一些,是有延時的。所以經常出現,剛寫入主庫的數據可能是讀不到的,要過幾十毫秒,甚至幾百毫秒才能讀取到。
而且這里還有另外一個問題,就是如果主庫突然宕機,然后恰好數據還沒同步到從庫,那么有些數據可能在從庫上是沒有的,有些數據可能就
丟失了。
所以MySQL實際上在這一塊有兩個機制,一個是半同步復制,用來解決主庫數據丟失問題;一個是并行復制,用來解決主從同步延時問題。
這個所謂半同步復制,也叫semi-sync復制,指的就是主庫寫入binlog日志之后,就會將強制此時立即將數據同步到從庫,從庫將日志寫入
自己本地的relay log之后,接著會返回一個ack給主庫,主庫接收到至少一個從庫的ack之后才會認為寫操作完成了。
所謂并行復制,指的是從庫開啟多個線程,并行讀取relay log中不同庫的日志,然后并行重放不同庫的日志,這是庫級別的并行。
MySQL主從同步延時問題
以前線上確實處理過因為主從同步延時問題而導致的線上的bug,屬于小型的生產事故。
是這個么場景。有個同學是這樣寫代碼邏輯的。先插入一條數據,再把它查出來,然后更新這條數據。在生產環境高峰期,寫并發達到了2000/s,這個時候,主從復制延時大概是在小幾十毫秒。線上會發現,每天總有那么一些數據,我們期望更新一些重要的數據狀態,但在高峰期時候卻沒更新。用戶跟客服反饋,而客服就會反饋給我們。
查看 Seconds_Behind_Master,可以看到從庫復制主庫的數據落后了幾ms。
一般來說,如果主從延遲較為嚴重,有以下解決方案:
·分庫,將一個主庫拆分為多個主庫,每個主庫的寫并發就減少了幾倍,此時主從延遲可以忽略不計。
打開 MySQL支持的并行復制,多個庫并行復制。如果說某個庫的寫入并發就是特別高,單庫寫并發達到了2000/s,并行復制還是沒意義。
重寫代碼,寫代碼的同學,要慎重,插入數據時立馬查詢可能查不到。
如果確實是存在必須先插入,立馬要求就查詢到,然后立馬就要反過來執行一些操作,對這個查詢設置直連主庫。不推薦這種方法,你這么搞導致讀寫分離的意義就喪失了。
A
1、B樹和B+樹之間的區別是什么?
2、Innodb中的B+樹有什么特點?
3、什么是Innodb中的page?
4、Innodb中的B+樹是怎么產生的?
5、什么是聚簇索引?
6、Innodb是如何支持范圍查找能走索引的?
7、什么聯合索引?對應的B+樹是如何生成的?
8、什么是最左前綴原則?
9、為什么要遵守最左前綴原則才能利用到索引?
10、什么是索引條件下推?
11、什么是覆蓋索引?
12、有哪些情況會導致索引失效?
一、MySQL有哪幾種數據存儲引擎?有什么區別?
二、什么是臟讀、幻讀、不可重復讀?要怎么處理?
三、事務的基本特性和隔離級別有哪些?
四、MySQL的鎖有哪些?什么是間隙鎖?
五、MySQL的索引結構是什么樣的?聚簇索引和非聚簇索引又是什
么?
六、MySQL的集群是如何搭建的?讀寫分離是怎么做的?
一、MySQL有哪幾種數據存儲引擎?有什么區別?
什么是索引下推?
::索引下推(INDEX CONDITION PUSHDOWN,簡稱ICP)是在MySQL5.6針對掃描二級索引的一項優化改進。總的來說是通過把索引過濾條件下推到存儲引擎,來減少MySQL存儲引擎訪問基表的次數以及MySQL服務層訪問存儲引擎的次數。ICP適用于MYISAM和INNODB,本篇的內容只基于INNODB。
在講這個技術之前你得對mysql架構有一個簡單的認識,見下圖
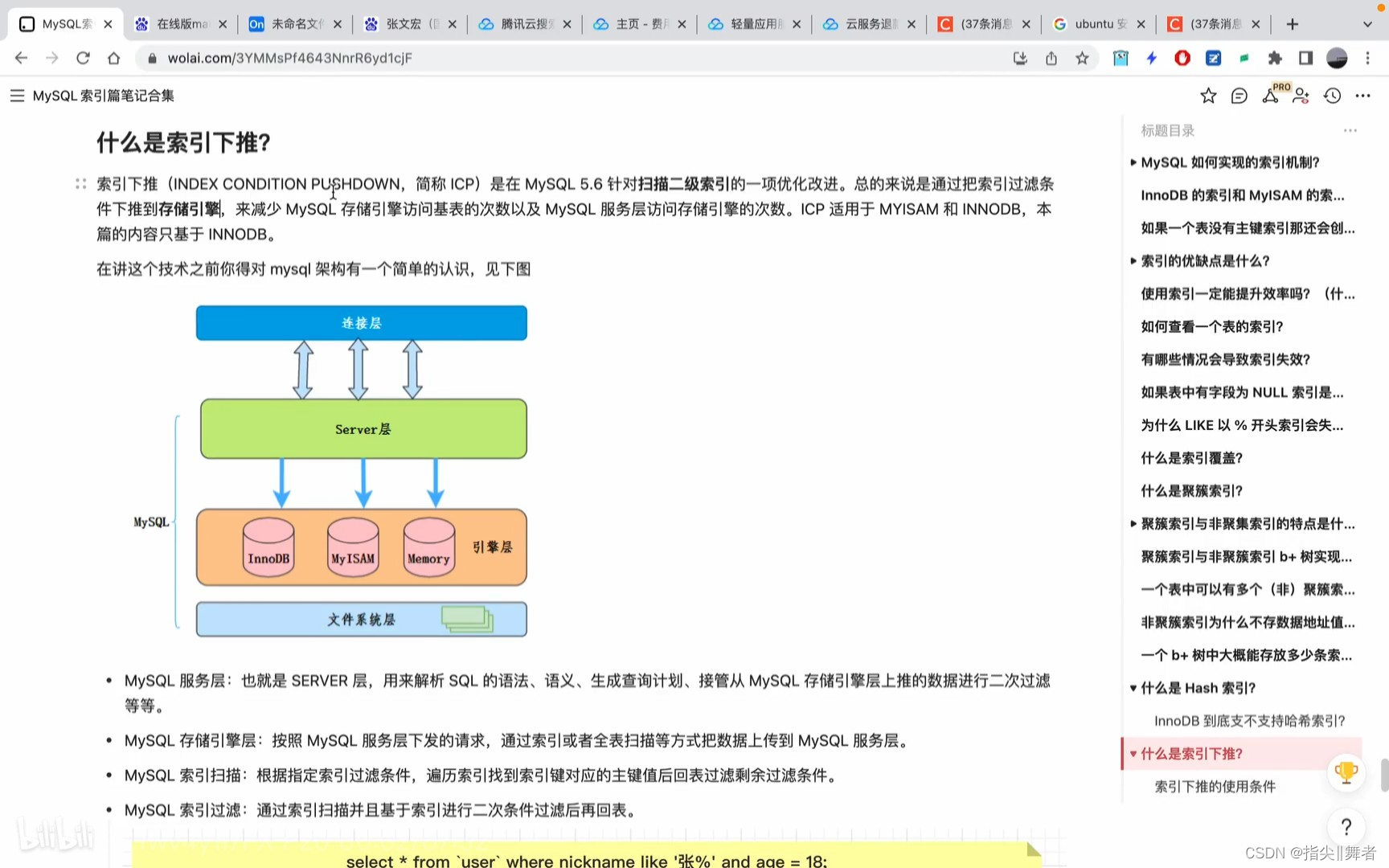
MySQL服務層:也就是SERVER層,用來解析SQL的語法、語義、生成查詢計劃、接管從MySQL存儲引擎層上推的數據進行二次過濾
等等。
MySQL存儲引擎層:按照MySQL服務層下發的請求,通過索引或者全表掃描等方式把數據上傳到MySQL服務層。
MySQL 索引掃描:根據指定索引過濾條件,遍歷索引找到索引鍵對應的主鍵值后回表過濾剩余過濾條件。
MySQL索引過濾:通過索引掃描并且基于索引進行二次條件過濾后再回表。
select * from ‘user’ where nickname like ‘張%’ and age = 18:
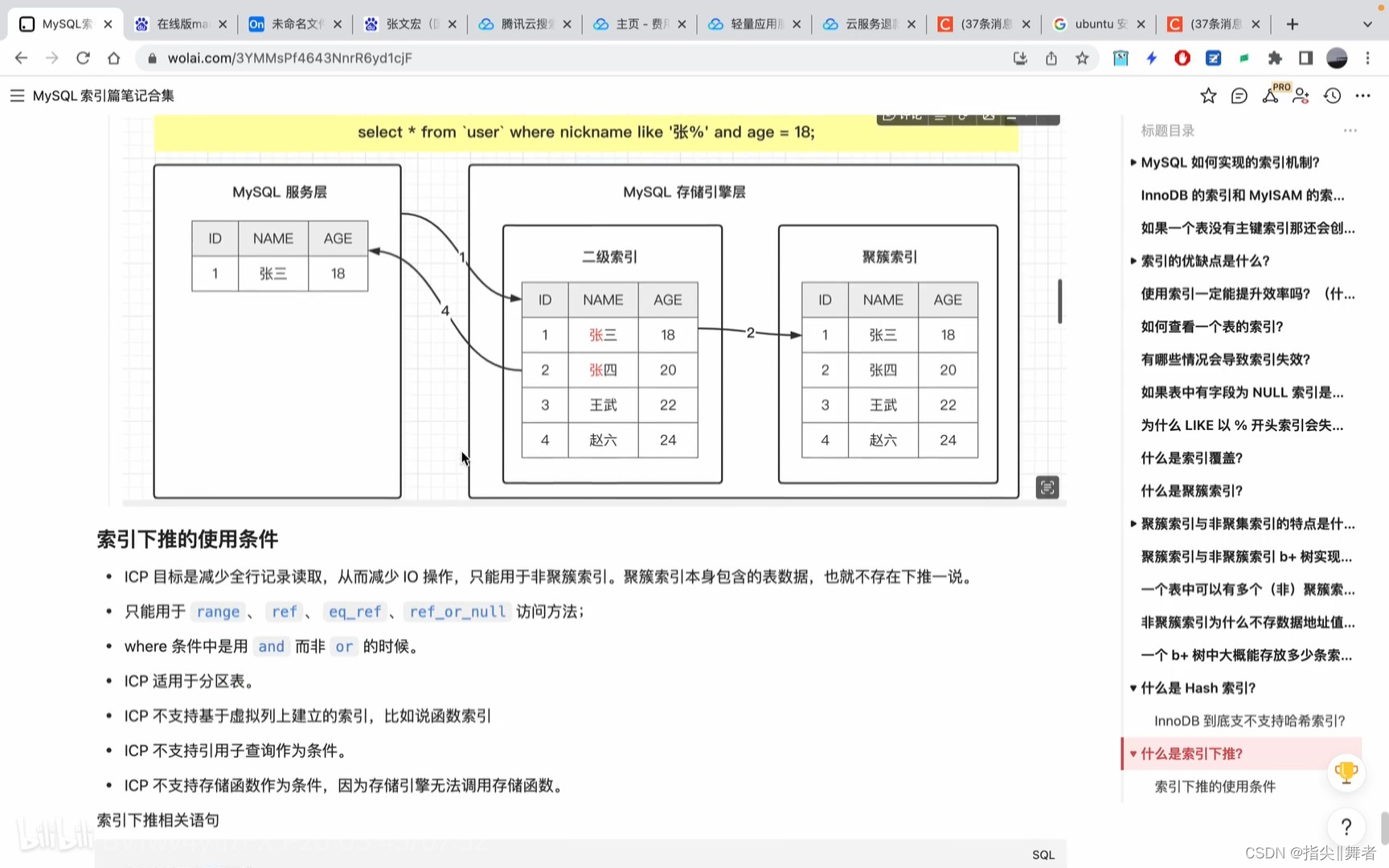
索引下推的使用條件
?ICP目標是減少全行記錄讀取,從而減少10操作,只能用于非聚簇索引。聚簇索引本身包含的表數據,也就不存在下推一說。
只能用于range、ref.
where 條件中是用
eq_ref、ref_or_null 訪問方法;and而非or的時候。
ICP 適用于分區表。
ICP 不支持基于虛擬列上建立的索引,比如說函數索引
ICP不支持引用子查詢作為條件。
ICP不支持存儲函數作為條件,因為存儲引擎無法調用存儲函數。
索引下推相關語句
#查看索引下推是否開啟
select @@optimizer_switch
#開啟索引下推
set optimizer_switch=“index_condition_pushdown=on”;
#關閉索引下推
set optimizer_switch=“index_condition_pushdown=off”;
有哪些情況會導致索引失效?
這個問題要分版本回答!!!版本不同可能會導致索引失效的場景也不同,直接給答案的都是耍流氓!!!
這里回答基于最新MySQL8版,MySQL8失效的以前版本也失效,MySQL8不失效的,以前可能會失
效。
使用
like 并且是左邊帶%,右邊可以帶會走索引(但是并不絕對,詳細解釋看下面 like專題分析)
隱式類型轉換,索引字段與條件或關聯字段的類型不一致。(比如你的字段是int,你用字符串方式去查
詢會導致索引失效)。
在where條件里面對索引列使用運算或者使用函數。
使用
且存在非索引列
在 where 條件中兩列做比較會導致索引失效
使用IN可能不會走索引(MySQL環境變量eq_range_index_dive_limit 的值對IN語法有很大影
響,該參數表示使用索引情況下 IN中參數的最大數量。MySQL 5.7.3以及之前的版本中,
舉例,
eq_range_index_dive_limit 的默認值為10,之后的版本默認值為200。我們拿 MySQL8.0.19 eq_range_index_dive_limit=200表示當IN(…)中的值 >200個時,該查詢一定不會走<=200則可能用到索引。)
索引。
使用非主鍵范圍條件查詢時,部分情況索引失效。
使用 order by可能會導致索引失效
is null
is not null ≠可能會導致索引失效
如果表中有字段為NULL索引是否會失效?
為什么LIKE以%開頭索引會失效?
數據結構和算法動態可視化(Ch
首先看看B+樹是如何查找數據的:
查找數據時,MySQL會從根節點開始,按照從左到右的順序比較查詢條件和節點中的鍵值。如果查詢條件小于節點中的鍵值,則跳到該節點的左子節點繼續查找;如果查詢條件大于節點中的鍵值,則跳到該節點的右子節點繼續查找;如果查詢條件等于節點中的鍵值,則繼續查找該節點的下一個節點。
比如說我有下面這條SQL:
select
from
where nickname
如果數據庫中存在南冥
北冥
西冥
東冥,那么在B+樹中搜索的效率和全表掃描還有什么區別呢?
走的聚簇索引全表掃描還不用回表。
最后在擴展講一個點,其實不一定會導致索引失效。舉個例子:
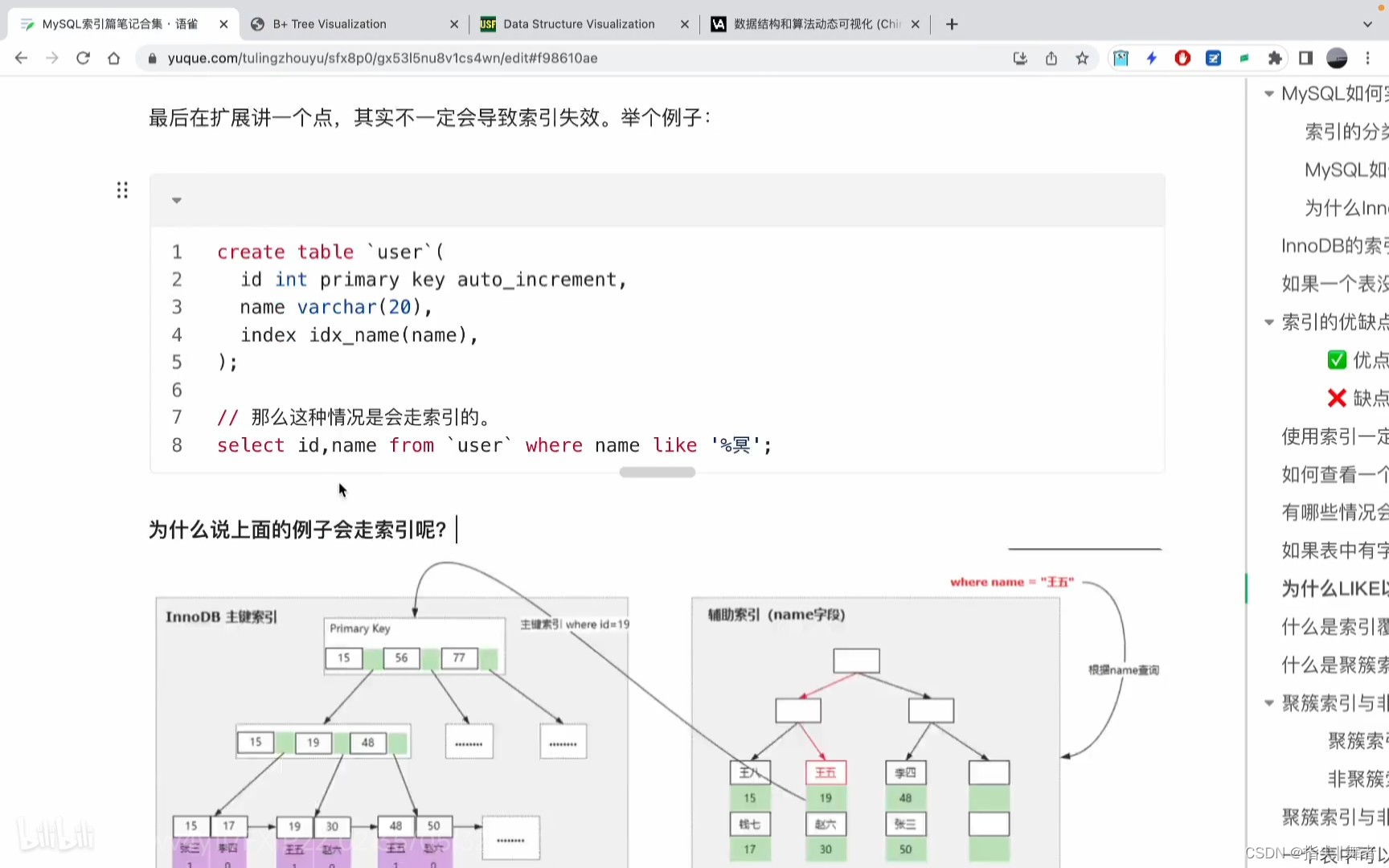
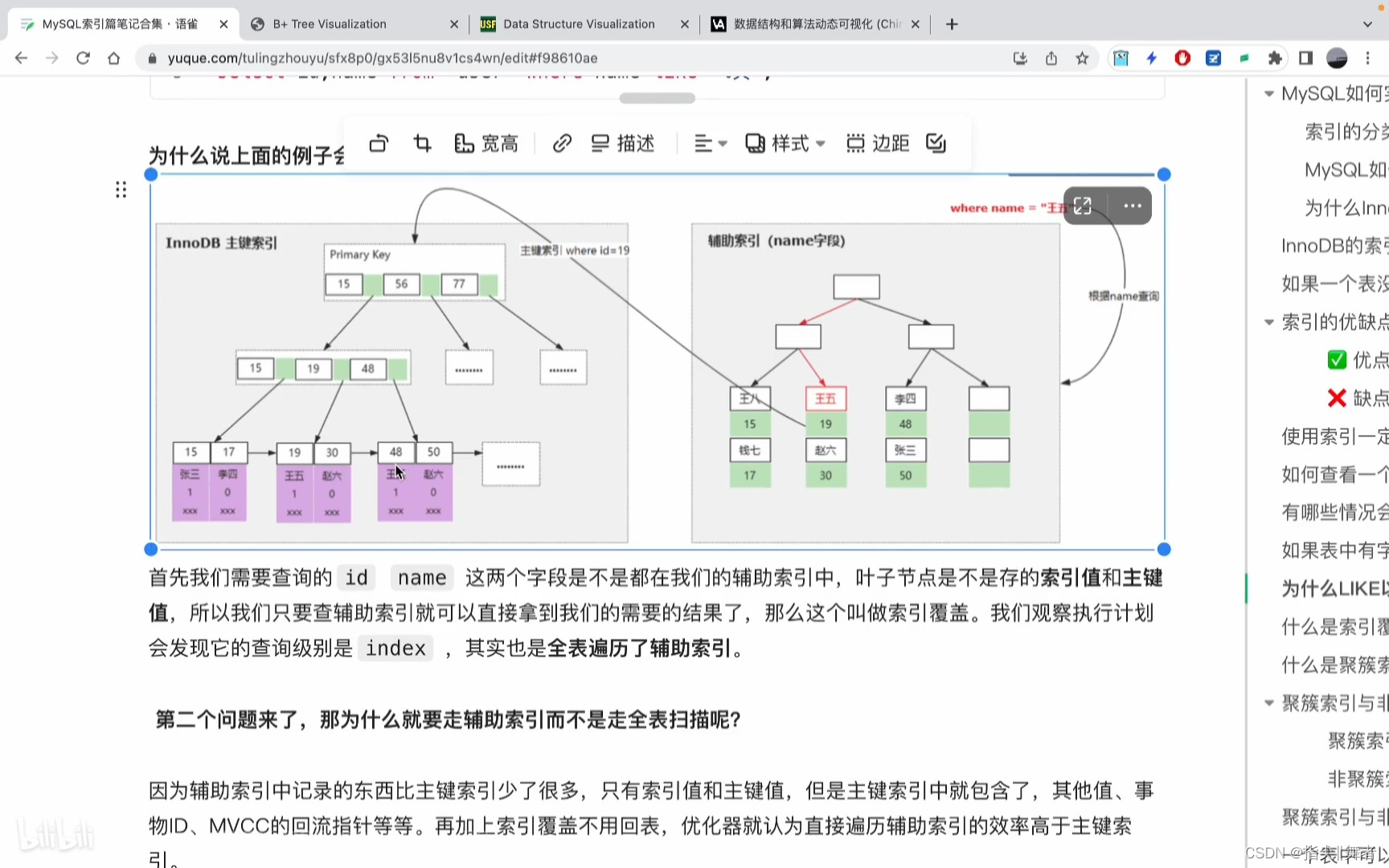
如果表中有字段為NULL索引是否會失效?
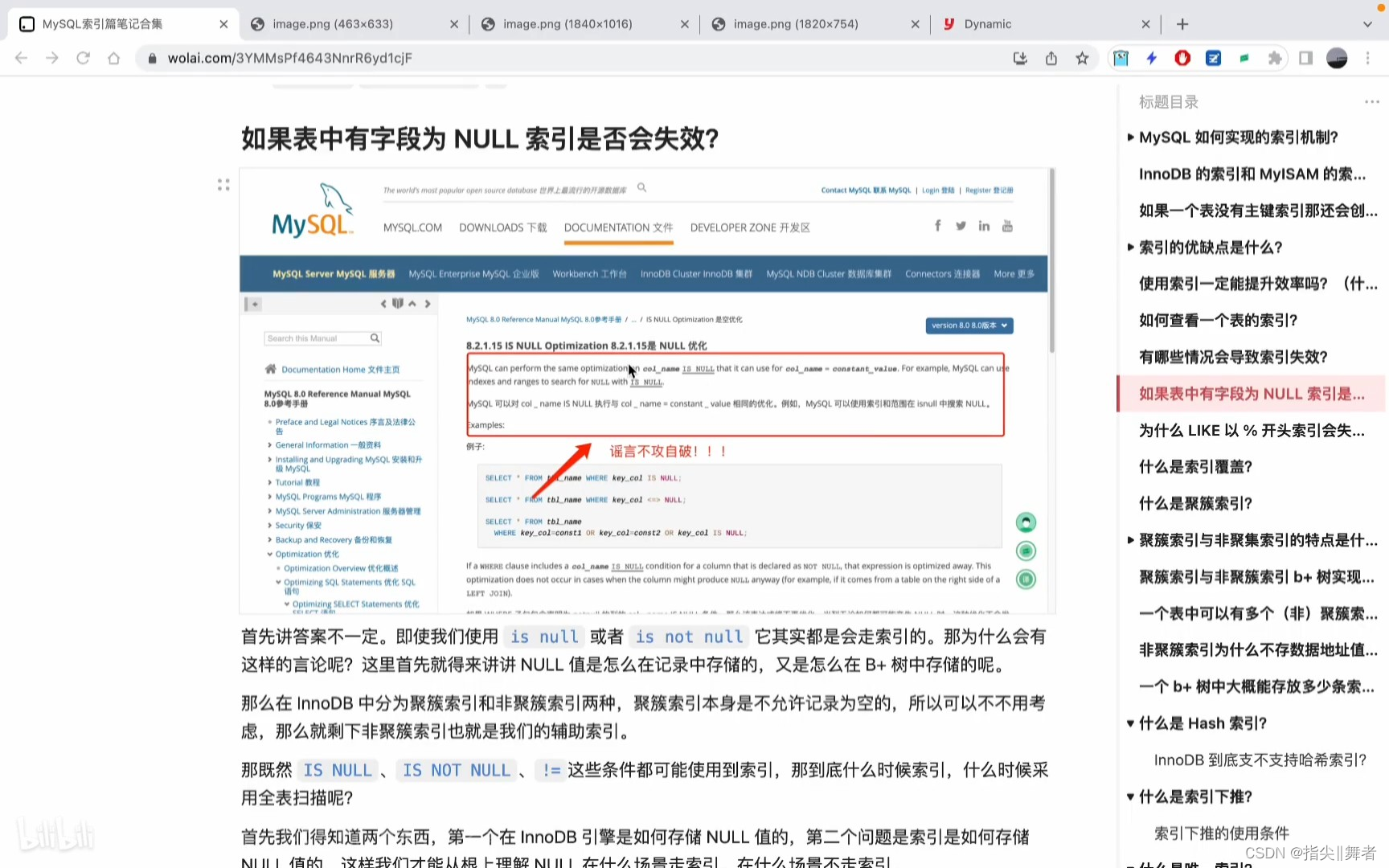
首先講答案不一定。即使我們使用 is null 或者 is not null它其實都是會走索引的。那為什么會有這樣的言論呢?這里首先就得來講講NULL值是怎么在記錄中存儲的,又是怎么在B+樹中存儲的呢。那么在InnoDB中分為聚簇索引和非聚簇索引兩種,聚簇索引本身是不允許記錄為空的,所以可以不不用考慮,那么就剩下非聚簇索引也就是我們的輔助索引。
那既然IS NULL
用全表掃描呢?
IS NOT NULL、
!= 這些條件都可能使用到索引,那到底什么時候索引,什么時候采
首先我們得知道兩個東西,第一個在InnoDB引擎是如何存儲NULL值的,第二個問題是索引是如何存儲
NUI|值的
這樣我們才能從根上理解 NUIL 在什么場景走索引。在什么場景不走索引
在InnoDB引擎是如何存儲NULL值的?
InnoDB引擎通過使用一個特殊的值來表示null,這個值通常被稱為"null bitmap"。null bitmap是一個二進制位序列,用來標記表中每一個列是否為null。當null bitmap中對應的位為1時,表示對應的列為null;當null bitmap中對應的位為0時,表示對應的列不為nul。在實際存儲時,InnoDB引擎會將null bitmap作為行記錄的一部分,存儲在行記錄的開頭,這樣可以在讀取行記錄時快速判斷每個列是否為null。
從頭開始說理解起來會比較容易,理解了獨占表空間文件就更容易理解行格式了,接著往下看:
當我們創建表的時候默認會創建一個*.idb文件,這個文件又稱為獨占表空間文件,它是由段、區、頁、
行組成。InnoDB存儲引擎獨占表空間大致如下圖;
表空間(Tablespace)
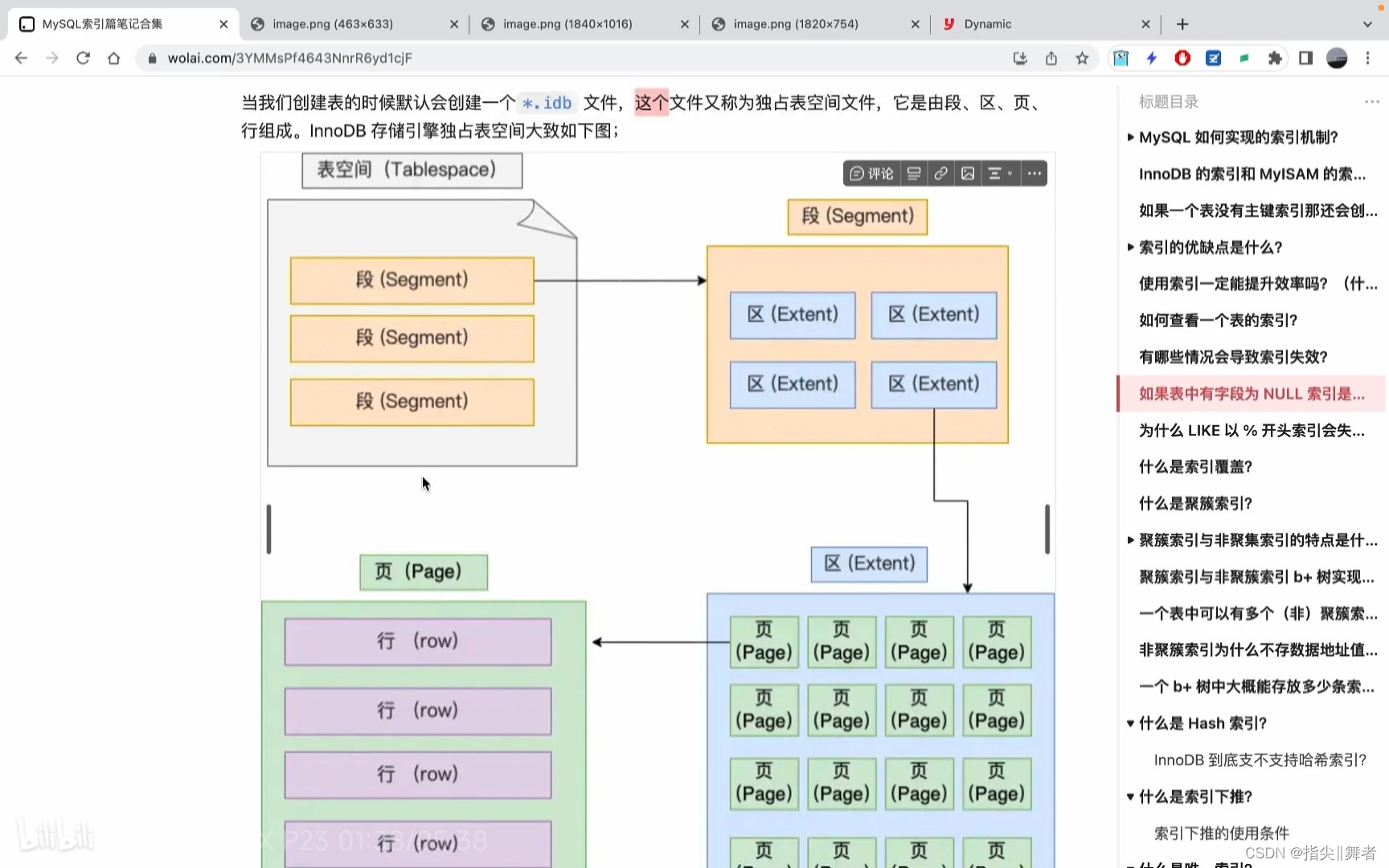
Segment(表空間)是由各個段(segment)組成的,段是由多個區(extent)組成的。段一般分為數據段、
索引段和回滾段等。
、數據段 存放B+樹的葉子節點的區的集合
索引段存放B+樹的非葉子節點的區的集合
回滾段 存放的是回滾數據的區的集合,MVCC就是利用了回滾段實現了多版本查詢數據
Extent(區)在表中數據量大的時候,為某個索引分配空間的時候就不再按照頁為單位分配了,而是按照區(extent)為單位分配。每個區的大小為1MB,對于16KB的頁來說,連續的64個頁會被劃為一個區,這樣就使得鏈表中相鄰的頁的物理位置也相鄰,就能使用順序|/O了。
(我們知道InnoDB存儲引擎是用B+樹來組織數據的。B+樹中每一層都是通過雙向鏈表連接起來的,如果是以頁為單位來分配存儲空間,那么鏈表中相鄰的兩個頁之間的物理位置并不是連續的,可能離得非常遠,那么磁盤查詢時就會有大量的隨機/O,隨機|/O是非常慢的。解決這個問題也很簡單,就是讓鏈表中相鄰的頁的物理位置也相鄰,這樣就可以使用順序|/0了,那么在范圍查詢(掃描葉子節點)的時候性能就會很高。)
Page(頁)記錄是按照行來存儲的,但是數據庫的讀取并不以「行」為單位,否則一次讀取(也就是一次1/0
操作)只能處理一行數據,效率會非常低。
因此,InnoDB的數據是按「頁」為單位來讀寫的,也就是說,當需要讀一條記錄的時候,并不是將這個行
記錄從磁盤讀出來,而是以頁為單位,將其整體讀入內存。
默認每個頁的大小為16KB,也就是最多能保證16KB的連續存儲空間。
頁是InnoDB存儲引擎磁盤管理的最小單元,意味著數據庫每次讀寫都是以16KB為單位的,一次最少從磁盤中讀取16K的內容到內存中,一次最少把內存中的16K內容刷新到磁盤中。
頁的類型有很多,常見的有數據頁、undo日志頁、溢出頁等等。數據表中的行記錄是用「數據頁」來管理
的,數據頁的結構這里我就不講細說了,總之知道表中的記錄存儲在「數據頁」里面就行。
Row(行)數據庫表中的記錄都是按行(row)進行存放的,每行記錄根據不同的行格式,有不同的存儲結
構。
重點來了!!!
InnoDB提供了4種行格式,分別是Redundant、Compact、Dynamic和Compressed行格式。
Redundant 是很古老的行格式了,MySQL5.0版本之前用的行格式,現在基本沒人用了,那就不展開
詳講了。
MySQL 5.0之后引入了Compact 行記錄存儲方式,由于Redundant不是一種緊湊的行格式,而采用更為緊湊的Compact,設計的初衷就是為了讓一個數據頁中可以存放更多的行記錄,從MySQL5.1版本之后,行格式默認設置成Compact。
Dynamic 和Compressed 兩個都是緊湊的行格式,它們的行格式都和Compact 差不多,因為都是基
于Compact改進一點東西。從MySQL5.7版本之后,默認使用Dynamic行格式。
那么我們來看看Dynamic里面長什么樣,先混個臉熟。

這里簡單介紹一下,Dynamic行格式其他內容后面單獨出一個章節介紹。
NULL值列表(本問題介紹重點)
表中的某些列可能會存儲NULL值,如果把這些NULL值都放到記錄的真實數據中會比較浪費空
間,所以Compact行格式把這些值為NULL的列存儲到NULL值列表中。如果存在允許 NULL值的列,則每個列對應一個二進制位(bit),二進制位按照列的順序逆序排列。
二進制位的值為 1時,代表該列的值為NULL。二進制位的值為0時,代表該列的值不為
NULL。另外,NULL值列表必須用整數個字節的位表示(1字節8位),如果使用的二進制位個數
不足整數個字節,則在字節的高位補0。
當然NULL值列表也不是必須的。當數據表的字段都定義成NOTNULL的時候,這時候表里的行格
式就不會有NULL值列表了。所以在設計數據庫表的時候,通常都是建議將字段設置為NOT
NULL,這樣可以節省1字節的空間(NULL值列表占用1字節空間)。
廠NULL值列表」的空間不是固定1字節的。當一條記錄有9個字段值都是NULL,那么就會創建2字節空間的「NULL值列表」,以此類推。
索引是如何存儲NULL值的?
我們知道 InnoDB引擎中按照物理存儲的不同分為聚簇索引和非聚簇索引,聚簇索引也就是主鍵索引,那么是不允許為空的。那就不再我們本問題的討論范圍,我們重點來看看非聚簇索引,非聚簇索引是允許值為空的。
在InnoDB中非聚簇索引是通過B+樹的方式進行存儲的
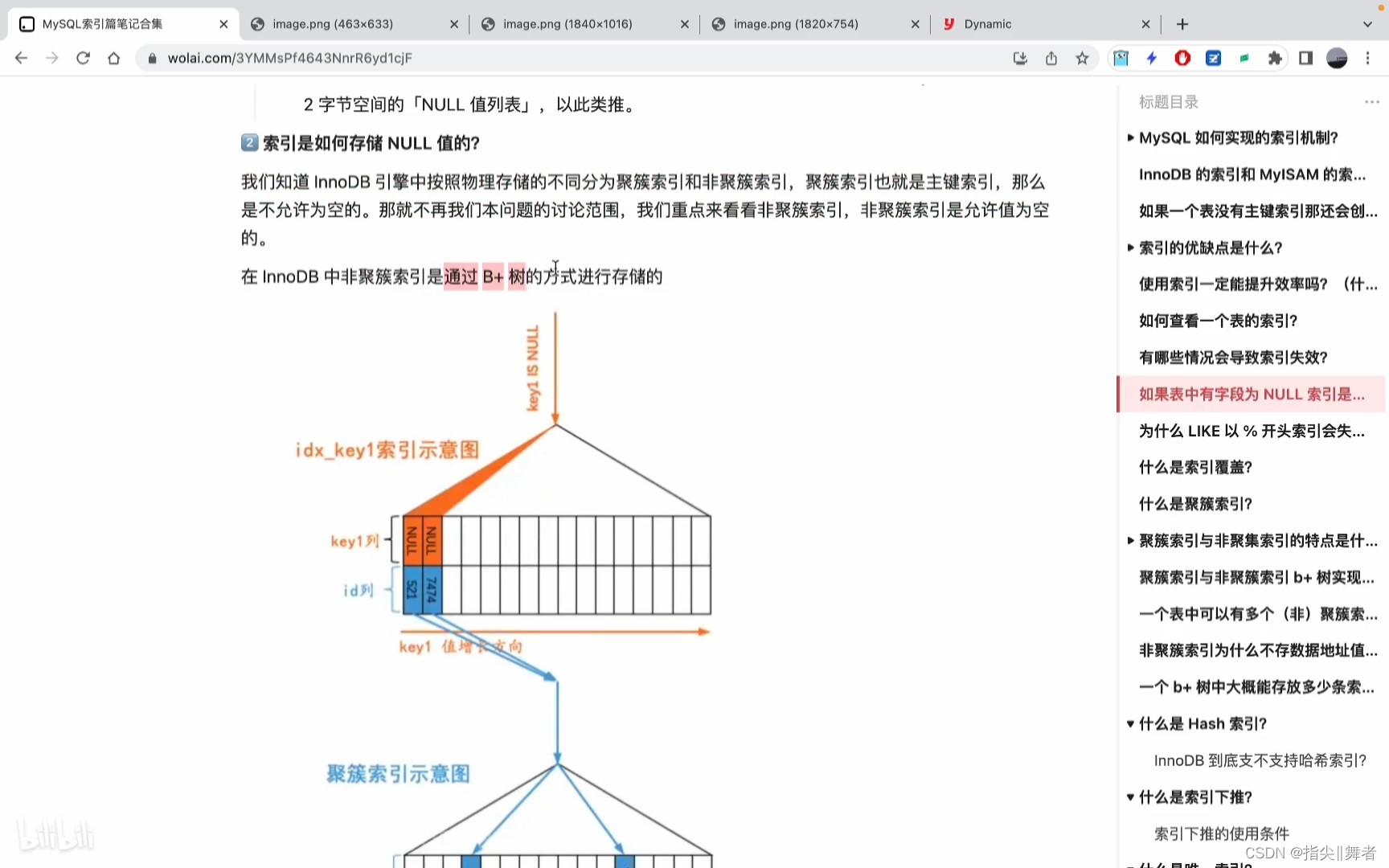
從圖中可以看出,對于 s1表的二級索引 idx_key1 來說,值為 NULL的二級索引記錄都被放在了
B+ 樹的最左邊,這是因為設計 InnoDB 的大叔有這樣的規定:
We define the SQL null to be the smallest possible value of a field
也就是說他們把 SQL中的NULL值認為是列中最小的值。在通過二級索引idx_key1對應的B+樹快速定位到葉子節點中符合條件的最左邊的那條記錄后,也就是本例中id值為521的那條記錄之后,就可以順著每條記錄都有的next_record屬性沿著由記錄組成的單向鏈表去獲取記錄了,直到某條記錄的key1列不為NULL。
我們了解了上面的兩個問題之后,我們就可以來看看,使不使用索引的依據是什么了
實際上來說我們用
is null is not null ≠這些條件都是能走索引的,那什么時候走索引什么時候走
全表掃描呢?
總結起來就是兩個字:成本!!!
如何去度量成本計算使用某個索引執行查詢的成本就非常復雜了,展開講這個話題就停不下來了,后面考慮
單獨列一個篇幅去講。
這里總結性講講:第一個,讀取二級索引記錄的成本,第二,將二級索引記錄執行回表操作,也就是到聚簇
索引中找到完整的用戶記錄操作所付出的成本。
要掃描的二級索引記錄條數越多,那么需要執行的回表操作的次數也就越多,達到了某個比例時,使用二級索引執行查詢的成本也就超過了全表掃描的成本(舉一個極端的例子,比方說要掃描的全部的二級索引記錄,那就要對每條記錄執行一遍回表操作,自然不如直接掃描聚簇索引來的快)
所以MySQL優化器在真正執行查詢之前,對于每個可能使用到的索引來說,都會預先計算一下需要掃描的
二級索引記錄的數量,比方說對于下邊這個查詢:
SELECT * FROM SI WHERE key1 IS NULL;
優化器會分析出此查詢只需要查找key1 值為NULL的記錄,然后訪問一下二級索引
idx_key1,看一下值為 NULL的記錄有多少(如果符合條件的二級索引記錄數量較少,那么統計結果是精確的,如果太多的話,會采用一定的手段計算一個模糊的值,當然算法也比較麻煩,我們就不展開說了),這種在查詢真正執行前優化器就率先訪問索引來計算需要掃描的索引記錄數量的方式稱之為index dive。當然,對于某些查詢,比方說WHERE子句中有IN條件,并且IN條件中包含許多參數的話,比方說這樣:
SQL
SELECT * FROM s1 WHERE key1 IN (‘a’,‘b
zzzzzzz’
這樣的話需要統計的key1 值所在的區間就太多了,這樣就不能采用 index dive 的方式去真正的訪問二級索引idx_key1,而是需要采用之前在背地里產生的一些統計數據去估算匹配的二級索引記錄有多少條(很顯然根據統計數據去估算記錄條數比 index dive 的方式精確性差了很多)。
反正不論采用 index dive 還是依據統計數據估算,最終要得到一個需要掃描的二級索引記錄條數,如果這個條數占整個記錄條數的比例特別大,那么就趨向于使用全表掃描執行查詢,否則趨向于使用這個索引執行查詢。
理解了這個也就好理解為什么在WHERE子句中出現 IS NULL、
!=這些條件仍然可以
使用索引,本質上都是優化器去計算一下對應的二級索引數量占所有記錄數量的比值而已。
大家可以看到,MySQL 中決定使不使用某個索引執行查詢的依據很簡單:就是成本夠不夠小。而不是是否在WHERE子句中用了 IS NULL、IS NOT NULL、!=這些條件。大家以后也多多辟謠吧,沒那么復雜,只是一個成本而已。
為什么LIKE以%開頭索引會失效?
首先看看B+樹是如何查找數據的:
// 特殊情況,這種也是會走索引的,雖然我的age在前面,username在后面。
/ 剛剛不是手最左前綴匹配嗎,為什么放到第二位也可以呢?
// 雖說順序不一致,但是在SQL執行過程中,根據查詢條件命中索引// 無論我username在不在前面,都會按照username去進行索引查找。select * from user where age = 18 and username =‘張三
使用Order By時能否通過索引排序?
我們知道在很多場景下會導致索引失效,比如說沒有遵循B+樹的最左匹配原則,但是也有一些情況是遵循了最左匹配原則但是還是沒有走索引,這里我們使用order by進行排序的時候就有不走索引的情況,那么帶大家來分析一下
SQL
drop table if exists drop table if exists create table ‘user’(
user
user_examp te
id` int primary key comment’主鍵ID’
card_id’ int comment’身份證’,
nickname’varchar(10)comment‘昵稱’,age’ int not null comment’年齡’,‘card_id’ (‘card_id’)
key
) engine=InnoDB default charset=utf8mb4;
//這里我們明明對card_id建好了單列索引,那為什么不走索引呢?
select * from ‘user’ order by card_id
如果索引覆蓋是可以走索引的
如果帶上索引條件是可以走索引的
通過索引排序內部流程是什么呢?
explain select nickname,card_id,age from user order by card_id;
我們在了解mysql底層是怎么排序的之前,我們先來了解一下一個概念 sort buffen
首先mysql會為每一個線程都分配一個固定大小的sort buffer 用于排序。它是一個具有邏輯概念的
內存區域,我們可以通過sort_buffer_size 參數來控制,默認值是 256kb
// 輸入查看最,小可以設置為32K,最大可以設置為46。
show variables like ‘sort_buffer_size’;
SQL
由于 sort buffer 大小是一個固定的,但是我們待排序的數據量它不是,所以根據它們之間的一個差值
呢,就分為了內部排序和外部排序
當待排序的數據量小于等于sort buffer 時,那我們的sort buffer 就能夠容納,MySQL就可以直接
在內存里面排序就行了,內部排序使用的排序算法是 快排
當待排序的數據量大于 sort buffer時,那我們的sort buffer 就不夠用了對吧。這個時候MySQL就得要借助外部文件來進行排序了。將待排序數據拆成多個小文件,對各個小文件進行排序,最后再匯總成一個有序的文件,外部排序使用的算法時 歸并排序
我們來聊聊row_id排序
和大家說一個這個參數max_length_for_sort_data ,在我們MySQL中專門控制用戶排序的行數據長
度參數。默認是4096,也就是說如果超過了這個長度MySQL就會自動升級成
row_id 算法。
//默認max_length_for_sort_data的大小為4096字節
show variables like ‘max_Length_for_sort_data’
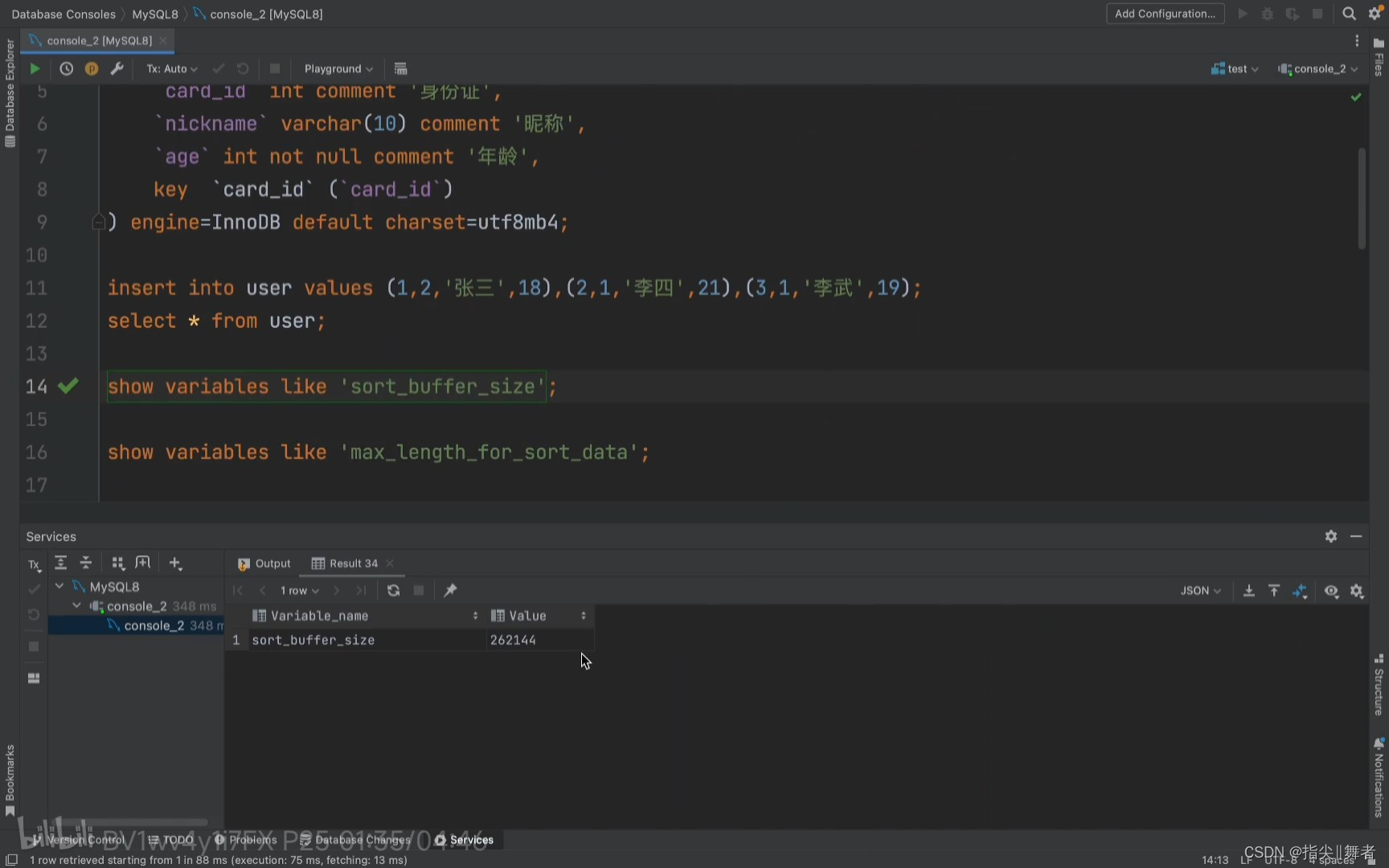
row_id 排序的思想就是把不需要的數據不放到
sort buffe中,讓sort buffer只存放需要排序的字段。
explain select nickname,card_id,age from user order by card_id;
SQL
我們前面說到了sort buffer,在 sort buffer 里面進行排序的數據是我們select的全部字段,所以當我們查詢的字段越多,那么 sort buffer 能容納的數據量也就越小。而通過row_id 排序就只會存放row_id 字段和排序相關的字段。其余的字段等排序完成之后通過主鍵1D進行回表拿。
group by分組和order by在索引使用上有什么不同嗎?
沒什么太大的差異 group by實際是先進行排序,再進行分組。所以遵循order by的索引機制。
索引的基本原理
索引用來快速地尋找那些具有特定值的記錄。如果沒有索引,一般來說執行查詢時遍歷整張表。
索引的原理:就是把無序的數據變成有序的查詢
1.把創建了索引的列的內容進行排序
2.對排序結果生成倒排表
3.在倒排表內容上拼上數據地址鏈
4.在查詢的時候,先拿到倒排表內容,再取出數據地址鏈,從而拿到具體數據
索引設計的原則?
查詢更快、占用空間更小
1.適合索引的列是出現在where子句中的列,或者連接子句中指定的列
2.基數較小的類,索引效果較差,沒有必要在此列建立索引
3.使用短索引,如果對長字符串列進行索引,應該指定一個前綴長度,這樣能夠節省大量索引空間,如果搜索詞
超過索引前綴長度,則使用索引排除不匹配的行,然后檢查其余行是否可能匹配。
4.不要過度索引。索引需要額外的磁盤空間,并降低寫操作的性能。在修改表內容的時候,索引會進行更新甚至
重構,索引列越多,這個時間就會越長。所以只保持需要的索引有利于查詢即可。
5.定義有外鍵的數據列一定要建立索引。
6.更新頻繁字段不適合創建索引
7.若是不能有效區分數據的列不適合做索引列(如性別,男女未知,最多也就三種,區分度實在太低)
8.盡量的擴展索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那么只需要修改原來的索
引即可。
9.對于那些查詢中很少涉及的列,重復值比較多的列不要建立索引。
10.對于定義為text、image和bit的數據類型的列不要建立索引。
索引覆蓋是什么
索引覆蓋就是一個SQL在執行時,可以利用索引來快速查找,并且此SQL所要查詢的字段在當前索引對應的字段中都包含了,那么
就表示此SQL走完索引后不用回表了,所需要的字段都在當前索引的葉子節點上存在,可以直接作為結果返回了
最左前綴原則是什么
當一個SQL想要利用索引是,就一定要提供該索引所對應的字段中最左邊的字段,也就是排在最前面的字段,比如針對a,b,c三個字段建立了一個聯合索引,那么在寫一個sql時就一定要提供a字段的條件,這樣才能用到聯合索引,這是由于在建立a,b,c三個字段的聯合索引時,底層的B+樹是按照a,bc三個字段從左往右去比較大小進行排序的,所以如果想要利用B+樹進行快速查找也得符合這個規則
Innodb是如何實現事務的
Innodb通過Buffer Pool,LogBuffer,Redo Log,Undo Log來實現事務,以一個update語句為例:1.Innodb在收到一個update語句后,會先根據條件找到數據所在的頁,并將該頁緩存在Buffer Pool中2.執行update語句,修改Buffer Pool中的數據,也就是內存中的數據
3.針對update語句生成一個RedoLog對象,并存入LogBuffer中
4.針對update語句生成undolog日志,用于事務回滾
5.如果事務提交,那么則把RedoLog對象進行持久化,后續還有其他機制將Buffer Pool中所修改的數據頁持久化到磁盤中
6.如果事務回滾,則利用undolog日志進行回滾
MySQL的集群是如何搭建的?讀寫分離是怎么做的?
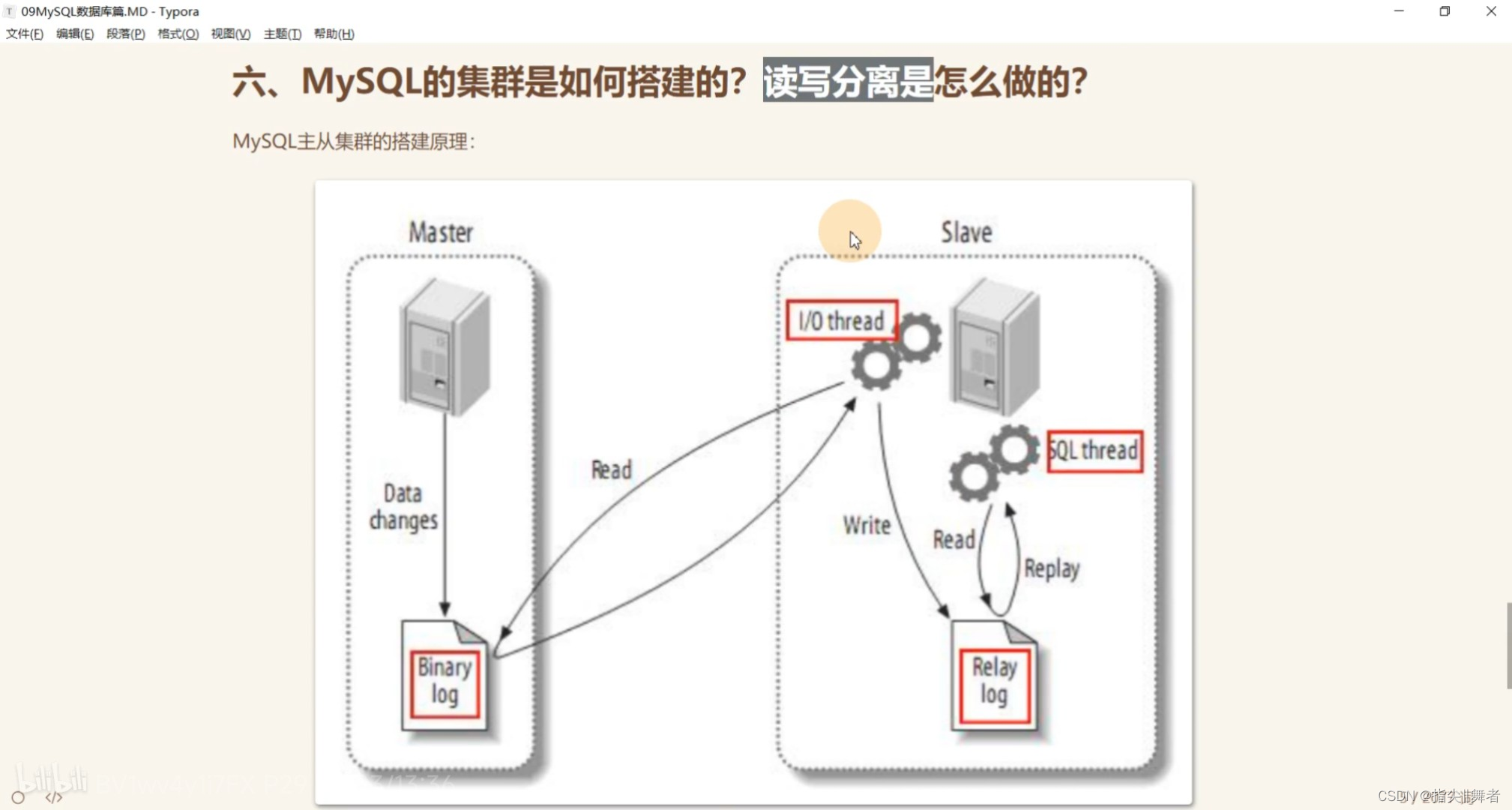
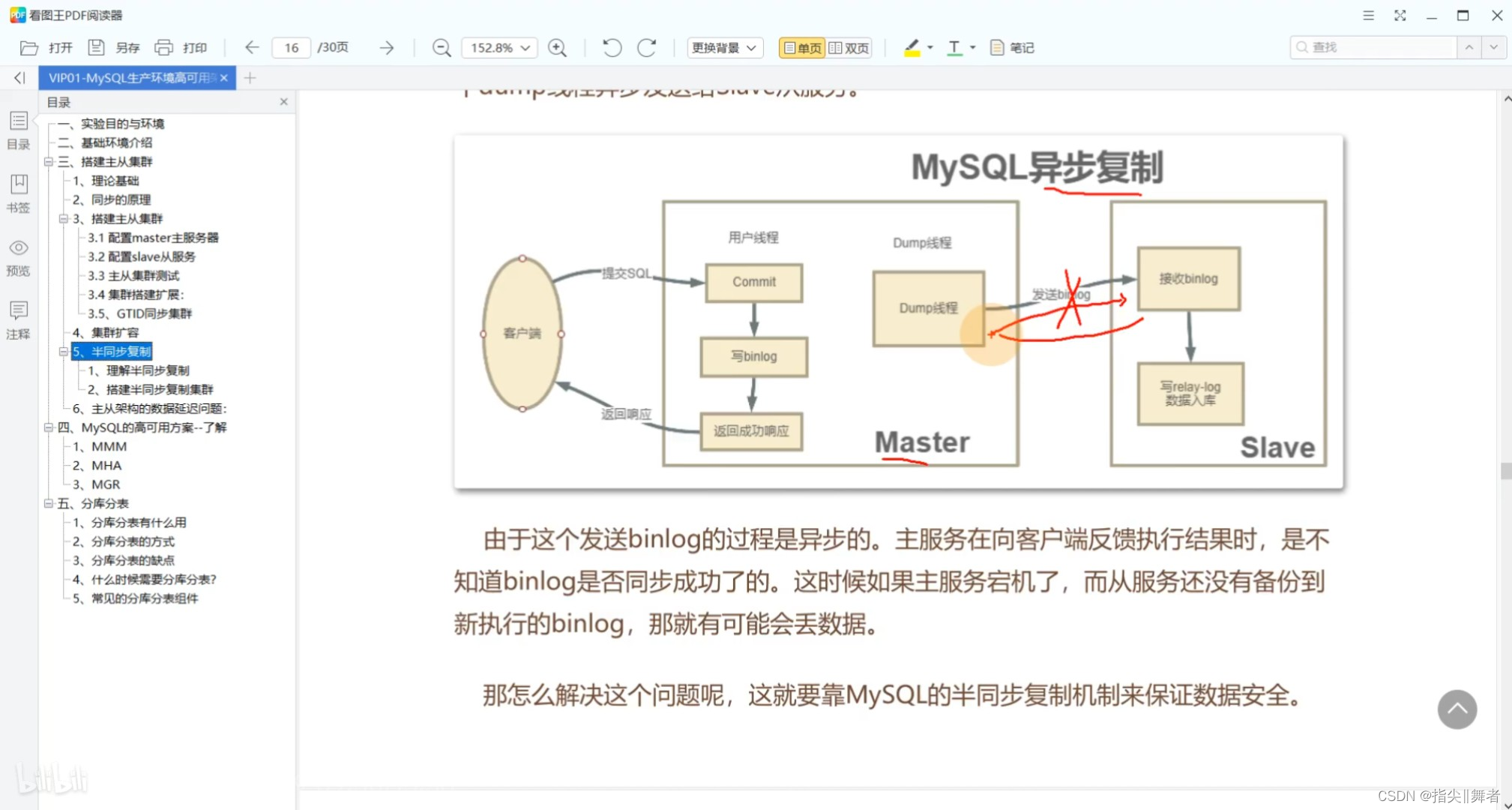
由于這個發送binlog的過程是異步的。主服務在向客戶端反饋執行結果時,是不知道binlog是否同步成功了的。這時候如果主服務宕機了,而從服務還沒有備份到新執行的binlog,那就有可能會丟數據。
那怎么解決這個問題呢,這就要靠MySQL的半同步復制機制來保證數據安全
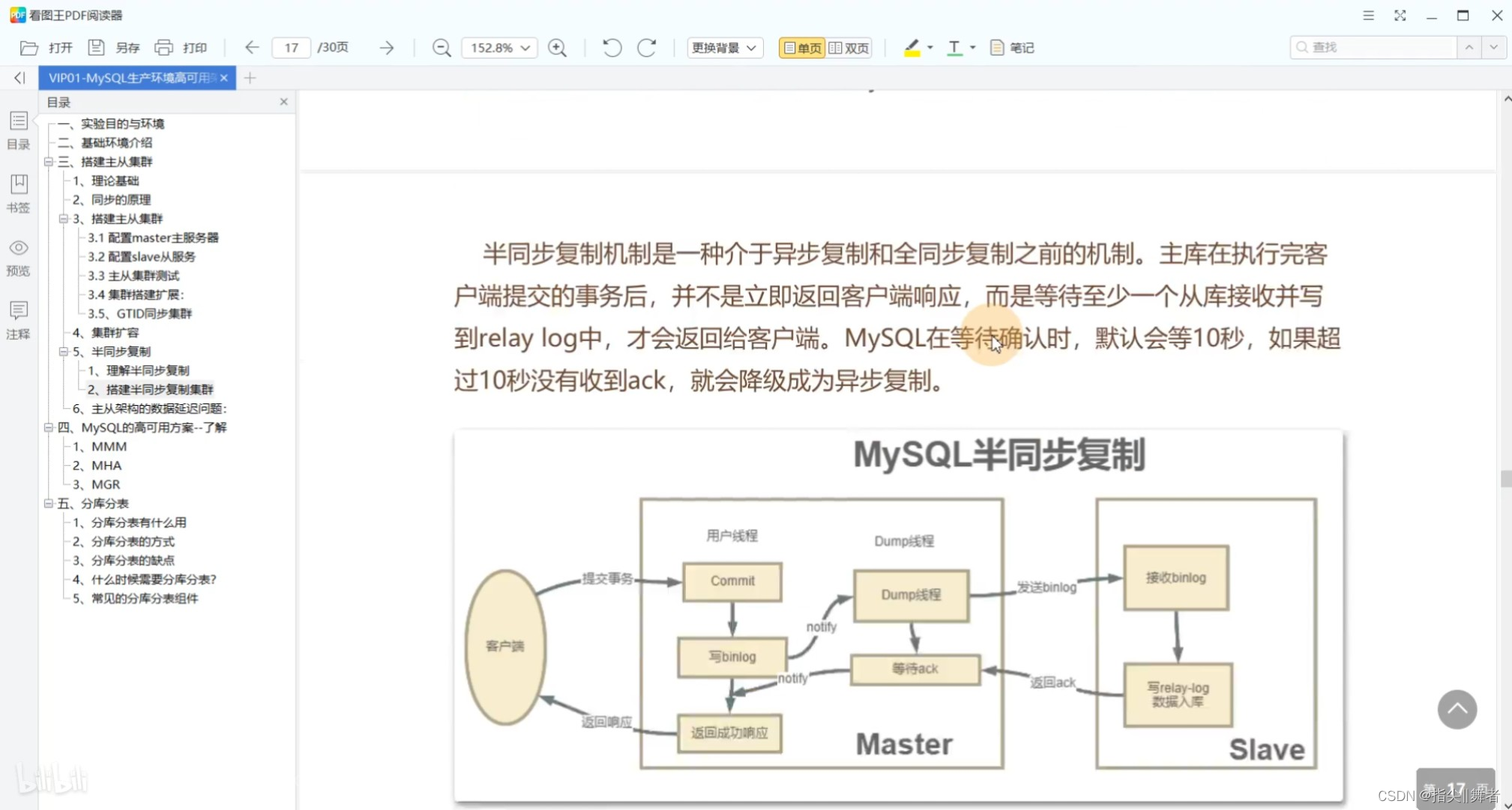
半同步復制機制是一種介于異步復制和全同步復制之前的機制。主庫在執行完客戶端提交的事務后,并不是立即返回客戶端響應,而是等待至少一個從庫接收并寫到relay log中,才會返回給客戶端。MySQL在等待確認時,默認會等10秒,如果超過10秒沒有收到ack,就會降級成為異步復制。
這種半同步復制相比異步復制,能夠有效的提高數據的安全性。但是這種安全性也不是絕對的,他只保證事務提交后的binlog至少傳輸到了一個從庫,并且并不保證從庫應用這個事務的binlog是成功的。另一方面,半同步復制機制也會造成一定程度的延遲,這個延遲時間最少是一個TCP/IP請求往返的時間。整個服務的性能是
mysql高可用方案?
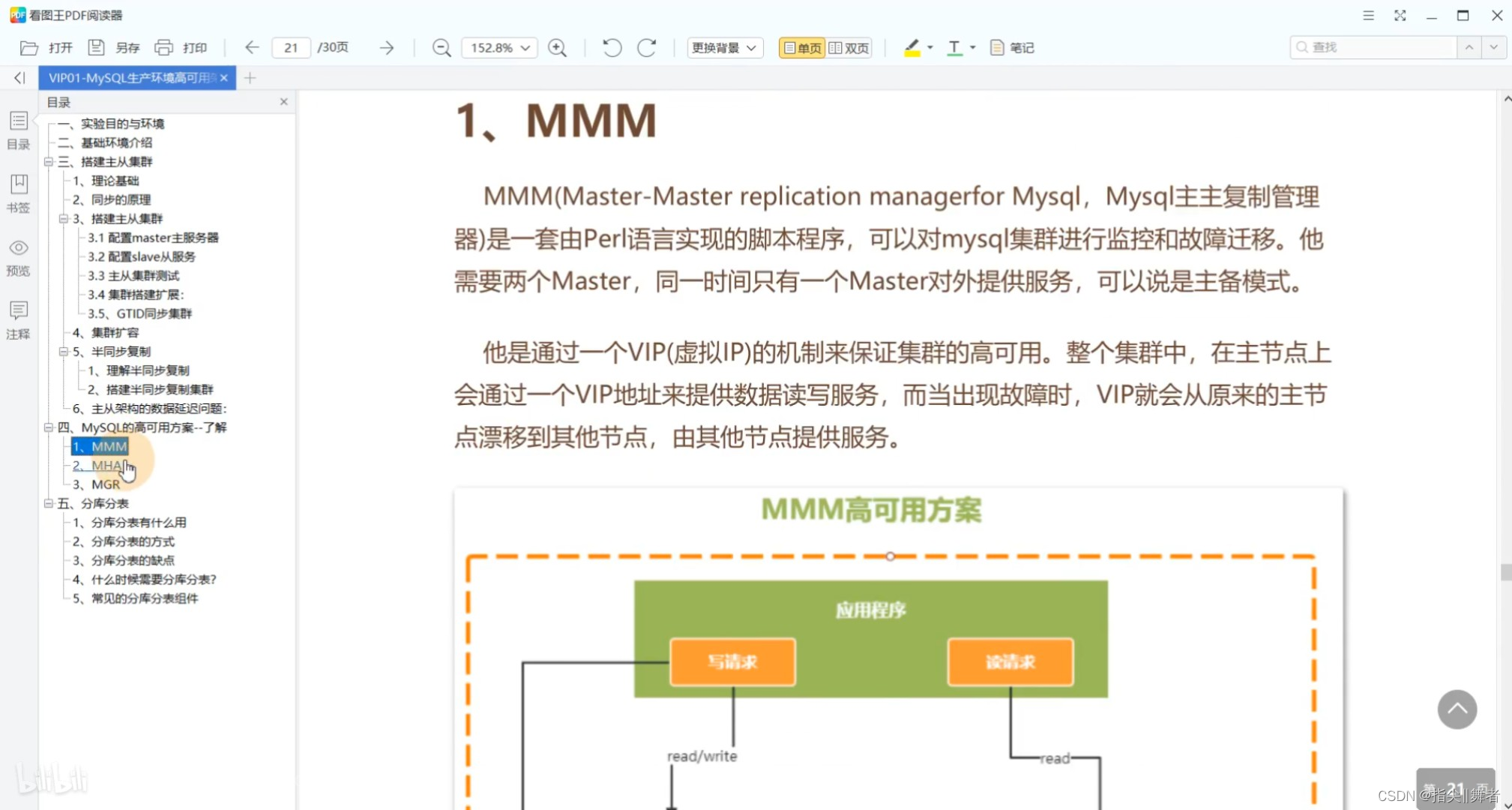
1、MMM
MMM(Master-Master replication managerfor Mysql,Mysql主主復制管理器)是一套由Perl語言實現的腳本程序,可以對mysql集群進行監控和故障遷移。他需要兩個Master,同一時間只有一個Master對外提供服務,可以說是主備模式。
他是通過一個VIP(虛擬IP)的機制來保證集群的高可用。整個集群中,在主節點上會通過一個VIP地址來提供數據讀寫服務,而當出現故障時,VIP就會從原來的主節點漂移到其他節點,由其他節點提供服務。
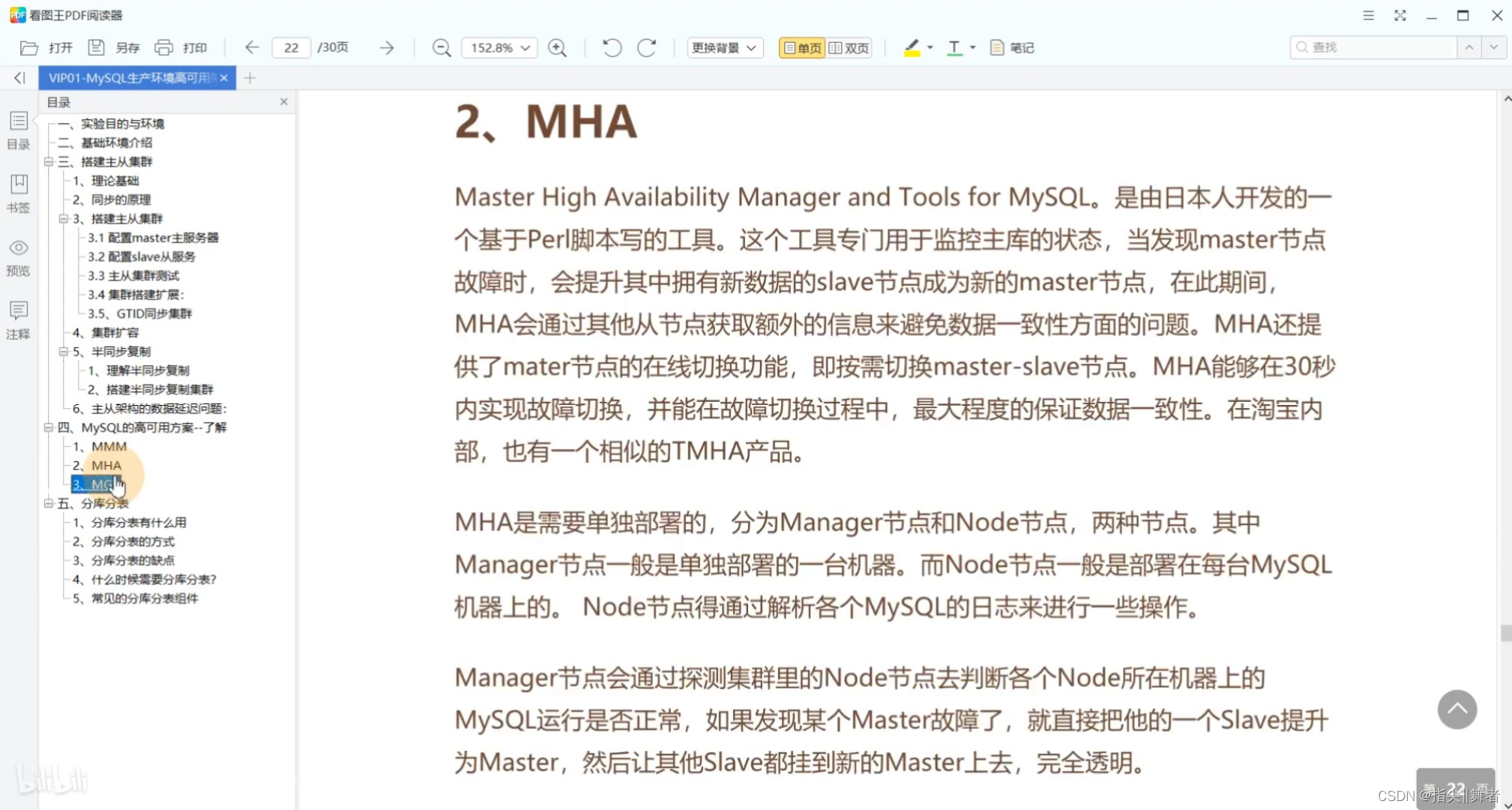
2、MHA
Master High Availability Manager and Tools for MySQL。是由日本人開發的一個基于Perl腳本寫的工具。這個工具專門用于監控主庫的狀態,當發現master節點故障時,會提升其中擁有新數據的slave節點成為新的master節點,在此期間,MHA會通過其他從節點獲取額外的信息來避免數據一致性方面的問題。MHA還提供了mater節點的在線切換功能,即按需切換master-slave節點。MHA能夠在30秒內實現故障切換,并能在故障切換過程中,最大程度的保證數據一致性。在淘寶內部,也有一個相似的TMHA產品。
MHA是需要單獨部署的,分為Manager節點和Node節點,兩種節點。其中Manager節點一般是單獨部署的一臺機器。而Node節點一般是部署在每臺MySQL機器上的。Node節點得通過解析各個MySQL的日志來進行一些操作。
Manager節點會通過探測集群里的Node節點去判斷各個Node所在機器上的MySQL運行是否正常,如果發現某個Master故障了,就直接把他的一個Slave提升為Master,然后讓其他Slave都掛到新的Master上去,完全透明。
3、MGR
MGR:MySQL Group Replication。是MySQL官方在5.7.17版本正式推出的一種
組復制機制。主要是解決傳統異步復制和半同步復制的數據一致性問題。
由若干個節點共同組成一個復制組,一個事務提交后,必須經過超過半數節點的決議并通過后,才可以提交。引入組復制,主要是為了解決傳統異步復制和半同步復制可能產生數據不一致的問題。MGR依靠分布式一致性協議(Paxos協議的一個變體),實現了分布式下數據的最終一致性,提供了真正的數據高可用方案(方案落地后是否可靠還有待商榷)。
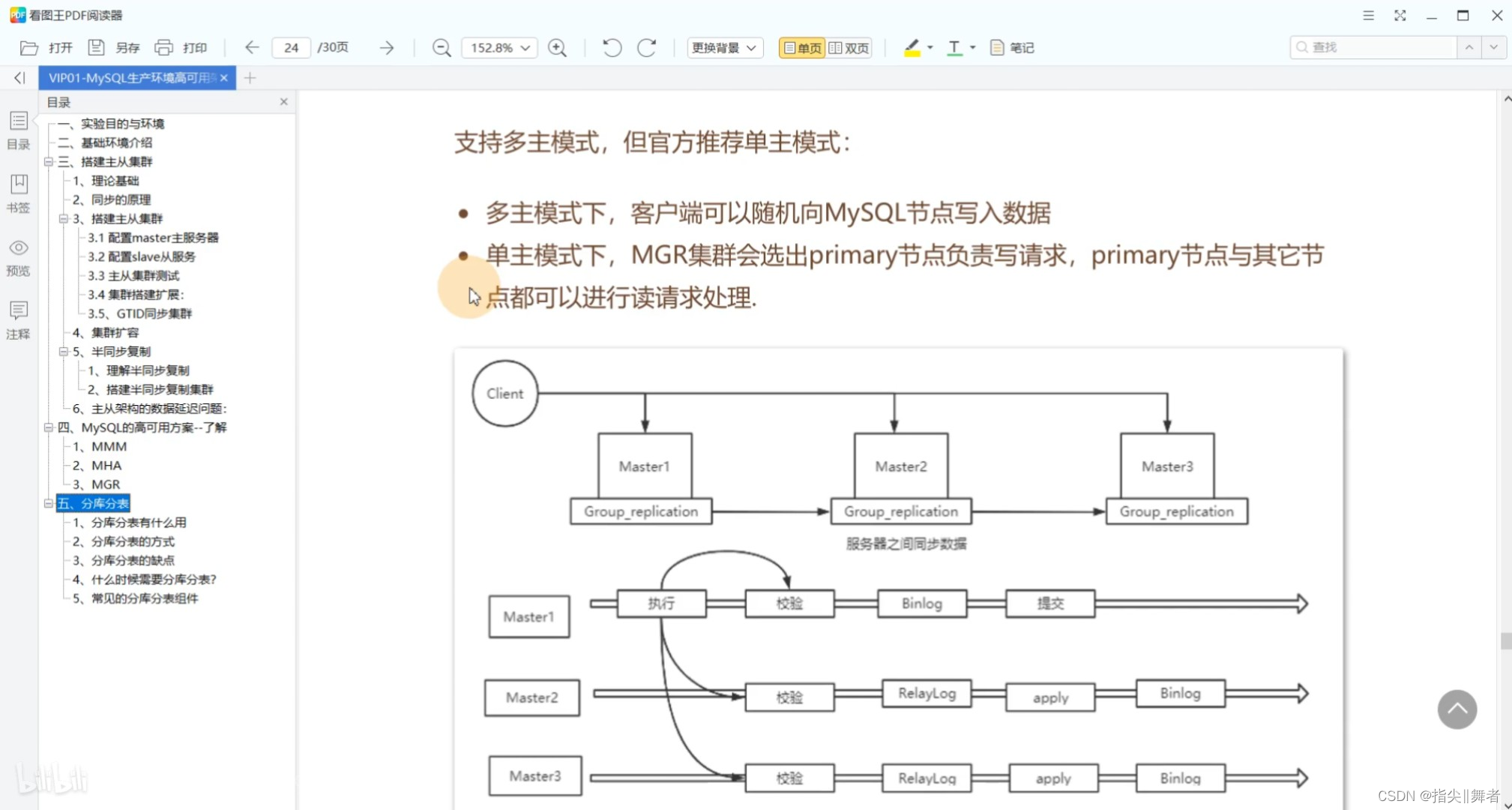
支持多主模式,但官方推薦單主模式:
。多主模式下,客戶端可以隨機向MySQL節點寫入數據
單主模式下,MGR集群會選出primary節點負責寫請求,primary節點與其它節
點都可以進行讀請求處理.
GTID同步集群
上面我們搭建的集群方式,是基于Binlog日志記錄點的方式來搭建的,這也是最
為傳統的MySQL集群搭建方式。而在這個實驗中,可以看到有一個
Executed_Grid_Set列,暫時還沒有用上。實際上,這就是另外一種搭建主從同步的
方式,即GTID搭建方式。這種模式是從MySQL5.6版本引入的。
GTID的本質也是基于Binlog來實現主從同步,只是他會基于一個全局的事務ID來標識同步進度。GTID即全局事務ID,全局唯一并且趨勢遞增,他可以保證為每一個在主節點上提交的事務在復制集群中可以生成一個唯一的ID。
在基于GTID的復制中,首先從服務器會告訴主服務器已經在從服務器執行完了哪些事務的GTID值,然后主庫會有把所有沒有在從庫上執行的事務,發送到從庫上進行執行,并且使用GTID的復制可以保證同一個事務只在指定的從庫上執行一次,這樣可以避免由于偏移量的問題造成數據不一致。
他的搭建方式跟我們上面的主從架構整體搭建方式差不多。只是需要在my.cnf中
修改一些配置。
在主節點上:
mysql聚簇和非聚簇索引的區別
都是B+樹的數據結構
,聚簇索引:將數據存儲與索引放到了一塊、并且是按照一定的順序組織的,找到索引也就找到了數據,數據的I物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那么對應的數據一定也是相鄰地存放在磁盤上的非聚簇索引:葉子節點不存儲數據、存儲的是數據行地址,也就是說根據索引查找到數據行的位置再取磁盤查找數據,這個就有點類似一本樹的目錄,比如我們要找第三章第一節,那我們先在這個目錄里面找,找到對應的頁碼后再去對應的頁碼看文章。
優勢:
1、查詢通過聚簇索引可以直接獲取數據,相比非聚簇索引需要第二次查詢(非覆蓋索引的情況下)效率要高
2、聚簇索引對于范圍查詢的效率很高,因為其數據是按照大小排列的
3、聚簇索引適合用在排序的場合,非聚簇索引不適合
劣勢:
1、維護索引很昂貴,特別是插入新行或者主鍵被更新導至要分頁(page sp1it)的時候。建議在大量插入新行后,選在負載較低的時間段,通過OPTIMIZE TABLE優化表,因為必須被移動的行數據可能造成碎片。使用獨享表空間可以弱化碎片
2、表因為使用UUId(隨機ID)作為主鍵,使數據存儲稀疏,這就會出現聚族索引有可能有比全表掃面更慢,所以建
議使用int的auto_increment作為主鍵
3、如果主鍵比較大的話,那輔助索引將會變的更大,因為輔助索引的葉子存儲的是主鍵值;過長的主鍵值,會導致非
葉子節點占用占用更多的物理空間
InnoDB中一定有主鍵,主鍵一定是聚簇索引,不手動設置、則會使用unique索引,沒有unique索引,則會使用
數據庫內部的一個行的隱藏id來當作主鍵索引。在聚簇索引之上創建的索引稱之為輔助索引,輔助索引訪問數據總是需要二次查找,非聚簇索引都是輔助索引,像復合索引、前綴索引、唯一索引,輔助索引葉子節點存儲的不再是行的物理位置,而是主鍵值
MyISM使用的是非聚簇索引,沒有聚簇索引,非聚簇索引的兩棵B+樹看上去沒什么不同,節點的結構完全一致只是存儲的內容不同而已,主鍵索引B+樹的節點存儲了主鍵,輔助鍵索引B+樹存儲了輔助鍵。表數據存儲在獨立的地方,這兩顆B+樹的葉子節點都使用一個地址指向真正的表數據,對于表數據來說,這兩個鍵沒有任何差別。由于索引樹是獨立的,通過輔助鍵檢索無需訪問主鍵的索引樹。
如果涉及到大數據量的排序、全表掃描、count之類的操作的話,還是MyISAM占優勢些,因為索引所占空間小,
這些操作是需要在內存中完成的。
Mysql數據庫中,什么情況下設置了索引但無法使用?
1.沒有符合最左前綴原則
2.字段進行了隱私數據類型轉化
3.走索引沒有全表掃描效率高
Innodb是如何實現事務的
Innodb通過Buffer Pool,LogBuffer,Redo Log,Undo Log來實現事務,以一個update語句為例:1.Innodb在收到一個update語句后,會先根據條件找到數據所在的頁,并將該頁緩存在Buffer Pool中2.執行update語句,修改Buffer Pool中的數據,也就是內存中的數據
3.針對update語句生成一個RedoLog對象,并存入LogBuffer中
4.針對update語句生成undolog日志,用于事務回滾
5.如果事務提交,那么則把RedoLog對象進行持久化,后續還有其他機制將Buffer Pool中所修改的數據頁持久化到磁盤中
6.如果事務回滾,則利用undolog日志進行回滾
mysql索引的數據結構,各自優劣
索引的數據結構和具體存儲引擎的實現有關,在MySQL中使用較多的索引有Hash索引,B+樹索引等,InnoDB存儲引擎的默認索引實現為:B+樹索引。對于哈希索引來說,底層的數據結構就是哈希表,因此在絕大多數需求為單條記錄查詢的時候,可以選擇哈希索引,查詢性能最快;其余大部分場景,建議選擇BTree索引。
B+樹:
B+樹是一個平衡的多叉樹,從根節點到每個葉子節點的高度差值不超過1,而且同層級的節點間有指針相互鏈接。在B+樹上的常規檢索,從根節點到葉子節點的搜索效率基本相當,不會出現大幅波動,而且基于索引的順序掃描時,也可以利用雙向指針快速左右移動,效率非常高。因此,B+樹索引被廣泛應用于數據庫、文件系統等場景。
哈希索引:
哈希索引就是采用一定的哈希算法,把鍵值換算成新的哈希值,檢索時不需要類似B+樹那樣從根節點到葉子節點
逐級查找,只需一次哈希算法即可立刻定位到相應的位置,速度非常快
如果是等值查詢,那么哈希索引明顯有絕對優勢,因為只需要經過一次算法即可找到相應的鍵值;前提是鍵值都是
唯一的。如果鍵值不是唯一的,就需要先找到該鍵所在位置,然后再根據鏈表往后掃描,直到找到相應的數據;
如果是范圍查詢檢索,這時候哈希索引就毫無用武之地了,因為原先是有序的鍵值,經過哈希算法后,有可能變成不連續的了,就沒辦法再利用索引完成范圍查詢檢索;
哈希素引也沒辦法利用索引完成排序,以及likexxx%這樣的部分模糊查詢(這種部分模糊查詢,其實本質上也是
范圍查詢);
哈希索引也不支持多列聯合索引的最左匹配規則;
B+樹索引的關鍵字檢索效率比較平均,不像B樹那樣波動幅度大,在有大量重復鍵值情況下,哈希索引的效率也是
極低的,因為存在哈希碰撞問題。
MySQL有哪幾種數據存儲引擎?有什么區別?
MySQL中通過show ENGINES指令可以看到所有支持的數據庫存儲引擎。 最為常用的就是MyISAM和nnoDB兩種。
MylSAM和LnnDB的區別:
1、存儲文件。 MylSAM每個表有兩個文件。 MYD和MYISAM文件。 MYD是數據文件。 MYI是索引文件。而InnDB每個表
只有一個文件,idb。
2、LnnoDB支持事務,支持行級鎖,支持外鍵。
3、InnoDB支持XA事務
4、LnnoDB支持savePoints
mysql主從同步原理
mysql主從同步的過程:
Mysql的主從復制中主要有三個線程:master(binlog dump thread)
thread),Master—條線程和Slave中的兩條線程。
·主節點binlog,主從復制的基礎是主庫記錄數據庫的所有變更記錄到binlog。binlog是數據庫服務器啟動的
那一刻起,保存所有修改數據庫結構或內容的一個文件。
主節點log dump線程,當binlog有變動時,log dump 線程讀取其內容并發送給從節點。
從節點1/O線程接收binlog內容,并將其寫入到relaylog文件中。
·從節點的SQL線程讀取 relay log 文件內容對數據更新進行重放,最終保證主從數據庫的一致性。
注:主從節點使用binglog文件+position偏移量來定位主從同步的位置,從節點會保存其已接收到的偏移量
如果從節點發生宕機重啟,則會自動從 position的位置發起同步。
由于mysql默認的復制方式是異步的,主庫把日志發送給從庫后不關心從庫是否已經處理,這樣會產生一個問題就
是假設主庫掛了,從庫處理失敗了,這時候從庫升為主庫后,日志就丟失了。由此產生兩個概念。
全同步復制
主庫寫入binlog后強制同步日志到從庫,所有的從庫都執行完成后才返回給客戶端,但是很顯然這個方式的話性能
會受到嚴重影響。
半同步復制
和全同步不同的是,半同步復制的邏輯是這樣,從庫寫入日志成功后返回ACK確認給主庫,主庫收到至少一個從庫
的確認就認為寫操作完成。
海量數據下,如何快速查找一條記錄?
1、使用布隆過濾器,快速過濾不存在的記錄。
使用Redis的bitmap結構來實現布隆過濾器。
2、在Redis中建立數據緩存。-將我們對Redis使用場景的理解盡量表達出來。
以普通字符串的形式來存儲,(serld->user.json)。以一個hash來存儲一條記錄(userld key->username field->,userAge->)。以一個整的hash來存儲所有的數據,Userlnfo->field就用userld,value就用user.json。一個hash最多能支持2^32-1(40多個億)個鍵值對。
緩存擊穿:對不存在的數據也建立key。這些key都是經過布隆過濾器過濾的,所以一般不會太多
緩存過期:將熱點數據設置成永不過期,定期重建緩存。 使用分布式鎖重建緩存。
3、查詢優化。
按槽位分配數據,
自己實現槽位計算,找到記錄應該分配在哪臺機器上,然后直接去目標機器上找
事務的基本特性和隔離級別有哪些?
事務: 表示多個數據操作組成一個完整的事務單元,這個事務內的所有數據操作要么同時成功,要么同時失敗。
事務的特性:ACID
1、原子性:事務是不可分割的,要么完全成功,要么完全失敗。
2、一致性:事務無論是完成還是失敗,都必須保持事務內操作的一致性。當失敗時,都要對前面的操作進行回滾,不管中途
是否成功。
3、隔離性:當多個事務操作一個數據的時候,為防止數據損壞,需要將每個事務進行隔離,互相不干擾。
4、持久性:事務開始就不會終止。他的結果不受其他外在因素的影響。
事務的隔離級別:SHOW VARIABLES like’transaction%’
設置隔離級別:set transaction level xxx設置下次事務的隔離級別。
set session transaction level xxx設置當前會話的事務隔離級別
set global transaction level xxx設置全局
set global transaction level xxx設置全局事務隔離級別
MySQL當中有五種隔離級別
NONE:不使用事務。
READ UNCOMMITED:I允許臟讀
READ COMMITED:防止臟讀,最常用的隔離級別
REPEATABLE READ::防止臟讀和不可重復讀。MYSQL默認
SERIALIZABLE:事務串行,可以防止臟讀、幻讀,不可重復度。
五種隔離級別,級別越高,事務的安全性是更高的,但是,事務的并性能也就會越低。
什么是MVCC
多版本并發控制:讀取數據時通過一種類擬快照的方式將數據保存下來,這樣讀鎖就和寫鎖不沖突了,不同的事務
session會看到自己特定版本的數據,版本鏈
MVCC只在 READ COMMITTED 和 REPEATABLE READ兩個隔離級別下工作。其他兩個隔離級別夠和MVCC不兼容,因為READ UNCOMMITTED總是讀取最新的數據行,而不是符合當前事務版本的數據行。而SERIALIZABLE則會對所有讀取的行都加鎖。
聚簇索引記錄中有兩個必要的隱藏列:
trx_id:用來存儲每次對某條聚簇索引記錄進行修改的時候的事務id。
roll_pointer:每次對哪條聚簇索引記錄有修改的時候,都會把老版本寫入undo日志中。這個roll_pointer就是存了一個指針,它指向這條聚簇索引記錄的上一個版本的位置,通過它來獲得上一個版本的記錄信息。(注意插入操作的undo日志沒有這個屬性,因為它沒有老版本)
已提交讀和可重復讀的區別就在于它們生成ReadView的策略不同。
開始事務時創建readview,readView維護當前活動的事務id,即未提交的事務id,排序生成一個數組
訪問數據,獲取數據中的事務id(獲取的是事務id最大的記錄),對比readview:
如果在readvew的左邊(比readview都小),可以訪問(在左邊意味著該事務已經提交)
如果在readview的右邊(比readview都大)或者就在readview中,不可以訪問,獲取roll_pointer,取上一版本
重新對比(在右邊意味著,該事務在readview生成之后出現,在readview中意味著該事務還未提交)
已提交讀隔離級別下的事務在每次查詢的開始都會生成一個獨立的ReadView,而可重復讀隔離級別則在第一次讀的
時候生成一個ReadView,之后的讀都復用之前的ReadView。
這就是MysqI的MVCC,通過版本鏈,實現多版本,可并發讀-寫,寫-讀。通過ReadView生成策略的不同實現不同的
隔離級別。
什么是臟讀、幻讀、不可重復讀?要怎么處理?
這些問題都是MySQL進行事務并發控制時經常遇到的問題。
臟讀:在事務進行過程中,讀到了其他事務未提交的數據。
不可重復讀:在一個事務過程中,多次查詢的結果不一致。
幻讀:在一個事務過程中,用同樣的操作查詢數據,得到的記錄數不相同。
處理的方式有很多種:加鎖、事務隔離、MVCC
加鎖:
1、臟讀:在修改時加排他鎖,直到事務提交才釋放。讀取時加共享鎖,讀完釋放鎖。
2、不可重復讀:讀數據時加共享鎖,寫數據時加排他鎖。
3、幻讀:加范圍鎖。
事務的基本特性和隔離級別
事務基本特性ACID分別是:
原子性指的是一個事務中的操作要么全部成功,要么全部失敗。
一致性指的是數據庫總是從一個一致性的狀態轉換到另外一個一致性的狀態。
BCf轉賬給B100塊錢,假設A只有90塊,支付之前我們數據庫里的數據都是符合約束的,但是如果事務執行成功了,,我們的數據庫數據就破壞約束了,因此事務不能成功,這里我們說事務提供了一致性的保證
隔離性指的是一個事務的修改在最終提交前,對其他事務是不可見的。
持久性指的是一旦事務提交,所做的修改就會永久保存到數據庫中。
隔離性有4個隔離級別,分別是:
read uncommit 讀未提交,可能會讀到其他事務未提交的數據,也叫做臟讀。
用戶本來應該讀取到id=1的用戶age應該是10,結果讀取到了其他事務還沒有提交的事務,結果讀取結果
age=20,這就是臟讀。
read commit 讀已提交,兩次讀取結果不一致,叫做不可重復讀.
不可重復讀解決了臟讀的問題,他只會讀取已經提交的事務。
用戶開啟事務讀取id=1用戶,查詢到age=10,再次讀取發現結果=20,在同一個事務里同一個查詢讀取到不同的結果叫做不可重復讀。
repeatable read 可重復復讀,這是mysgl的默認級別,
,就是每次讀取結果都一樣,但是有可能產生幻讀。
serializable串行,一般是不會使用的,他會給每一行讀取的數據加鎖,會導致大量超時和鎖競爭的問題。
臟讀(Drity Read):某個事務已更新一份數據,另一個事務在此時讀取了同一份數據,由于某些原因,前一個
Mysql慢查詢該如何優化?
1.檢查是否走了索引,如果沒有則優化SQL利用索引
2.檢查所利用的索引,是否是最優索引
3.檢查所查字段是否都是必須的,是否查詢了過多字段,查出了多余數據
4.檢查表中數據是否過多,是否應該進行分庫分表了
5.檢查數據庫實例所在機器的性能配置,是否太低,是否可以適當增加資源



)



加密分析)



)







)