前言
上一次,我們從優化子查詢的角度,講解了一些簡單的數據庫性能優化方面的知識。通過優化子查詢的順序,包括合理使用IN和EXISTS,可以起到部分查詢的效率提升。
但對于其他大多數場景,如單表記錄很大,或多表級聯查詢包含條件或排序時,子查詢的優化往往起不到決定性的效果。所以從今天開始,我們要逐漸接觸這一部分的主角:索引。這部分內容我會分為上中下三篇進行詳細的講解,上篇會著重于索引的概念,以及基礎的使用方式;中篇會講解索引背后的實現原理,便于理解索引如何發揮作用;下篇會結合一些復雜的SQL場景,來描述索引在實際工作中如何使用。
概述
數據庫中的索引,就像一本書的目錄,它可以幫我們快速定位和查找,從而加快數據查詢的效率。
如果我們不使用索引,那么記錄就必須從表中第一行開始進行逐行掃描,直到找出符合條件的記錄為止,這樣的查詢效率,必然是很低的。那么,索引是不是建立得越多就越好呢?
答案是否定的,因為索引也是一種存儲在數據庫硬盤中的數據結構,會占用一定的空間。而且對于數據的新增、修改和刪除時,數據庫也需要對其相關的索引進行更新,進而降低了整體效率。
索引的類型
了解了索引的基本概念之后,我們還需要知道不同索引的用途。索引從功能邏輯上可以分為四類:普通索引、唯一索引、主鍵索引和全文索引。而在物理實現上可以分為兩類:聚集索引和非聚集索引。下面我們來逐一講解:
1、普通索引:最基礎的索引,沒有任何約束,直接建立即可,用于提升查找的效率。
2、唯一索引:在普通索引的基礎上,加入了數據唯一性的約束,用于檢查數據是否唯一,在同一張數據表中,可以有多個唯一索引。
3、主鍵索引:在唯一索引的基礎上,加入了NOT NULL的特性,在我們給數據庫表設置主鍵時,會自動創建主鍵索引,而根據主鍵的特性,一個表中只能有一個主鍵索引。
4、全文索引:一種特殊的基于標記的索引,由數據庫引擎維護,用于快速查找某個字符出現的位置,較少使用。目前此種查找一般會使用搜索引擎實現,如ES(ElasticSearch)。
5、聚集索引:確定了數據存儲的順序,在物理上是連續存儲的,因此聚集索引在每個表中只能有一個。在默認情況下,數據庫會對主鍵約束自動創建聚集索引,這就是數據表中的行記錄通常按照主鍵排列的原因。
6、非聚集索引:在數據庫中有單獨的空間進行存儲,索引項本身是按照順序存儲的,但是索引指向的內容卻是隨機存儲的。也就是說非聚集索引在工作時,系統會進行兩次查找,第一次會找到索引本身,第二次則根據索引對應的位置找出數據行。非聚集索引不會把索引指向的內容像聚集索引一樣直接放到索引后面,而是維護單獨的索引表,為數據的檢索提供方便。由于實現原理的不同,非聚集索引在每個表中可以有多個。
索引的應用
現在我們來看一下索引使用的實際效果,目前我有一張表T_ORG_USER,其中大約有3000條數據。這時我們需要查詢一條記錄如下:
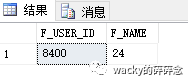
我們可以使用主鍵Id和用戶名分別查詢同一條記錄,然后查看查詢記錄的區別,首先我們使用主鍵Id進行查詢:
SET STATISTICS TIME ON
SELECT * FROM T_ORG_USER WHERE F_USER_ID = 8400查詢結果如下圖所示,執行時間為0毫秒:

此時,我們再使用用戶名進行查詢,用戶名字段沒有建立索引:
SET STATISTICS TIME ON
SELECT * FROM T_ORG_USER WHERE F_NAME = '24'查詢結果如下圖所示,執行時間為196毫秒:

從執行時間上,我們可以看出二者有明顯的效率差別,這時我們再對F_NAME字段建立索引:
CREATE INDEX IDX_USERNAME ON T_ORG_USER(F_NAME)再次查詢,結果如圖所示,執行時間縮短到了5毫秒:
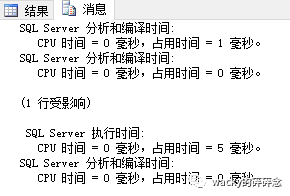
從上述三次的執行結果中,我們可以總結出以下兩點:
1、對WHERE條件后的字段進行索引,可以大幅度提高查詢的效率
2、采用聚集索引的查詢效率,比采用非聚集索引的查詢效率略高。在我們上述的例子中,第一次使用主鍵進行查詢,系統會使用聚集索引進行查找,而第三次我們使用非聚集索引進行查找,效率會降低。因此在需要多次查詢的場景下,我們的SQL語句應盡量使用主鍵索引進行查詢。
除了我們之前描述的幾種索引類型之外,索引還可以根據字段個數分為單一索引和聯合索引。
單一索引是指使用單個列創建的索引,如我們上述的IDX_USERNAME所示,而把多個列組合在一起創建的索引,叫做聯合索引。
創建聯合索引時,我們需要注意字段的順序問題,因為字段(a,b,c)和字段(b,a,c)創建出的聯合索引,在使用時查詢效率可能會不同。
導致這樣的原因是由于聯合索引存在最左匹配原則,也就是說如果我們創建了聯合索引(a,b,c)時,WHERE條件如果為WHERE a = 1 AND b = 2 AND c = 3,則會匹配上聯合索引,如果條件為WHERE b = 2,那么聯合索引會失效,查詢就會走全表掃描的方式去查找。還有一些范圍查找操作也會導致聯合索引失效,如果某一列使用了<,<=,>,>=,between等,那么此列后面的列就無法使用到索引。
總結
今天我們講述了索引的基本概念,索引的類型以及索引的基本使用方式。合理使用索引可以幫助我們提升查詢效率,但索引也存在一些缺點,如單獨占用空間,降低數據庫的寫操作性能等,所以我們在使用索引時需要權衡索引的利與弊。
在實際工作中,我們也要根據查詢的業務邏輯來決定如何建立索引,牢記最左匹配原則,適當對語句進行改寫以便于索引生效,也可以大大提升數據查詢的性能。
好了,今天我們要講的內容到這里就結束了,如果有什么疑問或者啟發,歡迎大家在評論區進行留言。下一期我們會從索引背后的原理:B樹和B+樹的算法實現進行講解,敬請期待!
您的點贊和在看是我創作的最大動力,感謝支持



公眾號:wacky的碎碎念
知乎:wacky

)



![[javaEE] JDBC快速入門](http://pic.xiahunao.cn/[javaEE] JDBC快速入門)
的創建與編輯)











 一些新功能 (監控/統計/配置/初始化))
