Raft算法屬于Multi-Paxos算法,它是在Multi-Paxos思想的基礎上,做了一些簡化和限制,比如增加了日志必須是連續的,只支持領導者、跟隨者和候選人三種狀態,在理解和算法實現上都相對容易許多
從本質上說,Raft算法是通過一切以領導者為準的方式,實現一系列值的共識和各節點日志的一致
1、領導者選舉
1)、成員身份
Raft算法支持領導者(Leader)、跟隨者(Follower)和候選人(Candidate)3種狀態:
- 跟隨者:接收和處理來自領導者的消息,當等待領導者心跳信息超時的時候,就主動站出來,推薦自己當候選人
- 候選人:候選人將向其他節點發送請求投票(RequestVote)RPC消息,通知其他節點來投票,如果贏得了大多數選票,就晉升當領導者
- 領導者:負責處理寫請求、管理日志復制和不斷地發送心跳信息,通知其他節點“我是領導者,我還活著,你們現在不要發起新的選舉,找個新領導者來替代我”
Raft算法是強領導者模型,集群中只能有一個領導者
2)、選舉領導者的過程
在初始狀態下,集群中所有的節點都是跟隨者狀態
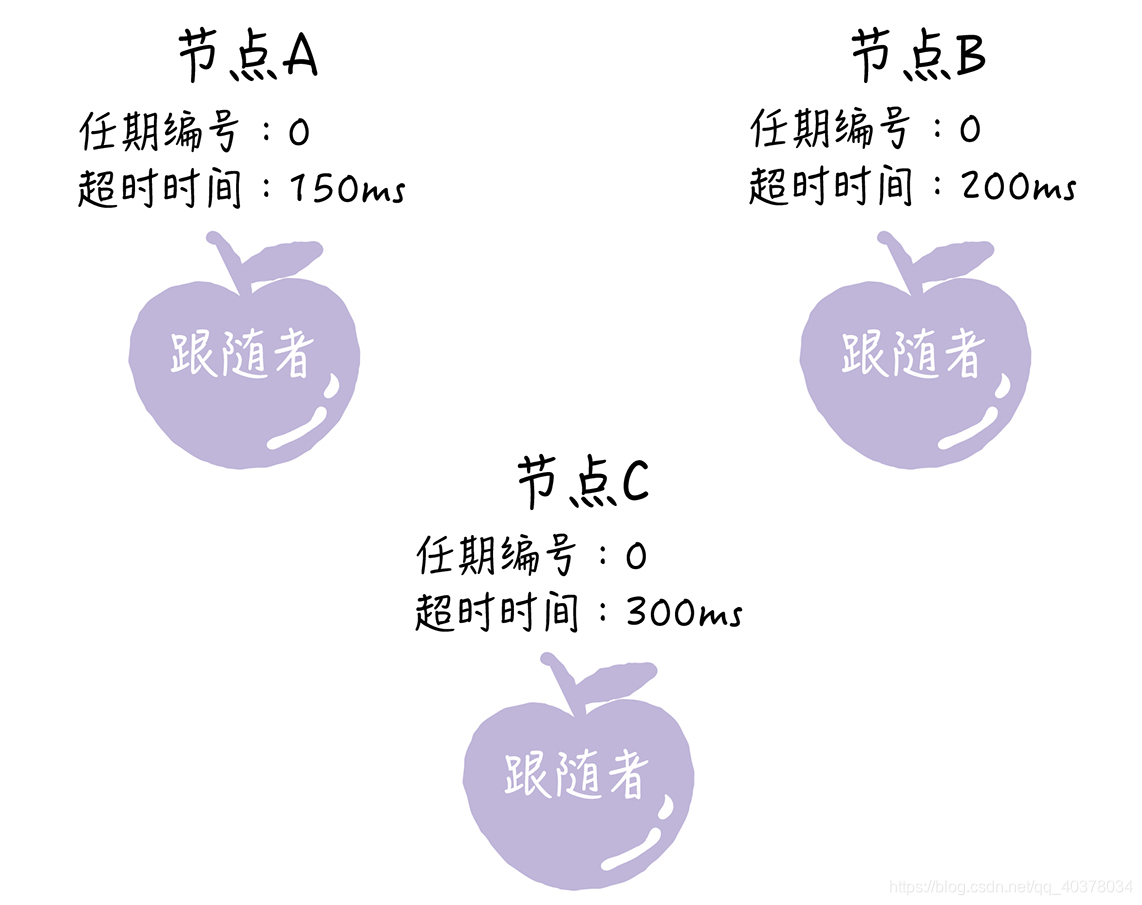
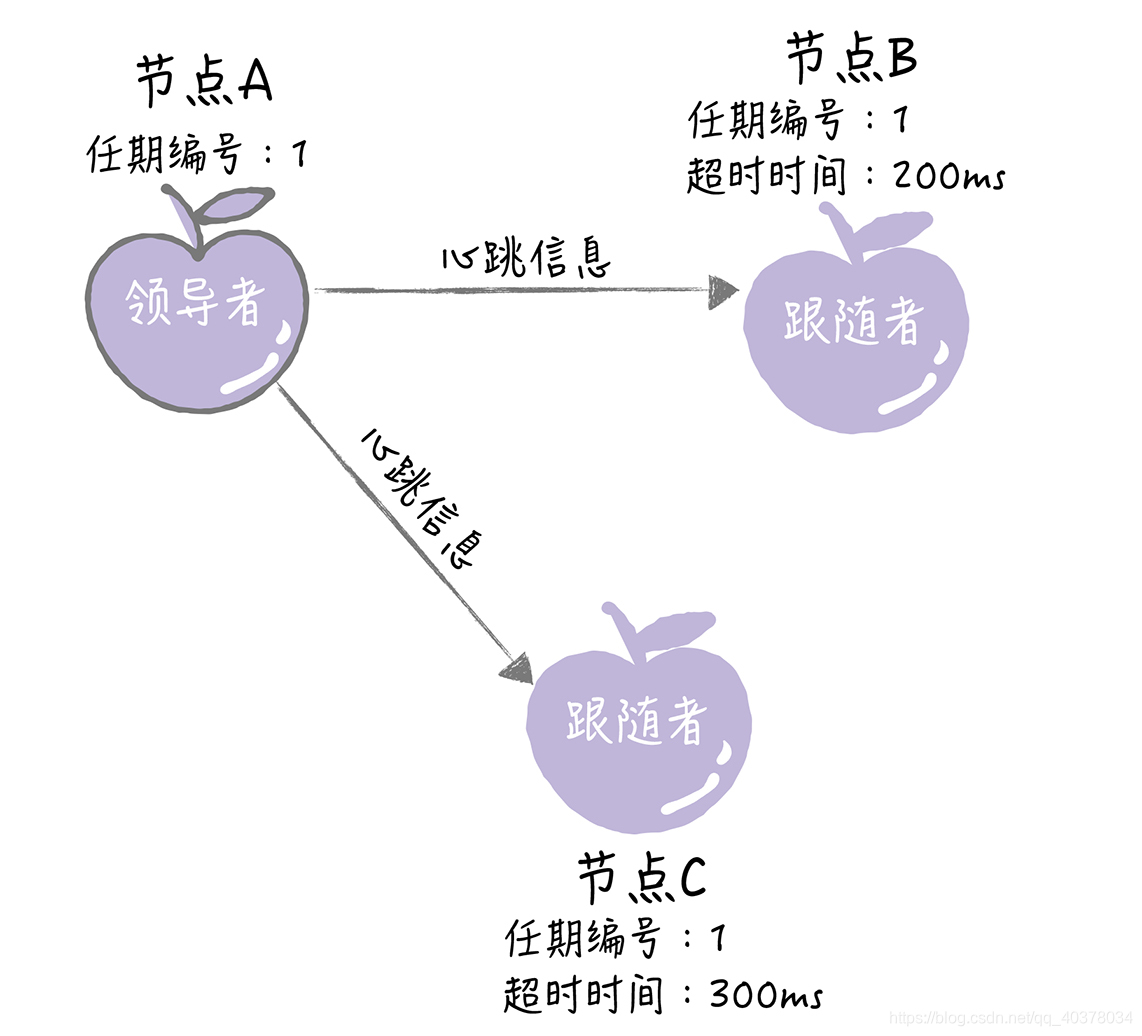
Raft算法實現了隨機超時時間的特性,每個節點等待領導者心跳信息的超時時間間隔是隨機的。上圖中,集群中沒有領導者,而節點A的等待超時時間最小,它會最先因為沒有等到領導者的心跳信息,發生超時
這時,節點A增加自己的任期編號,并推舉自己為候選人,先給自己投上一張選票,然后向其他節點發送請求投票RPC消息,請它們選舉自己為領導者
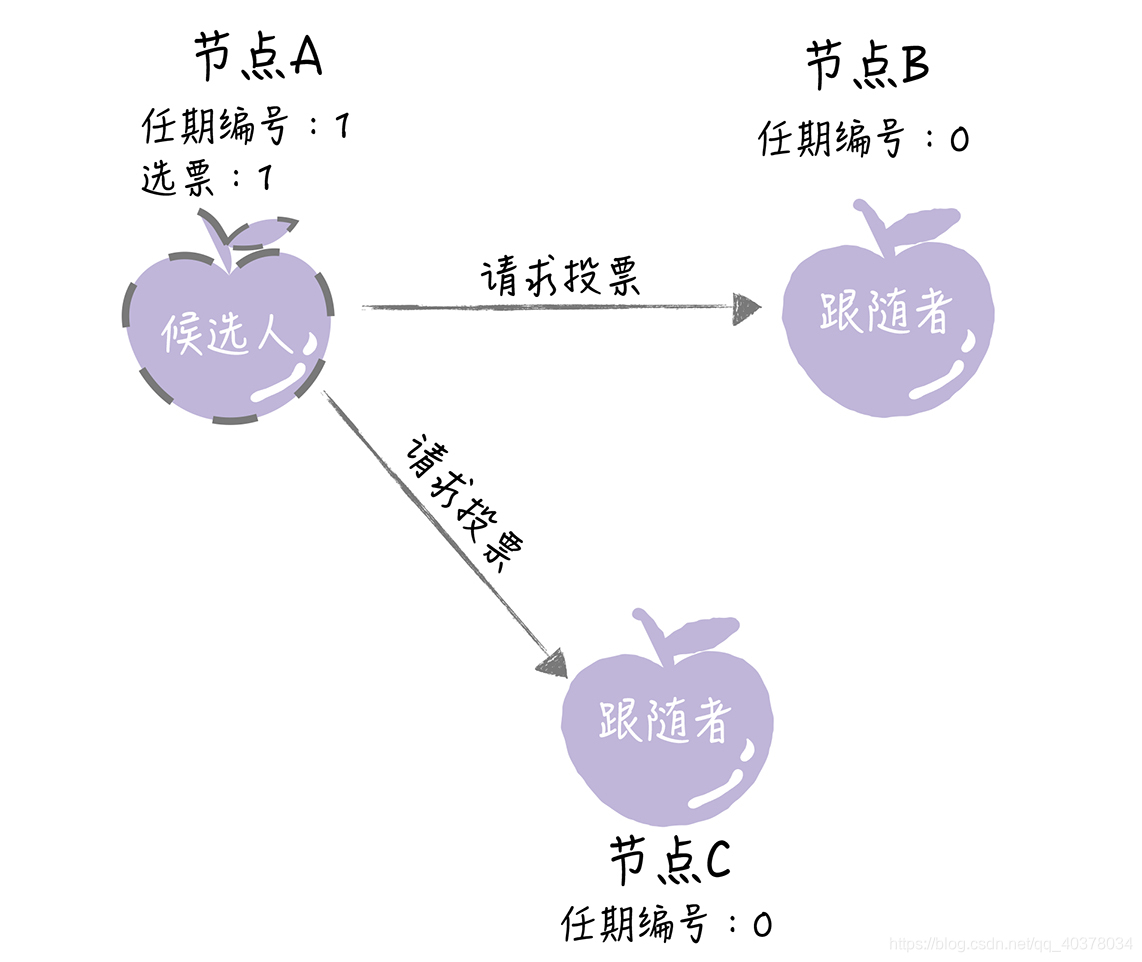
如果其他節點接收到候選人A的請求投票RPC消息,在編號為1的這屆任期內,也還沒有進行過投票,那么它將把選票投給節點A,并增加自己的任期編號
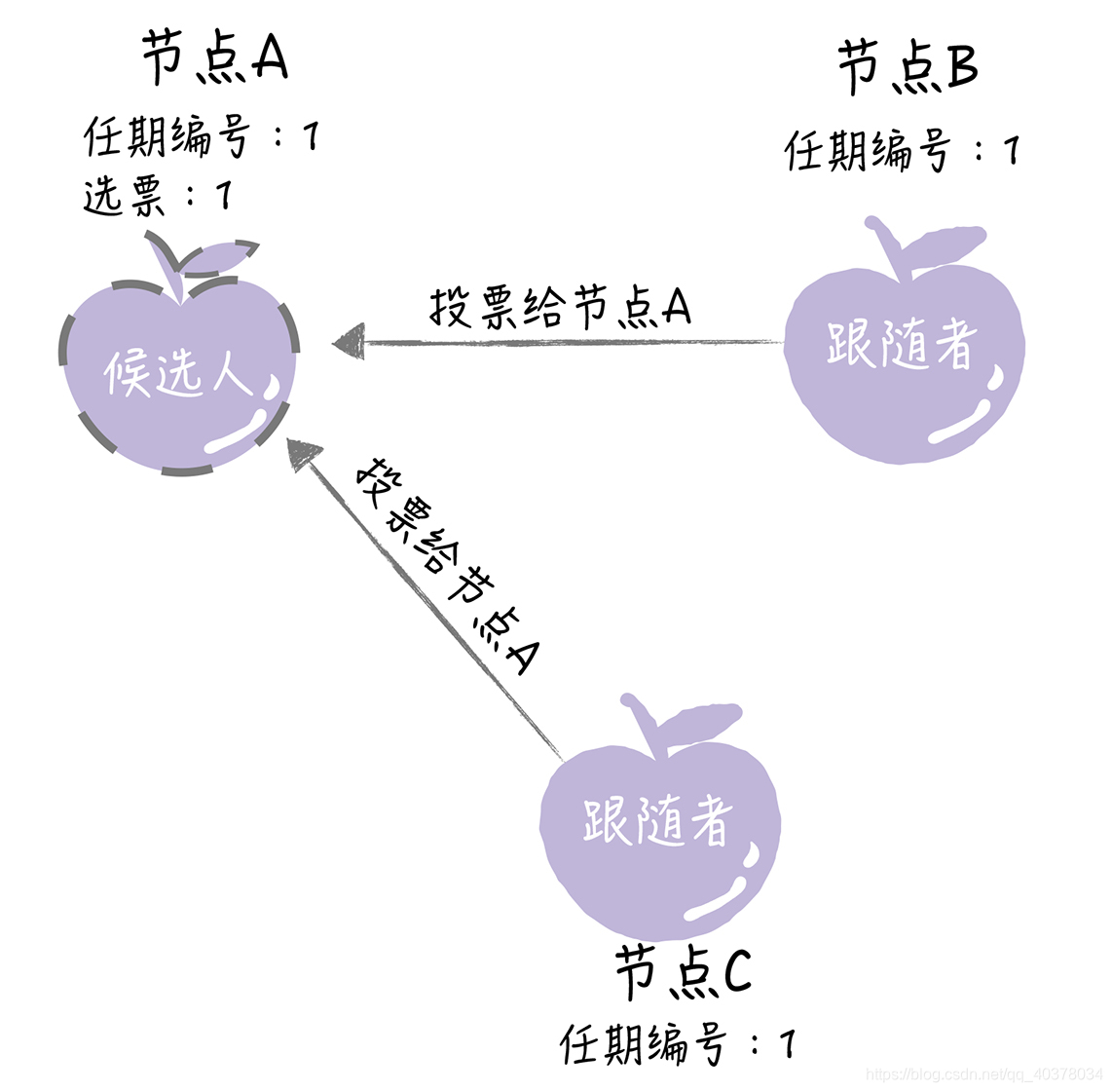
如果候選人在選舉超時時間內贏得了大多數的選票,那么它就會成為本屆任期內新的領導者
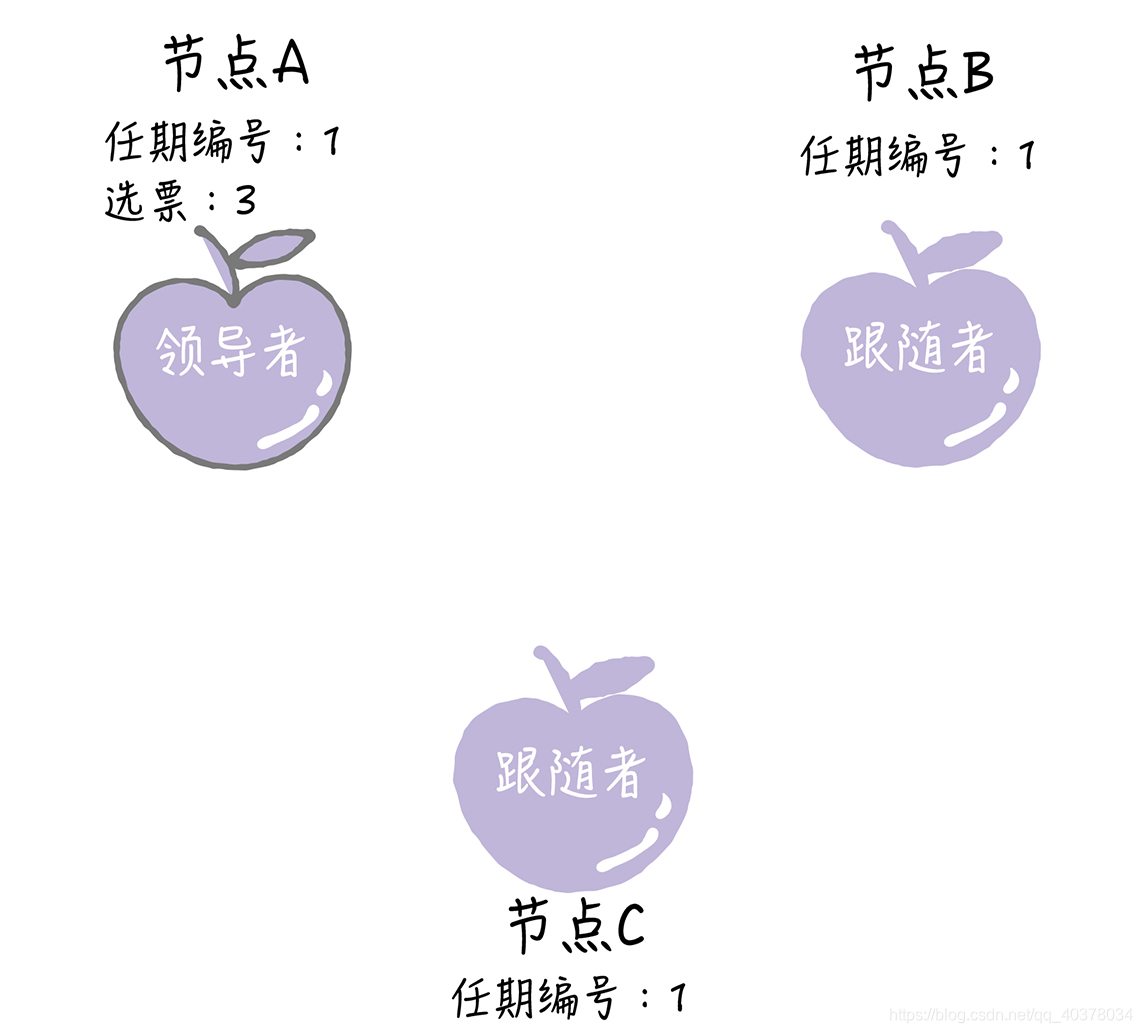
節點A當選領導者后,它將周期性地發送心跳消息,通知其他服務器我是領導者,阻止跟隨者發起新的選舉
3)、節點間如何通訊?
在Raft算法中,服務器節點間的溝通聯絡采用的是遠程過程調用(RPC),在領導者選舉中,需要用到這兩類的RPC:
- 請求投票(RequestVote)RPC:是由候選人在選舉期間發起,通知各節點進行投票
- 日志復制(AppendEntries)RPC:是由領導者發起,用來復制日志和提供心跳消息
4)、什么是任期?
Raft算法中每個任期由單調遞增的數字(任期編號)標識,任期編號是隨著選舉的舉行而變化的
- 跟隨者在等待領導者心跳信息超時后,推舉自己為候選人時,會增加自己的任期編號,比如節點A的任期編號為0,那么在推舉自己為候選人時,會將自己的任期編號增加為1
- 如果一個服務器節點,發現自己的任期編號比其他節點小,那么它會更新自己的任期編號到較大的編號值,比如節點B的任期編號是0,當收到來自節點A的請求投票RPC消息時,因為消息中包含了節點A的任期編號,且編號為1,那么節點B將把自己的任期編號更新為1
- 如果一個候選人或者領導者,發現自己的任期編號比其他節點小,那么它會立即恢復成跟隨者狀態。比如分區錯誤恢復后,任期編號為3的領導者節點B,收到來自新領導者的包含任期編號為4的心跳消息,那么節點B將立即恢復成跟隨者狀態
- 如果一個節點接收到一個包含較小的任期編號值的請求,那么它會直接拒絕這個請求。比如節點C的任期編號為4,收到包含任期編號為3的請求投票RPC消息,那么它將拒絕這個消息
5)、選舉有哪些規則?
-
領導者周期性地向所有跟隨者發送心跳消息(即不包含日志項的日志復制RPC消息),通知大家我是領導者,組織跟隨者發起新的選舉
-
如果在指定時間內,跟隨者沒有接收到來自領導者的消息,那么它就認為當前沒有領導者,推舉自己為候選人,發起領導者選舉
-
在一次選舉中,贏得大多數選票的候選人,將晉升為領導者
-
在一個任期內,領導者一直都會是領導者,直到它自身出現問題(比如宕機),或者因為網絡延遲,其他節點發起一輪新的選舉
-
在一次選舉中,每一個服務器節點最多會對一個任期編號投出一張選票,并且按照先來先服務的原則進行投票。比如節點C的任期編號為3,先收到了一個包含任期編號為4的投票請求(來自節點A),然后又收到了一個包含任期編號為4的投票請求(來自節點B)。那么節點C將會把唯一一張選票投給節點A,當再收到節點B的投票請求RPC消息時,對于編號為4的任期,已沒有選票可投了
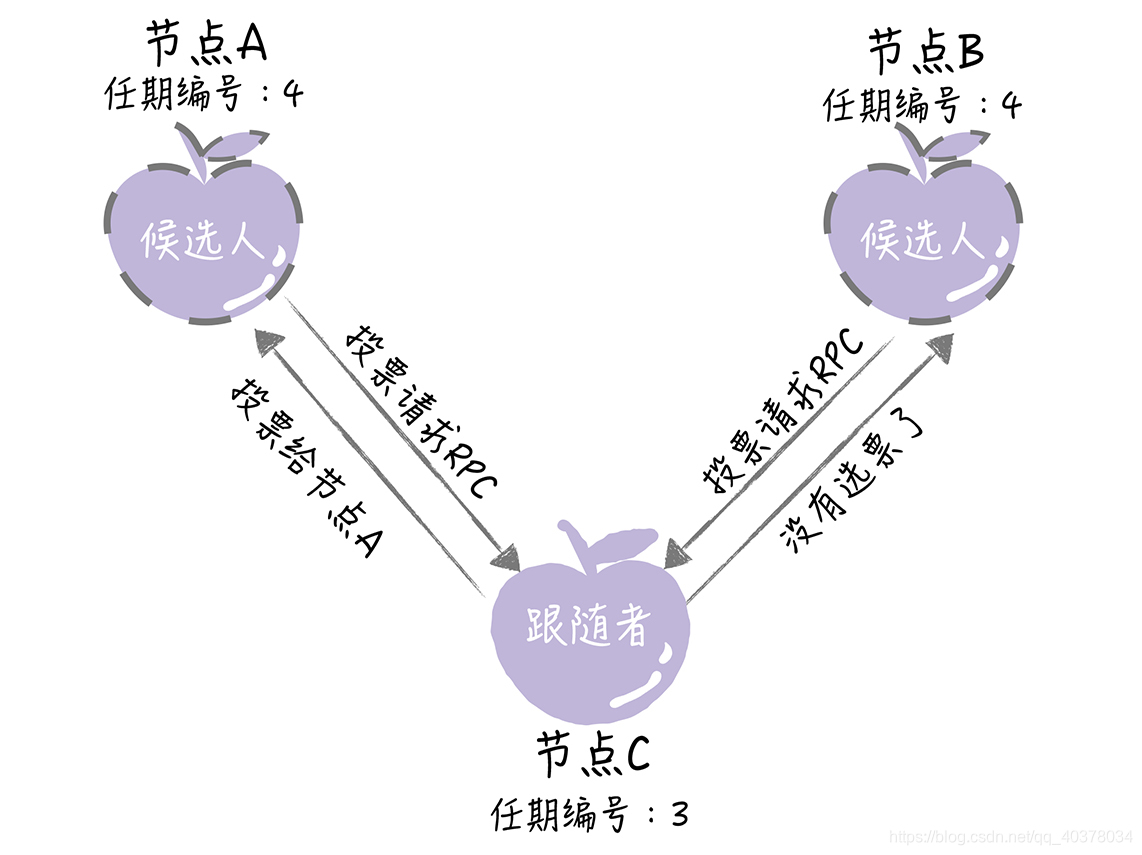
- 日志完整性高的跟隨者(也就是最后一條日志項對應的任期編號值更大,索引號更大)拒絕投票給日志完整性低的候選人。比如節點B的任期編號為3,節點C的任期編號為4,節點B的最后一條日志項對應的任期編號為3,而節點C為2,那么當節點C請求節點B投票給自己時,節點B將拒絕投票

選舉是跟隨者發起的,推舉自己為候選人;大多數選票是指集群成員半數以上的選票;大多數選票規則的目標,是為了保證在一個給定的任期內最多只有一個領導者
6)、隨機超時時間是什么?
Raft算法使用隨機選舉超時時間的方法,把超時時間都分散開來,在大多數情況下只有一個服務器節點先發起選舉,而不是同時發起選舉,這樣就能減少因選票瓜分導致選舉失敗的情況
在Raft算法中,隨機超時時間有2種含義:
- 跟隨者等待領導者心跳信息超時的時間間隔是隨機的
- 如果候選人在一個隨機時間間隔內,沒有贏得過半票數,那么選舉就無效了,然后候選人發起新一輪的選舉,也就是說,等待選舉超時的時間間隔是隨機的
7)、補充
1)Raft算法的強領導者模型選舉限制和局限如下:
- 讀寫請求和數據轉發壓力落在領導者節點,相當于單機,性能和吞吐量也會受到限制
- 大規模跟隨者的集群,領導者需要承擔大量元數據維護和心跳通知的成本
- 領導者單點問題,故障后直到新領導者選舉出來期間集群不可用
- 隨著候選人規模增長,收集半數以上投票的成本更大
2)強領導者模型會限制集群的寫性能,有什么辦法能突破Raft集群的寫性能瓶頸呢?
參考Kafka的分區和ES的主分片副本分片這種機制,雖然寫入只能通過Leader寫,但每個Leader可以負責不同的片區,來提高寫入的性能
2、日志復制
1)、如何理解日志?
副本數據是以日志的形式存在的,日志是由日志項組成,日志項是一種數據格式,它主要包含用戶指定的數據,也就是指令(Command),還包含一些附加信息,比如索引值(Log index)、任期編號(Term)
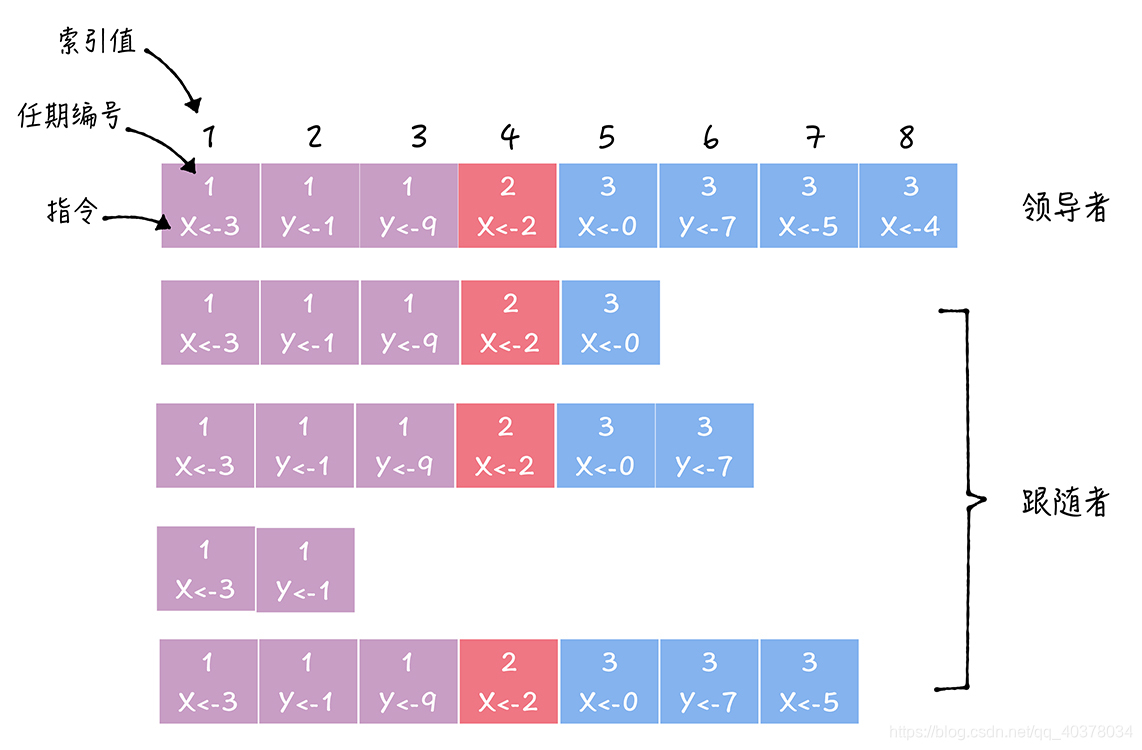
- 指令:一條由客戶端請求指定的、狀態機需要執行的指令,可以理解成客戶端指定的數據
- 索引值:日志項對應的整數索引值,用來標識日志項的,是一個連續的、單調遞增的證書號碼
- 任期編號:創建這條日志項的領導者的任期編號
2)、如何復制日志?
首先,領導者通過日志復制(AppendEntries)RPC消息,將日志項復制到集群其他節點上
接著,如果領導者接收到大多數的復制成功響應后,它將日志項應用到它的狀態機,并返回成功給客戶端。如果領導者沒有接收到大多數的復制成功響應,那么就返回錯誤給客戶端
領導者將日志項應用到它的狀態機,怎么沒通知跟隨者應用日志項呢?
因為領導者的日志復制RPC消息或心跳消息,包含了當前最大的、將會被提交的日志項索引值。所以通過日志復制RPC消息或心跳消息,跟隨者就可以知道領導者的日志提交位置信息
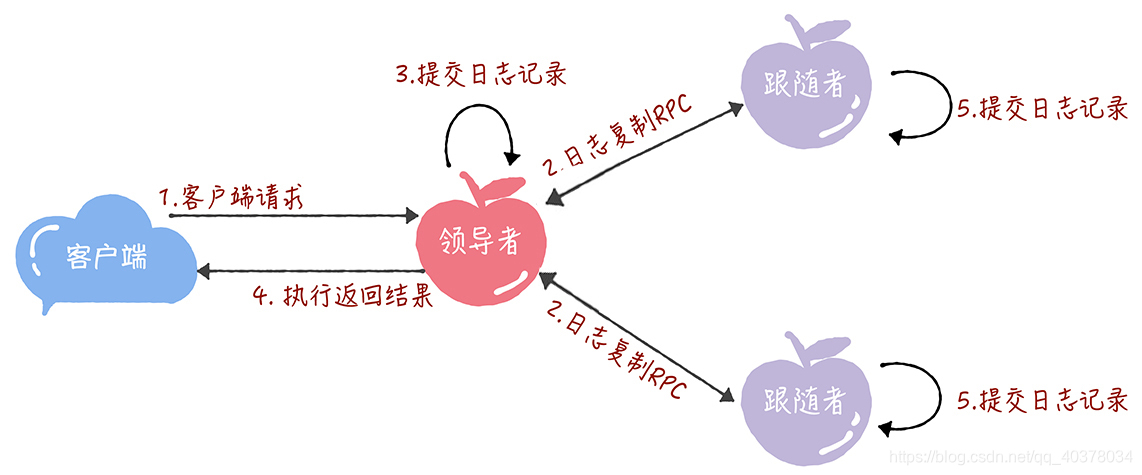
- 接收到客戶端請求后,領導者基于客戶端請求中的指令,創建一個新日志項,并附加到本地日志中
- 領導者通過日志復制RPC,將新的日志復制到其他的服務器
- 當領導者將日志項成功復制到大多數的服務器上的時候,領導者會將這條日志項應用到它的狀態機中
- 領導者將執行的結果返回給客戶端
- 當跟隨者接收到心跳消息,或者新的日志復制RPC消息后,如果跟隨者發現領導者已經提交了某條日志項,而它還沒應用,那么跟隨者就將這條日志項應用到本地的狀態機上
3)、如何實現日志的一致?
在Raft算法中,領導者通過強制跟隨者直接復制自己的日志項,處理不一致日志。也就是說,Raft是通過以領導者的日志為準,來實現各節點日志的一致性的
- 首先,領導者通過日志復制RPC的一致性檢查,找到跟隨者節點上與自己相同日志項的最大索引值。也就是說,這個索引值之前的日志,領導者和跟隨者是一致的,之后的日志是不一致的
- 然后,領導者強制跟隨者更新覆蓋不一致的日志項,實現日志的一致
引入2個新變量:
- PrevLogEntry:表示當前要復制的日志項,前面一條日志項的索引值。比如下圖中,如果領導者將索引值為8的日志項發送給跟隨者,那么此時PrevLogEntry值為7
- PrevLogTerm:表示當前要復制的日志項,前面一條日志項的任期編號,比如在圖中,如果領導者將索引值為8的日志項發送給跟隨者,那么此時PrevLogTerm值為4
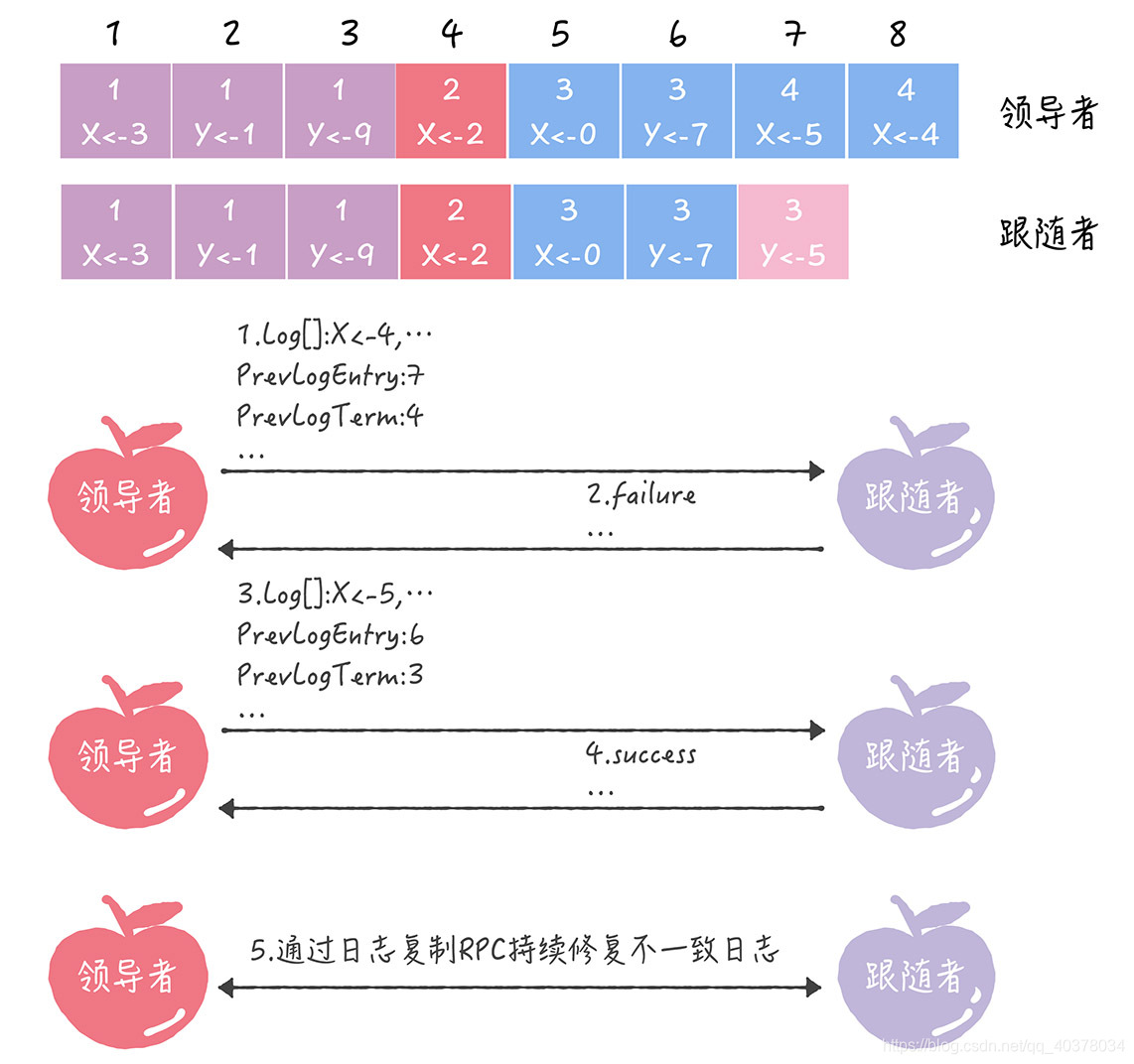
- 領導者通過日志復制RPC消息,發送當前最新日志項到跟隨者,這個消息的PrevLogEntry值為7、PrevLogTerm值為4
- 如果跟隨者在它的日志中,找不到PrevLogEntry值為7、PrevLogTerm值為4的日志項,也就是說它的日志和領導者的不一致了,那么跟隨者就會拒絕接收新的日志項,并返回失敗消息給領導者
- 這時,領導者會遞減要復制的日志項的索引值,并發送新的日志項到跟隨者,這個消息的PrevLogEntry值為6、PrevLogTerm值為3
- 如果跟隨者在它的日志中,找到了PrevLogEntry值為6、PrevLogTerm值為3的日志項,那么日志復制RPC返回成功,這樣一來,領導者就知道在PrevLogEntry值為6、PrevLogTerm值為3的位置,跟隨者的日志項與自己相同
- 領導者通過日志復制RPC復制并更新覆蓋該索引值之后的日志項(也就是不一致的日志項),最終實現了集群各節點日志的一致
領導者通過日志復制RPC一致性檢查,找到跟隨者節點上與自己相同日志項的最大索引值,然后復制并更新覆蓋該索引值之后的日志項,實現了各節點日志的一致。跟隨者中的不一致日志項會被領導者的日志覆蓋,而且領導者從來不會覆蓋或者刪除自己的日志
4)、補充
1)領導者接收到大多數的“復制成功”響應后,就會將日志應用到它自己的狀態機,然后返回“成功”響應客戶端。如果此時有個節點不在“大多數”中,也就是說它接收日志項失敗,那么在這種情況下,Raft會如何處理實現日志的一致呢?
處理日志項一致通過RPC一致性檢查,找到跟隨者中與自己相同日志項的最大索引,然后把后面的日志項同步過去,讓跟隨者復制更新
2)Raft在處理日志不一致時會給跟隨者發送RPC一致性檢查,找到和自己相同日志項的最大值,這里是對每個跟隨者而言的還是所有的跟隨者而言的?
日志復制信息對每個跟隨者都要單獨維護的
參考:
07 | Raft算法(一):如何選舉領導者?
08 | Raft算法(二):如何復制日志?
---------------------
作者:邋遢的流浪劍客
來源:CSDN
原文:https://blog.csdn.net/qq_40378034/article/details/117404484
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件

![[No0000DB]C# FtpClientHelper Ftp客戶端上傳下載重命名 類封裝](http://pic.xiahunao.cn/[No0000DB]C# FtpClientHelper Ftp客戶端上傳下載重命名 類封裝)

)
![[轉]guava快速入門](http://pic.xiahunao.cn/[轉]guava快速入門)


VS2010/MFC編程入門之四(MFC應用程序框架分析))





 靜態代理與JDK動態代理)





