從Spark應用的提交到執行完成有很多步驟,為了便于理解,我們把應用執行的整個過程劃分為三個階段。而我們知道Spark有多種運行模式,不同模式下這三個階段的執行流程也不相同。
本文介紹這三個階段的劃分,并概要介紹不同模式下各個階段的執行流程,各個模式的詳細流程會在后面的文章進行分析。
應用執行的階段劃分
我們知道,Spark應用可以在多種模式下運行。所謂多種模式主要是針對資源分配方式來說的,Spark應用可以在yarn,k8s,mesos等分布式資源管理平臺上運行,也可以啟動自帶的master和worker端來分配和管理資源(standalone模式)。例如:我們可以通過以下命令來向yarn提交一個spark任務:
$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples*.jar代碼1-3-1 spark應用提交命令
要注意的是,在執行以上應用提交命令時yarn資源管理集群必須已經啟動。另外,Spark應用的執行是通過Driver端和Executor端共同配合完成的。
要完成以上應用的執行,需要經歷很多步驟,為了便于更好的理解Spark應用從提交到執行完成的整個過程,我們把整個過程劃分成三個階段:
- 應用的提交
- 執行環境的準備
- 任務的調度和執行
如圖1所示:

不管以哪種模式運行,Spark應用的執行過程都可以劃分成這三個階段。下面對這三個階段分別進行說明。
三個階段概要說明
這三個階段以及每個階段要完成的目標如圖2所示。
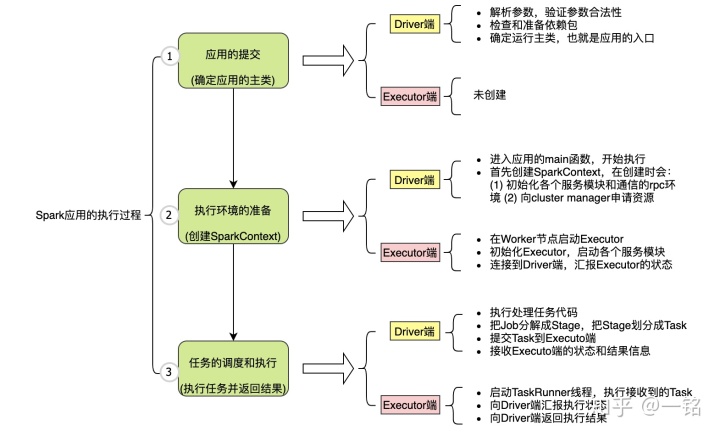
? 圖2 Spark應用執行的3階段目標概述
我們根據以下代碼為例,來講解Spark應用執行的各個階段。
# 第1階段:應用的提交
這個階段在Driver端完成,主要目標是:準備依賴包并確定Spark應用的執行主類。具體的任務包括:
- 解析任務提交的參數,并對參數進行解析和保存。
- 準備(可能會下載)任務啟動參數指定的依賴文件或程序包。
- 根據Spark應用的執行模式和應用的編寫語言,來確定執行的主類名稱。
- 實例化執行主類,生成SparkApplication對象,并調用SparkApplication#start()函數來運行Spark應用(若是Java或scala代碼其實是:執行Spark應用中的main函數)。
注意:第1階段完成時,Driver端并沒有向資源管理平臺申請任何資源,也沒有啟動任何Spark內部的服務。
第2階段:執行環境的準備
通過第1階段,已經找到了運行在Driver端的Spark應用的執行主類,并創建了SparkApplication對象:app。此時,在app.start()函數中會直接調用主類的main函數開始執行應用,從而進入第2階段。
第2階段主要目標是:創建SparkSession(包括SparkContext和SparkEnv),完成資源的申請和Executor的創建。第2階段完成后Task的執行環境就準備好了。
也就是說,第2階段不僅會在Driver端進行初始化,而且還要準備好Executor。這一階段的任務主要是在Driver端執行創建SparkSession的代碼來完成,也就是執行下面一行代碼:
val 第2階段的Driver端主要完成以下步驟:
- 創建SparkContext和SparkEnv對象,在創建這兩個對象時,向Cluster Manager申請資源,啟動各個服務模塊,并對服務模塊進行初始化。
- 這些服務模塊包括:DAG調度服務,任務調度服務,shuffle服務,文件傳輸服務,數據塊管理服務,內存管理服務等。
第2階段的Executor端主要完成以下步驟:
- Driver端向Cluster Manager申請資源,若是Yarn模式會在NodeManager上創建ApplicationMaster,并由ApplicationMaster向Cluster Manager來申請資源,并啟動Container,在Container中啟動Executor。
- 在啟動Executor時向Driver端注冊BlockManager服務,并創建心跳服務RPC環境,通過該RPC環境向Driver匯報Executor的狀態信息。
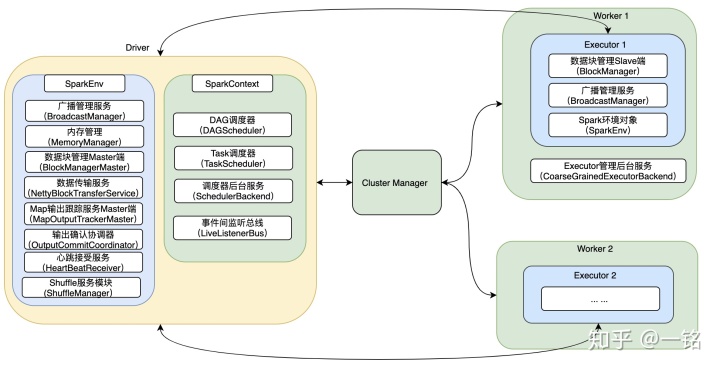
詳細的執行步驟,會在后面介紹每種模式的運行原理時,詳細分析。第2階段執行完成后的Spark集群狀態如下:
第3階段:任務的調度和執行
通過第2階段已經完成了Task執行環境的初始化,此時,在Driver端已經完成了SparkContext和SparkEnv的創建,資源已經申請到了,并且已經啟動了Executor。
這一階段會執行接下來的數據處理的代碼:
val 第3階段Driver端主要完成以下步驟:
- 執行Spark的處理代碼,當執行map操作時,生成新的RDD;
- 當執行Action操作時,觸發Job的提交,此時會執行以下步驟:
- 根據RDD的血緣,把Job劃分成相互依賴的Stage;
- 把每個Stage拆分成一個或多個Task;
- 把這些Task提交給已經創建好的Executor去執行;
- 獲取Executor的執行狀態信息,直到Executor完成所有Task的執行;
- 獲取執行結果和最終的執行狀態。
小結
本節介紹了Spark應用的執行過程,通過本節的學習應該對Spark應用的執行過程有一個總體的理解。接下來會根據具體的運行模式來詳細分析每個階段的執行步驟。

)



table塊鉆取,返回記住table塊位置)







![java圖片識別查看器模擬_[轉載]windows照片查看器無法顯示圖片內存不足](http://pic.xiahunao.cn/java圖片識別查看器模擬_[轉載]windows照片查看器無法顯示圖片內存不足)





