
【注1:結尾有大福利!】
【注2:想寫一個大數據小白系列,介紹大數據生態系統中的主要成員,理解其原理,明白其用途,萬一有用呢,對不對。】
??
大數據是什么?拋開那些高大上但籠統的說法,其實大數據說的是兩件事:一、怎么存儲大數據,二、怎么計算大數據。
我們先從存儲開始說,如果清晨起床,你的女仆給你呈上一塊牛排,牛排太大,一口吃不了,怎么辦?拿刀切小。
同樣的,如果一份數據太大,一臺機器存不了,怎么辦?切小了,存到幾臺機器上。
想要保存海量數據,無限地提高單臺機器的存儲能力顯然是不現實,就好比我們不能把一棟樓蓋得無限高一樣(通常這也不是經濟的做法),增加機器數量是相對可持續的方案。
使用多臺機器,需要有配套的分布式存儲系統把這些機器組織成一個整體,由于Hadoop幾乎是目前大數據領域的事實標準,那么這里介紹的分布式存儲系統就是HDFS(Hadoop Distributed Filesystem)。
先來介紹幾個重要概念。
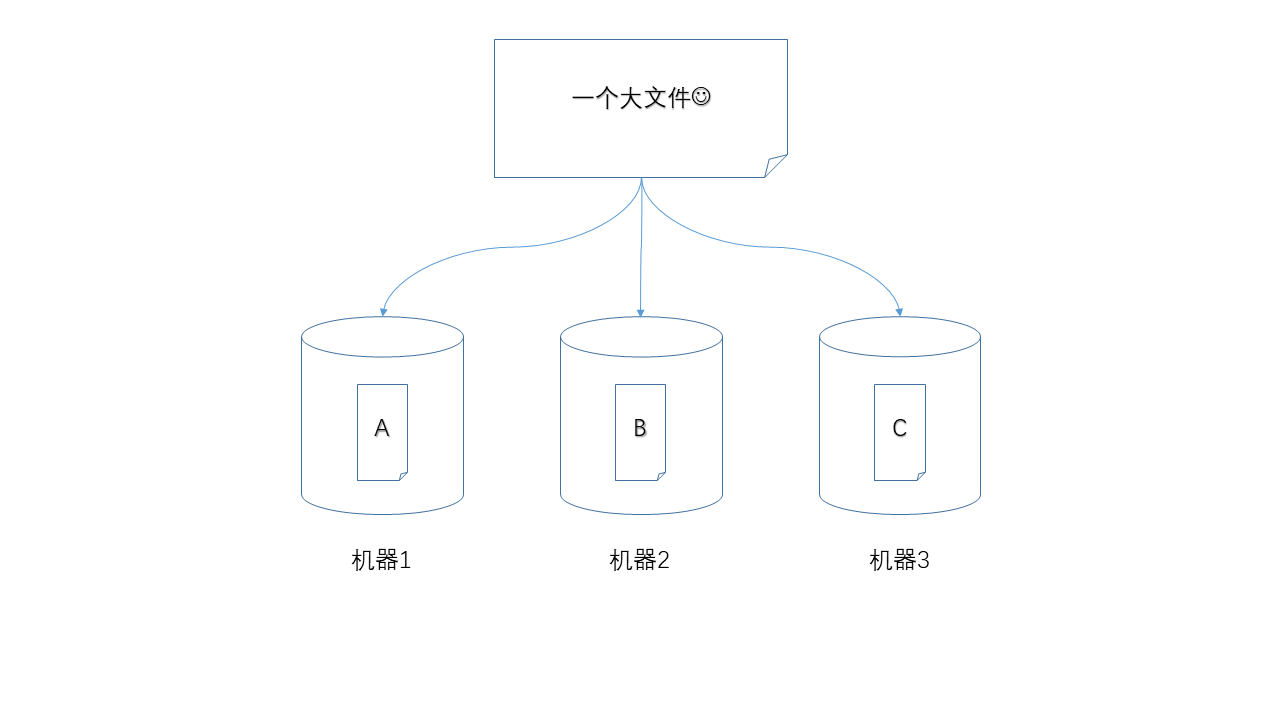
- 分片(shard)
就好比把牛排切成小塊,對大的文件進行切分,顯然是進行分布式存儲的前提,例如,HDFS中默認將數據切分成128MB的塊(block)。
?
- ?副本(replica)
三臺機器中,如果有一臺出現故障,如何保證數據不丟失,那么就是使用冗余的方式,為每一個數據塊都產生多個副本。
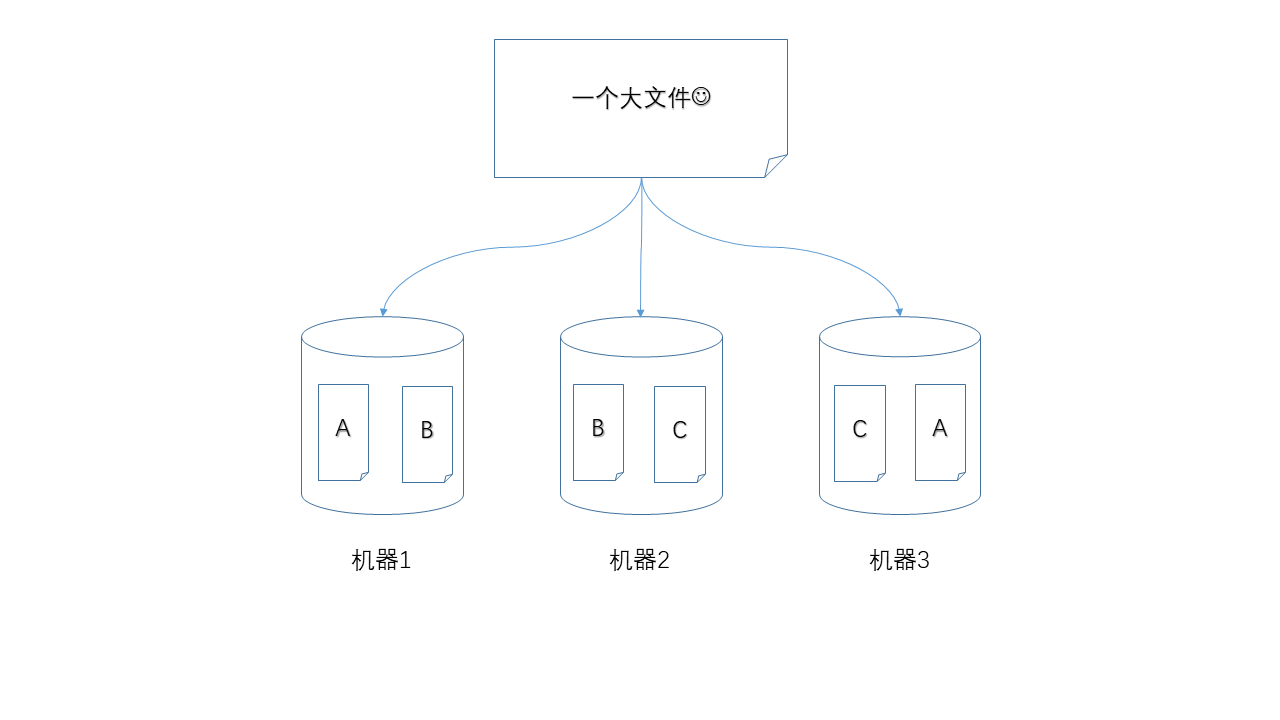
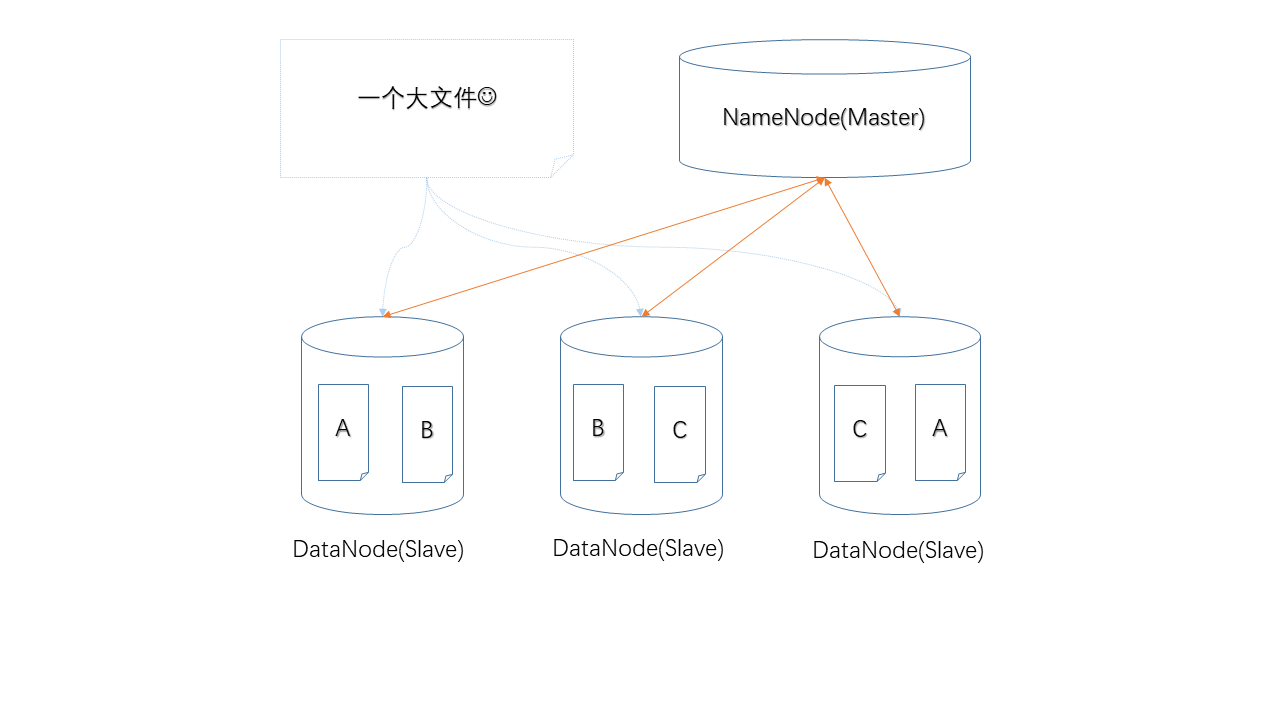
下面圖示中,任何單獨一個節點掉線,都不會造成數據丟失,仍然可以湊齊A、B、C三個數據塊。
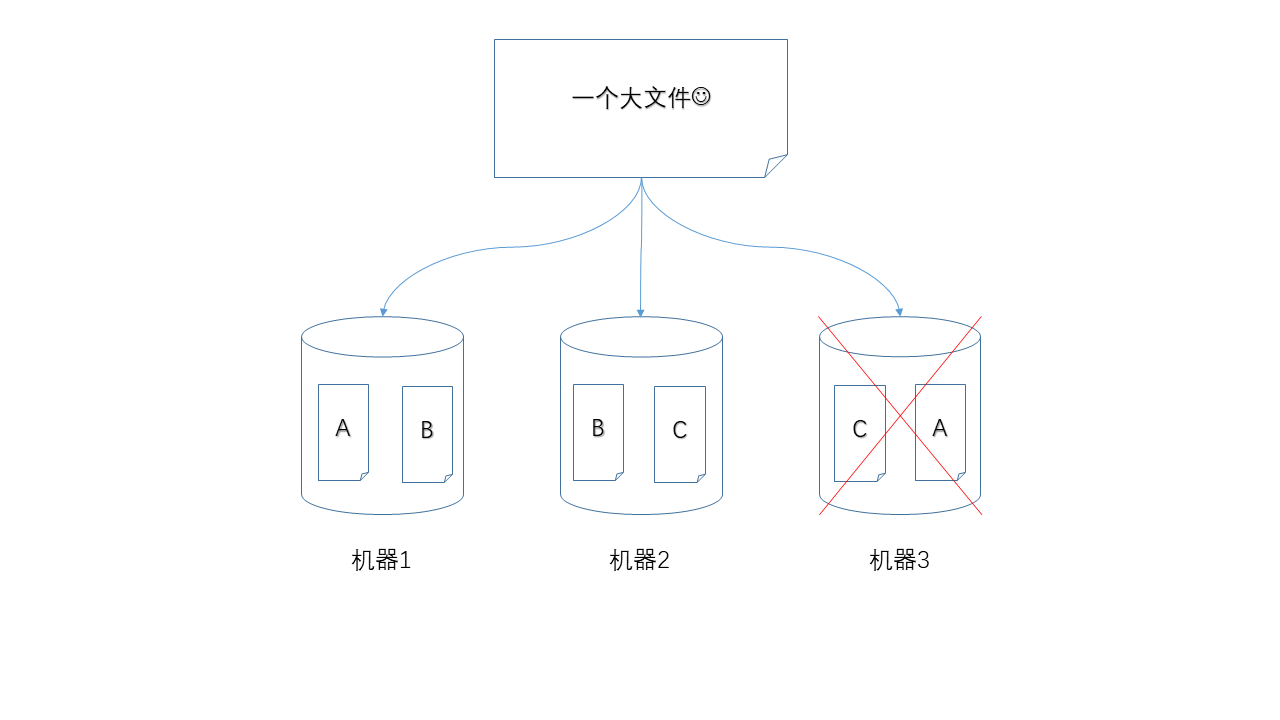
當然,如果兩個節點同時掉線就不行了。
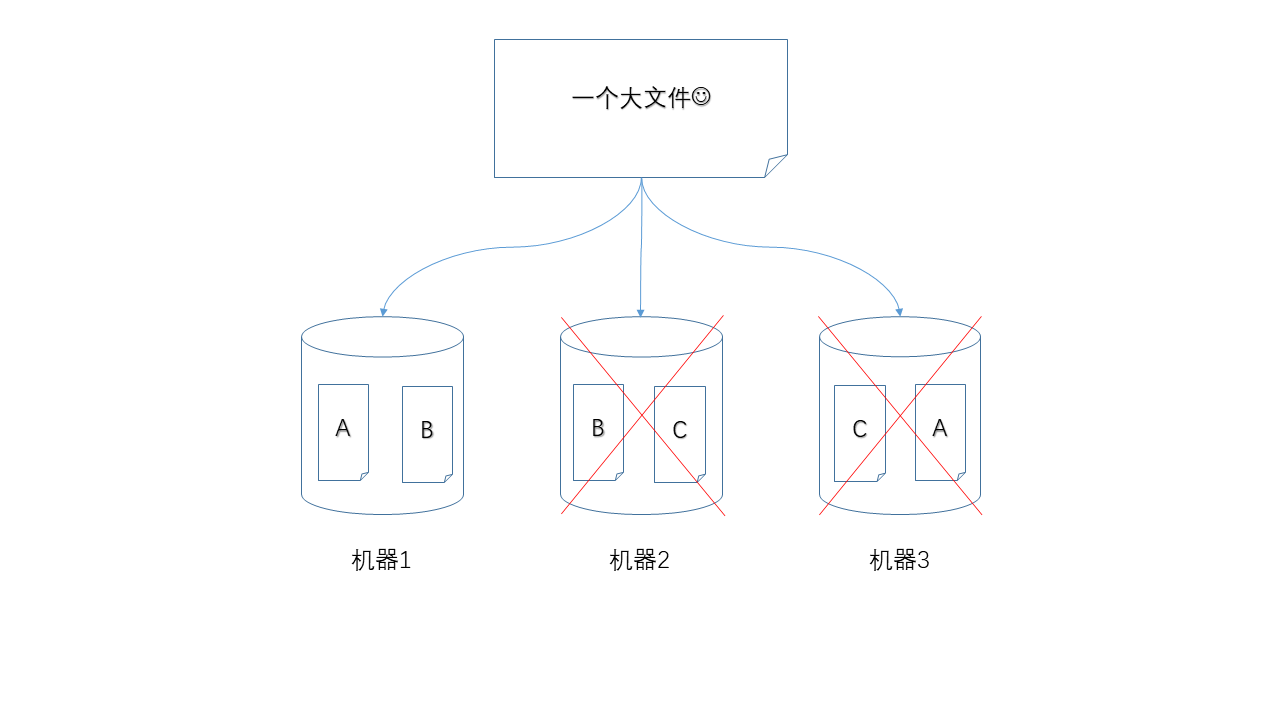
不過,如果每個數據塊都有兩個副本,那么可以承受同時損失兩個節點。代價是,你的存儲成本上升了。
- Master/Slave架構
只有工人而沒有包工頭的工地肯定不能正常運轉,所以,除了上面3臺負責存儲的機器,還需要至少一臺機器來領導它們,給它們分配工作,否則誰也沒辦法中的A、B、C具體應該存在哪個機器上。
HDFS中采用Master/Slave架構,其中的NameNode就是Master,負責管理工作,而DataNode就是Slave,負責存儲具體的數據,NameNode上管理著元數據,簡單的講就是記錄哪個數據塊存儲在哪臺機器上。同時,DataNode也會定時向NameNode匯報自己的工作狀態,以便后者監控節點狀態、是否故障。
?
說完上面幾個我覺得需要了解的基礎概念,我們再把HDFS的讀、寫流程描述一下。
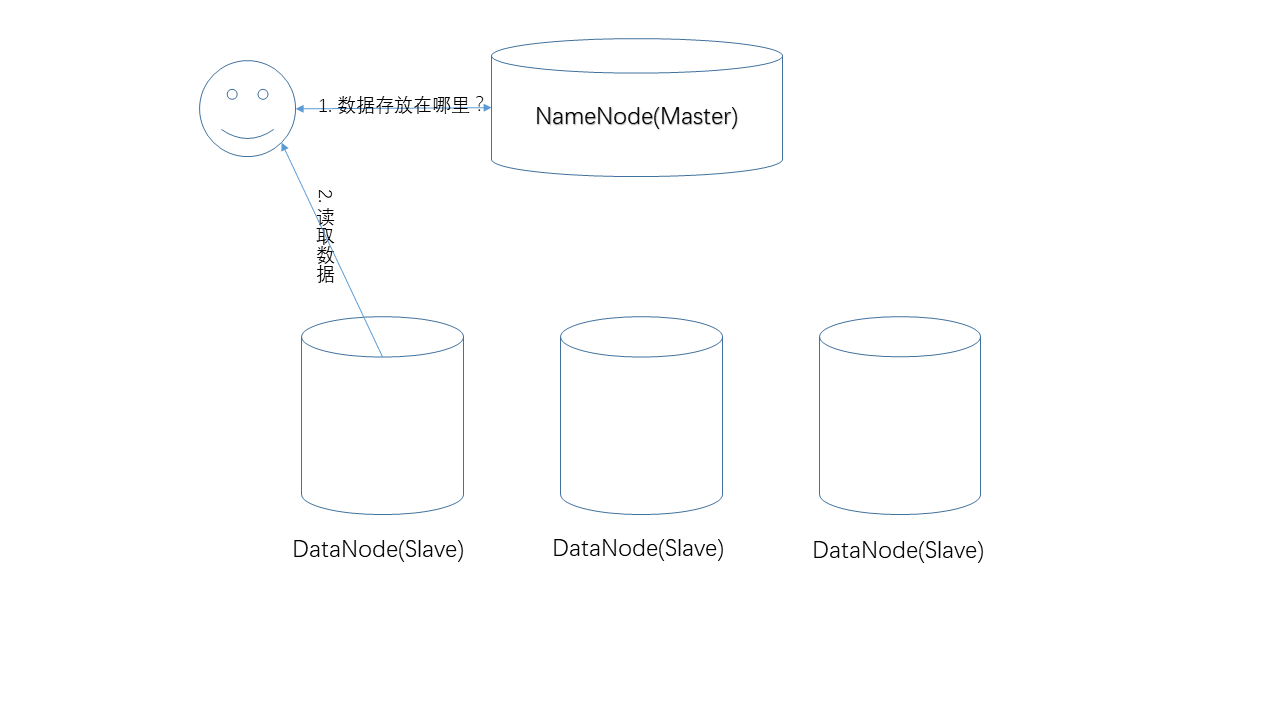
- 讀取數據
讀取數據的過程。在這個過程中,NameNode負責提供數據的存儲位置,真正的數據讀取操作發生在用戶和DataNode之間。由于數據有副本,一份數據在多個節點上存在,具體NameNode返回哪個節點,遵循一定的原則(比如,就近原則)。
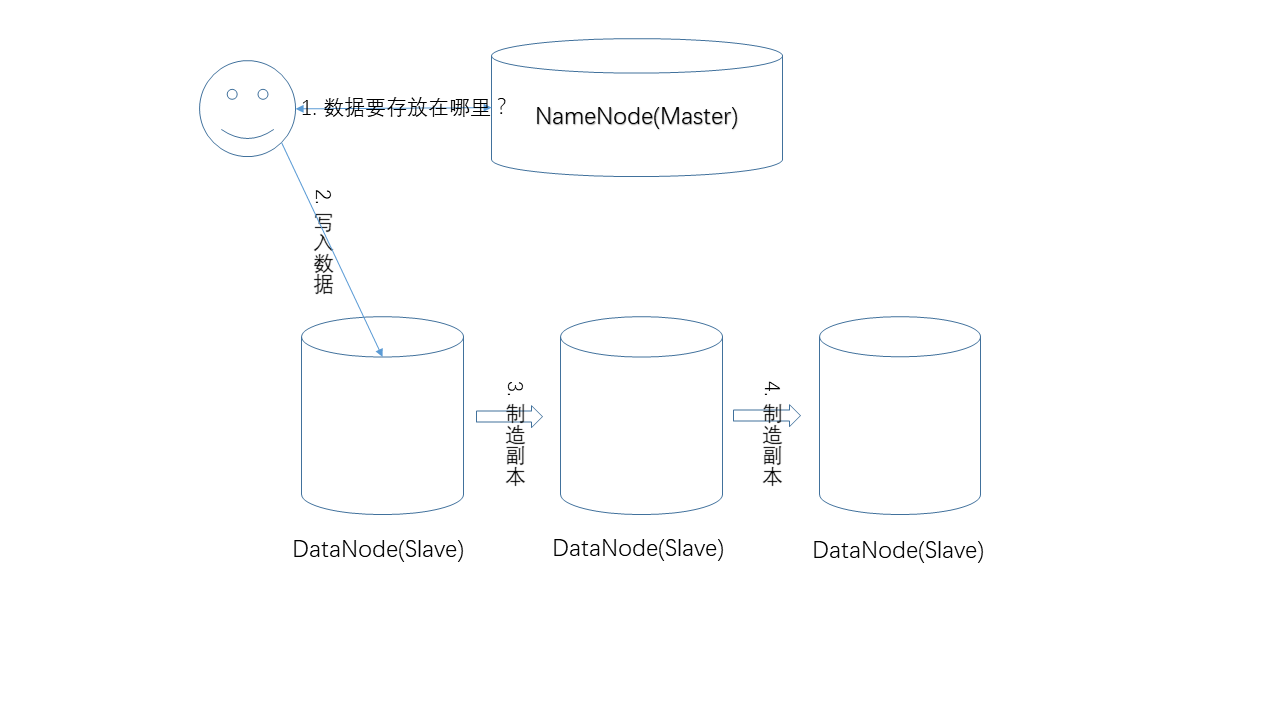
- 寫入數據
寫入數據的過程。和讀取流程類似,NameNode負責提供數據的存儲位置,真正的寫入操作發生在用戶和DataNode之間,而副本的制造,是在DataNode之間發生的,例如用戶先把數據寫入節點1,節點1再把數據復制到節點2等。
?
這篇文章就先到這里,下一篇準備接受HDFS中的單點問題、HA、Federation等概念。
?
最后,福利來了,關注公眾號“程序員雜書館”,將免費送出大數據經典書籍《Spark快速大數據分析》,沒錯,就是下面這本,紙質書哦,不是什么亂七八糟的其他書哦!還猶豫什么,抓緊掃碼關注吧。“程序員雜書館”以后將每周為大家帶來經典書籍資料、原創干貨分享,謝謝大家。
需要書的同學請直接在公眾號留言哈,如果不想要紙質書的也可以說明,我會選擇一些PDF數據贈送,謝謝大家。













:來自面向對象開發之前的吶喊:“學會寫可重用的代碼”...)
)





.csv()無法定位本地文件的問題)
