【編者的話】本文會讓你了解Prometheus是什么,并讓你理解它在監控領域的適用場景。
Prometheus起源
很久以前,加利福尼亞州山景城有一家名為Google的公司。他們推出了大量產品,其中最著名的是廣告系統和搜索引擎平臺。為了運行這些不同的產品,他們建立了一個名為Borg的平臺。Borg系統是“一個集群管理器,可以運行來自成千上萬個不同的應用程序的成千上萬個作業,它跨越多個集群,每個集群都有數萬臺服務器。“開源容器管理平臺Kubernetes很多部分都是對Borg平臺的傳承。在Borg部署到Google后不久,他們意識到這種復雜性需要一個同等水平的監控系統。Google建立了這個系統并命名為Borgmon。Borgmon是一個實時的時間序列監控系統,它使用這些時間序列數據來識別問題并發出警報。如果你想和更多Prometheus技術專家交流,可以加我微信liyingjiese,備注『加群』。群里每周都有全球各大公司的最佳實踐以及行業最新動態 。
Prometheus的靈感來自谷歌的Borgmon。它最初由前谷歌SRE Matt T. Proud開發,并轉為一個研究項目。在Proud加入SoundCloud之后,他與另一位工程師Julius Volz合作開發了Prometheus。后來其他開發人員陸續加入了這個項目,并在SoundCloud內部繼續開發,最終于2015年1月公開發布。
與Borgmon一樣,Prometheus主要用于提供近實時的,針對動態云環境下的和基于容器的微服務、服務和應用程序的檢測監控。SoundCloud是這些架構模式的早期采用者,Prometheus的建立是為了滿足這些需求。如今,Prometheus被更多的公司廣泛使用,通常也是滿足類似的監控需求,但也用來監控傳統架構的資源。
Prometheus專注于現在正在發生的事情,而不是追蹤數周或數月前的數據。它基于這樣一個前提,即大多數監控查詢和警報都是從最近的,通常是一天內的數據生成的。Facebook在其內部時間序列數據庫Gorilla的論文中驗證了這一觀點。Facebook發現85%的查詢是針對26小時內的數據。Prometheus假定你嘗試修復的問題可能是最近出現的,因此最有價值的是最近時間的數據,這反映在強大的查詢語言和通常有限的監控數據保留期上。
Prometheus是用開源編程語言Go編寫的,并在Apache 2.0許可證下授權。它孵化于云原生云計算基金會(Cloud Native Computing Foundation)。
Prometheus架構
Prometheus通過抓取或拉取從應用程序中暴露的時間序列數據來工作。時間序列數據通常由應用程序本身通過客戶端庫,或通過稱為導出器(exporter)的代理作為HTTP端點暴露。目前已經存在很多exporter和客戶端庫,支持多種編程語言、框架和開源應用程序,例如,Apache Web服務器和MySQL數據庫等。
Prometheus還有一個推送網關(push gateway),可用于接收少量數據 - 例如,來自無法拉取的目標數據,比如臨時作業或者防火墻后面的目標。
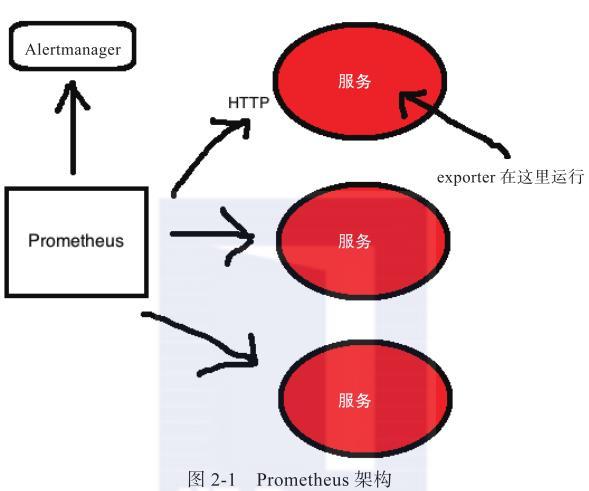
Prometheus架構
圖文字翻譯:Alert manager:Alertmanager;My Service:服務;Exporters run here:Exporter在這運行
指標收集
Prometheus稱其可以抓取的指標來源為端點(endpoint)。端點通常對應于單個進程、主機、服務或應用程序。為了抓取端點數據,Prometheus定義了名為目標(target)的配置。這是執行抓取所需的信息 - 例如,如何進行連接,要應用哪些元數據,連接需要哪些身份驗證,或定義抓取將如何執行的其他信息。一組目標被稱為作業(job)。作業通常是具有相同角色的目標組 - 例如,負載均衡器后面的Apache服務器集群,它們實際上是一組相似的進程。
生成的時間序列數據將被收集并存儲在Prometheus服務器本地,也可以設置從服務器發送數據到外部存儲器或其他時間序列數據庫。
服務發現
可以通過多種方式處理要監控的資源的發現,包括:
- 用戶提供的靜態資源列表
- 基于文件的發現。例如,使用配置管理工具生成在Prometheus中可以自動更新的資源列表
- 自動發現。例如,查詢Consul等數據存儲,在Amazon或Google中運行實例,或使用DNS SRV記錄生成資源列表
聚合和警報
服務器還可以查詢和聚合時間序列數據,并創建規則來記錄常用的查詢和聚合。這允許你從現有的時間序列創建新的時間序列,例如計算變化率和比率或求和等聚合。這樣就不必重新創建常用的聚合,例如用于調試,并且預計算可能比每次需要時運行查詢性能更好。
Prometheus還可以定義警報規則。這些是為系統配置在滿足條件時觸發警報的標準,例如,資源時間序列開始顯示異常的CPU使用率。Prometheus服務器沒有內置警報工具,而是將警報從Prometheus服務器推送到名為警報管理器(Alertmanager)的單獨服務器。Alertmanager可以管理、整合和分發各種警報到不同目的地 - 例如,它可以在發出警報時發送電子郵件,并能夠防止重復發送。
查詢數據
Prometheus服務器還提供了一套內置查詢語言PromQL,一個表達式瀏覽器以及用于瀏覽服務器上數據的圖形界面。
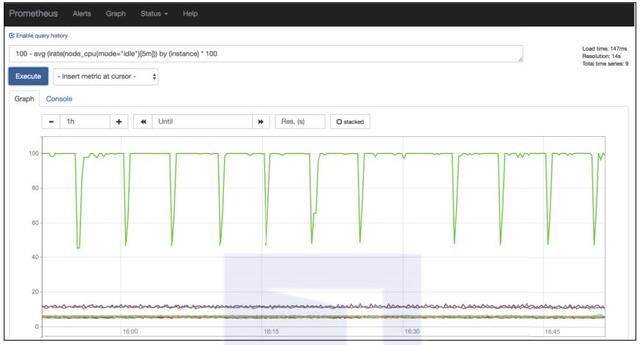
Prometheus表達式瀏覽器
自治
每個Prometheus服務器都設計為盡可能自治,旨在支持擴展到數千臺主機的數百萬個時間序列的規模。數據存儲格式被設計盡可能降低磁盤的使用率,并在查詢和聚合期間快速檢索時間序列。
提示:為了速度和可靠性,建議Prometheus服務器充分使用內存(Prometheus在內存中做很多事)和SSD磁盤。關于SSD使用可以參考注釋鏈接視頻。
冗余和高可用性
冗余和高可用性側重彈性而不是數據持久性。Prometheus團隊建議將Prometheus服務器部署到特定環境和團隊,而不是僅部署一個單體Prometheus服務器。如果你確實要部署高可用HA模式,則可以使用兩個或多個配置相同的Prometheus服務器收集時間序列數據,并且所有生成的警報都由可消除重復警報的高可用Alertmanager集群處理。
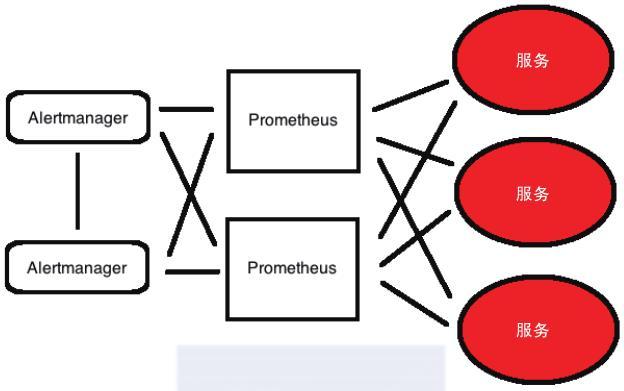
Prometheus冗余架構
圖文字翻譯:Alert manager:Alertmanager;My Service:服務
提示:我們將在第7章中介紹如何實現此配置。
可視化
可視化通過內置表達式瀏覽器提供,并與開源儀表板Grafana集成。此外,Prometheus也支持其他儀表板。
Prometheus數據模型
正如之前所述,Prometheus收集時間序列數據。為了處理這些數據,它使用一個多維時間序列數據模型。這個時間序列數據模型結合了時間序列名稱和被稱為標簽(label)的鍵/值對,這些標簽提供了維度。每個時間序列由時間序列名稱和標簽的組合唯一標識。
指標名稱
時間序列名稱通常可以描述收集的時間序列數據的一般性質 - 例如,website_visits_total為網站訪問的總數。
名稱可以包含ASCII字符、數字、下劃線和冒號。
指標標簽
標簽為Prometheus數據模型提供了維度。它們為特定時間序列添加上下文。例如,total_website_visits時間序列可以使用能夠識別網站名稱、請求IP或其他特殊標識的標簽。Prometheus可以在一個時間序列、一組時間序列或者所有相關的時間序列上進行查詢。
標簽共有兩大類:監控標簽(instrumentation label)和目標標簽(target label)。監控標簽來自被監控的資源 - 例如,對于與HTTP相關的時間序列,標簽可能會顯示所使用的特定HTTP謂詞。這些標簽在被抓取之前被添加到時間序列中,例如由客戶端或exporter。目標標簽更多地與架構相關 - 它們可能會識別時間序列所在的數據中心。目標標簽在Prometheus抓取期間和之后添加。
時間序列由名稱和標簽標識(盡管從技術上講,名稱本身也是名為__name__的標簽)。如果你在時間序列中添加或更改標簽,Prometheus會將其視為新的時間序列。
提示:你可以理解label就是鍵/值形式的標簽,并且新的標簽會創建新的時間序列。
標簽名稱可以包含ASCII字符、數字和下劃線。
提示:帶有__前綴的標簽名稱保留給Prometheus內部使用。
采樣數據
時間序列的真實值是采樣(sample)的結果,它包括兩部分:
- 一個float64類型的數值
- 一個毫秒精度的時間戳
符號表示
結合這些元素,我們可以看到Prometheus如何將時間序列表示為符號(notation)。
代碼清單2.1時間序列符號:
{=, ...} 例如,帶有標簽的total_website_visits時間序列可能如下所示。
代碼清單2.2時間序列示例:
total_website_visits{site="MegaApp


)

 如何在Ubuntu設定P7010的1280 x 768解析度? (OS) (Linux) (Ubuntu) (NB) (P7010))



![[網摘].NET 程序員十種必備工具-概述](http://pic.xiahunao.cn/[網摘].NET 程序員十種必備工具-概述)




![[轉] C#異步操作](http://pic.xiahunao.cn/[轉] C#異步操作)




