點擊上方關注,All in AI中國
本文將介紹如何使用Keras和Google CoLaboratory與TPU一起訓練LSTM模型,與本地計算機上的GPU相比,這樣訓練能大大縮短訓練時間。

很長一段時間以來,我都在單張GTX 1070顯卡上訓練我的模型,它的單精度大約為8.18 TFlops。后來Google的Colab開放了免費的Tesla K80顯卡,配備12GB RAM,8.73TFlops。直到最近,Colab的運行時類型選擇器中還會彈出帶有180 TFlops的Cloud TPU選項。這篇教程將簡要介紹如何將現有的Keras模型轉換為TPU模型,然后在Colab上訓練。與在GTX1070上訓練相比,TPU能夠加速20倍。
我們將構建一個易于理解,但訓練起來非常復雜的Keras模型,這樣我們就可以稍微"預熱"一下Cloud TPU。在IMDB情感分類任務上訓練LSTM模型可能是一個很好的例子,因為相比密集層和卷積層來說,訓練LSTM對算力要求更高。
工作流程概述:
- 使用靜態輸入batch_size構建用于功能API訓練的Keras模型
- 將Keras模型轉換為TPU模型
- 使用靜態batch_size * 8訓練TPU模型,并將權重保存到文件
- 創建一個結構相同,但輸入批大小可變的Keras模型,用于推理
- 加載模型權重
- 基于推理模型進行預測
在閱讀本文的同時,你可以上手試驗相應的Colab Jupyter notebook:Keras_LSTM_TPU.ipynb。(https://colab.research.google.com/drive/1QZf1WeX3EQqBLeFeT4utFKBqq-ogG1FN)
首先,按照下圖中的說明來激活在Colab運行中的TPU。
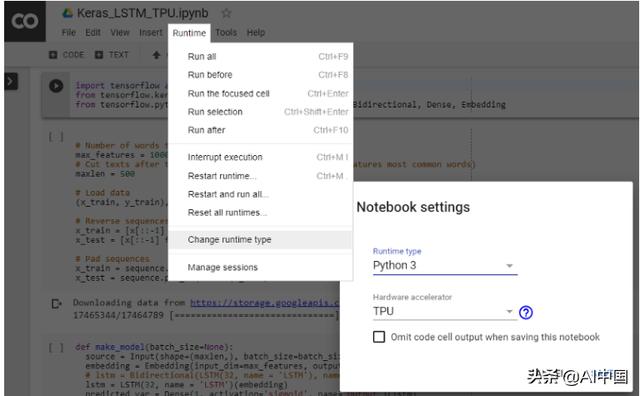
激活TPU
固定輸入批尺寸
大多數情況下,CPU和GPU上對輸入形狀沒有限制,但XLA/TPU環境下會強制使用固定的形狀和批尺寸。
Can TPU包含8個TPU核心,作為獨立的處理單元運行。如果沒有使用所有八個核心,那TPU就不會得到充分利用。為了充分提高訓練的矢量化速度,相比在單一GPU上訓練的同樣的模型,我們可以選擇較大的批尺寸。總批尺寸大小為1024(每個核心128個)通常是一個很好的起點。
如果你要訓練批尺寸較大的型號,請嘗試慢慢減小批尺寸,以保證TPU內存放得下,只需確保總批尺寸為64的倍數(每核心批尺寸應該是8的倍數)。
值得一提,在批尺寸較大時,通常可以提高優化器的學習速率,以實現更快的收斂。你可以在本文中找到參考——"Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour"。(https://arxiv.org/pdf/1706.02677.pdf)
在Keras中,要定義靜態批處理尺寸,我們使用函數API,然后為輸入層指定batch_size參數。請注意,模型構建在一個帶有batch_size參數的函數中,因此我們之后可以很方便地創建在CPU或GPU上運行的模型,這些模型接受可變批尺寸的輸入。
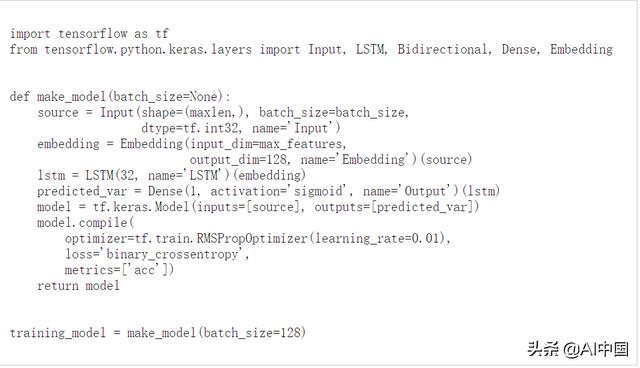
此外,我們在這里使用了tf.train.Optimizer而不是標準的Keras優化器,因為TPU對Keras優化器的支持還處于實驗階段。
將Keras模型轉換為TPU模型
tf.contrib.tpu.keras_to_tpu_model函數將tf.keras模型轉換為等價的TPU版本。

然后,我們使用標準的Keras方法來訓練,保存權重并評估模型。請注意,batch_size設置為模型輸入batch_size的八倍,因為輸入樣本在8個TPU核心上均勻分布。

我做了一個實驗,用來比較在Windows PC上運行單個GTX1070和在Colab上運行的TPU之間的訓練速度,結果如下:
- GPU和TPU都將輸入批尺寸設為128。
- GPU:每個歷元179秒。20個歷元后的驗證準確率達到了76.9%,總計3600秒。
- TPU:每個歷元5秒(第一個歷元需要49秒)。20個歷元后的驗證準確率達到了95.2%,總計150秒。
- 在20個歷元之后TPU的驗證準確度高于在GPU上的表現,那是因為TPU上同時訓練8個批的樣本(每個批的大小為128)。
在CPU上進行推理
一旦我們獲得了模型權重,我們就可以像往常一樣加載它,然后在CPU或GPU等其他設備上進行預測。我們想要推理模型接受可變的輸入批大小,這可以使用之前的make_model()函數來實現。

你可以看到推理模型現在可以接受可變輸入樣本數目,

然后,你可以使用標準的fit()、evaluate()函數與推理模型。
結論以及進一步閱讀
這篇快速教程向你簡要介紹了如何利用Google Colab上的免費Cloud TPU資源更快地訓練Keras模型。
云TPU文檔:https://cloud.google.com/tpu/docs/
云TPU性能指南:https://cloud.google.com/tpu/docs/performance-guide
云TPU故障排除指南:https://cloud.google.com/tpu/docs/troubleshooting
XLA概述:https://www.tensorflow.org/performance/xla/

編譯出品


![[New Portal]Windows Azure Virtual Machine (14) 在本地制作數據文件VHD并上傳至Azure(1)](http://pic.xiahunao.cn/[New Portal]Windows Azure Virtual Machine (14) 在本地制作數據文件VHD并上傳至Azure(1))
)



)






 PowerShell整理)




