文章目錄
- 3.8 集合論
- nee中的元素在haystack中出現的次數,可以在任何可迭代對象上
- 3.8.1集合字面量
- 3.8.2 集合推導
- 3.8.3 集合操作
- 3.9 dict和set的背后
- 3.9.1 一個關于效率的實驗
- 3.9.2 字典中的散列表
- 1.散列值和相等性
- 2.散列表算法
- 獲取值:
- 添加新的元素
- 更新現有的鍵值
- 3.9.3 dict的實現及其導致的結果
- 1.鍵必須是可散列的
- 所有用戶自定義的對象默認都是可散列的,因為它們的散列值由id()值獲取,而且都是不相等的。
- 2.字典在內存上的開銷巨大
- 3.鍵查詢很快
- 4.鍵的次序取決于添加順序
- 5.往字典里添加新鍵可能會改變已有鍵的順序
- 3.9.4 set的實現以及導致的結果
3.8 集合論
集合的本質是許多唯一對象的聚集。一次,集合可以用于去重。
集合中的元素必須是可散列的,set類型本身是不可散列的,但是frozenset可以。因此可以創建一個包含不同frozenset的set.
- 什么叫做可散列的呢?“python里所有不可變類型都是可散列的”。
除了保證唯一性,集合還實現了很多基礎的中綴表達式
| 中綴運算符 | 含義 |
|---|---|
| a&b | 返回它們的交集 |
| a | b |
| a-b | 返回它們的差集 |
nee中的元素在haystack中出現的次數,可以在任何可迭代對象上
found = len(set(nee) & set(haystack))
或者
found = len(set(nee).intersection(haystack))
除了快速的查找功能(歸功于背后的散列表),內置的set和frozenset提供了額豐富的功能和操作。
3.8.1集合字面量
{1},{1,2,3}和數學形式一模一樣
3.8.2 集合推導
例子:
>>> from unicodedata import name
>>> {chr(i) for i in range(32,256) if 'SIGN' in name(chr(i),'')}
{'×', '?', '%', '÷', '°', '?', '+', '¤', '£', '?', '?', '¢', '<', '±', 'μ', '=', '$', '§', '#', '¥', '>'}
3.8.3 集合操作
比較普遍,可以參考之前的文章
3.9 dict和set的背后
重視一下的幾個問題:
- python里的dict和set的效率有多高?
- 為什么它們是無序的?
- 為什么并不是所有的python對象都可以當做dict的鍵或者set里面的元素?
- 為什么dict的鍵和set的順序是根據它們被添加的次序而定的,以及為什么在映射對象的生命周期中,這個順序呢并不是一成不變的?
- 為什么不應該在迭代循環dict或是set的同時往里添加元素?
3.9.1 一個關于效率的實驗
最快的是集合,最糟糕的是列表。由于列表的背后沒有散列表來支持in運算符,每次搜索都需要掃描一次完整的列表,導致所需的時間線性增長。
3.9.2 字典中的散列表
散列表其實是一個稀疏數組(總是有空白元素的數據稱為稀疏數組)。一般認為,散列表中的單元通常叫作表元(bucket)。在dict的散列表當中,每個鍵值對都占用一個表元,每個表元都有兩部分,一個是對鍵的引用,另一個是對值的引用。因為所有表元的大小一致,所有可以通過偏移量來讀取某個表元。
因為python會設法保證大概還有三分之一的表元是空的,所以在快要達到這個閥值的時候,原有的散列值會被復制到一個更大的空間里面。
如果要把一個對象放入散列表,那么首先要計算這個元素鍵的散列值。python中可以用hash()方法來做這件事情。
1.散列值和相等性
內置的hash()方法可以用于所有的內置類型對象。如果是自定義對象調用hash()的話,實際上運行的是自定義的__hash__.如果兩個對象在比較的時候是相等的,那么它們的散列值必須相等,否則就不能正常運行了。
2.散列表算法
獲取值:
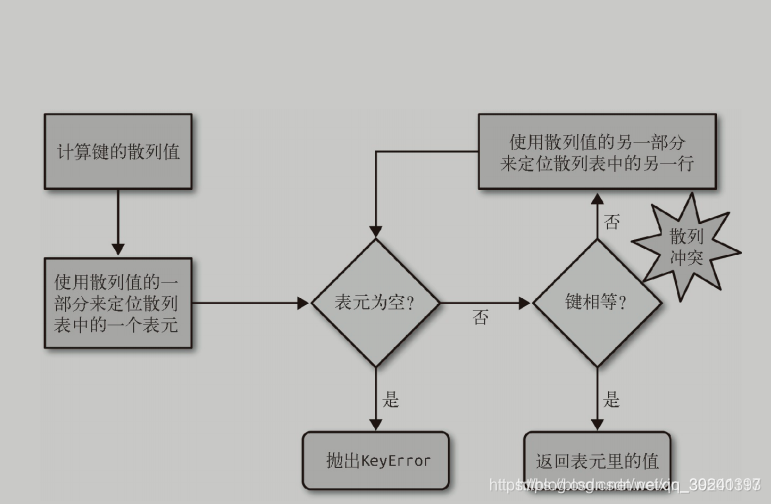
為了獲取my_dict[search_key]背后的值,python首先會調用hash(search_key)來計算search_key的散列值,把這個值最低的幾位數字當做偏移量,在散列表里查找表元(具體取幾位,得看當前散列值的大小)。若找到的表元是空的,則拋出KeyError異常。若不是空的,則表元里會有found_key:found_value。這時候python會檢驗search_key == found_key是否為真,如果它們相等的話,就會返回found_value.
如果search_key和found_key不匹配的話,就稱為散列沖突。發生這種情況是因為,散列表所做的其實是把隨機的元素映射到只有幾位的數字上,而散列表本身的索引又只依賴這個數字的一部分。為了解決散列沖入,算法會在散列值中另外取幾位,然后用特殊方法處理一下,把新得到的數字再當作索引來尋找表元。這次找到若表元若是空的,則同樣會拋出KeyError。若非空,或者鍵匹配,則返回這個值;或者又發現散列沖突,則重復以上步驟。如下圖:
添加新的元素
在發現空表元的時候會放入一個新的元素
更新現有的鍵值
在找到相應的表元,原表中的值對象會被替換成新值
另外在插入新值時候,python可能會按照散列表的擁擠程度來決定是否要重新分配內存為它擴容。如果增加了散列表的大小,那散列值所占的位數和用作索引的位數都會隨之增加,這樣做是為了減少發生散列沖突的概率。
3.9.3 dict的實現及其導致的結果
1.鍵必須是可散列的
一個散列的對象必須包含下面要求:
- (1)支持hash()函數,并且通過__hash__()所得到的散列值是不可變的
- (2)支持通過__eq__()方法來檢測相等性
- (3)若a == b 為真,則hash(a)== hash(b) 也為真
所有用戶自定義的對象默認都是可散列的,因為它們的散列值由id()值獲取,而且都是不相等的。
如果你實現了一個類的__eq__方法,并且希望它是可散列的,那么它一定要有個恰當的__hash__方法.
2.字典在內存上的開銷巨大
因為字典使用了散列表,而散列表又必須是稀疏的,這導致了它在空間上的效率底下。
在用戶自定義的類型中,__slot__屬性可以改變實例屬性的存儲方式,由dict變成tuple.
在類中定義__slots__屬性的目的是告訴解釋器:“這個類中所有實力屬性都在這兒了”
class Point():__slots__ = ("x", "y")def __init__(self, x, y):self.x = xself.y = ydef __str__(self):return "X={}-Y={}".format(self.x,self.y)
3.鍵查詢很快
dict是典型的空間換時間:字典類型有著巨大的內存開銷,但是它們提供了無視數據大小的快速訪問—只要字典被裝在內存里。
4.鍵的次序取決于添加順序
當往dict里添加新建而又發生散列沖突的時候,新鍵可能會被安排到另一個位置。
DIAL_CODES本身按照人口排序的,國家人口前10的國家
>>> DIAL_CODES=[
... (86,'China'),
... (91,'India'),
... (1,'United States'),
... (62,'Indonesia'),
... (55,'Brazil'),
... (92,'Pakistan'),
... (880,'Bangladesh'),
... (234,'Nigeria'),
... (7,'Russia'),
... (81,'Japan'),]
>>> d1= dict(DIAL_CODES)
>>> d1.keys()
dict_keys([86, 91, 1, 62, 55, 92, 880, 234, 7, 81])
>>> d2 = dict(sorted(DIAL_CODES)) # 按照國家的電話區號排序
>>> d2.keys()
dict_keys([1, 7, 55, 62, 81, 86, 91, 92, 234, 880])
>>> d3 = dict(sorted(DIAL_CODES, key=lambda x:x[1])) 按照國家英文名拼寫排序
>>> d3.keys()
dict_keys([880, 55, 86, 91, 62, 81, 234, 92, 7, 1])
>>> d1 == d2 and d2 == d3
True
5.往字典里添加新鍵可能會改變已有鍵的順序
無論何時往字典里添加新的鍵,python解釋器都可能做出為字典擴容的決定。擴容導致的結果就是新建一個更大的散列表,并把字典里已經有的元素添加到新表里。這個過程可能呢會發生新的散列沖突,導致新散列表中的鍵的次序變化。要注意的是,上面提到的這些變化是否會發生以及如何發生,都依賴于字典背后的具體實現。
由此可知,不要對字典同時進行迭代和修改。如果想要掃描并修改一個字典,最好分成兩步來進行:首先對字典迭代,以得出需要添加的內容,把這些內容放到一個新的字典里,迭代結束以后,再對原有字典進行更新。
3.9.4 set的實現以及導致的結果
set和frozenset的實現也依賴散列表,但在它們的散列表里存放的只有元素的引用(就像在字典中只有存放鍵而沒有響應的值)
特點總結:
- 結合里的元素必須是散列的
- 結合很消耗內存
- 可以很高效的判斷元素是否存在與某個集合
- 元素的次序取決于被添加到集合里的次序
- 往集合里面添加元素,可能會改變集合里已有元素的次序。









)
)



)


![python[進階] 6.使用一等函數實現設計模式](http://pic.xiahunao.cn/python[進階] 6.使用一等函數實現設計模式)

