以上討論的單鏈表的結點中只有一個指向其后繼結點的指針域next,因此若已知某結點的指針為p,其后繼結點的指針則為p->next ,而找其前驅則只能從該鏈表的頭指針開始,順著各結點的next 域進行,也就是說找后繼的時間性能是O(1),找前驅的時間性能是O(n),如果也希望找前驅的時間性能達到O(1),則只能付出空間的代價:每個結點再加一個指向前驅的指針域,結點的結構為如圖2.18 所示,用這種結點組成的鏈表稱為雙向鏈表。

雙向鏈表結點的定義如下:
1 typedef struct dlnode
2 {
3 datatype data;
4 struct dlnode *prior,*next;
5 }DLNode,*DLinkList; 和單鏈表類似,雙向鏈表通常也是用頭指針標識,也可以帶頭結點和做成循環結構,圖2.19 是帶頭結點的雙向循環鏈表示意圖。顯然通過某結點的指針p 即可以直接得到它的后繼結點的指針p->next,也可以直接得到它的前驅結點的的指針p->prior。這樣在有些操作中需要找前驅時,則無需再用循環。從下面的插入刪除運算中可以看到這一點。

設p 指向雙向循環鏈表中的某一結點,即p 中是該結點的指針,則p->prior->next 表示的是*p 結點之前驅結點的后繼結點的指針,即與p 相等;類似,p->next->prior 表示的是*p 結點之后繼結點的前驅結點的指針,也與p 相等,所以有以下等式:
雙向鏈表中結點的插入:設p 指向雙向鏈表中某結點,s 指向待插入的值為x 的新結點,將*s 插入到*p 的前面,插入時需要更改兩個指針變量。插入操作時,順序很重要,千萬不能寫反了。插入示意圖如圖2.20 所示。
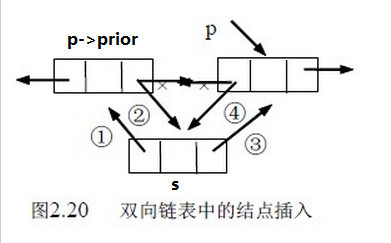
操作如下:
1 s->prior=p->prior; //把p->prior賦值給s的前驅,如圖① 2 p->prior->next=s; //把s賦值給p->prior的后繼,如圖② 3 s->next=p; //把p賦值給s的后繼,如圖③ 4 p->prior=s; //把s賦值給p的前驅,如圖④
指針操作的順序不是唯一的,但也不是任意的,操作①必須要放到操作④的前面完成,否則*p的前驅結點的指針就丟掉了。讀者把每條指針操作的涵義搞清楚,就不難理解了。
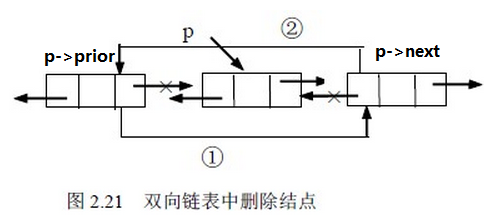
雙向鏈表中結點的刪除:
設p 指向雙向鏈表中某結點,刪除*p。
操作示意圖如圖2.21 所示。操作如下:
1 p->prior->next=p->next; //把p->next賦值給p->prior的后繼,如圖中① 2 p->next->prior=p->prior; //把p->prior賦值給p->next的前驅,如圖中② 3 free(p); //釋放結點




實現對樹的遍歷)



)


的實際應用)







)