 大家好,我是泥腿子安尼特,5個月沒在李佬都公眾號更新文章了。上一篇,大致介紹了作為工具人的我是如何基本使用這一套ELK 系統的。今天就講講這個最重要的E——基于Lucene的搜索引擎ElasticSearch(后面簡稱ES)。最近剛搬家,沒想到隔壁住的都是一對對情侶,半夜三更令人臉紅耳赤的聲音在耳邊聽到就消散不去,然后我就改了路由器名字,提醒一下鄰居,結果當天晚上我的燈就壞了。。。真的不能做惡人。。。雖然自己業務需求也忙,不過這都是借口,自己挖的坑,還是要自己填完。
大家好,我是泥腿子安尼特,5個月沒在李佬都公眾號更新文章了。上一篇,大致介紹了作為工具人的我是如何基本使用這一套ELK 系統的。今天就講講這個最重要的E——基于Lucene的搜索引擎ElasticSearch(后面簡稱ES)。最近剛搬家,沒想到隔壁住的都是一對對情侶,半夜三更令人臉紅耳赤的聲音在耳邊聽到就消散不去,然后我就改了路由器名字,提醒一下鄰居,結果當天晚上我的燈就壞了。。。真的不能做惡人。。。雖然自己業務需求也忙,不過這都是借口,自己挖的坑,還是要自己填完。 廢話不多說,跟隨我的一張充滿靈魂的圖,我們一起開始今天的內容
廢話不多說,跟隨我的一張充滿靈魂的圖,我們一起開始今天的內容
一些基本名詞
名詞 | 解釋 | 備注 |
cluster | 集群,一個ES集群可以由1個或者多個node節點組成 | cluster是由一組包含相同的cluster.name的節點構成。在不修改默認配置的情況下,各個node節點會自動組成一個叫elasticsearch的集群 |
node | 每個集群實例中的一個節點 | 當節點新加入或剔除時,集群會自動均分數據到各個節點上。 |
index | 雖然index翻譯過來是索引的意思,這里是一個指向一個或多個物理shard的邏輯命名空間 | 可以把數據結構基本一致的文檔放在同一個index里 |
type | 類型,低版本的ES可以在一個index里面多個type,目前已在ES7舍棄, 用一個_doc當做每個index的默認type | ES8將完全移除type |
document | ES存儲的數據是文檔型的,一個index里面可以包含多個文檔 文檔以json格式保存 | 我們往ES里PUT一條數據,就相當于生成一個文檔,每個文檔有一個唯一ID(_id) |
field | 字段,每個document由多個字段組成 | |
mapping | 各個字段的數據類型描述 我們在插入一條document的時候如果不指定mapping,ES會自動給我們生成mapping | ES支持的字段類型還是挺多,比如日期類型,數值類型,字符串等等,還支持搞附近的人geohash |
shard | 分片(index里的數據可以分片的形式存在多個shard里,方便橫向擴容),每個index有1個或多個shard,如果你是多節點的集群的話,shard分布在不同的機器上 | shard還分為replica shard(備份分片 可調整)和primary shard(主分片 不可調整) |
replica | 副本,可以備份數據用,多個replica還可以提高查詢的吞吐量 | |
query dsl | ES的復雜查詢語句簡稱 | 就像我們查mysql叫查詢語句叫sql一樣 |
很多ES的教程都會跟你類比index=數據庫 type=表 document=一行數據 field=字段 mapping=字段類型描述。其實這個不完全對,你往index里面put一條數據的時候就生成了一個document,每個文檔有個唯一ID(_id),每個文檔都有一個版本號,每次修改或刪除文檔時,_version就會自增。PUT一個document到一個index后,ES會自動給我們生成mapping,當然,你也可以自定義mapping。默認情況下,每個字段會被analyzed,就是會被自動分詞掉,所以,有時候你存進去的字段里面類似xxx_xx_xxxx的字符串時候,你用xxx_xx_xxxx精準匹配竟然搜不到,就是因為被自動analyzed的原因。
倒排索引&&正排索引
 假如說你去面試,你說用過ES,面試官肯定會問你倒排索引。那什么是倒排索引,是不是聽著很niu bi。我就借著官網上了例子講下:
假如說你去面試,你說用過ES,面試官肯定會問你倒排索引。那什么是倒排索引,是不是聽著很niu bi。我就借著官網上了例子講下:
例如,假設我們有兩個文檔的內容是
The quick brown fox jumped over the lazy dogQuick brown foxes leap over lazy dogs in summerPUT完這兩個之后,ES會按標準模式(大寫轉小寫,單復數按單數,同義詞存一個單詞)生成索引,查詢輸入內容也會被同樣的做標準化處理。
這時候存的索引可以簡化為就像下面這樣:
Term Doc_1 Doc_2-------------------------brown | X | Xdog | X | Xfox | X | Xin | | Xjump | X | Xlazy | X | Xover | X | Xquick | X | Xsummer | | Xthe | X | X------------------------這就把內容分詞后,拿分詞的各個字段對應文檔id,所以也形象的稱之為倒排索引。類比傳統像mysql這樣的數據庫,通常的做法是按id維度建立索引,查詢想要快也是通過id查具體的內容。而ES按分詞來建立與文檔ID的做法,大大的提升全文搜索的速度。?
當然 倒排索引還存了單詞頻率TF(即這個詞在某個文檔中的出現次數),還記錄詞文檔出現的位置信息。所以我們每次查詢的時候,查詢結果都會返回一個_score,默認的查詢結果按分值從高到低返回,詞在文檔中出現次數越多,詞越相似,分值越高,這也符合我們想要的搜索結果。
ES默認的分詞器對于中文內容只會單純的拆分每個中文字,沒法像英文文檔,用默認的就能得到強大的效果,所以需要自行去找合適的中文分詞器。
那我們再簡單來講講正排索引,其實ES對于我們插入的內容,除了會分詞生成倒排索引之外,它也會存每個字段的一些值(doc_value)。假如我們要根據查詢結果按某個字段的的數值進行排序,前面我們講到ES的field是支持很多數據類型的,所謂的正排索引就是單存的存了每個字段的原始值,所以,假如我們要對一個字符串類型的字段做排序,那么我們要手動把它設為not_analyzed,不然字符串類型的field是沒辦法排序的。
基本的增刪改查
ES支持RESTful API 方便讓我們執行很多操作。ES也有批量操作的Bulk API,其實就相當于一次性發送多個語句過去。讓我們在上一篇文章的基礎上,開啟ES、Kibana,然后打開Kibana的DevTools
創建/刪除一個index
PUT?lib3DELETE?lib3/查看index的信息
GET /lib3/_settings
創建index的時候我們還可以手動配置setting設置分片數量,我單機ES默認就一個分片,一個備份
插入/更新一個document
POST?/lib3/_doc/{_id}{"name":"cxk","age":18,"interests":["chang", "tiao", "rap", "lanqiu"]}我們插入文檔的時候可以手動指定文檔id (一般插入的時候都還是不指定id的),當然如果你不指定ES也會自動生成一個,每個文檔插入后也會生成一個自增的_version(插入的時候也可以指定version,默認的version是1到2^63-1 沒修改一次自增1)。ES就是根據_version(版本控制),采用樂觀鎖來保證文檔的更新。如果你指定了文檔id,并且這個文檔存在,那么ES就會覆蓋更新這個文檔。ES的實際上內部的更新策略就是先刪除再插入,所以ES的更新效率并不高。李老之前在搞附近的人項目中提到ES也是支持geohash數據類型的,但是ES這樣的架構,更適合搞附近的店,搞附近的人其實也能搞,就是效率不是很高。
按id精準查詢document
GET /lib1/_doc/{_id}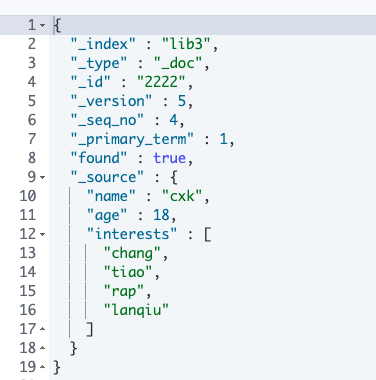
我們可以在查詢的時候指定返回的字段只要在后面加上?_source=字段1,字段2 如果要按某字段(有doc_value)排序,可以在后面加上sort=字段:desc。默認情況下查詢結果是不返回_version的,如果你需要 可以在后面帶上version=true
按field匹配
GET /lib3/_search?q=name:cxk
這時候我們發現查詢結果回來的字段好多,因為基本上我們使用搜索引擎的時候,我們肯定事先是不知道內容到底在哪個document里的,不然還用搜么-,所以基本上是不可能按document id來查的。而基本上我們都要用到復雜查詢,對于一些簡單的需求,我們可以簡單的用一個簡單的語法?q=字段:查詢輸入關鍵詞 再復雜一點,我們就要手擼更復雜的 query dsl語句了。
后話,本篇內容看似很長,其實并沒有講透很多內容,也只是對于ES做了一個簡單的應用介紹。比如ES里面的倒排索引的底層數據結構到底是如何的,還有像ES的_version到底是怎么靠樂觀鎖來更新的,ES的各個node選master的算法,ES里的field支持的數據類型,以及它們怎么存儲的,都沒一一展開深入。不過這不重要,如果你不是專門從事搜索相關業務的技術開發,每個點都去深究,都可以寫好幾篇文章。我可能更多的想給一些業務開發,以及沒用過ES或者想嘗試一下ES的泥腿子們提供一個簡單快速入門的ES的介紹,以及一些基本的使用。下一篇 我將花一整篇介紹query dsl!
話說這次修改路由器ssid名字我發現原來路由器的ssid有個32位長度限制,過了幾天后隔壁的果然消停了好多,順便也改了路由器的名字給我懟回來了
參考資料
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://abcfy2.gitbooks.io/elasticsearch_the_definitive_guide/




)














