常規的分頁方式
API處理分頁看似簡單,實際上暗藏危機。最常見的分頁方式,大概是下面這樣的
/users/?page=1&limit=5
//服務端返回
最理想的情況下,客戶端請求第一頁的5條數據,服務端如常返回,比如下圖:
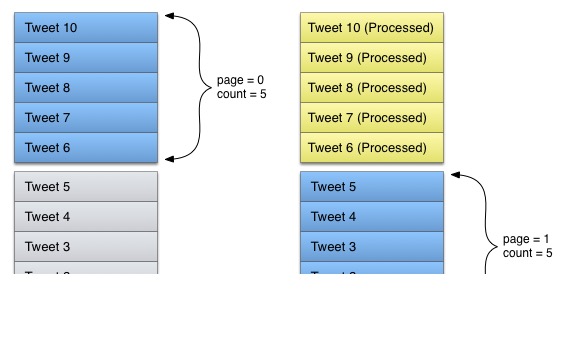
拿Twitter的圖用一下,假設我們的數據庫有10條數據,按照5條一頁,正好有2頁。
在理想情況下,客戶端拉取數據時不會出現任何異常。但,這僅僅是正常情況,如果此時剛好有2條新數據插入。
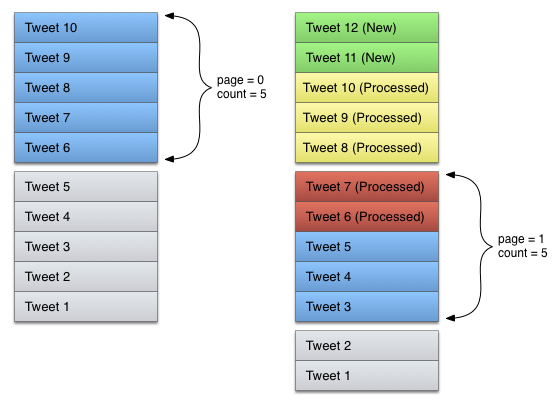
數據庫記錄變為13。原來第二頁的數據是[5, 4, 3, 2, 1],現在變為[7, 6, 5, 4, 3],我們再一次拿到了第一頁的數據。同理,如果用戶在拉取數據時正好有數據被刪除,一樣會出現類似的問題。
根據item_id分頁
要解決此類問題,就不能使用常規的分頁方式。現在,我們換一個思路,客戶端拉取數據時不再傳page,改為item_id,我們就把它稱為max_id
/users/?max_id=5&limit=5
此時服務端就知道我們上次拉取到了item_id為5的數據,繼續在它后面拉取5條, 如下圖:

數據可以正常取回,不會再出現上一頁中的[6,7]。好了,讓我們再一次假設,此時又有8條數據插入了數據庫。再一次獲取數據
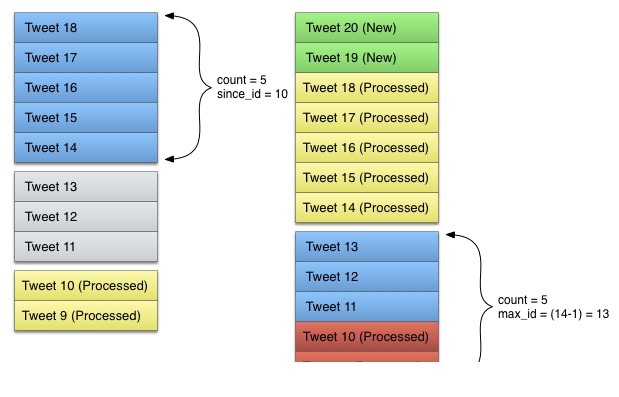
可以看出,再一次出現問題,我們又拿到了上一頁的[10,9]。所以,我們得告訴服務端,上一次拿到哪一條數據了。所以繼續增加一個since_id字段。

恩,再一次取出了正確的數據。可能你覺得一切都正常了,但還是隱藏了一個致命的缺陷。
上面的數據能正常獲取,是因為數據都是一個有序的集合,如果數據無序,且從數據庫取出時需要按照某個字段排序,那么一切再次打回原點:所有的分頁都亂了。
如何設計分頁API
可以看出,兩種分頁方式都存在問題。所以這兩種需求都是必要的,我們需要根據不同的業務場景使用不同的分頁方式。
為了不造成客戶端的麻煩,我們對api的分頁做了一些更改。
{我們由服務端來決定如何分頁,前端需要做的,只是把next字段直接拼接到url中,這樣就可以應付各種分頁情況。
總結
常規的分頁方式不能應付經常變更的數據,sinceid和maxid的方式不能應付有其他排序的數據。大概就是這個樣子,沒有一種萬能的分頁方案,我們只能針對具體的業務場景去設計一個彈性的API來處理復雜的分頁場景。
ps: 最初我們想到的分頁方案,是直接使用item_id作為拉取數據的依據,后來看到Twitter的文章,感覺有更好的分頁方案,又懶得畫圖,所以就直接搬Twitter分頁的部分了。:)
參考鏈接:
Working with Timelines







...)




 虛擬環境的創建,jupyter notebook如何使用虛擬環境)
)

--基于表單庫的儀表板...)


)
