在運維的坑里摸爬滾打好幾年了,我還記得我剛開始的時候,我只會使用一些簡單的命令,寫腳本的時候,也是要多簡單有多簡單,所以有時候寫出來的腳本又長又臭,像一些高級點的命令,比如說Xargs 命令、管道命令、自動應答命令等,如果當初我要是知道,那我也可能寫出簡潔高效的腳本。不管出于任何原因,我都想對一些Linux使用的高級命令進行用法說明,利人利己,以后不記得的話,我也可以回頭翻來看看。

1、實用的xargs命令
在平時的使用中,我認為xargs這個命令還是較為重要和方便的。我們可以通過使用這個命令,將命令輸出的結果作為參數傳遞給另一個命令。比如說我們想找出某個路徑下以.conf結尾的文件,并將這些文件進行分類,那么普通的做法就是先將以.conf結尾的文件先找出來,然后輸出到一個文件中,接著cat這個文件,并使用file文件分類命令去對輸出的文件進行分類。這個普通的方法還的確是略顯麻煩,那么這個時候xargs命令就派上用場了。
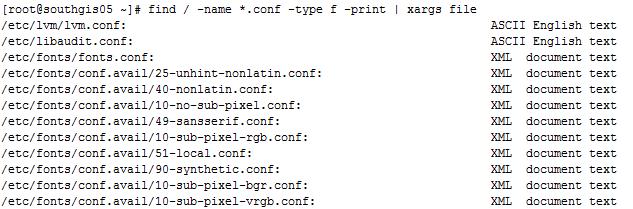
例1:找出 / 目錄下以.conf 結尾的文件,并進行文件分類
命令:# find / -name *.conf -type f -print | xargs file
輸出結果如下所示:
xargs后面不僅僅可以加文件分類的命令,你還可以加其他的很多命令,比如說實在一點的tar命令,你可以使用find命令配合tar命令,將指定路徑的特殊文件使用find命令找出來,然后配合tar命令將找出的文件直接打包,命令如下:
# find / -name *.conf -type f -print | xargs tar cjf test.tar.gz
2、命令或腳本后臺運行
有時候我們進行一些操作的時候,不希望我們的操作在終端會話斷了之后就跟著斷了,特別是一些數據庫導入導出操作,如果涉及到大數據量的操作,我們不可能保證我們的網絡在我們的操作期間不出問題,所以后臺運行腳本或者命令對我們來說是一大保障。
比如說我們想把數據庫的導出操作后臺運行,并且將命令的操作輸出記錄到文件,那么我們可以這么做:
nohup mysqldump -uroot -pxxxxx --all-databases > ./alldatabases.sql &(xxxxx是密碼)
當然如果你不想密碼明文,你還可以這么做:
nohup mysqldump -uroot -p --all-databases > ./alldatabases.sql (后面不加&符號)
執行了上述命令后,會提示叫你輸入密碼,輸入密碼后,該命令還在前臺運行,但是我們的目的是后天運行該命令,這個時候你可以按下Ctrl+Z,然后在輸入bg就可以達到第一個命令的效果,讓該命令后臺運行,同時也可以讓密碼隱蔽輸入。
命令后臺執行的結果會在命令執行的當前目錄下留下一個nohup.out文件,查看這個文件就知道命令有沒有執行報錯等信息。
3、找出當前系統內存使用量較高的進程
在很多運維的時候,我們發現內存耗用較為嚴重,那么怎么樣才能找出內存消耗的進程排序呢?
命令:# ps -aux | sort -rnk 4 | head -20
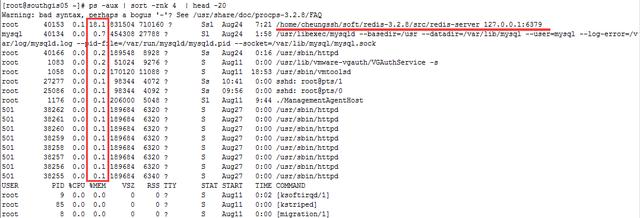
輸出的第4列就是內存的耗用百分比。最后一列就是相對應的進程。
4、找出當前系統CPU使用量較高的進程
在很多運維的時候,我們發現CPU耗用較為嚴重,那么怎么樣才能找出CPU消耗的進程排序呢?
命令:# ps -aux | sort -rnk 3 | head -20
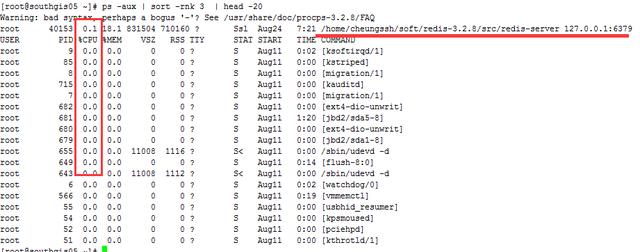
輸出的第3列為CPU的耗用百分比,最后一列就是對應的進程。
我想大家應該也發現了,sort 命令后的3、4其實就是代表著第3列進行排序、第4列進行排序。
5、同時查看多個日志或數據文件
在日常工作中,我們查看日志文件的方式可能是使用tail命令在一個個的終端查看日志文件,一個終端就看一個日志文件。包括我在內也是,但是有時候也會覺得這種方式略顯麻煩,其實有個工具叫做multitail可以在同一個終端同時查看多個日志文件。
首先安裝multitail:
# wget ftp://ftp.is.co.za/mirror/ftp.rpmforge.net/redhat/el6/en/x86_64/dag/RPMS/multitail-5.2.9-1.el6.rf.x86_64.rpm
# yum -y localinstall multitail-5.2.9-1.el6.rf.x86_64.rpm
multitail工具支持文本的高亮顯示,內容過濾以及更多你可能需要的功能。
如下就來一個有用的例子:
此時我們既想查看secure的日志指定過濾關鍵字輸出,又想查看實時的網絡ping情況:
命令如下:
# multitail -e "Accepted" /var/log/secure -l "ping baidu.com"
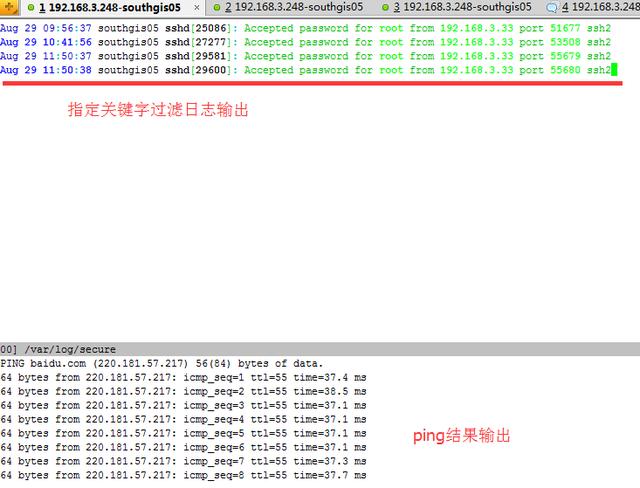
是不是很方便?如果平時我們想查看兩個日志之間的關聯性,可以觀察日志輸出是否有觸發等。如果分開兩個終端可能來回進行切換有點浪費時間,這個multitail工具查看未嘗不是一個好方法。
6、持續ping并將結果記錄到日志
很多時候,運維總會聽到一個聲音,是不是網絡出什么問題了啊,導致業務出現怪異的癥狀,肯定是服務器網絡出問題了。這個就是俗稱的背鍋,業務出了問題,第一時間相關人員找不到原因很多情況下就會把問題歸結于服務器網絡有問題。這個時候你去ping幾個包把結果丟出來,人家會反駁你,剛剛那段時間有問題而已,現在業務都恢復正常了,網絡肯定正常啊,這個時候估計你要氣死。你要是再拿出zabbix等網絡監控的數據,這個時候就不太妥當了,zabbix的采集數據間隔你不可能設置成1秒鐘1次吧?小編就遇到過這樣的問題,結果我通過以下的命令進行了ping監控采集。然后再有人讓我背鍋的時候,我把出問題時間段的ping數據庫截取出來,大家公開談,結果那次被我叼杠回去了,以后他們都不敢輕易甩鍋了,這個感覺好啊。
命令:
ping api.jpush.cn | awk '{ print $0"" strftime("%Y-%m-%d %H:%M:%S





訪問https站點)







和導出(Export))





