轉載請注明出處,謝謝
2017-10-22 17:14:09
之前都是用python開發maprduce程序的,今天試了在windows下通過eclipse java開發,在開發前先搭建開發環境。在此,總結這個過程,希望能夠幫助有需要的朋友。
用Hadoop eclipse plugin,可以瀏覽管理HDFS,自動創建MR程序的模板文件,最爽的就是可以直接Run on hadoop。
1、安裝插件
下載hadoop-eclipse-plugin-1.2.1.jar,并把它放到?F:\eclipse\plugins 目錄下。
2、插件配置與使用
2.1指定hadoop的源碼目錄

2.2、打開Map/Reduce視圖
”Window”->”Open Perspective”->”Other”->“Map/Reduce”.
“Window”->”Show views”->”Other”->”Map Reduce Tools”->”Map/Reduce locations”.
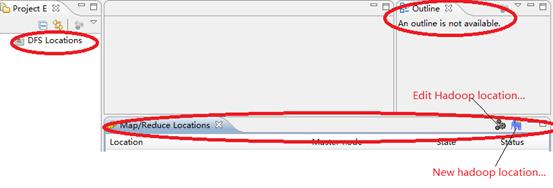
?
正常情況下回出現左上角的HDFS標志,等eclipse與hadoop集群連接后,會在這顯示HDFS目錄結構。
2.3、新建Map/Reduce Localtion

點擊圖中紅色框或者鼠標右擊選中新建,然后出現下面的界面,配置hadoop集群的信息。

這里需要注意的是hadoop集群信息的填寫。因為我是在windows下用eclipse遠程連接hadoop集群【完全分布式】開發的,所以這里填寫的host是master的IP地址。如果是hadoop偽分布式的可以填寫localhost。
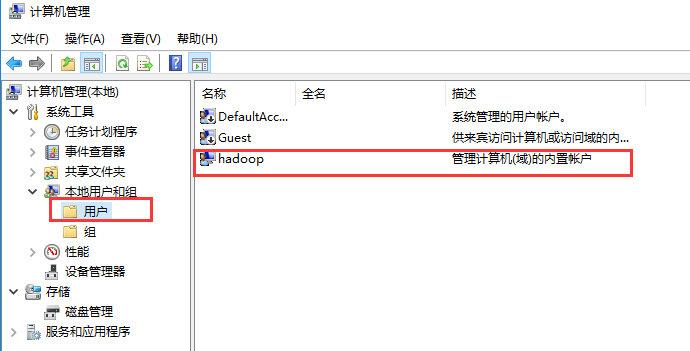
【Jser name】填寫的windows電腦的用戶名,右擊【我的電腦】-->【管理】-->【本地用戶和組】-->【修改用戶名字】
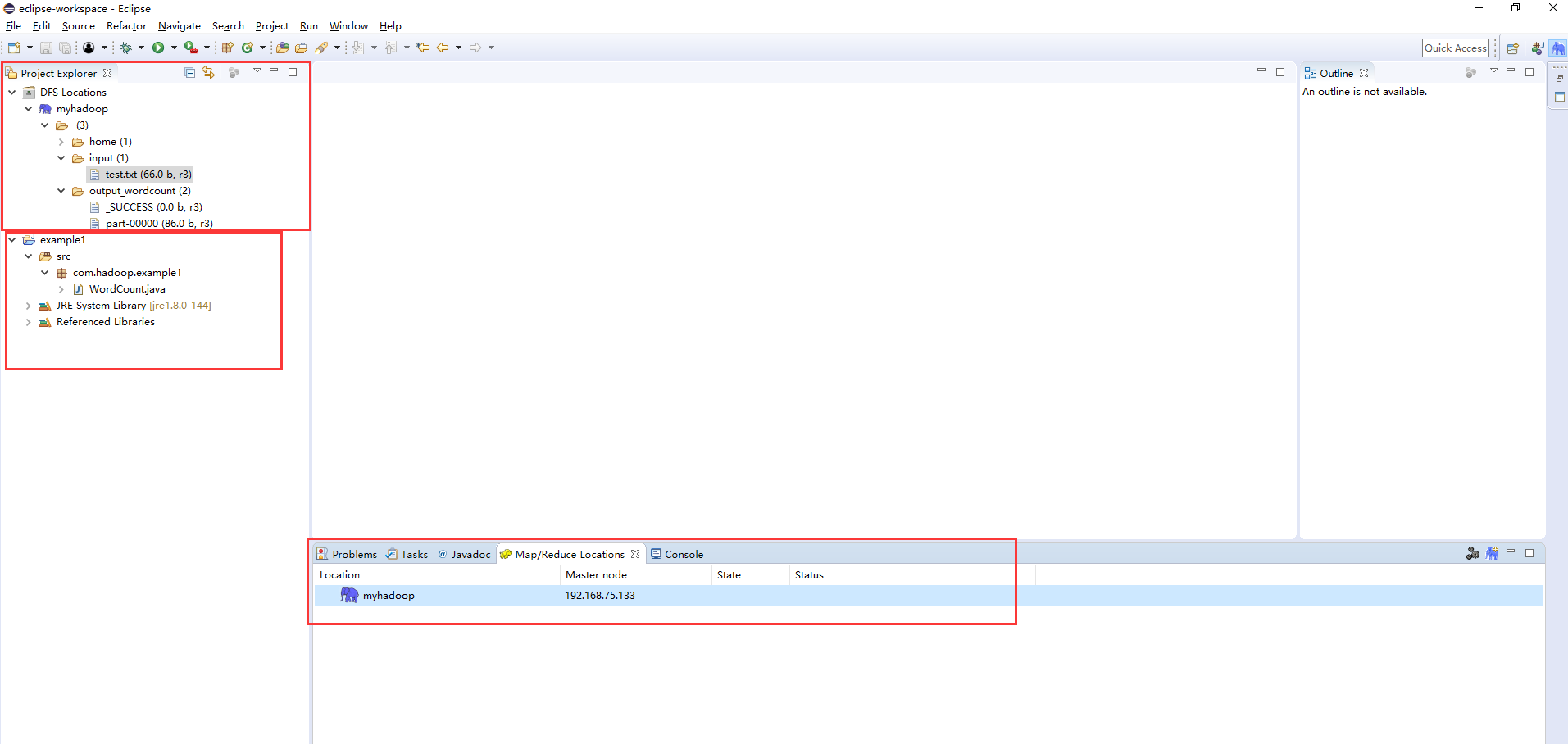
完成前面的步驟后,正常的eclipse界面應該像下圖那樣的。注意example1工程是我自己新建的,主要是用來驗證eclipse能否遠程連接hadoop集群來開發mapreduce程序。并且,此時在eclipse的HDFS視圖界面對HDFS的操作(增刪查)和在命令行上對HDFS操作的結果是一樣的。
3、開發mapreduce程序
3.1、新建mapreduce工程

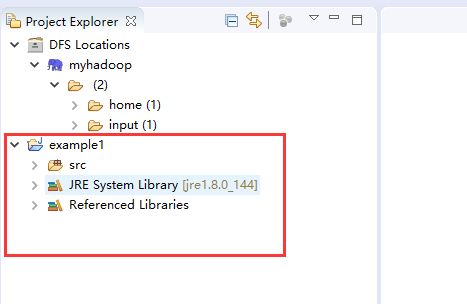
使用插件開發的好處這時顯示出來了,完成這一個步驟,在工程視圖會出現一個mapreduce工程模板,不用我們自己導入hadoop的jar包。下圖紅框就是新建mapreduce工程后生成的空模板,我們需要做的是在src文件夾中新建包和開發java程序。
3.3、在遠程終端中通過命令行方式上傳文件hadoop fs -put test.txt /input/? 或者 通過eclipse 的HDFS視圖上傳input文件: /input/test.txt,內容如下:
liang ni hao ma
wo hen hao
ha
qwe
asasa
xcxc vbv xxxx aaa eee 3.2、WordCount.java程序
package com.hadoop.example1; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobClient; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.TextOutputFormat; public class WordCount {public static class Map extends MapReduceBase implementsMapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value,OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException {String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());output.collect(word, one);}}}public static class Reduce extends MapReduceBase implementsReducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterator<IntWritable> values,OutputCollector<Text, IntWritable> output, Reporter reporter)throws IOException {int sum = 0;while (values.hasNext()) {sum += values.next().get();}output.collect(key, new IntWritable(sum));}}public static void main(String[] args) throws Exception {JobConf conf = new JobConf(WordCount.class);conf.setJobName("wordcount");conf.setOutputKeyClass(Text.class);conf.setOutputValueClass(IntWritable.class);conf.setMapperClass(Map.class);conf.setCombinerClass(Reduce.class);conf.setReducerClass(Reduce.class);conf.setInputFormat(TextInputFormat.class);conf.setOutputFormat(TextOutputFormat.class);FileInputFormat.setInputPaths(conf, new Path(args[0]));FileOutputFormat.setOutputPath(conf, new Path(args[1]));JobClient.runJob(conf);} }
?
3.3、運行examplse1工程
注意的這種開發方式運行采用的是:run on haoop
運行方法:【右擊工程】-->【Run as】-->【run on hadoop】 。在這里如果跳出一個界面讓你選擇,證明現在工程選用的Java Applicaltion不對。這時可以這樣做:【右擊工程】-->【Run as】-->【run on configrations】。并填寫傳的參數是輸入文件路徑和輸出目錄路徑。


在Linux eclipse上開發,以上步驟都成功的話程序會正常運行。但是在windows eclipse 下開發會以下錯誤。因為在hadoop源碼中會檢查windows文件權限,因此,我們要修改hadoop源碼。
14/05/29 13:49:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/05/29 13:49:16 ERROR security.UserGroupInformation: PriviledgedActionException as:ISCAS cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-ISCAS\mapred\staging\ISCAS1655603947\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-ISCAS\mapred\staging\ISCAS1655603947\.staging to 0700 at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:691) at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:664) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:514) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:349) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:193) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936) at org.apache.hadoop.mapreduce.Job.submit(Job.java:550) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:580) at org.apache.hadoop.examples.WordCount.main(WordCount.java:82)
3.4、修改hadoop源碼以支持windows下eclipse開發mapreduce程序。
出現問題的代碼位于 【hadoop-1.2.1\src\core\org\apache\hadoop\fs\FileUtil.java】。
修改方式如下,注釋掉對文件權限的判斷。
private static void checkReturnValue(boolean rv, File p, FsPermission permission) throws IOException {/*** comment the following, disable this functionif (!rv){throw new IOException("Failed to set permissions of path: " + p +" to " +String.format("%04o", permission.toShort()));}*/ }
然后將修改好的文件重新編譯,并將.class文件打包到hadoop-core-1.2.1.jar中,并重新刷新工程。這里,為了方便大家,我提供已經修改后的jar文件包,如果需要可以點擊下載,并替換掉原有的hadoop-1.2.1中的jar包,位于hadoop-1.2.1根目錄。
再次3,3步驟的操作,這時運行成功了。
3.5查看結果
在HDFS視圖刷新后,可以看到生成output_wordcount文件夾,進入此目錄可以看見生成的part-00000,其結果為:

?







![BZOJ 1692: [Usaco2007 Dec]隊列變換( 貪心 )](http://pic.xiahunao.cn/BZOJ 1692: [Usaco2007 Dec]隊列變換( 貪心 ))

——工具函數包說明(二))

![[LINK]用Python計算昨天、今天和明天的日期時間](http://pic.xiahunao.cn/[LINK]用Python計算昨天、今天和明天的日期時間)



![[譯] RNN 循環神經網絡系列 2:文本分類](http://pic.xiahunao.cn/[譯] RNN 循環神經網絡系列 2:文本分類)
![[置頂] Android開發者官方網站文檔 - 國內踏得網鏡像](http://pic.xiahunao.cn/[置頂] Android開發者官方網站文檔 - 國內踏得網鏡像)


