一、概念
池化就是把數據壓縮的過程,屬于下采樣的一種方法,可以顯著降低神經網絡計算復雜度,減少訓練中的過擬合,同時可以使數據具有一定的不變性。
池化從方法上來講可以分為average Pooling、max Pooling、Overlapping Pooling、Spatial Pyramid Pooling,其中max Pooling是最常見的池化方法,Overlapping Pooling值得注意的是filter的size小于stride,Spatial Pyramid Pooling(空間金字塔池化)可以將不同維度的卷積特征轉化到同一個維度,可以減少一些由于croping引起的數據損失。
下圖是用最大池化的方法對4 * 4的矩陣進行處理,filter為2 * 2,stride等于2,最終得到2*2的矩陣,矩陣中的值為遍歷矩陣的最大值。

二、Pytorch示例
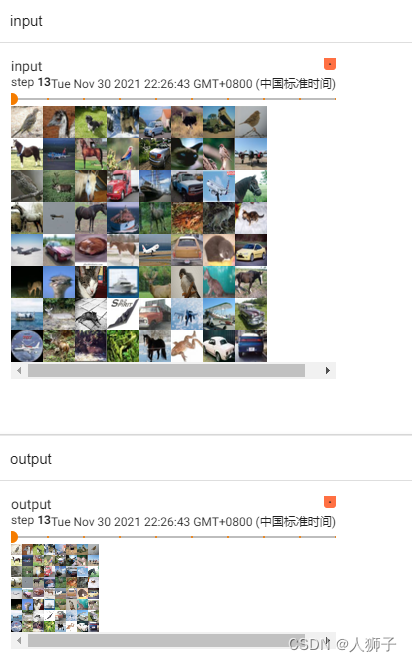
還是用CIFAR10數據集,池化方法采用最大池化,filter為3*3。
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, download=True, transform=torchvision.transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=64)class Wzh(nn.Module):def __init__(self):super(Wzh, self).__init__()self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, input):output = self.maxpool1(input)return outputwzh = Wzh()
w= SummaryWriter("MaxPool")
i = 0for data in dataloader:imgs, targets = data output1 = wzh(imgs)w.add_images("input", imgs, i)w.add_images("output", output1, i)i= i+ 1w.close()
結果如下:


)
——激活函數)

![【NOIP 模擬題】[T1] 等差數列(dp)](http://pic.xiahunao.cn/【NOIP 模擬題】[T1] 等差數列(dp))
)
——線性層(全連接層))
)


剖析:吐槽)
——正則化)


區域并且保存(含鼠標事件))


——損失函數)
