MySQL/InnoDB的加鎖分析,一直是一個比較困難的話題。我在工作過程中,經常會有同事咨詢這方面的問題。同時,微博上也經常會收到MySQL鎖相關的私信,讓我幫助解決一些死鎖的問題。本文,準備就MySQL/InnoDB的加鎖問題,展開較為深入的分析與討論,主要是介紹一種思路,運用此思路,拿到任何一條SQL語句,都能完整的分析出這條語句會加什么鎖?會有什么樣的使用風險?甚至是分析線上的一個死鎖場景,了解死鎖產生的原因。
?
注:MySQL是一個支持插件式存儲引擎的數據庫系統。本文下面的所有介紹,都是基于InnoDB存儲引擎,其他引擎的表現,會有較大的區別。
?
-
MVCC:Snapshot Read vs Current Read
?
MySQL InnoDB存儲引擎,實現的是基于多版本的并發控制協議——MVCC (Multi-Version Concurrency Control) (注:與MVCC相對的,是基于鎖的并發控制,Lock-Based Concurrency Control)。MVCC最大的好處,相信也是耳熟能詳:讀不加鎖,讀寫不沖突。在讀多寫少的OLTP應用中,讀寫不沖突是非常重要的,極大的增加了系統的并發性能,這也是為什么現階段,幾乎所有的RDBMS,都支持了MVCC。
?
在MVCC并發控制中,讀操作可以分成兩類:快照讀 (snapshot read)與當前讀 (current read)。快照讀,讀取的是記錄的可見版本 (有可能是歷史版本),不用加鎖。當前讀,讀取的是記錄的最新版本,并且,當前讀返回的記錄,都會加上鎖,保證其他事務不會再并發修改這條記錄。
?
在一個支持MVCC并發控制的系統中,哪些讀操作是快照讀?哪些操作又是當前讀呢?以MySQL InnoDB為例:
?
- 快照讀:簡單的select操作,屬于快照讀,不加鎖。(當然,也有例外,下面會分析)
- select * from table where ?;
?
-
- 當前讀:特殊的讀操作,插入/更新/刪除操作,屬于當前讀,需要加鎖。
- select * from table where ? lock in share mode;
- select * from table where ? for update;
- insert into table values (…);
- update table set ? where ?;
- delete from table where ?;
所有以上的語句,都屬于當前讀,讀取記錄的最新版本。并且,讀取之后,還需要保證其他并發事務不能修改當前記錄,對讀取記錄加鎖。其中,除了第一條語句,對讀取記錄加S鎖 (共享鎖)外,其他的操作,都加的是X鎖 (排它鎖)。
?
-
為什么將 插入/更新/刪除 操作,都歸為當前讀?可以看看下面這個 更新 操作,在數據庫中的執行流程:
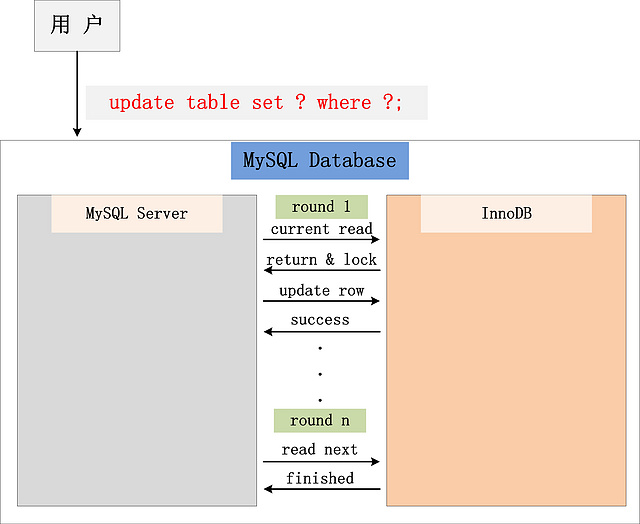
?
從圖中,可以看到,一個Update操作的具體流程。當Update SQL被發給MySQL后,MySQL Server會根據where條件,讀取第一條滿足條件的記錄,然后InnoDB引擎會將第一條記錄返回,并加鎖 (current read)。待MySQL Server收到這條加鎖的記錄之后,會再發起一個Update請求,更新這條記錄。一條記錄操作完成,再讀取下一條記錄,直至沒有滿足條件的記錄為止。因此,Update操作內部,就包含了一個當前讀。同理,Delete操作也一樣。Insert操作會稍微有些不同,簡單來說,就是Insert操作可能會觸發Unique Key的沖突檢查,也會進行一個當前讀。
?
注:根據上圖的交互,針對一條當前讀的SQL語句,InnoDB與MySQL Server的交互,是一條一條進行的,因此,加鎖也是一條一條進行的。先對一條滿足條件的記錄加鎖,返回給MySQL Server,做一些DML操作;然后在讀取下一條加鎖,直至讀取完畢。
?
-
Cluster Index:聚簇索引
?
InnoDB存儲引擎的數據組織方式,是聚簇索引表:完整的記錄,存儲在主鍵索引中,通過主鍵索引,就可以獲取記錄所有的列。關于聚簇索引表的組織方式,可以參考MySQL的官方文檔:Clustered and Secondary Indexes?。本文假設讀者對這個,已經有了一定的認識,就不再做具體的介紹。接下來的部分,主鍵索引/聚簇索引 兩個名稱,會有一些混用,望讀者知曉。
?
-
2PL:Two-Phase Locking
?
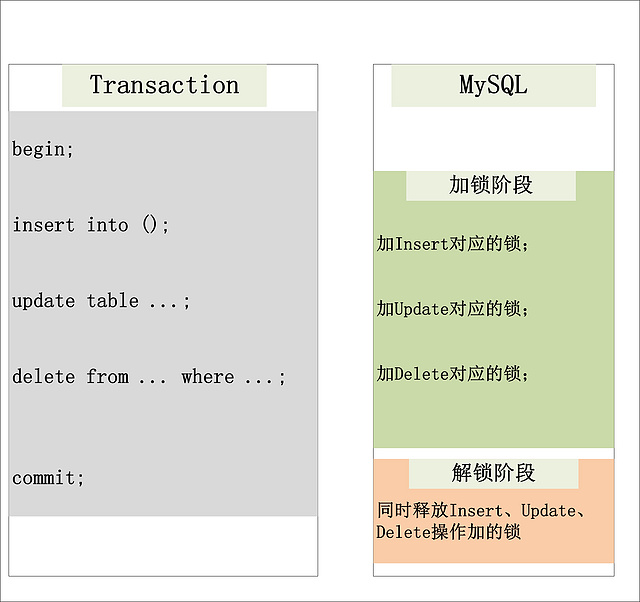
傳統RDBMS加鎖的一個原則,就是2PL (二階段鎖):Two-Phase Locking。相對而言,2PL比較容易理解,說的是鎖操作分為兩個階段:加鎖階段與解鎖階段,并且保證加鎖階段與解鎖階段不相交。下面,仍舊以MySQL為例,來簡單看看2PL在MySQL中的實現。
?
?
?
從上圖可以看出,2PL就是將加鎖/解鎖分為兩個完全不相交的階段。加鎖階段:只加鎖,不放鎖。解鎖階段:只放鎖,不加鎖。
?
-
Isolation Level
?
隔離級別:Isolation Level,也是RDBMS的一個關鍵特性。相信對數據庫有所了解的朋友,對于4種隔離級別:Read Uncommited,Read Committed,Repeatable Read,Serializable,都有了深入的認識。本文不打算討論數據庫理論中,是如何定義這4種隔離級別的含義的,而是跟大家介紹一下MySQL/InnoDB是如何定義這4種隔離級別的。
?
MySQL/InnoDB定義的4種隔離級別:
- Read Uncommited
可以讀取未提交記錄。此隔離級別,不會使用,忽略。
- Read Committed (RC)
快照讀忽略,本文不考慮。
針對當前讀,RC隔離級別保證對讀取到的記錄加鎖 (記錄鎖),存在幻讀現象。
- Repeatable Read (RR)
快照讀忽略,本文不考慮。
針對當前讀,RR隔離級別保證對讀取到的記錄加鎖 (記錄鎖),同時保證對讀取的范圍加鎖,新的滿足查詢條件的記錄不能夠插入 (間隙鎖),不存在幻讀現象。
- Serializable
從MVCC并發控制退化為基于鎖的并發控制。不區別快照讀與當前讀,所有的讀操作均為當前讀,讀加讀鎖 (S鎖),寫加寫鎖 (X鎖)。
Serializable隔離級別下,讀寫沖突,因此并發度急劇下降,在MySQL/InnoDB下不建議使用。
?
-
一條簡單SQL的加鎖實現分析
?
在介紹完一些背景知識之后,本文接下來將選擇幾個有代表性的例子,來詳細分析MySQL的加鎖處理。當然,還是從最簡單的例子說起。經常有朋友發給我一個SQL,然后問我,這個SQL加什么鎖?就如同下面兩條簡單的SQL,他們加什么鎖?
?
- SQL1:select * from t1 where id = 10;
- SQL2:delete from t1 where id = 10;
?
針對這個問題,該怎么回答?我能想象到的一個答案是:
?
- SQL1:不加鎖。因為MySQL是使用多版本并發控制的,讀不加鎖。
- SQL2:對id = 10的記錄加寫鎖 (走主鍵索引)。
?
這個答案對嗎?說不上來。即可能是正確的,也有可能是錯誤的,已知條件不足,這個問題沒有答案。如果讓我來回答這個問題,我必須還要知道以下的一些前提,前提不同,我能給出的答案也就不同。要回答這個問題,還缺少哪些前提條件?
?
- 前提一:id列是不是主鍵?
?
- 前提二:當前系統的隔離級別是什么?
- 前提三:id列如果不是主鍵,那么id列上有索引嗎?
- 前提四:id列上如果有二級索引,那么這個索引是唯一索引嗎?
- 前提五:兩個SQL的執行計劃是什么?索引掃描?全表掃描?
?
沒有這些前提,直接就給定一條SQL,然后問這個SQL會加什么鎖,都是很業余的表現。而當這些問題有了明確的答案之后,給定的SQL會加什么鎖,也就一目了然。下面,我將這些問題的答案進行組合,然后按照從易到難的順序,逐個分析每種組合下,對應的SQL會加哪些鎖?
?
注:下面的這些組合,我做了一個前提假設,也就是有索引時,執行計劃一定會選擇使用索引進行過濾 (索引掃描)。但實際情況會復雜很多,真正的執行計劃,還是需要根據MySQL輸出的為準。
?
- 組合一:id列是主鍵,RC隔離級別
- 組合二:id列是二級唯一索引,RC隔離級別
- 組合三:id列是二級非唯一索引,RC隔離級別
- 組合四:id列上沒有索引,RC隔離級別
- 組合五:id列是主鍵,RR隔離級別
- 組合六:id列是二級唯一索引,RR隔離級別
- 組合七:id列是二級非唯一索引,RR隔離級別
- 組合八:id列上沒有索引,RR隔離級別
- 組合九:Serializable隔離級別
?
排列組合還沒有列舉完全,但是看起來,已經很多了。真的有必要這么復雜嗎?事實上,要分析加鎖,就是需要這么復雜。但是從另一個角度來說,只要你選定了一種組合,SQL需要加哪些鎖,其實也就確定了。接下來,就讓我們來逐個分析這9種組合下的SQL加鎖策略。
?
注:在前面八種組合下,也就是RC,RR隔離級別下,SQL1:select操作均不加鎖,采用的是快照讀,因此在下面的討論中就忽略了,主要討論SQL2:delete操作的加鎖。
?
-
組合一:id主鍵+RC
?
這個組合,是最簡單,最容易分析的組合。id是主鍵,Read Committed隔離級別,給定SQL:delete from t1 where id = 10; 只需要將主鍵上,id = 10的記錄加上X鎖即可。如下圖所示:
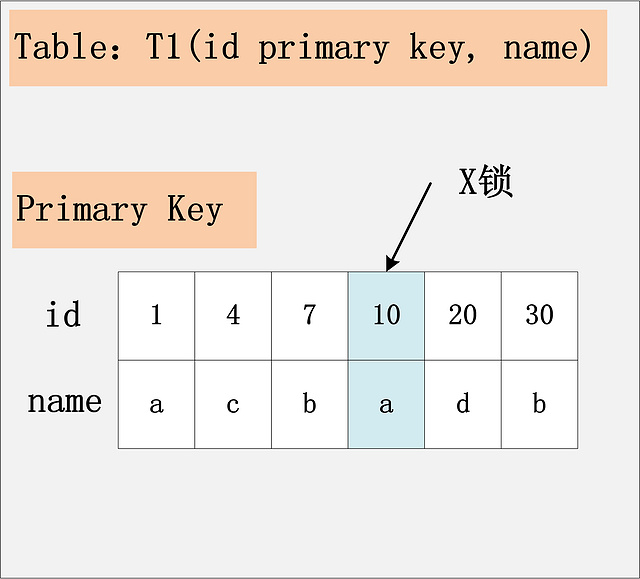
?
結論:id是主鍵時,此SQL只需要在id=10這條記錄上加X鎖即可。
?
-
組合二:id唯一索引+RC
?
這個組合,id不是主鍵,而是一個Unique的二級索引鍵值。那么在RC隔離級別下,delete from t1 where id = 10; 需要加什么鎖呢?見下圖:
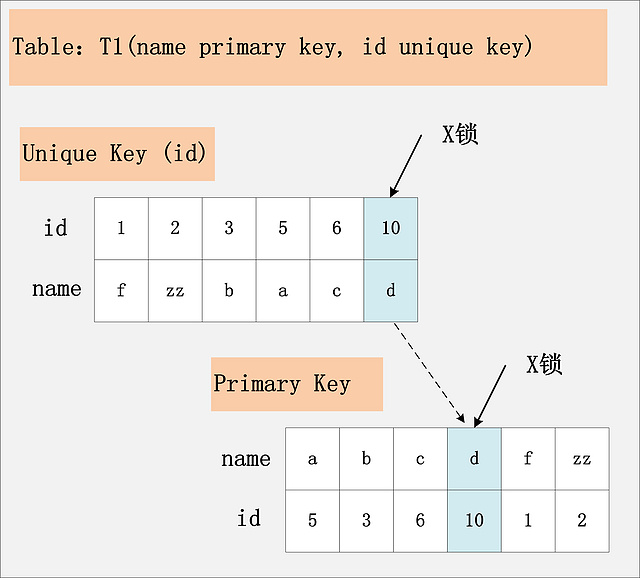
?
此組合中,id是unique索引,而主鍵是name列。此時,加鎖的情況由于組合一有所不同。由于id是unique索引,因此delete語句會選擇走id列的索引進行where條件的過濾,在找到id=10的記錄后,首先會將unique索引上的id=10索引記錄加上X鎖,同時,會根據讀取到的name列,回主鍵索引(聚簇索引),然后將聚簇索引上的name = ‘d’ 對應的主鍵索引項加X鎖。為什么聚簇索引上的記錄也要加鎖?試想一下,如果并發的一個SQL,是通過主鍵索引來更新:update t1 set id = 100 where name = ‘d’; 此時,如果delete語句沒有將主鍵索引上的記錄加鎖,那么并發的update就會感知不到delete語句的存在,違背了同一記錄上的更新/刪除需要串行執行的約束。
?
結論:若id列是unique列,其上有unique索引。那么SQL需要加兩個X鎖,一個對應于id unique索引上的id = 10的記錄,另一把鎖對應于聚簇索引上的[name='d',id=10]的記錄。
?
-
組合三:id非唯一索引+RC
?
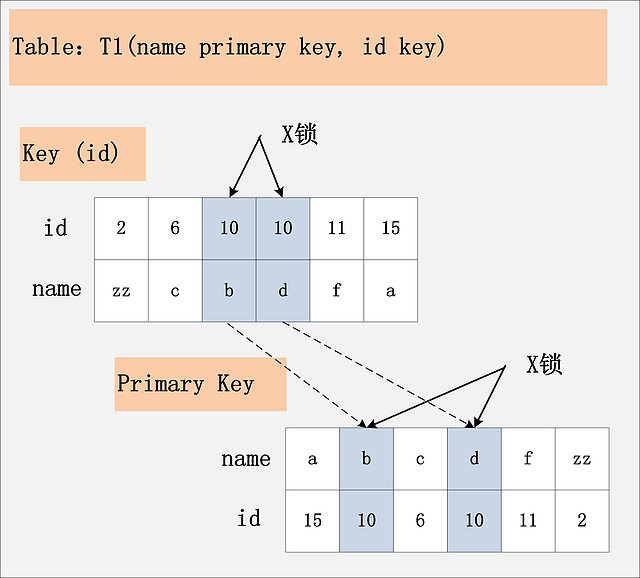
相對于組合一、二,組合三又發生了變化,隔離級別仍舊是RC不變,但是id列上的約束又降低了,id列不再唯一,只有一個普通的索引。假設delete from t1 where id = 10; 語句,仍舊選擇id列上的索引進行過濾where條件,那么此時會持有哪些鎖?同樣見下圖:
?
?
根據此圖,可以看到,首先,id列索引上,滿足id = 10查詢條件的記錄,均已加鎖。同時,這些記錄對應的主鍵索引上的記錄也都加上了鎖。與組合二唯一的區別在于,組合二最多只有一個滿足等值查詢的記錄,而組合三會將所有滿足查詢條件的記錄都加鎖。
?
結論:若id列上有非唯一索引,那么對應的所有滿足SQL查詢條件的記錄,都會被加鎖。同時,這些記錄在主鍵索引上的記錄,也會被加鎖。
?
-
組合四:id無索引+RC
?
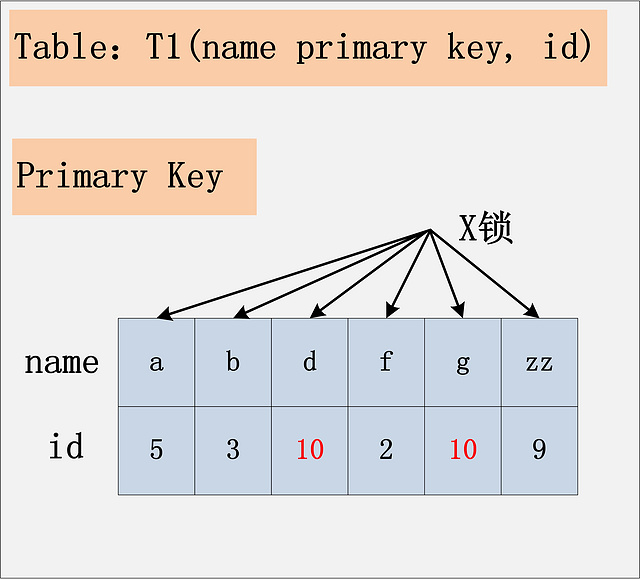
相對于前面三個組合,這是一個比較特殊的情況。id列上沒有索引,where id = 10;這個過濾條件,沒法通過索引進行過濾,那么只能走全表掃描做過濾。對應于這個組合,SQL會加什么鎖?或者是換句話說,全表掃描時,會加什么鎖?這個答案也有很多:有人說會在表上加X鎖;有人說會將聚簇索引上,選擇出來的id = 10;的記錄加上X鎖。那么實際情況呢?請看下圖:
?
由于id列上沒有索引,因此只能走聚簇索引,進行全部掃描。從圖中可以看到,滿足刪除條件的記錄有兩條,但是,聚簇索引上所有的記錄,都被加上了X鎖。無論記錄是否滿足條件,全部被加上X鎖。既不是加表鎖,也不是在滿足條件的記錄上加行鎖。
?
有人可能會問?為什么不是只在滿足條件的記錄上加鎖呢?這是由于MySQL的實現決定的。如果一個條件無法通過索引快速過濾,那么存儲引擎層面就會將所有記錄加鎖后返回,然后由MySQL Server層進行過濾。因此也就把所有的記錄,都鎖上了。
?
注:在實際的實現中,MySQL有一些改進,在MySQL Server過濾條件,發現不滿足后,會調用unlock_row方法,把不滿足條件的記錄放鎖 (違背了2PL的約束)。這樣做,保證了最后只會持有滿足條件記錄上的鎖,但是每條記錄的加鎖操作還是不能省略的。
?
結論:若id列上沒有索引,SQL會走聚簇索引的全掃描進行過濾,由于過濾是由MySQL Server層面進行的。因此每條記錄,無論是否滿足條件,都會被加上X鎖。但是,為了效率考量,MySQL做了優化,對于不滿足條件的記錄,會在判斷后放鎖,最終持有的,是滿足條件的記錄上的鎖,但是不滿足條件的記錄上的加鎖/放鎖動作不會省略。同時,優化也違背了2PL的約束。
?
-
組合五:id主鍵+RR
?
上面的四個組合,都是在Read Committed隔離級別下的加鎖行為,接下來的四個組合,是在Repeatable Read隔離級別下的加鎖行為。
?
組合五,id列是主鍵列,Repeatable Read隔離級別,針對delete from t1 where id = 10; 這條SQL,加鎖與組合一:[id主鍵,Read Committed]一致。
?
-
組合六:id唯一索引+RR
?
與組合五類似,組合六的加鎖,與組合二:[id唯一索引,Read Committed]一致。兩個X鎖,id唯一索引滿足條件的記錄上一個,對應的聚簇索引上的記錄一個。
?
-
組合七:id非唯一索引+RR
?
還記得前面提到的MySQL的四種隔離級別的區別嗎?RC隔離級別允許幻讀,而RR隔離級別,不允許存在幻讀。但是在組合五、組合六中,加鎖行為又是與RC下的加鎖行為完全一致。那么RR隔離級別下,如何防止幻讀呢?問題的答案,就在組合七中揭曉。
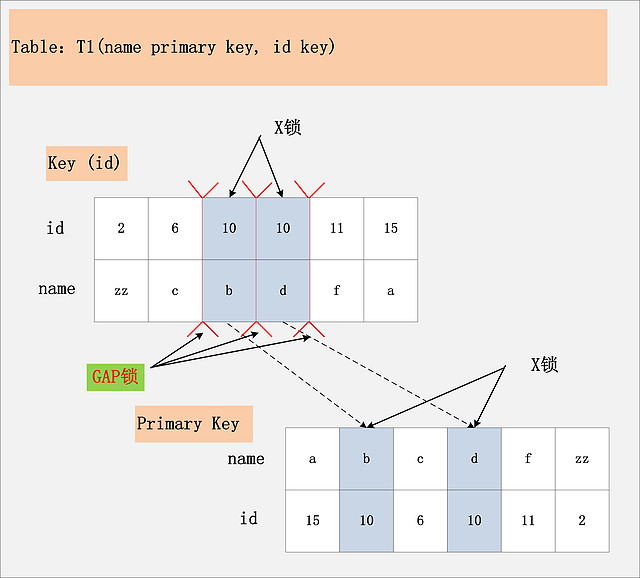
組合七,Repeatable Read隔離級別,id上有一個非唯一索引,執行delete from t1 where id = 10; 假設選擇id列上的索引進行條件過濾,最后的加鎖行為,是怎么樣的呢?同樣看下面這幅圖:
?
此圖,相對于組合三:[id列上非唯一鎖,Read Committed]看似相同,其實卻有很大的區別。最大的區別在于,這幅圖中多了一個GAP鎖,而且GAP鎖看起來也不是加在記錄上的,倒像是加載兩條記錄之間的位置,GAP鎖有何用?
?
其實這個多出來的GAP鎖,就是RR隔離級別,相對于RC隔離級別,不會出現幻讀的關鍵。確實,GAP鎖鎖住的位置,也不是記錄本身,而是兩條記錄之間的GAP。所謂幻讀,就是同一個事務,連續做兩次當前讀 (例如:select * from t1 where id = 10 for update;),那么這兩次當前讀返回的是完全相同的記錄 (記錄數量一致,記錄本身也一致),第二次的當前讀,不會比第一次返回更多的記錄 (幻象)。
?
如何保證兩次當前讀返回一致的記錄,那就需要在第一次當前讀與第二次當前讀之間,其他的事務不會插入新的滿足條件的記錄并提交。為了實現這個功能,GAP鎖應運而生。
?
如圖中所示,有哪些位置可以插入新的滿足條件的項 (id = 10),考慮到B+樹索引的有序性,滿足條件的項一定是連續存放的。記錄[6,c]之前,不會插入id=10的記錄;[6,c]與[10,b]間可以插入[10, aa];[10,b]與[10,d]間,可以插入新的[10,bb],[10,c]等;[10,d]與[11,f]間可以插入滿足條件的[10,e],[10,z]等;而[11,f]之后也不會插入滿足條件的記錄。因此,為了保證[6,c]與[10,b]間,[10,b]與[10,d]間,[10,d]與[11,f]不會插入新的滿足條件的記錄,MySQL選擇了用GAP鎖,將這三個GAP給鎖起來。
?
Insert操作,如insert [10,aa],首先會定位到[6,c]與[10,b]間,然后在插入前,會檢查這個GAP是否已經被鎖上,如果被鎖上,則Insert不能插入記錄。因此,通過第一遍的當前讀,不僅將滿足條件的記錄鎖上 (X鎖),與組合三類似。同時還是增加3把GAP鎖,將可能插入滿足條件記錄的3個GAP給鎖上,保證后續的Insert不能插入新的id=10的記錄,也就杜絕了同一事務的第二次當前讀,出現幻象的情況。
?
有心的朋友看到這兒,可以會問:既然防止幻讀,需要靠GAP鎖的保護,為什么組合五、組合六,也是RR隔離級別,卻不需要加GAP鎖呢?
?
首先,這是一個好問題。其次,回答這個問題,也很簡單。GAP鎖的目的,是為了防止同一事務的兩次當前讀,出現幻讀的情況。而組合五,id是主鍵;組合六,id是unique鍵,都能夠保證唯一性。一個等值查詢,最多只能返回一條記錄,而且新的相同取值的記錄,一定不會在新插入進來,因此也就避免了GAP鎖的使用。其實,針對此問題,還有一個更深入的問題:如果組合五、組合六下,針對SQL:select * from t1 where id = 10 for update; 第一次查詢,沒有找到滿足查詢條件的記錄,那么GAP鎖是否還能夠省略?此問題留給大家思考。
?
結論:Repeatable Read隔離級別下,id列上有一個非唯一索引,對應SQL:delete from t1 where id = 10; 首先,通過id索引定位到第一條滿足查詢條件的記錄,加記錄上的X鎖,加GAP上的GAP鎖,然后加主鍵聚簇索引上的記錄X鎖,然后返回;然后讀取下一條,重復進行。直至進行到第一條不滿足條件的記錄[11,f],此時,不需要加記錄X鎖,但是仍舊需要加GAP鎖,最后返回結束。
?
-
組合八:id無索引+RR
?
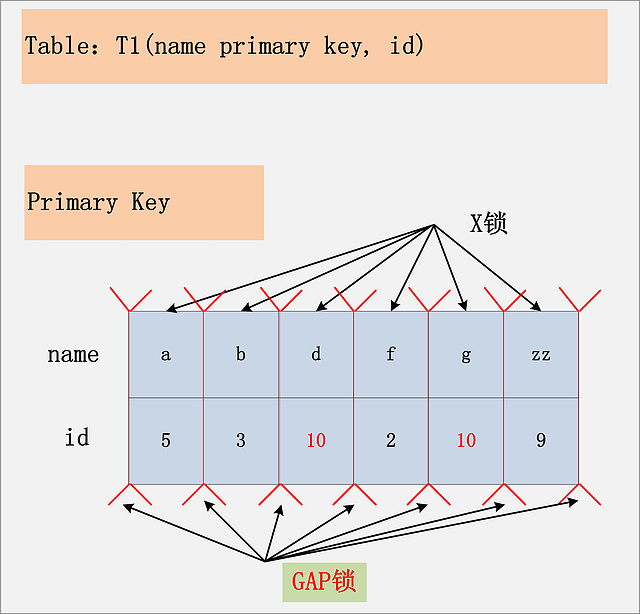
組合八,Repeatable Read隔離級別下的最后一種情況,id列上沒有索引。此時SQL:delete from t1 where id = 10; 沒有其他的路徑可以選擇,只能進行全表掃描。最終的加鎖情況,如下圖所示:
?
如圖,這是一個很恐怖的現象。首先,聚簇索引上的所有記錄,都被加上了X鎖。其次,聚簇索引每條記錄間的間隙(GAP),也同時被加上了GAP鎖。這個示例表,只有6條記錄,一共需要6個記錄鎖,7個GAP鎖。試想,如果表上有1000萬條記錄呢?
?
在這種情況下,這個表上,除了不加鎖的快照度,其他任何加鎖的并發SQL,均不能執行,不能更新,不能刪除,不能插入,全表被鎖死。
?
當然,跟組合四:[id無索引, Read Committed]類似,這個情況下,MySQL也做了一些優化,就是所謂的semi-consistent read。semi-consistent read開啟的情況下,對于不滿足查詢條件的記錄,MySQL會提前放鎖。針對上面的這個用例,就是除了記錄[d,10],[g,10]之外,所有的記錄鎖都會被釋放,同時不加GAP鎖。semi-consistent read如何觸發:要么是read committed隔離級別;要么是Repeatable Read隔離級別,同時設置了innodb_locks_unsafe_for_binlog?參數。更詳細的關于semi-consistent read的介紹,可參考我之前的一篇博客:MySQL+InnoDB semi-consitent read原理及實現分析?。
?
結論:在Repeatable Read隔離級別下,如果進行全表掃描的當前讀,那么會鎖上表中的所有記錄,同時會鎖上聚簇索引內的所有GAP,杜絕所有的并發 更新/刪除/插入 操作。當然,也可以通過觸發semi-consistent read,來緩解加鎖開銷與并發影響,但是semi-consistent read本身也會帶來其他問題,不建議使用。
?
-
組合九:Serializable
?
針對前面提到的簡單的SQL,最后一個情況:Serializable隔離級別。對于SQL2:delete from t1 where id = 10; 來說,Serializable隔離級別與Repeatable Read隔離級別完全一致,因此不做介紹。
?
Serializable隔離級別,影響的是SQL1:select * from t1 where id = 10; 這條SQL,在RC,RR隔離級別下,都是快照讀,不加鎖。但是在Serializable隔離級別,SQL1會加讀鎖,也就是說快照讀不復存在,MVCC并發控制降級為Lock-Based CC。
?
結論:在MySQL/InnoDB中,所謂的讀不加鎖,并不適用于所有的情況,而是隔離級別相關的。Serializable隔離級別,讀不加鎖就不再成立,所有的讀操作,都是當前讀。
?
-
一條復雜的SQL
?
寫到這里,其實MySQL的加鎖實現也已經介紹的八八九九。只要將本文上面的分析思路,大部分的SQL,都能分析出其會加哪些鎖。而這里,再來看一個稍微復雜點的SQL,用于說明MySQL加鎖的另外一個邏輯。SQL用例如下:

?
如圖中的SQL,會加什么鎖?假定在Repeatable Read隔離級別下 (Read Committed隔離級別下的加鎖情況,留給讀者分析。),同時,假設SQL走的是idx_t1_pu索引。
?
在詳細分析這條SQL的加鎖情況前,還需要有一個知識儲備,那就是一個SQL中的where條件如何拆分?具體的介紹,建議閱讀我之前的一篇文章:SQL中的where條件,在數據庫中提取與應用淺析?。在這里,我直接給出分析后的結果:
?
- Index key:pubtime > 1 and puptime < 20。此條件,用于確定SQL在idx_t1_pu索引上的查詢范圍。
?
- Index Filter:userid = ‘hdc’ 。此條件,可以在idx_t1_pu索引上進行過濾,但不屬于Index Key。
- Table Filter:comment is not NULL。此條件,在idx_t1_pu索引上無法過濾,只能在聚簇索引上過濾。
?
在分析出SQL where條件的構成之后,再來看看這條SQL的加鎖情況 (RR隔離級別),如下圖所示:
?
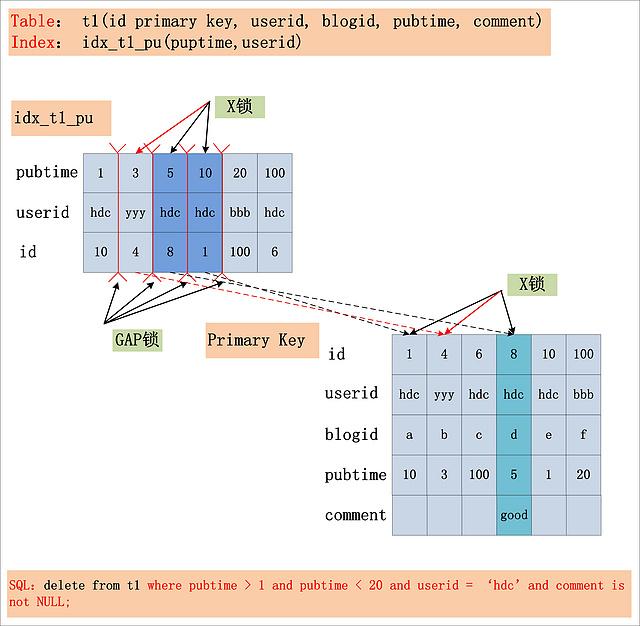
?
從圖中可以看出,在Repeatable Read隔離級別下,由Index Key所確定的范圍,被加上了GAP鎖;Index Filter鎖給定的條件 (userid = ‘hdc’)何時過濾,視MySQL的版本而定,在MySQL 5.6版本之前,不支持Index Condition Pushdown(ICP),因此Index Filter在MySQL Server層過濾,在5.6后支持了Index Condition Pushdown,則在index上過濾。若不支持ICP,不滿足Index Filter的記錄,也需要加上記錄X鎖,若支持ICP,則不滿足Index Filter的記錄,無需加記錄X鎖 (圖中,用紅色箭頭標出的X鎖,是否要加,視是否支持ICP而定);而Table Filter對應的過濾條件,則在聚簇索引中讀取后,在MySQL Server層面過濾,因此聚簇索引上也需要X鎖。最后,選取出了一條滿足條件的記錄[8,hdc,d,5,good],但是加鎖的數量,要遠遠大于滿足條件的記錄數量。
?
結論:在Repeatable Read隔離級別下,針對一個復雜的SQL,首先需要提取其where條件。Index Key確定的范圍,需要加上GAP鎖;Index Filter過濾條件,視MySQL版本是否支持ICP,若支持ICP,則不滿足Index Filter的記錄,不加X鎖,否則需要X鎖;Table Filter過濾條件,無論是否滿足,都需要加X鎖。
?
-
死鎖原理與分析
?
本文前面的部分,基本上已經涵蓋了MySQL/InnoDB所有的加鎖規則。深入理解MySQL如何加鎖,有兩個比較重要的作用:
?
- 可以根據MySQL的加鎖規則,寫出不會發生死鎖的SQL;
?
- 可以根據MySQL的加鎖規則,定位出線上產生死鎖的原因;
下面,來看看兩個死鎖的例子 (一個是兩個Session的兩條SQL產生死鎖;另一個是兩個Session的一條SQL,產生死鎖):

?
?

?
上面的兩個死鎖用例。第一個非常好理解,也是最常見的死鎖,每個事務執行兩條SQL,分別持有了一把鎖,然后加另一把鎖,產生死鎖。
?
第二個用例,雖然每個Session都只有一條語句,仍舊會產生死鎖。要分析這個死鎖,首先必須用到本文前面提到的MySQL加鎖的規則。針對Session 1,從name索引出發,讀到的[hdc, 1],[hdc, 6]均滿足條件,不僅會加name索引上的記錄X鎖,而且會加聚簇索引上的記錄X鎖,加鎖順序為先[1,hdc,100],后[6,hdc,10]。而Session 2,從pubtime索引出發,[10,6],[100,1]均滿足過濾條件,同樣也會加聚簇索引上的記錄X鎖,加鎖順序為[6,hdc,10],后[1,hdc,100]。發現沒有,跟Session 1的加鎖順序正好相反,如果兩個Session恰好都持有了第一把鎖,請求加第二把鎖,死鎖就發生了。
?
結論:死鎖的發生與否,并不在于事務中有多少條SQL語句,死鎖的關鍵在于:兩個(或以上)的Session加鎖的順序不一致。而使用本文上面提到的,分析MySQL每條SQL語句的加鎖規則,分析出每條語句的加鎖順序,然后檢查多個并發SQL間是否存在以相反的順序加鎖的情況,就可以分析出各種潛在的死鎖情況,也可以分析出線上死鎖發生的原因。
?
-
總結
?
寫到這兒,本文也告一段落,做一個簡單的總結,要做的完全掌握MySQL/InnoDB的加鎖規則,甚至是其他任何數據庫的加鎖規則,需要具備以下的一些知識點:
?
- 了解數據庫的一些基本理論知識:數據的存儲格式 (堆組織表 vs 聚簇索引表);并發控制協議 (MVCC vs Lock-Based CC);Two-Phase Locking;數據庫的隔離級別定義 (Isolation Level);
- 了解SQL本身的執行計劃 (主鍵掃描 vs 唯一鍵掃描 vs 范圍掃描 vs 全表掃描);
- 了解數據庫本身的一些實現細節 (過濾條件提取;Index Condition Pushdown;Semi-Consistent Read);
- 了解死鎖產生的原因及分析的方法 (加鎖順序不一致;分析每個SQL的加鎖順序)
?
有了這些知識點,再加上適當的實戰經驗,全面掌控MySQL/InnoDB的加鎖規則,當不在話下。
?
文轉載自 ?http://hedengcheng.com/?p=771
擴展閱讀 ?
并發編程含義 ?http://hedengcheng.com/?p=803
mysql行級別鎖測試 ?http://blog.csdn.net/lengzijian/article/details/7234909

)

)
![[js高手之路]構造函數的基本特性與優缺點](http://pic.xiahunao.cn/[js高手之路]構造函數的基本特性與優缺點)














