?
一、前端信號處理
1. 語音檢測(VAD)
語音檢測(英文一般稱為 Voice Activity Detection,VAD)的目標是,準確的檢測出音頻信號的語音段起始位置,從而分離出語音段和非語音段(靜音或噪聲)信號。由于能夠濾除不相干非語音信號,高效準確的 VAD 不但能減輕后續處理的計算量,提高整體實時性,還能有效提高下游算法的性能。
VAD 算法可以粗略的分為三類:基于閾值的 VAD、作為分類器的 VAD、模型 VAD。
基于閾值的 VAD:通過提取時域(短時能量、短期過零率等)或頻域(MFCC、譜熵等)特征,通過合理的設置門限,達到區分語音和非語音的目的。這是傳統的 VAD 方法。
作為分類器的 VAD:可以將語音檢測視作語音/非語音的兩分類問題,進而用機器學習的方法訓練分類器,達到檢測語音的目的。
模型 VAD:可以利用一個完整的聲學模型(建模單元的粒度可以很粗),在解碼的基礎,通過全局信息,判別語音段和非語音段。
VAD 作為整個流程的最前端,需要在本地實時的完成。由于計算資源非常有限,因此,VAD 一般會采用閾值法中某種算法;經過工程優化的分類法也可能被利用;而模型 VAD 目前難以在本地部署應用。
?
2. 降噪
實際環境中存在著空調、風扇以及其他各種各樣的噪聲。降低噪聲干擾,提高信噪比,降低后端語音識別的難度。?
常用的降噪算法有 自適應 LMS 和維納濾波等。
?
3. 聲學回聲消除(Acoustic Echo Cancellaction, AEC)
AEC也是一種常見的技術,在語音通話中,AEC是必不可少的基礎技術。?
?
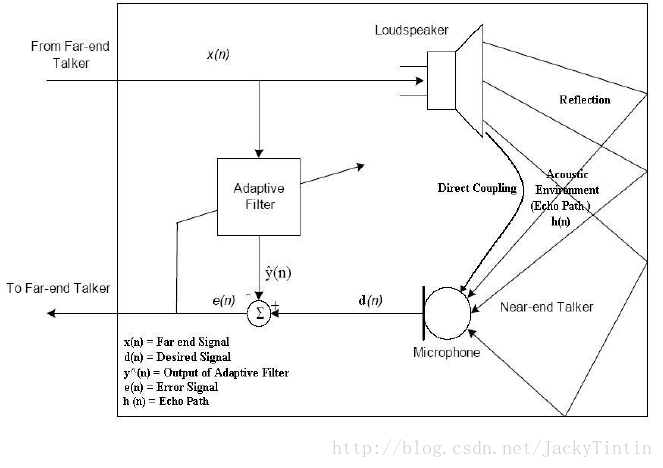
具體的,AEC 的目的是,在音箱揚聲器工作(播放音樂或語音)時,從麥克風中收集的語音中,去除自身播放的聲音信號。這是雙工模式的前提。否則,當音樂播放時,我們的聲音信號會淹沒在音樂聲中,不能繼續對音箱進行有效的語音控制。
?
4. 去混響處理
在室內,語音會被墻壁等多次反射,麥克風采集到(圖12)。混響對于人耳完全不是問題,但是,延遲的語音疊加產生掩蔽效應,這對語音識別是致命的障礙。
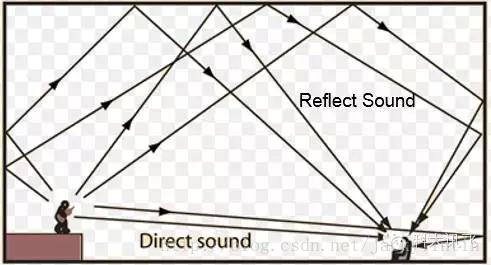
對于混響,一般從兩個方面來嘗試解決:1)去混響 2)對語音識別的聲學模型加混響訓練。由于真實環境的復雜性,一定的前端去混響算法還是非常有必要的。
?
5. 聲源定位(Direction of Arrival estimation, DOA)
聲源定位是根據麥列收集的聲音語,確定說話人的位置。DOA 至少有兩個用途,1)用于方位燈的展示,增強交互效果;2)作為波束形成的前導任務,確定空間濾波的參數。
聲源定位有如下常用方法有基于波束掃描的聲源定位、基于起分辨率率譜估計的聲源定位以及 基于到達時間差(Time Difference of Arrival, TDOA)的聲源定位。考慮到算法復雜性和延時,一般采用TDOA方法。
?
6. 波束形成(Beam Forming, BF)
波束形成是利用空間濾波的方法,將多路聲音信號,整合為一路信號。通過波束形成,一方面可以增強原始的語音信號,另一方面抑制旁路信號,起到降噪和去混響的作用(圖13)。
?

?
二、 喚醒
出于保護用戶隱私和減少誤識別兩個因素的考慮,智能音箱一般在檢測到喚醒詞之后,才會開始進一步的復雜信號處理(聲源定位、波束形成)和后續的語音交互過程。
一般而言,喚喚醒模塊是一個小型語音識別引擎。由于目標單一(檢測 出指定的喚醒詞),喚醒只需要較小的聲學模型和語言模型(只需要區分出有無喚醒詞出現),聲學打分和解碼可以很快,空間占用少,能夠在本地實時。
也有喚醒做為關鍵詞檢索(key word search)或文本相關的聲紋識別問題來解決。
?
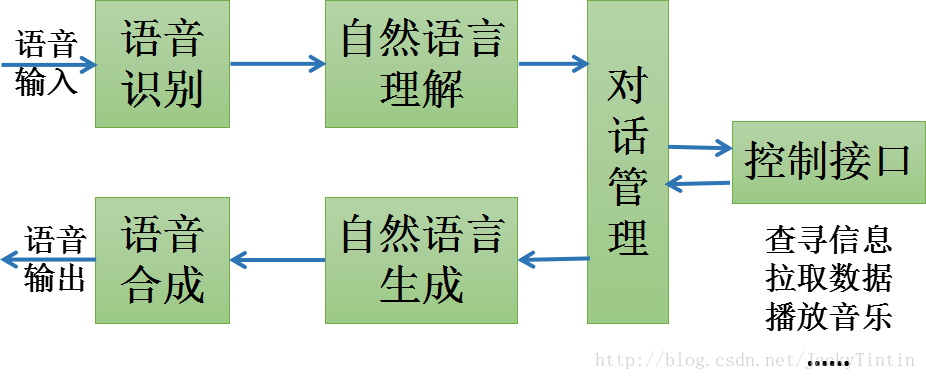
三、語音交互
語音交互的基本流程如圖16所示。下面分別對各個環節進行簡要介紹。?
?
?
1. 語音識別(Automatic Speech Recognition, ASR)
語音識別的目的是將語音信號轉化為文本。語音識別技術相對成熟。目前,基于近場信號的、受控環境(低噪聲、低混響)下的標準音語音識別能夠達到很的水平。然而在智能音箱開放性的真實環境,語音識別依然是一個不小的挑戰,需要接合前端信號處理一起來優化。
?
2. 自然語言理解(Natural Language Understanding, NLU)
NLU 作為一個研究課題還遠沒有被解決。但是在限定領域下,結合良好的產品設計,我們還是能夠利用現有技術,做出實用的產品。
可以將基于框架的(frame-based) NLU 分為三個子問題去解決(圖15):?
* 領域分類:識別出用戶命令所屬領域。其中,領域是預先設計的封閉集合(如產品設計上,音箱只支持音樂、天氣等領域),而每個領域都只支持無限預設的查詢內容和交互方式。?
* 意圖分類:在相應領域,識別用戶的意圖(如播放音樂、暫停或切換等)。意圖往往對應著實際的操作。?
* 實體抽取(槽填充):確定意圖(操作)的參數(如確定,具體是播放哪首歌或哪位歌手的歌曲)。
?

3. 對話管理(Diaglou Management, DM)
多輪對話對于自然的人工交互非常重要。比如,當我們詢問“北京明天的天氣怎么?”,之后,更習慣追問“那深圳呢?”而不是重復的說”**深圳明天的天氣怎么?**“
在 NLU 無有得到很好解決的情況下,對話管理似乎不可能。好在限范圍下,結合產品設計,還是能做的不錯。一般的作法是,將輪對話解析出的參數做為上下文(全局變量),帶入到下一輪對話;當前輪對話,根據一定的條件判斷,是否保持在上一輪的領域,是否清空上下文。
不同于純粹的聊天機器的對話管理,智能音箱的對話管理還有實際的操作功能(查詢信息、提供控制指令)。
?
4. 自然語言生成(Natural Language Generation, NLG)
目前完全自動化的 NLG 方法還不成熟。實際產品中,多采用預先設計的文本模板來生成文本輸出。比如,播放歌曲時,生成語句為:“即將為您播放【歌手名】的【歌曲名】”。
?
5.? 語音合成(Speech Synthesis)
語音合成又叫做文語轉換(Text-to-Speech,TTS),更常見可能是 TTS 這一稱呼。TTS 的終極目標是,使機器能夠像人一樣朗讀任意給定的文本。
評價實用的語音合成系統的兩個主要的標準是1)可懂度(人能夠聽懂)和2)自然度(使人聽著舒服)。目前,可懂度的問題基本得到解決。參數合成和拼接合成是TTS的兩種主要合成方法,其中,參數計算量小,部署靈活,但自然較差;拼接接近真人發音,存儲和計算資源高,一般只能在線合成。例如,Echo 采用的基于單元選擇(unit selection)的拼接合成。
?
四、 其他技術
最后,我們簡單列舉一些相對成熟,但還沒有廣泛應用于智能音箱的技術。
聲紋識別
聲紋識別是據語音波形反映說話人生理和行為特征的語音參數,自動識別說話人身份的一項技術。微信中的聲音鎖就是聲紋技術的一項具體應用。
通過聲紋識別,可以設計出更加個性化的服務。
人臉檢測
如果音箱配置為攝像頭,可以通人臉檢測,確定用戶的位置。一方面可以有更好的交互設計,另一方面可以輔助聲源定位。
?
人臉識別
同聲紋識別類似,人臉識別也可以用來確定用戶的身份。
?
原文出處:https://blog.csdn.net/jackytintin/article/details/62040823

![【BZOJ1500】[NOI2005]維修數列 Splay](http://pic.xiahunao.cn/【BZOJ1500】[NOI2005]維修數列 Splay)
(主席樹))


及readLine()方法的使用心得)









)

![關于拓撲排序的問題-P3116 [USACO15JAN]會議時間Meeting Time](http://pic.xiahunao.cn/關于拓撲排序的問題-P3116 [USACO15JAN]會議時間Meeting Time)

)