一、MapReduce編程思想
學些MapRedcue主要是學習它的編程思想,在MR的編程模型中,主要思想是把對數據的運算流程分成map和reduce兩個階段:
Map階段:讀取原始數據,形成key-value數據(map方法)。即,負責數據的過濾分發。
Reduce階段:把map階段的key-value數據按照相同的key進行分組聚合(reduce方法)。即,數據的計算歸并。
它其實是一種數據邏輯運算模型,對于這樣的運算模型,有一些成熟的具體軟件實現,比如hadoop中的mapreduce框架、spark等,例如在hadoop的mr框架中,對map階段的具體實現是map task,對reduce階段的實現是reduce task。這些框架已經為我們提供了一些通用功能的實現,讓我們專注于數據處理的邏輯,而不考慮分布式的具體實現,比如讀取文件、寫文件、數據分發等。我們要做的工作就是在這些編程框架下,來實現我們的具體需求。
下面我們先介紹一些map task和reduce task中的一些具體實現:
二、MapTask和ReduceTask
2.1 Map Task
讀數據:利用InputFormat組件完成數據的讀取。
InputFormat-->TextInputFormat 讀取文本文件的具體實現
-->SequenceFileInputFormat 讀取Sequence文件
-->DBInputFormat 讀數據庫
處理數據:這一階段將讀取到的數據按照規則進行處理,生成key-value形式的結果。maptask通過調用用Mapper類的map方法實現對數據的處理。
分區:這一階段主要是把map階段產生的key-value數據進行分區,以分發給不同的reduce task來處理,使用的是Partitioner類。maptask通過調用Partitioner類的getPartition()方法來決定如何劃分數據給不同的reduce task。
排序:這一階段,對key-value數據做排序。maptask會按照key對數據進行排序,排序時調用key.compareTo()方法來實現對key-value數據排序。
2.2 Reduce Task
讀數據:這一階段通過http方式從maptask產生的數據文件中下載屬于自己的“區”的數據。由于一個區的數據可能來自多個maptask,所以reduce還要把這些分散的數據進行合并(歸并排序)
處理數據:一個reduce task中,處理剛才下載到自己本地的數據。通過調用GroupingComparator的compare()方法來判斷文件中的哪些key-value屬于同一組。然后將這一組數傳給Reducer類的reduce()方法聚合一次。
輸出結果:調用OutputFormat組件將結果key-value數據寫出去。
Outputformat --> TextOutputFormat 寫文本文件(會把一個key-value對寫一行,分隔符為制表符\t
--> SequenceFileOutputFormat 寫Sequence文件(直接將key-value對象序列化到文件中)
--> DBOutputFormat?
下面介紹下利用MapReduce框架下的一般編程過程。我們要做的 工作就是把我們對數據的處理邏輯加入到框架的業務邏輯中。我們編寫的MapReduce的job客戶端主要包括三個部分,Mapper 、 Reducer和JobSubmitter,三個部分分別完成MR程序的map邏輯、reduce邏輯以及將我們編寫的job程序提交給集群。下面分別介紹這三個部分如何實現。
三、Hadoop中MapReduce框架下的一般編程步驟
Mapper:創建類,該類要實現Mapper父類,復寫read()方法,在方法內實現當前工程中的map邏輯。
Reducer:創建類,繼承Reducer父類,復寫reduce()方法,方法內實現當前工程中的reduce邏輯。
jobSubmitter:這是job在集群上實際運行的類,主要是通過main方法,封裝job相關參數,并把job提交。jobsubmitter內一般包括以下操作
step1:創建Configuration對象,并通過創建的對象對集群進行配置,同時支持用戶自定義一些變量并配置。這一步有些像我們集群搭建的時候對$haoop_home/etc/hadoop/*下的一些文件進行的配置。
step2:獲得job對象,并通過job對象對我們job運行進行一些配置。例如,設置集群運行的jar文件、設置實際執行map和reduce的類等,下面列出一些必要設置和可選設置。
Configuration conf = new Configuration(); //創建集群配置對象。Job job = Job.getInstance(conf);//根據配置對象獲取一個job客戶端實例。job.setJarByClass(JobSubmitter.class);//設置集群上job執行的類job.setMapperClass(FlowCountMapper.class);//設置job執行時使用的Mapper類job.setReducerClass(FlowCountReducer.class);//設置job執行時使用的Reducer類job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job, new Path("I:\\hadooptest\\input"));FileOutputFormat.setOutputPath(job, new Path("I:\\hadooptest\\output_pri"));//設置maptask做數據分發時使用的分發邏輯類,如果不指定,默認使用hashparjob.setPartitionerClass(ProvincePartitioner.class);job.setNumReduceTasks(4);//自定義的分發邏輯下,可能產生n個分區,所以reducetask的數量需要是nboolean res = job.waitForCompletion(true);System.exit(res ? 0:-1);
?一般實踐中,可以定義一個類,其中添加main方法對job進行提交,并在其中定義靜態內部類maper和reduce類。
四、MapReduce框架中的可自定義項
<不小心刪除以后就沒有再補充了,挺重要的。。。。補上吧。。。。>
總結,你要把bean寫到文本嗎?重寫toString方法
要傳輸嗎?實現Writable接口
要排序嗎?實現writablecompareble接口
?
遇到一些復雜的需求,需要我們自定義實現一些組件
2.1 自定義序列化數據類型
MapReduce框架為我們提供了基本數據類型的序列化類型,如String的Text類型,int的IntWritalbe類型,null的NullWritable類型等。但是有時候會有一些我們自定義的類型需要我們在map和reduce之間進行傳輸或者需要寫到hdfs上。hadoop提供了自己的序列化機制,實現自定義類型的序列化和反序列化將自定義的類實現hadoop提供的Writable接口。
自定義類實現Writable接口,實現readFields(in) 和write(out)方法。
同時,重寫toString()方法,可以自定義在寫到文件系統時候寫入的字段內容。


* hadoop系統在序列化該類的對象時要調用的方法*/@Overridepublic void write(DataOutput out) throws IOException {out.writeInt(upFlow);out.writeUTF(phone);out.writeInt(dFlow);out.writeInt(amountFlow);}/*** hadoop系統在反序列化該類的對象時要調用的方法*/@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readInt();this.phone = in.readUTF();this.dFlow = in.readInt();this.amountFlow = in.readInt();}@Overridepublic String toString() {return this.phone + ","+this.upFlow +","+ this.dFlow +"," + this.amountFlow;}
2.2 自定義排序規則
MapReduce中提供了一個排序機制,map worker 和reduce worker ,都會對數據按照key的大小來排序,所以map和reduce階段輸出的記錄都是經過排序的(按照key排序)。我們在實踐中有時候需要對計算出來的結果進行排序,比如一個這樣的需求:計算每個頁面訪問次數,并按照訪問量倒序輸出。我們可以在統計了每個頁面訪問次數之后進行排序,但是我們還可以直接應用MR自身的排序特性,在MR處理的時候按照我們的需求進行排序。這時候就需要我們自定義排序規則。
自定義類,實現WritableComparable接口,實現其中的compareTo()方法,在其中自定義排序的規則。同時一般還要實現readFields(in) 和write(out)和toString()方法。
public class PageCount implements WritableComparable<PageCount>{private String page;private int count;public void set(String page, int count) {this.page = page;this.count = count;}public String getPage() {return page;}public void setPage(String page) {this.page = page;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic int compareTo(PageCount o) {return o.getCount()-this.count==0?this.page.compareTo(o.getPage()):o.getCount()-this.count;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(this.page);out.writeInt(this.count);}@Overridepublic void readFields(DataInput in) throws IOException {this.page= in.readUTF();this.count = in.readInt();}@Overridepublic String toString() {return this.page + "," + this.count;}}
總結:
實現Writable接口,是為了bean能夠傳輸,能夠寫到文件系統中。
實現WritableComparable還為了bean能夠按照你定義的規則進行排序。
2.2 自定義分區規則
我們知道,map計算出來的結果會分發給不同的reduce任務去進一步處理。MR中提供了一個默認的數據分發規則,會按照map的輸出中的key的hashcode,然后模除reduce task的數量,模除的結果就是數據的分區。我們可以通過自定義map數據分發給reduce的規則,實現把數據按照自己的需求記錄到不同的數據中。比如實現這樣的需求,有一個通話記錄的文件,按照歸屬地分別存儲數據。
?自定義類,繼承Partitioner父類(類的泛型為MapTask的輸出的key,value的類型),重寫?getPartition(<>key, <>value, int numPartitions)?方法,在其中自定義分區的規則,方法返回計算出來的分區數。MapTask每處理一行數據都會調用getPartition方法。因此最好不要在方法中創建可以給很多數據行共同使用的對象。在jobsubmitter中,設置maptask在做數據分區時使用的分區邏輯類,?job.setPartitonerClass(your.class)?,同時注意設置reduceTask的任務數量為我們在分區邏輯中定義的規則下回產生的分區數量,?job.setNumReduceTasks(numOfPartition);?
/*** 本類是提供給MapTask用的* MapTask通過這個類的getPartition方法,來計算它所產生的每一對kv數據該分發給哪一個reduce task* @author ThinkPad**/ public class ProvincePartitioner extends Partitioner<Text, FlowBean>{static HashMap<String,Integer> codeMap = new HashMap<>();static{codeMap.put("135", 0);codeMap.put("136", 1);codeMap.put("137", 2);codeMap.put("138", 3);codeMap.put("139", 4);}@Overridepublic int getPartition(Text key, FlowBean value, int numPartitions) {Integer code = codeMap.get(key.toString().substring(0, 3));return code==null?5:code;}}
public class JobSubmitter {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(JobSubmitter.class);job.setMapperClass(FlowCountMapper.class);job.setReducerClass(FlowCountReducer.class);// 設置參數:maptask在做數據分區時,用哪個分區邏輯類 (如果不指定,它會用默認的HashPartitioner)job.setPartitionerClass(ProvincePartitioner.class);// 由于我們的ProvincePartitioner可能會產生6種分區號,所以,需要有6個reduce task來接收job.setNumReduceTasks(6);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job, new Path("F:\\mrdata\\flow\\input"));FileOutputFormat.setOutputPath(job, new Path("F:\\mrdata\\flow\\province-output"));job.waitForCompletion(true);}}
2.3 自定義分組規則
MapTask每調用一次map就會產生一個k-v,多次調用后,生成多個k-v,具有相同key的的記錄稱為一組,會存入一個partition中,注意一個patition可以包含多個組。
?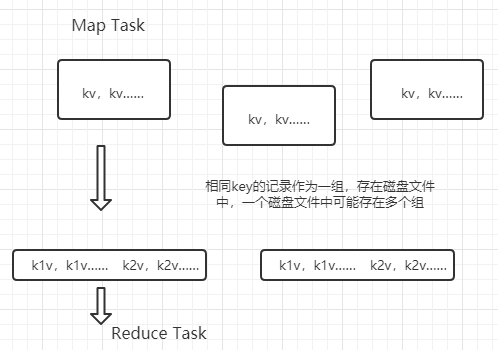
一個ReduceTask處理一個partition,在處理的時候 ,按照key的順序進行。調用一次reduce會聚合一組數據,就是reduce方法中傳入的一個Itetor。為了確認一個分區中的兩條記錄是不是同一個組,會調用一個工具類GroupingCompatator的compare(01,02)方法,用來判斷兩個key是否相同,如果兩個key相等,則為同一組。利用這樣的機制,我們可以自定義一個分組規則。
自定義類,實現?WritableComparator?類,實現?compare?方法,在其中告知MapTask如何判斷兩個 記錄是不是屬于同一個組。調用父類構造函數,指定比較的類。
public class OrderIdGroupingComparator extends WritableComparator {pbulic OrderIdGroupingComparator(){//通過構造函數指定要比較的類super(OrderBean.class, true);// }@Overridepublic int compare(WritableComparable a, WritableComparable b) {//參數中將來會傳入我們自定義的繼承了WritableComparable的bean,把a、b向下轉型為我們自定義類型的bean,才能比較a和bOrderBean o1 = (OrderBean)a;OrderBean o2 = (OrderBean)b;return o1.getOrderId().compareTo(o2.getOrderID);//id相同就是同一組 } }
在jobSubmiter中指定分組規則,
job.setGroupingComparatorClass(OrderIdGroupingComparator.class); 注意:關于區分分區和分組:
分區比分組的范圍更加大。分區是指,在map task結束之后,中間結果數據會被分給哪些reduce task,而分組是指,同一個分區中(即一個reduce task處理的數據中)數據的分組。在默認的計算分區的方法中,不同key的hash code對reduce task取模計算出來的結果可能相同,這樣的數據會被分到同一個分區;這一個分區中的key的haashcode不同,這樣就在一個區中分了不同組。
那么什么時候使用分區,什么時候使用分組呢?
再如在計算每個訂單中總金額最大的3筆中的案例中,可以考慮進行倒序排序,然后取前三;按照id進行倒序排序嗎?不現實,因為訂單id太多,不可能啟動那么多的reduce task。那么就要把多個訂單的數據存儲到第一個分區中,同時保證同一個訂單的數據全部在一個分區中,這時候,就需要自定義分區規則(保證同一訂單中的數據在同一個分區),但是又要分組排序,所以這時候就需要自定義分組規則(保證該分區中同一訂單在一組,不同訂單在不同組)
2.3自定義MapTask的局部聚合規則
默認情況下,map計算的結果逐條保存到磁盤中,傳輸給reduce之后也是分條的記錄,這樣可能造成一個問題就是如果某個分區下的數據較多,而有的分區下數據較少,就導致出現reduce task之間任務量差距較大,即出現數據傾斜的情況。一個解決辦法是在形成map結果文件的時候進行一次局部聚合。
使用Combiner組件可以實現在每個MapTask中對數據進行一次局部聚合。這個局部聚合的邏輯其實和Reducer的邏輯是一樣的,都是對map計算出的kv數據進行聚合,只不過如果是maptask來調用我們定義的Reducer實現類,則聚合的是當前這個maptask運行的結果,如果是reducetask來調用我們定義的Reducer實現類,則聚合的是全部maptask的運行結果。
定義類局部聚合類XXCombationer,繼承Rducer,復寫reduce方法,在方法中實現具體的聚合邏輯;在jobSubmitter的job中設置mapTask端的局部聚合類為我們定義的類?job.setCombinerClass(XXCombiner.class)?。
?
2.4 控制輸入輸出格式。。。

?
?
五、MR程序的調試、執行方式

?
5.1 提交到linux運行
?
5.2 Win本地執行
?

)












 - 進擊的小牛牛 - 博客園)




