什么是機器學習?
廣義概念:
機器學習是讓計算機具有學習的能力,無需明確的編程?—— 亞瑟·薩繆爾,1959
工程概念:
計算機程序利用經驗 E 學習任務 T,性能是 P,如果針對任務 T 的性能 P 隨著經驗 E 不斷增長,則稱為機器學習。 —— 湯姆·米切爾,1997
機器學習系統的類型
機器學習有多種類型,可以根據以下規則進行分類:
- 是否在人類監督下進行訓練(監督、非監督、半監督和強化學習)
- 是否可以動態漸進學習(在線學習和批量學習)
- 它們是否只是簡單的通過比較新的數據點和已知的數據點,還是在訓練數據中進行模式識別,以建立一個預測模型,就像科學家所做的那樣(基于實力學習和基于模型學習)
監督/非監督學習
機器學習可以根據訓練時監督的量和類型進行分類。主要有四類:監督、非監督、半監督和強化學習
監督學習
在監督學習中,用來訓練算法的訓練數據包含了答案,稱為標簽。

圖 1 用于監督學習(比如垃圾郵件分類)的加了標簽的訓練集
?一個典型的監督學習就是分類,垃圾郵件過濾器就是一個很好的例子:用很多帶有歸類(垃圾郵件和普通郵件)的郵件樣本進行訓練,過濾器還能用新郵件進行分類。
另一個典型數值是預測目標數值,例如給出一些特征(里程數、車程、品牌等等)稱為預測值,來預測一輛汽車的價格。這類任務稱為回歸,要訓練在這個系統,你需要給出大量汽車樣本,包括它們的預測值和標簽(即它們的價格)
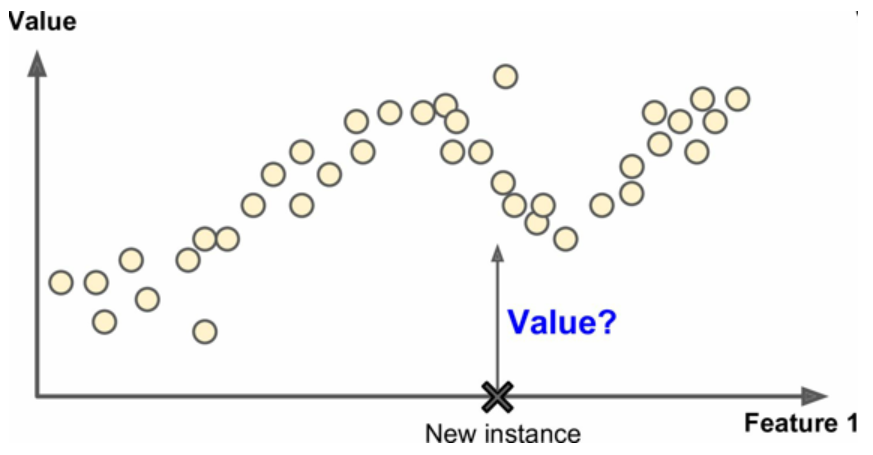
圖2 回歸
?注意:一些回歸算法也可以用來進行分類,例如,邏輯回歸常用來進行分類,它可以生成一個歸屬某一類的可能性的值。
下面是一些重要的監督性學習算法:
- K近鄰算法
- 線性回歸
- 邏輯回歸
- 支持向量機(SVM)
- 決策樹和隨機森林
- 神經網絡
?非監督學習
?訓練數據沒有加標簽。
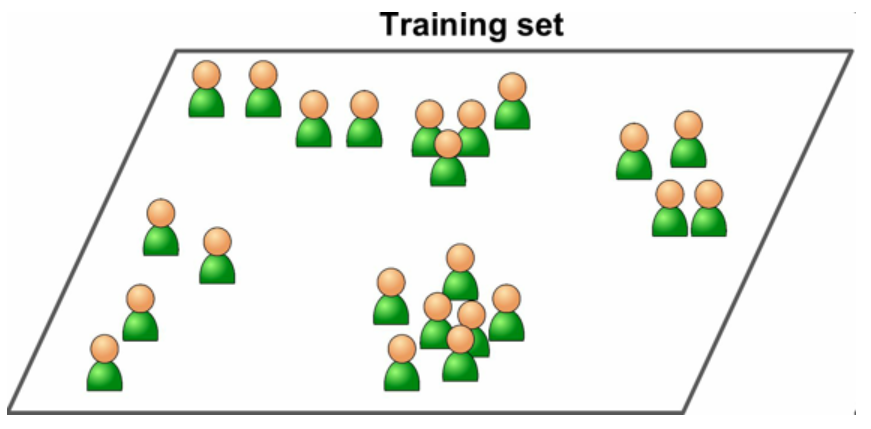
圖 3 非監督學習的一個不加標簽的訓練集
下面是一些最重要的非監督學習算法:
- 聚類 (K均值、層次聚類分析、期望最大值)
- 可視化和降維度 (主成分分析、核主成分分析、局部線性嵌入、t-分布鄰域嵌入算法)
- 關聯性規則學習(Apriori算法、Eclat算法)
例如,假設你有一份關于你的博客訪客的大量數據。你想運行一個聚類算法,檢測相似訪客的分組(圖 1-8)。你不會告訴算法某個訪客屬于哪一類:它會自己找出關系,無需幫助。例如,算法可能注意到 40% 的訪客是喜歡漫畫書的男性,通常是晚上訪問,20% 是科幻愛好者,他們是在周末訪問等等。如果你使用層次聚類分析,它可能還會細分每個分組為更小的組。這可以幫助你為每個分組定位博文。
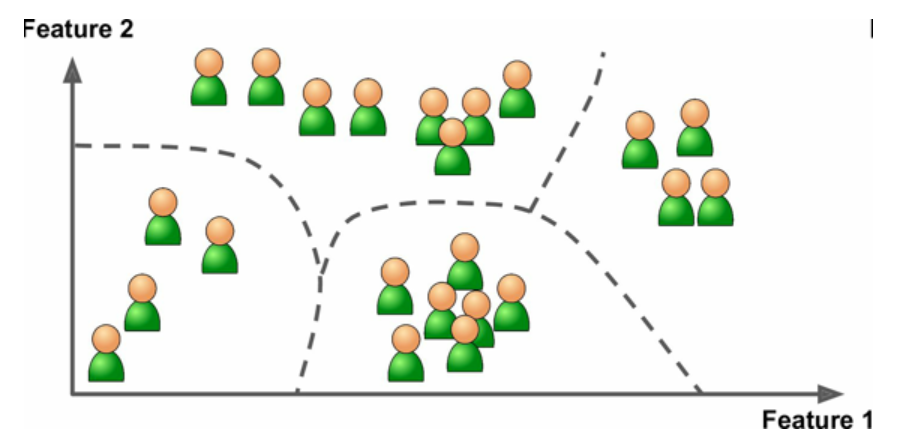
圖4 聚類
?可視化算法也是極佳的非監督學習案例:給算法大量復雜的且不加標簽的數據,算法輸出數據的2D或3D圖像(圖 1-9)。算法會試圖保留數據的結構(即嘗試保留輸入的獨立聚類,避免在圖像中重疊),這樣就可以明白數據是如何組織起來的,也許還能發現隱藏的規律。
?
圖 5 t-SNE 可視化案例,突出了聚類(注:注意動物是與汽車分開的,馬和鹿很近、與鳥距離遠,以此類推)
?與此有關聯的任務是降維,降維的目的是簡化數據、但是不能失去大部分信息。做法之一是合并若干相關的特征。例如,汽車的里程數和車齡高度相關,降維算法就會將他們合并為汽車的磨損,叫做特征提取。
注意:在用訓練集訓練機器學習算法(比如監督學習算法)時,最好對訓練集進行降維。這樣可以運行的更快,占用的硬盤和內存空間更少,有些情況下性能也更好。
另一個非常重要的非監督任務時異常檢測(anomaly detection) —— 例如,檢測異常的信用卡轉賬以防欺詐,檢測制造缺陷,或者在訓練之前自動從訓練集中去除異常值,異常監測的系統是用正常值訓練的,當它碰到一個新實例,可以判斷這個新實例是正常值還是異常值。

圖6 異常檢測
?最后,另一個很重要的非監督學習是關聯規則學習,他的目標是挖掘大量數據以發現屬性間有趣的關系。
例如,假設你擁有一個超市。在銷售日志上運行關聯規則,可能發現買了燒烤醬和薯片的人也會買牛排。因此,你可以將這些商品放在一起。
?半監督學習
?一些算法可以處理部分帶標簽的訓練數據,通常是大量不帶標簽數據加上少量帶標簽數據,這種稱為半監督學習。
一些圖片存儲服務,比如 Google Photos,是半監督學習的好例子。一旦你上傳了所有家庭相片,它就能自動識別到人物 A 出現在了相片 1、5、11 中,另一個人 B 出現在了相片 2、5、7 中。這是算法的非監督部分(聚類)。現在系統需要的就是你告訴它這兩個人是誰。只要給每個人一個標簽,算法就可以命名每張照片中的每個人,特別適合搜索照片。
?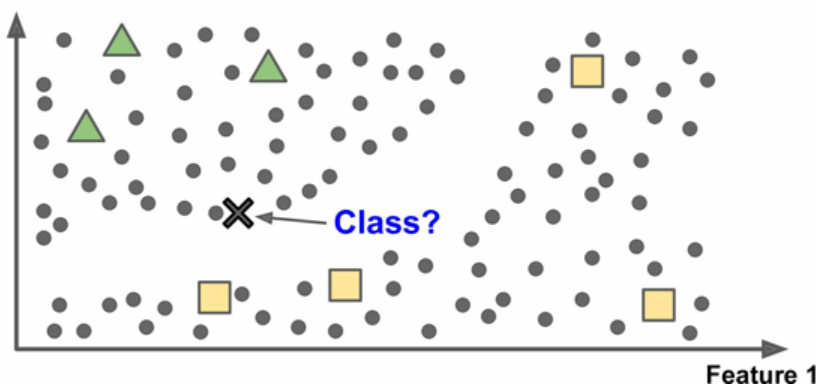
圖7 半監督學習
?多數半監督學習算法是半監督學習和監督學習的結合。例如,深度信念網絡(deep belief networks)是基于被稱為互相疊加的受限玻爾茲曼機(restricted Boltzmann machines,RBM)的非監督組件。RBM 是先用非監督方法進行訓練,再用監督學習方法對整個系統進行微調。
強化學習
?強化學習非常不同。學習系統在這里稱為智能體,可以對環境進行觀察、選擇和執行動作(負獎勵是懲罰),然后它必須自己學習哪個是最佳方法(稱為策略),已獲得長久的最大獎勵。策略決定了智能體在給定情況下應采取的行動。
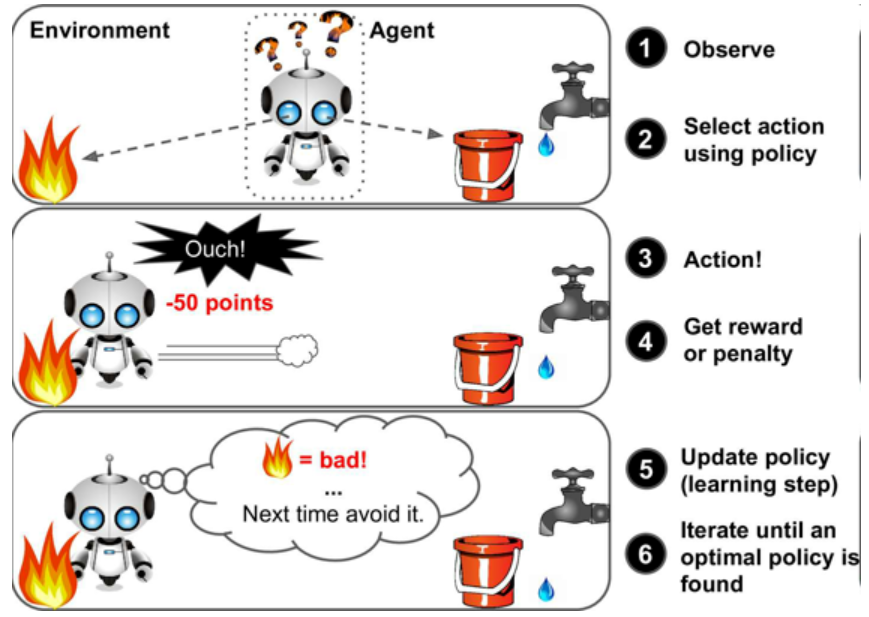
圖8 強化學習
例如,許多機器人運行強化學習算法以學習如何行走。DeepMind 的 AlphaGo 也是強化學習的例子:它在 2016 年三月擊敗了世界圍棋冠軍李世石(譯者注:2017 年五月,AlphaGo 又擊敗了世界排名第一的柯潔)。它是通過分析數百萬盤棋局學習制勝策略,然后自己和自己下棋。要注意,在比賽中機器學習是關閉的;AlphaGo 只是使用它學會的策略。
批量和在線學習
?另一個用來分類機器學習的準則是,它是否能從導入的數據流進行持續學習。
?批量學習
在批量學習中,系統不能進行持續學習:必須用所有可用數據進行訓練。這通常會占用大量時間和計算資源,所以一般是線下做的。首先是進行訓練,然后部署在生產環境且停止學習,它只是使用已經學到的策略。這稱為離線學習。
如果你想讓一個批量學習系統明白新數據(例如垃圾郵件的新類型),就需要從頭訓練一個系統的新版本,使用全部數據集(不僅有新數據也有老數據),然后停掉老系統,換上新系統。
幸運的是,訓練、評估、部署一套機器學習的系統的整個過程可以自動進行,所以即便是批量學習也可以適應改變。只要有需要,就可以方便地更新數據、訓練一個新版本。
這個方法很簡單,通常可以滿足需求,但是用全部數據集進行訓練會花費大量時間,所以一般是每 24 小時或每周訓練一個新系統。如果系統需要快速適應變化的數據(比如,預測股價變化),就需要一個響應更及時的方案。
另外,用全部數據訓練需要大量計算資源(CPU、內存空間、磁盤空間、磁盤 I/O、網絡 I/O 等等)。如果你有大量數據,并讓系統每天自動從頭開始訓練,就會開銷很大。如果數據量巨大,甚至無法使用批量學習算法。
最后,如果你的系統需要自動學習,但是資源有限(比如,一臺智能手機或火星車),攜帶大量訓練數據、每天花費數小時的大量資源進行訓練是不實際的。
幸運的是,對于上面這些情況,還有一個更佳的方案可以進行持續學習。
在線學習
在在線學習中,用數據實例可以持續進行訓練 ,可以一次一個或一次幾個實例(稱為小批量)。每個學習步驟都很快且廉價,系統可以動態學習收到的新數據。
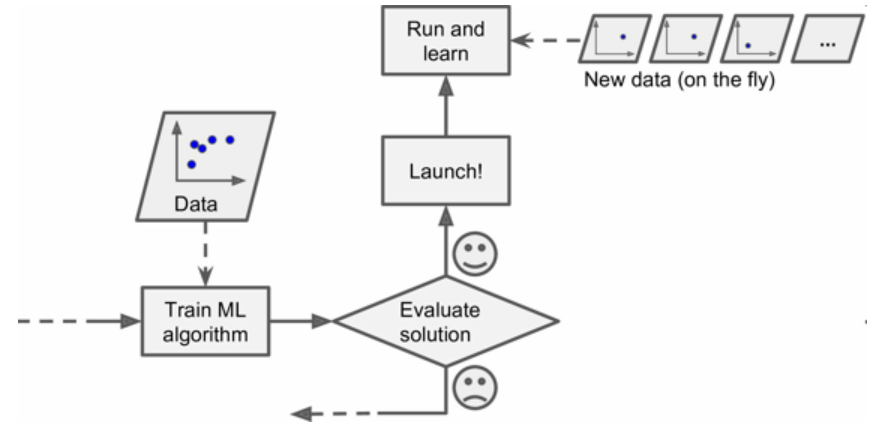
圖9 在線學習
在線學習很適合系統接收連續流的數據(比如股票價格),且需要自動對改變做出調整,如果計算資源有限,在線學習是一個不錯的方案:一旦在線學習系統學習了新的數據實例,它就不再需要這些數據了,所以扔掉這些數據(除非你想滾回到之前的一個狀態,再次使用數據)。這樣可以節省大量的空間。
在線學習算法也適合于超大數據集(一臺計算機不足以存儲它)上訓練系統(這稱作核外學習,out-of-core learning)。算法每次只加載部分數據,用這些數據進行訓練,然后重復這個過程,直到使用完所有的數據。
警告:這個整個過程通常是離線完成的(即,不在部署的系統上),所以在線學習這個名字會讓人疑惑。可以把它想成持續學習。
?在線學習系統的一個重要參數是,它們可以多快地適應數據的改變:這被稱為學習速率。如果你設定一個高學習速率,系統就可以快速適應新數據,但是也會快速忘記老數據(你可不想讓垃圾郵件過濾器只標記最新的垃圾郵件種類)。相反的,如果你設定的學習速率低,系統的惰性就會強:即,它學的更慢,但對新數據中的噪聲或沒有代表性的數據點結果不那么敏感。
在線學習的挑戰之一是,如果壞數據被用來進行訓練,系統的性能就會逐漸下滑。如果這是一個部署的系統,用戶就會注意到。例如,壞數據可能來自失靈的傳感器或機器人,或某人向搜索引擎傳入垃圾信息以提高搜索排名。要減小這種風險,你需要密集監測,如果檢測到性能下降,要快速關閉(或是滾回到一個之前的狀態)。你可能還要監測輸入數據,對反常數據做出反應(比如,使用異常檢測算法)。
基于實例VS基于模型學習
另一種分類機器學習是判斷它們如何進行推廣的,大多數機器學習是關于預測的。這意味著給定一定數量的訓練樣本,系統能夠推廣到沒有見過的樣本。對訓練數據集有很好的預測還不夠,真正的目標是對新實例預測的性能。有兩種歸納方法:基于實例和基于模型學習。
基于實例學習
也許最簡單的學習形式就是用記憶學習。如果用這種方法做一個垃圾郵件過濾器。只需要標記所有和用戶標記的垃圾郵件相同的郵件----這個方法不差,但肯定不是最好的。
不僅能標記和已知的垃圾郵件相同的郵件,你的垃圾郵件過濾器也要能標記類似垃圾郵件的郵件。這就需要測量兩封郵件的相似性。一個(簡單的)相似度測量方法是統計兩封郵件包含的相同單詞的數量。如果一封郵件含有許多垃圾郵件中的詞,就會被標記為垃圾郵件。
這被稱作基于實例學習:系統先用記憶學習案例,然后使用相似度測量推廣到新的例子

圖10 基于實例學習
基于模型學習
另一種從樣本集進行歸納的方法,是建立這些樣本的模型,然后使用這個模型進行預測。這稱作基于模型學習。
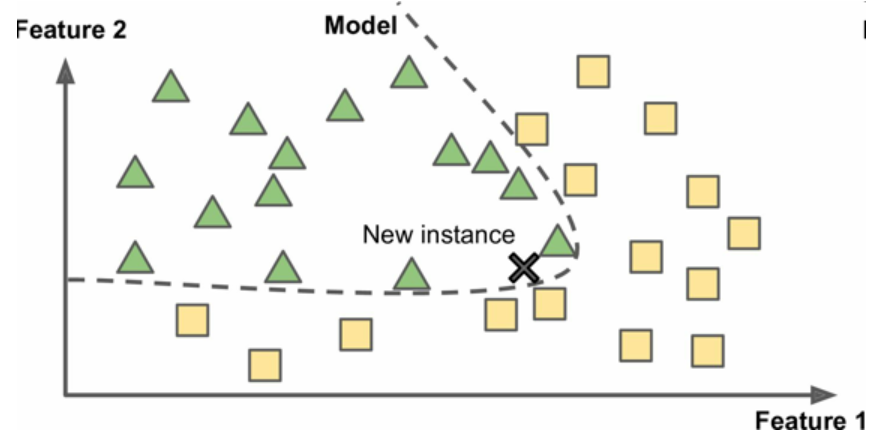
圖11 基于模型學習
例如,你想知道錢是否能讓人快樂,你從 OECD 網站下載了 Better Life Index 指數數據,還從 IMF 下載了人均 GDP 數據。表 1-1 展示了摘要。

?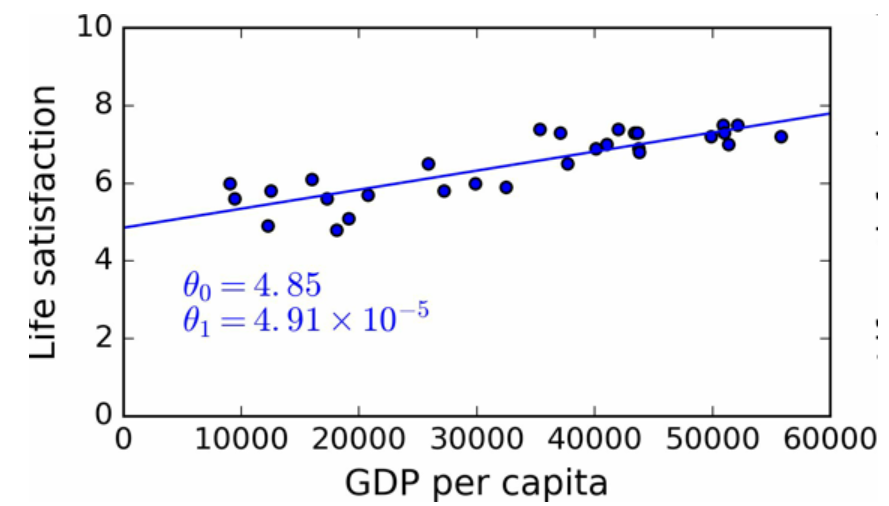
圖12 最佳擬合訓練數據的線性模型
最后,可以準備運行模型進行預測了。例如,假如你想知道塞浦路斯人有多幸福,但 OECD 沒有它的數據。幸運的是,你可以用模型進行預測:查詢塞浦路斯的人均 GDP,為 22587 美元,然后應用模型得到生活滿意度,后者的值在4.85 + 22,587 × 4.91 × 10-5 = 5.96左右。
案例 1-1 展示了加載數據、準備、創建散點圖的 Python 代碼,然后訓練線性模型并進行預測。
案例 1-1,使用 Scikit-Learn 訓練并運行線性模型。
import matplotlib import matplotlib.pyplot as plt import numpy as np import pandas as pd import sklearn # 加載數據 oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',') gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',encoding='latin1', na_values="n/a") # 準備數據 country_stats = prepare_country_stats(oecd_bli, gdp_per_capita) X = np.c_[country_stats["GDP per capita"]] y = np.c_[country_stats["Life satisfaction"]] # 可視化數據 country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction') plt.show() # 選擇線性模型 lin_reg_model = sklearn.linear_model.LinearRegression() # 訓練模型 lin_reg_model.fit(X, y) # 對塞浦路斯進行預測 X_new = [[22587]] # 塞浦路斯的人均GDP print(lin_reg_model.predict(X_new)) # outputs [[ 5.96242338]]
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
TemplateRef和ViewContainerRef)

ViewChild和ViewChildren)

ContentChild和ContentChildren)
屬性型指令)

結構型指令)




DI提供者)
生命周期)
![[轉載]httpClient.execute拋Connection to refused異常問題](http://pic.xiahunao.cn/[轉載]httpClient.execute拋Connection to refused異常問題)
依賴注入)



