文章目錄
- 1、操作系統的選擇
- 1.1、I/O 模型的使用
- 1.2、數據網絡傳輸效率
- 1.3、社區支持度
- 2、磁盤的選擇
- 3、磁盤容量的規劃
- 3.1、舉例思考本問題:
- 3.2、計算一下:
- 3.3、規劃磁盤容量時你需要考慮下面這幾個元素:
- 4、帶寬規劃
- 4.1、計算
- 總結
1、操作系統的選擇
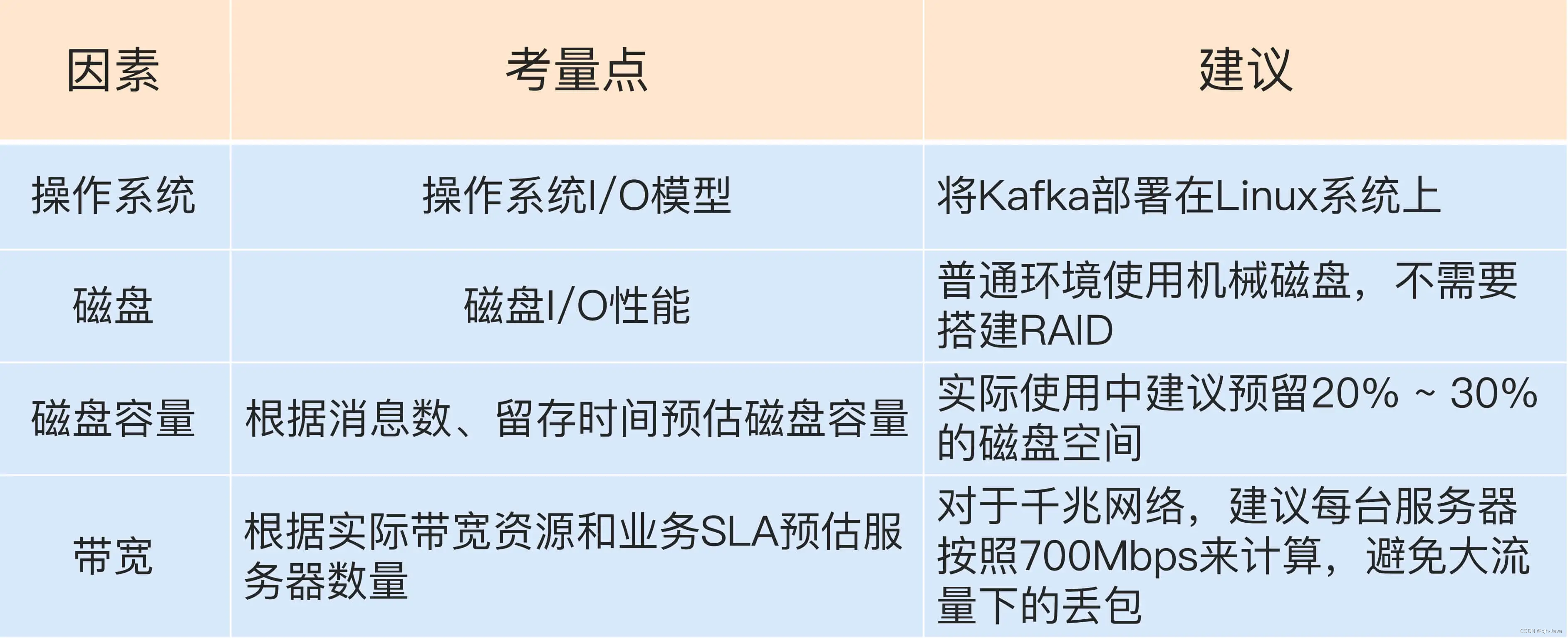
對比 Linux、Mac、Window,Linux 系統顯然要更加適合部署 Kafka。主要有下面這三個方面,Linux 的表現更勝一籌。
1.1、I/O 模型的使用
主流的 I/O 模型通常有 5 種類型:阻塞式 I/O、非阻塞式 I/O、I/O 多路復用、信號驅動 I/O 和異步 I/O。
通常情況下我們認為后一種模型會比前一種模型要高級。
相關實現場景,比如 Java 中 Socket 對象的阻塞模式和非阻塞模式就對應于前兩種模型;而 Linux 中的系統調用 select 函數就屬于 I/O 多路復用模型;大名鼎鼎的 epoll 系統調用則介于第三種和第四種模型之間;至于第五種模型,其實很少有 Linux 系統支持,反而是 Windows 系統提供了一個叫 IOCP 線程模型屬于這一種。
那么 I/O 模型與 Kafka 的關系又是什么呢?Kafka 客戶端底層使用了 Java 的 selector,selector 在 Linux 上的實現機制是 epoll,而在 Windows 平臺上的實現機制是 select。因此在這一點上將 Kafka 部署在 Linux 上是有優勢的,因為能夠獲得更高效的 I/O 性能。
1.2、數據網絡傳輸效率
Kafka 生產和消費的消息都是通過網絡傳輸的,而消息保存在哪里呢?肯定是磁盤。故 Kafka 需要在磁盤和網絡間進行大量數據傳輸。Linux 有個零拷貝(Zero Copy)技術,就是當數據在磁盤和網絡進行傳輸時避免昂貴的內核態數據拷貝從而實現快速的數據傳輸。Linux 平臺實現了這樣的零拷貝機制,但有些令人遺憾的是在 Windows 平臺上必須要等到 Java 8 的 60 更新版本才能 “享受” 到這個福利。
一句話總結一下,在 Linux 部署 Kafka 能夠享受到零拷貝技術所帶來的快速數據傳輸特性。
1.3、社區支持度
社區目前對 Windows 平臺上發現的 Kafka Bug 不做任何承諾。雖然口頭上依然保證盡力去解決,但根據我的經驗,Windows 上的 Bug 一般是不會修復的。因此,Windows 平臺上部署 Kafka 只適合于個人測試或用于功能驗證,千萬不要應用于生產環境。
2、磁盤的選擇
磁盤資源對 Kafka 性能影響尤其突出,那應該選擇普通的機械磁盤還是固態硬盤?
- 機械磁盤成本低且容量大,但易損壞;
- 固態硬盤性能優勢大,不過單價高。
建議是使用普通機械硬盤即可
- Kafka 大量使用磁盤不假,可它使用的方式多是順序讀寫操作,一定程度上規避了機械磁盤最大的劣勢,即隨機讀寫操作慢。從這一點上來說,使用 SSD 似乎并沒有太大的性能優勢,畢竟從性價比上來說,機械磁盤物美價廉
- 機械磁盤因易損壞而造成的可靠性差等缺陷,又由 Kafka 在軟件層面提供機制來保證
3、磁盤容量的規劃
Kafka 集群到底需要多大的存儲空間?Kafka 需要將消息保存在底層的磁盤上,這些消息默認會被保存一段時間然后自動被刪除。 雖然這段時間是可以配置的,但你應該如何結合自身業務場景和存儲需求來規劃Kafka集群的存儲容量呢?
3.1、舉例思考本問題:
- 假設你所在公司有個業務每天需要向 Kafka 集群發送 1 億條消息,
- 每條消息保存兩份以防止數據丟失,
- 另外消息默認保存兩周時間。
現在假設消息的平均大小是 1KB,那么你能說出你的 Kafka 集群需要為這個業務預留多少磁盤空間嗎?
3.2、計算一下:
- 每天 1 億條 1KB 大小的消息,保存兩份且留存兩周的時間,那么總的空間大小就等于 1 億 * 1KB * 2 / 1000 / 1000 = 200GB。
- 一般情況下 Kafka 集群除了消息數據還有其他類型的數據,比如索引數據等,故我們再為這些數據預留出 10% 的磁盤空間,因此總的存儲容量就是 220GB。
- 既然要保存兩周,那么整體容量即為 220GB * 14,大約 3TB 左右。
- Kafka 支持數據的壓縮,假設壓縮比是 0.75,那么最后你需要規劃的存儲空間就是 0.75 * 3 = 2.25TB。
3.3、規劃磁盤容量時你需要考慮下面這幾個元素:
- 新增消息數
- 消息留存時間
- 平均消息大小
- 備份數
- 是否啟用壓縮
4、帶寬規劃
對于Kafka這種通過網絡進行大數據傳輸的框架,帶寬容易成為瓶頸。 普通的以太網絡,帶寬主要有兩種:1Gbps的千兆網絡和10Gbps的萬兆網絡,特別是千兆網絡應該是一般公司網絡的標準配置了 以千兆網絡為例,說明帶寬資源規劃。
真正要規劃的是所需的Kafka服務器的數量。 假設機房環境是千兆網絡,即1Gbps,現在有業務,其目標或SLA是在1小時內處理1TB的業務數據。 那么問題來了,你到底需要多少臺Kafka服務器來完成這個業務呢?
4.1、計算
帶寬是 1Gbps,即每秒處理 1Gb 的數據,假設每臺 Kafka 服務器都是安裝在專屬的機器上,也就是說每臺 Kafka 機器上沒有混布其他服務,畢竟真實環境中不建議這么做。通常情況下你只能假設 Kafka 會用到 70% 的帶寬資源,因為總要為其他應用或進程留一些資源。超過 70% 的閾值就有網絡丟包的可能性了,故 70% 的設定是一個比較合理的值,也就是說單臺 Kafka 服務器最多也就能使用大約 700Mb 的帶寬資源。
這只是它能使用的最大帶寬資源,你不能讓 Kafka 服務器常規性使用這么多資源,故通常要再額外預留出 2/3 的資源,即單臺服務器使用帶寬 700Mb / 3 ≈ 240Mbps。需要提示的是,這里的 2/3 其實是相當保守的,你可以結合你自己機器的使用情況酌情減少此值。
有了 240Mbps,我們就可以計算 1 小時內處理 1TB 數據所需的服務器數量了。根據這個目標,我們每秒需要處理 2336Mb 的數據,除以 240,約等于 10 臺服務器。如果消息還需要額外復制兩份,那么總的服務器臺數還要乘以 3,即 30 臺。
總結
所謂 “兵馬未動,糧草先行”。與其盲目上馬一套 Kafka 環境然后事后費力調整,不如在一開始就思考好實際場景下業務所需的集群環境。在考量部署方案時需要通盤考慮,不能僅從單個維度上進行評估。

)
)







)
)






)
