目錄
1.Spark 概念
2. Hadoop和Spark的對比
3. Spark特點
3.1?運行速度快
3.2 簡單易用
3.3?通用性強
3.4?可以允許運行在很多地方
4. Spark框架模塊
4.1 Spark Core
4.2?SparkSQL
4.3?SparkStreaming
4.4?MLlib
4.5?GraphX
5. Spark的運行模式
5.1 本地模式(單機) Local運行模式
5.2 Standalone模式(集群)
5.3 HadoopYARN模式(集群)
5.4 Kubernetes模式(容器集群)
5.5?云服務模式(運行在云平臺上)
6. Spark架構
6.1 在Spark中任務運行層面
6.2 在Spark中資源層面
1.Spark 概念
- 定義:Apache Spark 是用于大規模數據處理的統一分析引擎
- 其特點就是對任意類型的數據進行自定義計算。
- Spark可以計算:結構化、半結構化、非結構化等各種類型的數據結構,同時也支持使用Python、Java、Scala、R以及SQL語言去開發應用程序計算數據。
- Spark的適用面非常廣泛,所以,被稱之為統一的(適用面廣)的分析引擎(數據處理)
- Spark最早源于一篇論文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, 該論文是由加州大學柏克萊分校的Matei Zaharia等人發表的。論文中提出了一種彈性分布式數據集(即RDD)的概念。
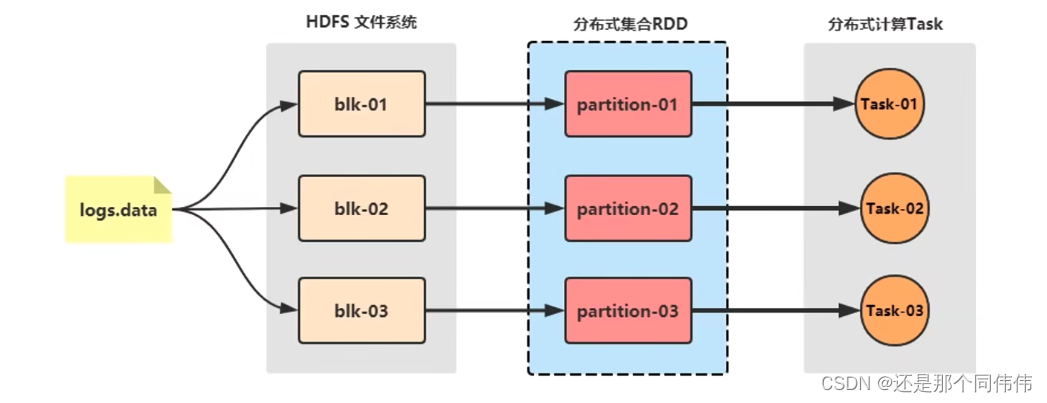
- RDD是一種分布式內存抽象,其使得程序員能夠在大規模集群中做內存運算,并且有一定的容錯方式。而這也是整個Spark的核心數據結構,Spark整個平臺都圍繞著RDD進行。
2. Hadoop和Spark的對比
盡管Spark相對于Hadoop而言具有較大優勢,但Spark并不能完全替代Hadoop
- 在計算層面,Spark相比較MR(MapReduce)有巨大的性能優勢,但至今仍有許多計算工具基于MR構架,比如非常成熟的Hive
- Spark僅做計算,而Hadoop:生態圈不僅有計算(MR)也有存儲(HDFS)和資源管理調度(YARN),HDFS和YARN仍是許多大數據體系的核心架構。
3. Spark特點
3.1?運行速度快
Spark處理數據與MapReduce處理數據相比,有如下兩個不同點:
- Spark處理數據時,可以將中間處理結果數據存儲到內存中;
- Spark提供了非常豐富的算子(APi),可以做到復雜任務在一個Spark程序中完成.
3.2 簡單易用
3.3?通用性強
3.4?可以允許運行在很多地方
4. Spark框架模塊
4.1 Spark Core
Spark的核心,Spark核心功能均由SparkCore模塊提供,是Spark:運行的基礎。
SparkCorel以RDD為數據抽象,提供Python、Java、Scala、R語言的API,可以編程進行海量離線數據批處理計算。
4.2?SparkSQL
基于SparkCore之上,提供結構化數據的處理模塊。
SparkSQL支持以sQL語言對數據進行處理,SparkSQL本身針對離線計算場景。
同時基于SparkSQL,Spark提供了StructuredStreaming模塊,可以以SparkSQL為基礎,進行數據的流式計算。
4.3?SparkStreaming
以SparkCore為基礎,提供數據的流式計算功能。
4.4?MLlib
以SparkCore為基礎,進行機器學習計算,內置了大量的機器學習庫和APi算法等。方便用戶以分布式計算的模式進行機器學習計算。
4.5?GraphX
以SparkCore為基礎,進行圖計算,提供了大量的圖計算APl,方便用于以分布式計算模式進行圖計算。
5. Spark的運行模式
5.1 本地模式(單機) Local運行模式
本地模式就是以一個獨立的進程,通過其內部的多個線程來模擬整個Spark運行時的環境
5.2 Standalone模式(集群)
Spark中的各個角色以獨立進程的形式存在,并組成Spark:集群環境
5.3 HadoopYARN模式(集群)
Spark中的各個角色運行在YARN的容器內部,并組成Spark集群環境??
5.4 Kubernetes模式(容器集群)
Spark中的各個角色運行在Kubernetesl的容器內部,并組成Spark:集群環境
5.5?云服務模式(運行在云平臺上)
6. Spark架構
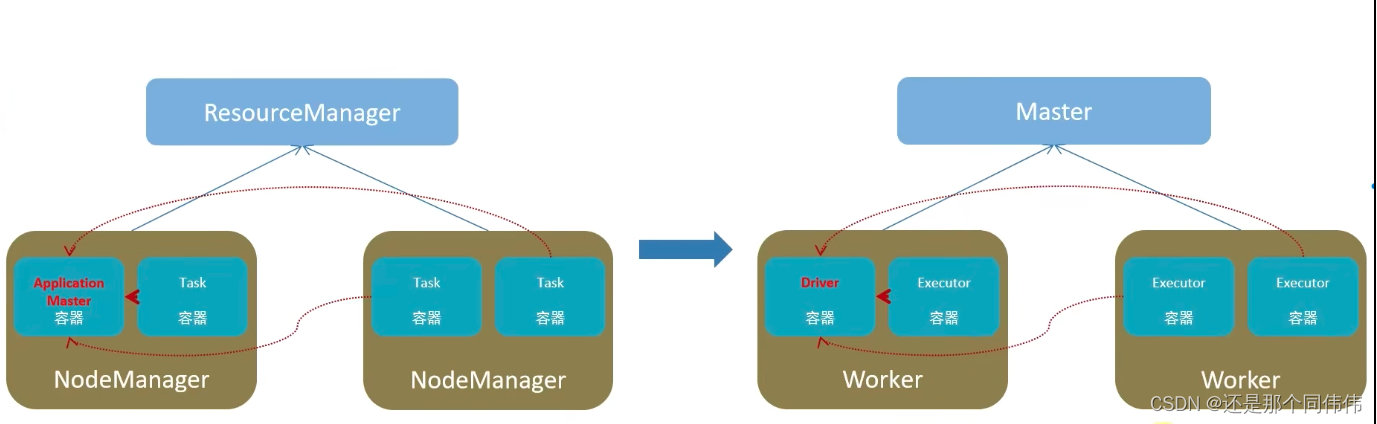
左邊是YARN框架,右邊是Spark框架
6.1 在Spark中任務運行層面
- Driver, 負責對一個任務的運行進行管理(單個任務的管理)
- ?Executor,單個任務的計算(干活的)
- 正常情況下Executor是干活的角色,不過特殊場景下,(local模式)Driver可以即管又干活
6.2 在Spark中資源層面:
- Master角色:集群資源管理
- Worker的角色: 單機資源管理
Spark與PySpark(1.概述、框架、模塊)


本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/214995.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/214995.shtml 英文地址,請注明出處:http://en.pswp.cn/news/214995.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

初識Vue 解決vue在啟動時生成的提示
讓我為大家簡單介紹一下吧! Vue是一套用于構建用戶界面的漸進式javaScript框架
當我們引入vue.js后
<script src"../js/vue.js"></script>我們發現,當我們打開網頁時,控制臺會出現以下內容
那我們該怎么解決呢&…

【設計模式--結構型--組合模式】
設計模式--結構型--組合模式 組合模式定義結構案例組合模式的分類優點使用場景 組合模式
定義
又稱部分整體模式,是用于把一組相似的對象當作一個單一的對象。組合模式依據樹型結構來組合對象,用來表示部分以及整體層次,這種類型的設計模式…

新增模板中心和系統設置模塊,支持飛書平臺對接,DataEase開源數據可視化分析平臺v2.1.0發布
這一版本的功能升級包括:新增模板中心,用戶可以通過模板中心的模板快速創建儀表板和數據大屏;新增“系統設置”功能模塊,該模塊包含系統參數、認證設置、嵌入式管理、平臺對接四個子模塊。在“系統參數”子模塊中,用戶…

代碼上傳的gitee平臺
1.首先我們訪問工作臺 - Gitee.com進行注冊和登錄
2.我們創建一個倉庫: 3.在本地創建我們的項目 在這文件夾里面我們打開git bush,執行 一下操作:
git init :初始化倉庫
git status:檢查狀態
git add . :將當前文件…

ubuntu 命令行安裝 conda
安裝包地址:
Index of /
找到對應的版本,右鍵點復制鏈接 wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.shbash Anaconda3-2023.09-0-Linux-x86_64.sh https://linzhji.blog.csdn.net/article/details/126530244

BERT大模型:英語NLP的里程碑
BERT的誕生與重要性
BERT(Bidirectional Encoder Representations from Transformers)大模型標志著自然語言處理(NLP)領域的一個重要轉折點。作為首個利用掩蔽語言模型(MLM)在英語語言上進行預訓練的模型&…
)
Keepalived+Nginx實現高可用(上)
一、背景與簡介 為了服務的高可用性,避免單點故障問題,通常我們使用"冗余設計思想"進行架構設計。冗余設計思想,本質就是將同一個應用或者服務放置在多臺不同的服務器上[雞蛋不放在同一個籃子里],這樣減少整體服務宕機的…
 725.完全數)
ACWing week 3(C語言) 725.完全數
一個整數,除了本身以外的其他所有約數的和如果等于該數,那么我們就稱這個整數為完全數。
例如,66 就是一個完全數,因為它的除了本身以外的其他約數的和為 1236
現在,給定你 N 個整數,請你依次判斷這些數是…

ESP32網絡開發實例-搭建ESP32固件遠程升級服務器
搭建ESP32固件遠程升級服務器 文章目錄 搭建ESP32固件遠程升級服務器1、ESP32設備自動升級流程2、軟件準備3、硬件準備4、代碼實現4.1 固件升級服務器代碼實現4.2 基礎固件代碼4.3 新固件代碼實現我們在前面的文章中,已經實現了OTA方式升級固件的兩種方式:在Arduino IDE 中升…

數據結構與算法-動態規劃-機器人達到指定位置方法數
機器人達到指定位置方法數
來自左程云老師書中的一道題
【題目】
假設有排成一行的 N 個位置,記為 1~N,N 一定大于或等于 2。開始時機器人在其中的 M
位置上(M 一定是 1~N 中的一個),機器人可以往左走或…

基于大語言模型的復雜任務認知推理算法CogTree
近日,阿里云人工智能平臺PAI與華東師范大學張偉教授團隊合作在自然語言處理頂級會議EMNLP2023上發表了基于認知理論所衍生的CogTree認知樹生成式語言模型。通過兩個系統:直覺系統和反思系統來模仿人類產生認知的過程。直覺系統負責產生原始問題的多個分解…

10 # 類:繼承和成員修飾符
類的基本實現
類的成員屬性都是實例屬性,而不是原型屬性,類的成員方法都是原型方法。
class Dog {constructor(name: string) {this.name name;}name: string;run() {}
}console.log(Dog.prototype);
let dog new Dog("wangwang");
consol…
———mysql比較varchar值大小_Mysql varchar大小長度問題)
知識筆記(五十四)———mysql比較varchar值大小_Mysql varchar大小長度問題
1、限制規則
字段的限制在字段定義的時候有以下規則:
a) 存儲限制
varchar 字段是將實際內容單獨存儲在聚簇索引之外,內容開頭用1到2個字節表示實際長度(長度超過255時需要2個字節),因此最大長度不能超過65535。
b) 編碼長度限制
字符類…

低功耗模式的通用 MCU ACM32F0X0 系列,具有高整合度、高抗干擾、 高可靠性的特點
ACM32F0X0 系列是一款支持多種低功耗模式的通用 MCU。集成 12 位 1.6 Msps 高精度 ADC 以及比 較器、運放、觸控按鍵控制器、段式 LCD 控制器,內置高性能定時器、多路 UART、LPUART、SPI、I2C 等豐富的通訊外設,內建 AES、TRNG 等信息安全模塊࿰…

kubeadm搭建單master多node的k8s集群--小白文,圖文教程
參考文獻
K8S基礎知識與集群搭建 kubeadm搭建單master多node的k8s集群—主要參考這個博客,但是有坑,故貼出我自己的過程,坑會少很多 注意:
集群配置是:一臺master:zabbixagent-k8smaster,兩臺…
綜合示例)
C++類和對象——(10)綜合示例
一、示例對象數組:
#include<iostream>
using namespace std;class Point{private:int x,y;public:Point(int px0,int py0){xpx;ypy;}void init(int px0,int py0){xpx;ypy;}void print(){cout<<"("<<x<<","<<y…

FFmpeg的AVInputFormat
文章目錄 結構體定義操作函數支持的AVOutputFormat 通過上面的分析,基本可以看到ffmpeg的套路了,首先一個context上下文,上下文里面一個priv_data 指針,然后再插件結構體中有一個priv_data_size,然后回調函數。
結構體…

JVM-GC調優-字節碼篇-01
筆記來源:JVM
注意:實在想學習可以看一下,讓自己更加了解JVM,看起來可能會枯燥。
JVM-概述
1、你的問題 1.1你被JVM傷害過嗎? 你是否也遇到過這些問題?
運行著的線上系統突然卡死,系統無法訪…


HTML中如何設置音頻和視頻?
文章目錄 🔊嵌入音頻🎞?嵌入視頻 🔊嵌入音頻 HTML 元素用于在文檔中嵌入音頻內容。 元素可以包含一個或多個音頻資源, 這些音頻資源可以使用 src 屬性或者 元素來進行描述:瀏覽器將會選擇最合適的一個來使用。也可以使…