前言: 大家對StarRocks 的了解可能不及 ClickHouse或者是遠不及 ClickHouse?。但是大家可能聽說過 Doris ,而 StarRocks 實際上原名叫做 Doris DB ,他相當于是一個加強版的也就是一個 Doris+ ,也就是說 Doris 所有的功能 StarRocks 都是有的,但是 StarRocks 有的這種加速的功能 Doris 目前是沒有的。我們可以基于 Apache Doris 統一 OLAP 技術棧,滿足龐大數據體量下的實時分析與極速查詢。
1、什么是StarRocks?
StarRocks原名DorisDB,StarRocks 是 Apache Doris 的 Fork 版本。StarRocks 是新一代極速全場景 MPP (Massively Parallel Processing) 數據庫。StarRocks 是一款高性能分析型數據倉庫,使用向量化、MPP 架構、CBO、智能物化視圖、可實時更新的列式存儲引擎等技術實現多維、實時、高并發的數據分析。StarRocks 既支持從各類實時和離線的數據源高效導入數據,也支持直接分析數據湖上各種格式的數據。StarRocks 兼容 MySQL 協議,可使用 MySQL 客戶端和常用 BI 工具對接。同時 StarRocks 具備水平擴展,高可用、高可靠、易運維等特性。廣泛應用于實時數倉、OLAP 報表、數據湖分析等場景。
StarRocks 架構簡潔,采用了全面向量化引擎,并配備全新設計的 CBO (Cost Based Optimizer) 優化器,查詢速度(尤其是多表關聯查詢)遠超同類產品。
-
StarRocks 能很好地支持實時數據分析,并能實現對實時更新數據的高效查詢。StarRocks 還支持現代化物化視圖,進一步加速查詢。
-
多分布式 Join極速引擎,這個分布式?Join 目前就是 ClickHouse?比較缺乏的一個功能。如果了解 spark 或者了解 presto 的話,其實都應該知道這都是有的,就是說這個其實就是做 Shuffle ,就是把不同的 Key 給 Shuffle 到同一個 bucket 里邊,然后再去做 Join ,然后右邊實際上是一個更加高效的一種 Join 方式也就是提前的去做好了這個 bucket 的分類,也就是說同一個 Key,兩張表相同的 Key ,全部落到同一個 bucket 的范圍,然后這個 bucket 的之間肯定是沒有 over lap ,所以可以放心的做這個Colocate ?joy ,在這個 spark 里面也叫 bucket join 。
-
使用 StarRocks,用戶可以靈活構建包括大寬表、星型模型、雪花模型在內的各類模型。
-
StarRocks 兼容 MySQL 協議,支持標準 SQL 語法,易于對接使用,全系統無外部依賴,高可用,易于運維管理。StarRocks 還兼容多種主流 BI 產品,包括 Tableau、Power BI、FineBI 和 Smartbi。
2、使用Doris替換ClickHouse、Kylin和Druid
這里有一家電子商務SaaS提供商,其數據系統提供實時和離線報告、客戶分割和日志分析服務。最初,他們為這些不同的目的使用了不同的OLAP引擎:
-
Apache Kylin用于離線報告:該系統為超過500萬個賣家提供離線報告服務。其中的大型賣家擁有超過1000萬注冊會員和100,000個SKU,詳細信息放在平臺上的400多個數據立方體中。
-
ClickHouse用于客戶分割和Top-N日志查詢:這需要高頻更新、高QPS和復雜的SQL。
-
Apache Druid用于實時報告:賣家通過組合不同的維度提取所需的數據,這種實時報告需要快速的數據更新、快速的查詢響應和系統的強大穩定性。
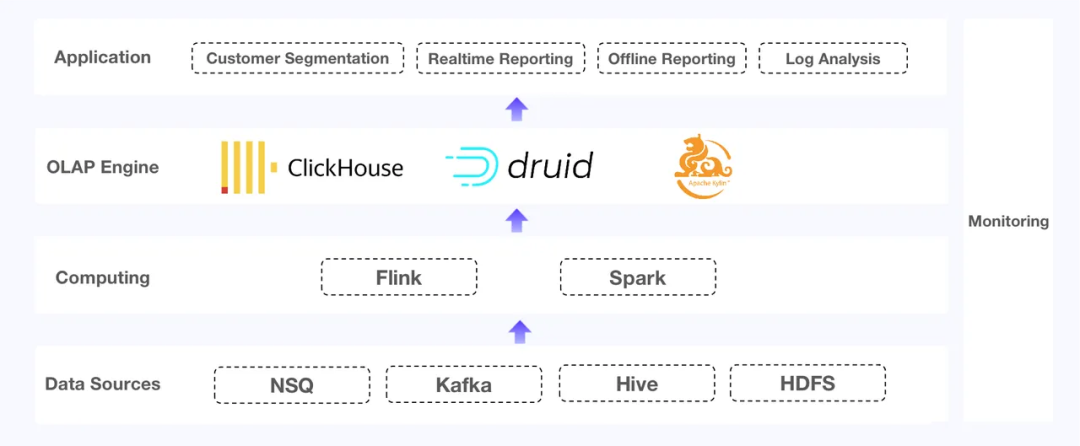
這三個組件都有各自的痛點:
-
Apache Kylin在固定表模式下運行良好,但每次添加維度時,需要創建一個新的數據立方體并在其中重新填充歷史數據。
-
ClickHouse不適用于多表join處理,因此需要額外的解決方案來進行聯合查詢和多表連接查詢。在高并發場景下,它的表現低于預期。
-
Apache Druid實現了冪等寫入,因此它本身不支持數據更新或刪除。這意味著當上游出現問題時,需要進行完整的數據替換。如果您從頭到尾考慮所有數據備份和移動,這樣的數據修復是一個多步驟的過程。此外,新攝入的數據在放入Druid中的段之前將無法用于查詢。這意味著存在更長的時間窗口,從而導致上下游之間的數據不一致。
由于它們共同工作,這種架構可能太難以維護,因為它需要在開發、監控和維護方面了解所有這些組件。此外,每次用戶擴展集群時,他們必須停止當前集群并遷移所有數據庫和表,這不僅是一個巨大的任務,而且會對業務造成巨大的干擾。基于上述架構痛點,友贊對市面上的架構進行了調研與選型,希望選擇一款能夠簡化當前復雜架構、統一 OLAP 技術棧的引擎。他們除了分析 OLAP 性能本身對于業務的幫助,還需要評估架構改造所帶來的收益成本比,思考架構進行遷移和重構之后所帶來的 ROI 是否符合預期。
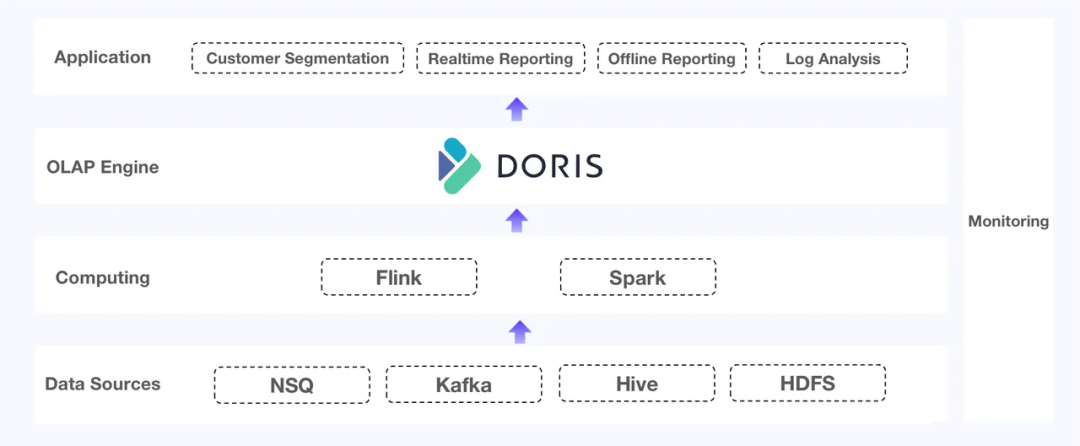
Apache Doris填補了這些空白。
-
查詢性能:Doris擅長高并發查詢和JOIN連接查詢,并且現在配備了倒排索引以加速日志搜索。
-
數據更新:Doris的唯一鍵模型支持大容量更新和高頻實時寫入,而重復鍵模型和唯一鍵模型支持部分列更新。它還提供數據寫入的恰好一次保證,并確保基表、物化視圖和副本之間的一致性。
-
維護:Doris與MySQL兼容。它支持輕松擴展和輕量級模式更改。它配備了自己的集成工具,如Flink-Doris-Connector和Spark-Doris-Connector。

3、?StarRocks和ClickHouse壓測性能對比
這里比較了兩個組件在SQL和連接查詢方案上的性能,并計算了Apache Doris的CPU和內存消耗。
2.1 SQL查詢性能
Apache Doris在16個SQL查詢中的10個中表現優于ClickHouse,最大的性能差距比例接近30。總體而言,Apache Doris比ClickHouse快2~3倍。
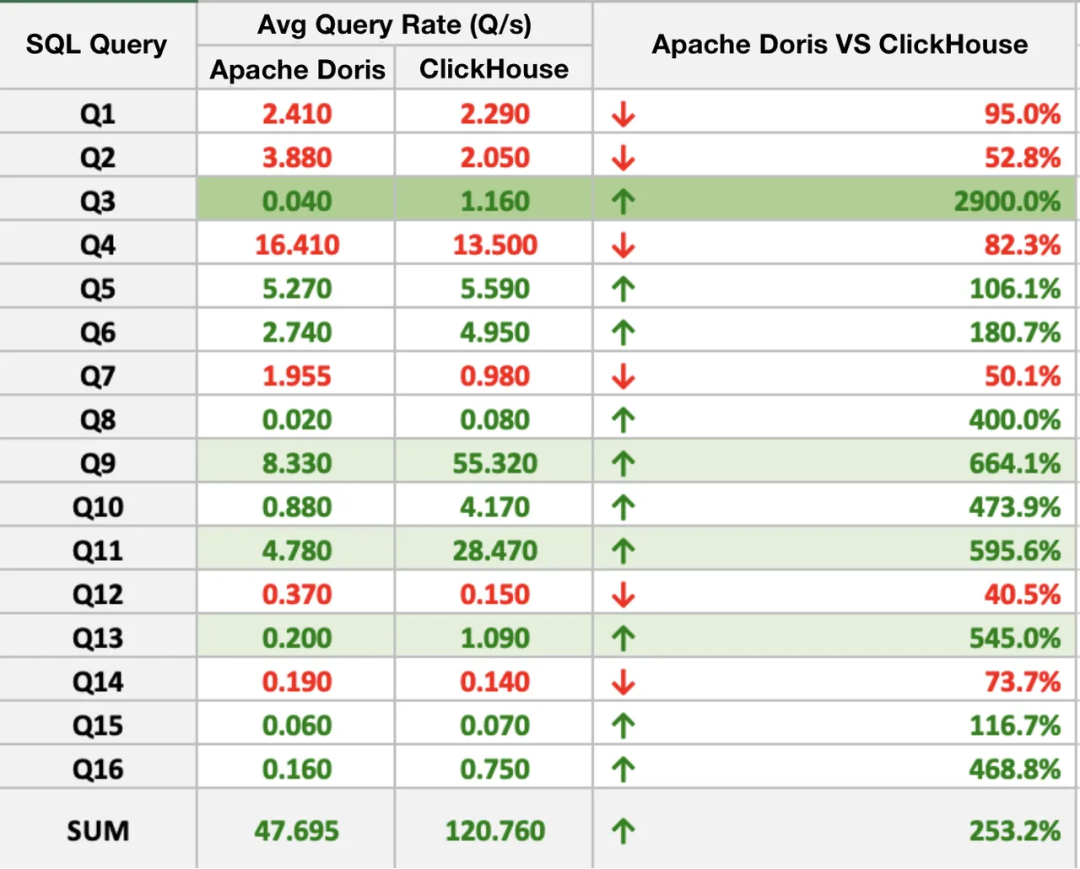
2.2 連接查詢性能
對于連接查詢測試,使用了不同大小的主表和維表。
-
主表:用戶活動表(40億行)、用戶屬性表(250億行)和用戶屬性表(960億行)
-
維表:100萬行、1000萬行、5000萬行、1億行、5億行、10億行和25億行。
測試包括完全連接查詢和過濾連接查詢。完全連接查詢連接主表和維表的所有行,而過濾連接查詢使用WHERE過濾器檢索特定賣家ID的數據。結果如下:
主表(40億行):
-
完全連接查詢:Doris在所有維表的完全連接查詢中均優于ClickHouse。隨著維表變大,性能差距越來越大。最大的差距比例接近5。
-
過濾連接查詢:基于賣家ID,過濾器從主表中篩選出了4100萬行。對于小型維表,Doris比ClickHouse快2~3倍;對于大型維表,Doris比ClickHouse快10倍以上;對于大于1億行的維表,ClickHouse會拋出OOM錯誤,而Doris則正常運行。
主表(250億行):
-
完全連接查詢:Doris在所有維表的完全連接查詢中均優于ClickHouse。ClickHouse在維表大于5000萬行時會產生OOM錯誤。
-
過濾連接查詢:過濾器從主表中篩選出了5.7億行。Doris在幾秒鐘內響應,而ClickHouse在連接大型維表時完成時間為幾分鐘,并在此過程中崩潰。
主表(960億行):
Doris在所有查詢中都表現出相對較快的性能,而ClickHouse無法執行所有查詢。
在CPU和內存消耗方面,Apache Doris在所有大小的連接查詢中都保持穩定的集群負載。
參考鏈接:
從 Clickhouse 到 Apache Doris:有贊業務場景下性能測試與遷移驗證
開源大數據 OLAP 引擎最佳實踐 | 學習筆記(二)-阿里云開發者社區








)


)




![[三次反轉法]循環移動數組元素](http://pic.xiahunao.cn/[三次反轉法]循環移動數組元素)


)