目錄
一、機器學習中的分類算法
1.1 基礎分類算法
1.2 集成分類算法
1.3 其它分類算法:
二、各種機器學習分類算法的優缺點
?
分類算法也稱為模式識別,是一種機器學習算法,其主要目的是從數據中發現規律并將數據分成不同的類別。分類算法通過對已知類別訓練集的計算和分析,從中發現類別規則并預測新數據的類別。常見的分類算法包括決策樹、樸素貝葉斯、邏輯回歸、K-最近鄰、支持向量機等。分類算法廣泛應用于金融、醫療、電子商務等領域,以幫助人們更好地理解和利用數據。
本文介紹15種機器學習中的分類算法,并介紹相關的優缺點,在使用時可以根據優缺點選擇合適的算法。
?本文部分圖文借鑒自《老餅講解-機器學習》
一、機器學習中的分類算法
機器學習中常用的用于做分類的算法如下:
1.1 基礎分類算法
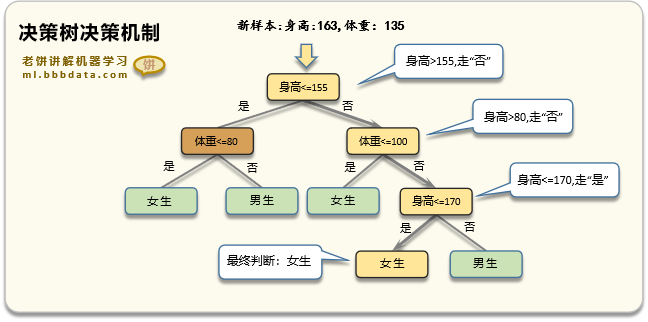
1.決策樹:決策樹算法通過將數據集劃分為不同的子集來預測目標變量。它從根節點開始,根據某個特征對數據集進行劃分,然后遞歸地生成更多的子節點,直到滿足停止條件為止。決策樹的每個內部節點表示一個特征屬性上的判斷條件,每個分支代表一個可能的屬性值,每個葉節點表示一個分類結果。
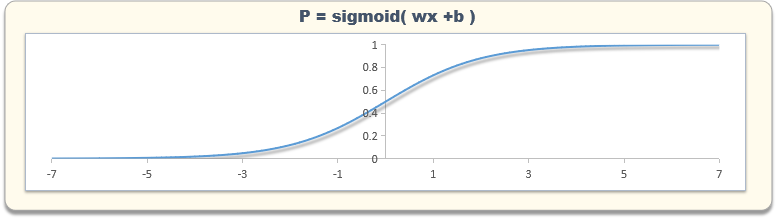
2.邏輯回歸:邏輯回歸算法是一種用于二元分類的算法,它通過使用邏輯函數將線性回歸的結果映射到[0,1]范圍內。邏輯回歸模型將輸入特征與輸出類別之間的關系表示為線性回歸函數,然后通過邏輯函數將線性回歸的結果轉換為一個概率值,用于預測目標變量。邏輯回歸的優點是計算效率高,但在處理高維數據時可能會過擬合。
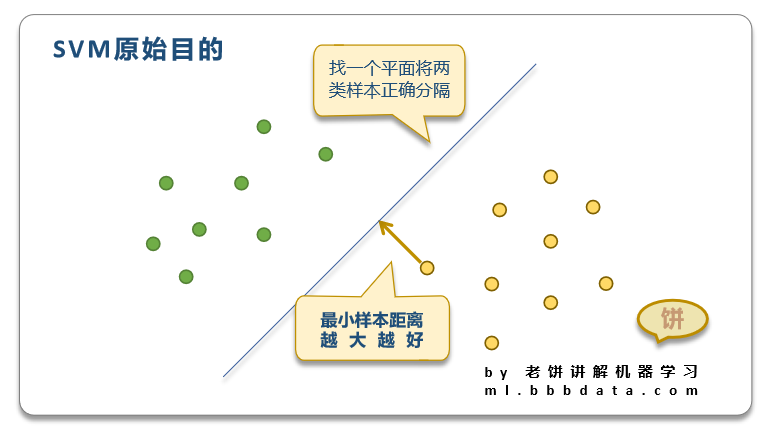
3.支持向量機(SVM):SVM算法通過找到一個超平面來劃分不同的類別。它試圖最大化兩個類別之間的邊界,這個邊界被稱為間隔。SVM的目標是找到一個能夠將數據集中的點正確分類的超平面,同時最大化間隔。在二分類問題中,SVM通過求解一個二次優化問題來找到這個超平面。
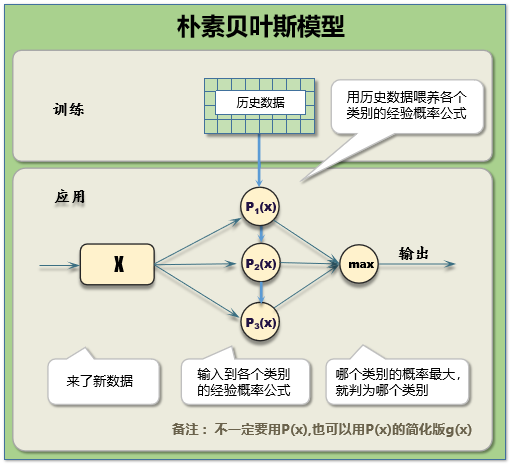
4.樸素貝葉斯:樸素貝葉斯算法是一種基于貝葉斯定理的分類算法,它通過計算每個類別的條件概率來預測目標變量。樸素貝葉斯算法假設每個特征之間是獨立的,然后根據這個假設來計算類別的條件概率,并選擇概率最大的類別作為預測結果。樸素貝葉斯的優點是在處理高維數據時效率高,并且對數據集的大小和分布不敏感。
5.K-最近鄰(KNN):KNN算法是一種基于實例的學習算法,它根據數據集中的距離度量將新的實例分類到最近的類別中。KNN算法根據距離度量計算待分類項與數據集中每個項的距離,然后選取距離最近的K個項,根據這K個項的類別進行投票,將得票最多的類別作為待分類項的預測類別。KNN的優點是簡單、易于理解和實現,但可能會受到數據集大小和維數的影響。
6.神經網絡:神經網絡是一種基于人工神經元的分類算法,它通過訓練神經元之間的連接權重來預測目標變量。神經網絡由多個神經元組成,每個神經元接收輸入信號并產生輸出信號,輸出信號通過連接權重與下一個神經元的輸入信號相乘得到新的輸入信號,最終的輸出信號由所有的神經元組成。神經網絡的優點是在處理復雜和非線性問題時表現良好,但需要大量的數據和計算資源來訓練模型。
7.貝葉斯網絡:貝葉斯網絡是一種基于概率論的分類算法,它通過建立條件獨立關系來構建網絡模型,并用于分類和概率推理。貝葉斯網絡的優點是在處理不確定性和概率推理時表現良好。
8.線性判別分析(Linear Discriminant Analysis,LDA):線性判別分析是一種基于判別函數的分類算法,它通過構建一個線性判別函數來劃分不同的類別。LDA的優點是在處理高維數據和多個類別時表現良好。
9.最大熵模型(Maximal Entropy Model):最大熵模型是一種基于概率論的分類算法,它通過最大化熵來構建模型,并用于分類和概率推理。最大熵模型的優點是在處理具有不確定性和噪聲的數據時表現良好。
1.2 集成分類算法
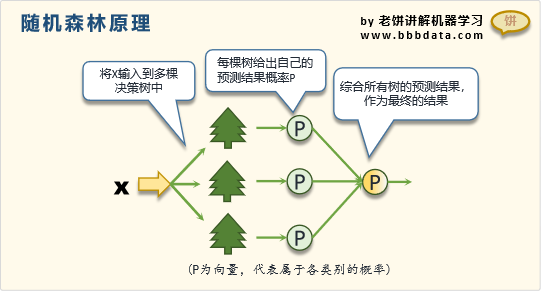
10.隨機森林:隨機森林算法基于決策樹算法,通過構建多個決策樹并組合它們的預測結果來提高分類精度。它通過隨機選擇樣本和特征來生成多個決策樹,然后以投票的方式將最多個數的結果作為最終分類結果。隨機森林的優點是可以處理高維數據,并且對數據集的大小和分布不敏感。
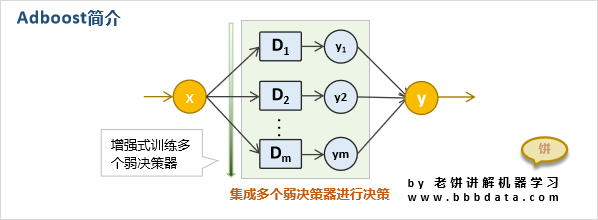
11.AdaBoost:AdaBoost是一種迭代算法,它通過將多個弱分類器的結果組合來預測目標變量。AdaBoost算法將數據集分成多個子集,然后針對每個子集訓練一個弱分類器,并調整每個弱分類器的權重,使得分類錯誤的樣本得到更大的權重,然后再次訓練弱分類器。如此反復迭代,直到達到預設的迭代次數或者弱分類器的精度達到某個閾值為止。最終的預測結果由所有弱分類器的加權和決定。AdaBoost的優點是可以處理多類分類問題,并且對噪聲和異常值不敏感。
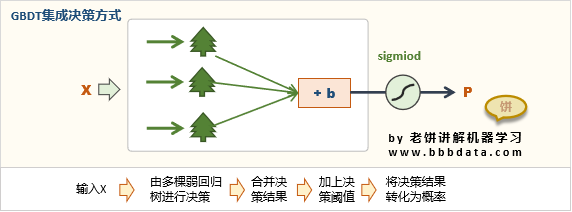
12.梯度提升決策樹(GBDT):GBDT算法是一種基于梯度提升的分類算法,它通過將多個決策樹的結果組合來預測目標變量。GBDT算法通過不斷地添加樹、更新模型參數和優化目標函數來提高模型的精度。每棵樹都是通過對樣本特征空間進行劃分、尋找最佳劃分點來生成的。每棵樹生成后,就對應一個殘差函數,用當前所有樹的殘差和作為下一棵樹的生成依據。如此反復迭代,直到達到預設的迭代次數或者滿足其他停止條件為止。最終的預測結果由所有樹的加權和決定。GBDT的優點是在處理復雜和非線性問題時表現良好,并且對數據集的大小和分布不敏感。
13.極端梯度提升(XGBoost):XGBoost算法是一種改進的梯度提升算法,它通過使用二階導數信息來優化損失函數。XGBoost算法在生成每棵樹時,不僅考慮了一階導數信息,還考慮了二階導數信息,從而能夠更好地擬合數據集。此外,XGBoost算法還引入了一個正則化項來控制模型的
1.3 其它分類算法:
14.決策樹樁(Decision Stump):決策樹樁是一種簡化版的決策樹算法,它只在一個層級上進行劃分,從而簡化模型的復雜度。決策樹樁的優點是在處理小型數據集和進行實時分類時效率高。
15.K-最近鄰樸素貝葉斯(K-Nearest Neighbor Naive Bayes):K-最近鄰樸素貝葉斯算法結合了K-最近鄰和樸素貝葉斯的原理,它通過計算每個類別的最近鄰數量來進行分類。K-最近鄰樸素貝葉斯的優點是在處理大規模數據集和進行實時分類時效率高。
二、各種機器學習分類算法的優缺點
上述分類算法的優缺點如下:
決策樹、隨機森林和梯度提升決策樹(GBDT):
這些算法都屬于集成學習方法,通過將多個弱學習器組合起來提高預測精度。它們能夠處理非線性問題,并且對數據量較大的數據集有較好的處理效果。但是,它們可能會過擬合訓練數據,導致泛化能力下降。此外,它們也需要較大的計算資源和時間來進行訓練。
支持向量機(SVM):
SVM是一種有堅實理論基礎的新穎的小樣本學習方法,它基本上不涉及概率測度及大數定律等,因此不同于現有的統計方法。SVM利用內積核函數代替向高維空間的非線性映射,能夠處理高維數據,并且不用降維。但是,SVM對特征空間劃分的最優超平面是未知的,因此需要人為設定一些參數。
邏輯回歸:
邏輯回歸是一種簡單易懂的分類算法,計算速度快,適用于小數據集。但是,它假設數據服從線性分布,因此對非線性問題處理效果不佳。另外,邏輯回歸對多重共線性數據較為敏感,可能導致模型不穩定。
K-最近鄰(KNN):
KNN是一種簡單且易于實現的分類算法,適用于小數據集和大規模數據集。但是,它對數據分布的敏感度較高,對于一些特殊的數據分布可能會導致較差的預測效果。
樸素貝葉斯:
樸素貝葉斯算法基于貝葉斯定理,對給定的問題能夠提供概率形式的決策支持。它能夠處理多類分類問題,并且對缺失數據和不完整數據的處理能力較強。然而,樸素貝葉斯算法假設特征之間相互獨立,這在實際應用中往往難以滿足。
神經網絡:
神經網絡具有較強的非線性擬合能力,可以處理復雜的模式識別和預測問題。它具有自學習、自組織和適應性等特點,可以處理大規模的數據集。但是,神經網絡的訓練過程較為復雜,需要大量的計算資源和時間。此外,神經網絡的參數較多,需要仔細調整才能獲得最佳的預測效果。
總的來說,不同的機器學習分類算法都有其優缺點,選擇哪種算法取決于具體的應用場景和問題特點。在選擇算法時,需要考慮數據的規模、特征的復雜性、模型的泛化能力、計算資源和時間等因素。
如果覺得本文有幫助,點個贊吧!



宿主機奔潰無法進入系統,lxc容器和虛擬機遷移,無備份,硬盤未損壞,記錄數據找回過程及思考)



![輸入一組數據,以-1結束輸入[c]](http://pic.xiahunao.cn/輸入一組數據,以-1結束輸入[c])






)



